
À l’origine, Dynamo est le service développé en 2004 par Amazon afin de gérer les transactions de son site e-commerce. Cet outil cherche à répondre aux problématiques de charges, de scalabilité et de fiabilité auxquelles pouvait être confronté le site de commerce en ligne. Dans la continuité, Amazon DynamoDB est un service serverless de base de données NoSQL propriétaire développé et managé par AWS depuis 2012 se chargeant de répondre aux mêmes besoins.
Vous n’avez jamais utilisé le service DynamoDB ou bien vous vous demandez s’il conviendrait à votre situation ? Alors cet article vous est destiné : il présente le service dans ses grandes lignes ainsi que ses différents cas d’utilisation. Notamment, les exemples sont tirés d’une mise à l’épreuve de la base sur un projet en mission pour un client : DynamoDB est utilisé afin de stocker des produits destinés à une plateforme d’échange.
Présentation
Les composants
Amazon DynamoDB est une base de données NoSQL, ou non relationnelle, qui supporte aussi bien le stockage clé-valeur que document. Ce service se charge de stocker des éléments, eux-mêmes composés d’attributs, au sein de tables, concept également présent dans les bases de données relationnelles. Ces derniers contiennent diverses informations qui sont décrites par les attributs. Les types des attributs sont assez limités et peuvent être :
- scalaire : parmi number, string, binary ou boolean.
- document : un document est un type imbriqué, pouvant aller jusqu’à 32 niveaux d’imbrication. Les types imbriqués sont :
- list : une liste d’attributs, sans restriction, ils peuvent avoir des types différents.
- map : collection de clé-valeur, sans restriction sur les types contenus.
- set : collection de valeurs ne contenant aucun doublon, le type set supporte les types number, string ou binary, avec restriction sur le type : tous les éléments doivent être du même type.
Selon le niveau d’imbrication d’un attribut, il peut être appelé attribut de haut niveau ou bien attribut imbriqué.
Il faut garder à l’esprit que la taille maximale des éléments au sein d’une table est de 400Ko.
Par exemple, une table produit stocke des produits qui sont décrits par des attributs définissant ses caractéristiques :
{
"company_id": 123,
"product_code": "123456789",
"product": "Batterie 12V 17AH",
"price": 10.0,
"region": "Europe",
"tax_ids": [
1,
13
],
"informations": {
"description": "Batterie 12V 17AH neuve poids 1kg",
"images": [
"url-test.com",
"autre-url.com"
],
"details": {
"size": [10, 10, 5],
"weight": 10
}
}
}
Cet exemple présente un élément de la table produit, décrit par des attributs de types différents : scalaire, list, map. L’attribut est identifié par sa clé primaire composée des attributs “company_id” et “product_code”.
Clé primaire
Les éléments d’une table DynamoDB sont identifiés de manière unique par une clé primaire. La clé peut être de deux formats différents : soit une clé de partition soit l’association d’une clé de partition et d’une clé de tri.
Dans le premier format, la clé est définie par un seul attribut et donc chaque élément de la table aura une clé de partition (clé primaire) distincte. Dans le deuxième format, la clé primaire est une clé composite : composée d’une clé de partition et d’une clé de tri.
La clé de partition (ou “attribut de hachage”) est utilisée comme entrée d’une fonction de hachage dont la valeur de sortie déterminera la partition au sein de laquelle l’élément est disponible. Cette fonction répartit uniformément les éléments entre les partitions. La clé de tri (ou “attribut de plage”) quant à elle, ordonne les éléments au sein de la partition en stockant physiquement proches les éléments dont la clé de partition est égale.
Les attributs de la clé primaire doivent être des scalaires, restreints aux types string, number ou binary, et cette clé primaire ne peut être composée, au maximum, que de deux attributs.
Le schéma ci-dessous présente deux exemples de partitions : pour une clé primaire simple et une clé primaire composite. L’affiliation des éléments aux partitions est définie par la fonction de hachage.
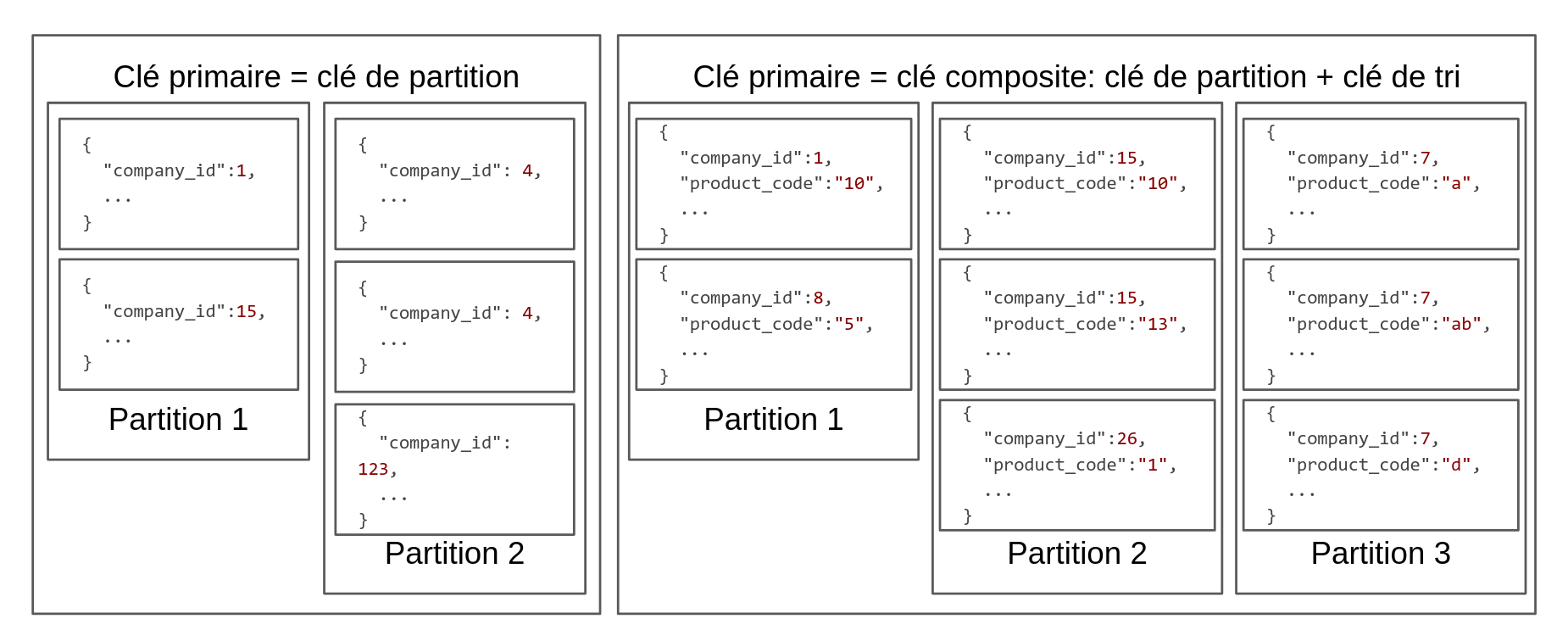
Pour en revenir à l’exemple de la table produit, la clé primaire est une clé composite dont la clé de partition est “company_id” et la clé de tri “product_code”. De nombreux produits sont stockés pour différentes boutiques, ce qui explique la clé de partition, qui devrait être choisie pour un ensemble d’éléments large au sein duquel les éléments peuvent être ordonnés.
Structure de données
Au sein de DynamoDB, aucune notion de schéma n’est présente. Le service est dit schemaless, ce qui est un avantage puisque tout type de données peut être stocké au sein de cette base. Cependant, bien qu’à première vue ceci soit un avantage, il peut s’avérer être une tourmente pour organiser les données et maintenir une certaine cohérence.
La seule donnée nécessitant un type prédéfini est la clé primaire de la table. Cette clé est indispensable pour l’identification unique d’un élément et sa définition est donc requise.
Ainsi, lors de la création de la table, il est nécessaire de spécifier les types des attributs de la clé. Voici les seules informations requises lors de la création :
- le nom de la table,
- la clé primaire et le type du/des attributs,
- les capacités de la table (nous y reviendrons plus tard).
Dans le cadre de la mission, nous avons instauré un schéma associé à la table afin de s’assurer de la validité des données. Ce schéma définit les champs possibles ainsi que leurs types. Nous utilisons JSON schema pour valider et formater les éléments en entrée.
Bien qu’aucun schéma ne soit nécessaire, certaines contraintes en découlent, et notamment le format de manipulation des données.
DynamoDB JSON
Pour manipuler les données dans DynamoDB, le format utilisé est le JSON (JavaScript Object Notation), qui est lisible par tout développeur. Cependant, lors d’exécution de requêtes, il faut associer à chaque valeur d’attribut son type. Par exemple, pour lire un élément dans la table produit, voici le JSON à fournir :
{
"company_id": {"N": "89"},
"product_code": {"S": "123"}
}
Ici, le N correspond à Number et le S à String. Ainsi, ce format peut devenir rapidement complexe, notamment lors de l’utilisation d’attributs imbriqués, dont les types devront à chaque fois être indiqués.
Un autre élément notable du format de données survient lors de la mise à jour d’éléments de la table, à l’aide de la requête update. Voici à quoi ressemble une simple mise à jour d’élément via la CLI :
aws dynamodb update-item \
--table-name product \
--key '{"company_id": {"N": "89"}, "product_code": {"S": "123"}}' \
--update-expression "SET #sd = :short_description, #p = :price" \
--expression-attribute-values '{":short_description": {"S": "test"},":price": {"N": "123"}}' \
--expression-attribute-names '{"#sd": "short_description", "#p": "price"}'
L’expression de mise à jour (--update-expression) indique l’association de l’attribut avec sa valeur et les deux autres expressions spécifient la valeur ainsi que le nom de l’attribut. Cet exemple met à jour seulement deux attributs sans utiliser d’autre clause, qui pourraient être la suppression d’un attribut existant. Il est donc basique mais son écriture est lourde.
Cette difficulté est due à l’absence de schéma : tout attribut peut être ajouté avec n’importe quel type, et il est donc indispensable de spécifier toutes ses informations. Lors de requêtes complexes, la lecture est simplifiée : les actions et les attributs modifiés sont visibles d’une part, et leur valeur d’autre part.
Heureusement, lors de l’implémentation, il existe des librairies facilitant l’écriture de telles requêtes, mais la lisibilité et la maintenabilité du code sont impactées par cette complexité.
Service managé
DynamoDB est un service managé : de nombreuses fonctionnalités sont gérées par le fournisseur, en l’occurrence AWS. Ces fonctionnalités concernent la supervision, le monitoring, l’encryptage ou encore la gestion des capacités. Cette dernière vaut le détour afin de mieux comprendre les options disponibles.
Gestion des capacités
DynamoDB propose deux modes de gestion des capacités : sur demande ou provisionné.
Mode sur demande
Le mode sur demande (ou on-demand) se base sur le nombre de requêtes en lecture et écriture effectuées par mois. Les variations de charges que peut subir la base sont automatiquement gérées par le service. Cependant, ces variations ne doivent pas être trop importantes : tant que le trafic est inférieur à deux fois le dernier pic atteint, les requêtes aboutissent. Si cette valeur est dépassée, les capacités sont mises à jour mais cela peut prendre jusqu’à 30 minutes.
Un exemple pour mieux comprendre : le dernier pic de requêtes était de 2 000 requêtes par seconde, donc le trafic actuel peut aller jusqu’à 4 000 requêtes par seconde. Lors du prochain pic (disons 3 500 requêtes/seconde), les capacités seront mises à jour, et les nouvelles capacités seront le double du dernier pic (donc 7 000).
Les valeurs pour une nouvelle table dont les charges ne peuvent pas être estimées sont de 2 000 unités d’écriture et de 6 000 unités de lecture (donc le pic maximal supporté est de 4 000 écritures et 12 000 lectures).
Le principal avantage de ce mode est de ne pas avoir à spécifier les capacités de lecture et d’écriture : le trafic pris en charge se base sur les dernières utilisations. Le paiement prend en compte seulement les requêtes effectuées et pas les capacités provisionnées, à la différence du mode provisionné.
Mode provisionné
Le mode provisionné (ou provisioned) se base lui sur les capacités spécifiées par l’utilisateur. L’auto-scaling peut être activé sur ce mode de fonctionnement : ceci permet d’adapter les capacités selon le trafic. Il est nécessaire de spécifier des extrema pour l’auto-scaling : les limites (minimum et maximum) des capacités atteignables, ainsi qu’une cible d’utilisation, en pourcentage. Cette cible vise à adapter les capacités : si le trafic est supérieur à la valeur cible, alors les capacités doublent au bout d’une certaine période d’utilisation, jusqu’à atteindre la limite maximale des capacités. Au contraire, si le trafic est inférieur à la cible, les capacités diminuent jusqu’à atteindre le minimum.
Voici un exemple de mise à jour des capacités par l’auto-scaling :
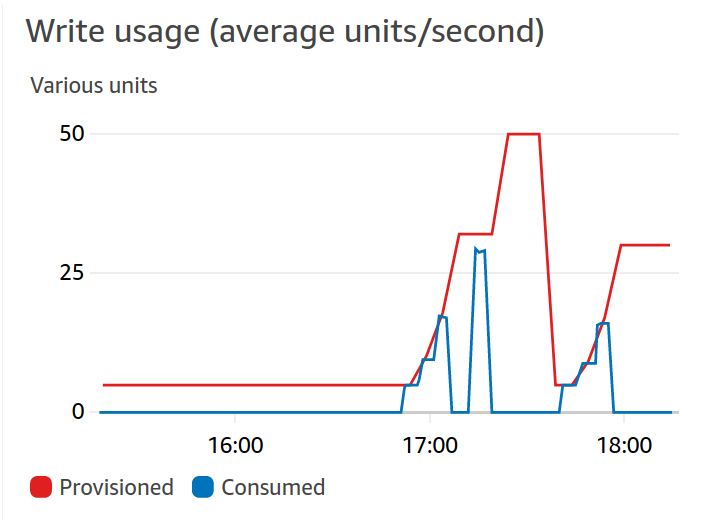
La période durant laquelle est comparée le trafic à la cible est de 5 minutes et elle n’est pas modifiable aisément. Ceci peut représenter un problème lorsque le trafic s’intensifie par périodes, par exemple lors d’exécutions de batchs, qui risquent de requêter fortement sur une courte durée. Une solution pour raccourcir la période de mise à l’échelle est de modifier les alarmes CloudWatch comme montré dans cet article. L’auto-scaling se base sur les alarmes CloudWatch : lorsqu’un certain nombre d’alarmes est déclenché, les capacités sont augmentées. L’objectif de l’article mentionné est de réduire le seuil d'alarme afin d’augmenter les dimensions dès la première alarme.
Ainsi, choisir le mode de provisionnement est important pour réduire les coûts tout en s’adaptant au trafic de la table. Voici quelques éléments permettant de se décider sur le mode à choisir :
| On-demand | Provisioned |
| Nouvelle table avec des charges inconnues Pic de charge imprévisible Pas de requête entre les charges |
Trafic constant ou progressif Prévision des besoins |
Dans le cadre de la mission, le choix du mode provisionné a été fait : les requêtes sont faites dans le cadre de lots sur la durée, et le trafic est plus ou moins connu. Ce trafic est plutôt régulier et les besoins sont prévisibles lors des fortes charges.
Pour ce qui est du calcul du nombre d’accès à la table, il est réalisé à partir des unités de lecture et d’écriture. Une unité correspond à la lecture de 4Ko de données à cohérence forte ou bien à deux lectures à cohérence à terme (strong vs eventual consistency). Pour rappel, la différence entre ces deux types de lecture intervient lors de la lecture immédiatement après mise à jour d’une valeur : dans le cas de la cohérence forte, la valeur retournée sera celle mise à jour, tandis que dans l’autre cas la valeur peut être celle avant ou après mise à jour. Par défaut, les lectures sont à cohérence à terme. Pour modifier ce comportement, il est nécessaire de spécifier le mode de lecture à cohérence forte lors de la requête.
Pour l’écriture, une unité correspond à l’écriture d’un élément d’une taille allant jusqu’à 1Ko.
DynamoDB supporte les transactions, et ces transactions utilisent deux unités pour l’écriture d’un élément de 1Ko ou la lecture d’un élément de 4Ko.
Pour y voir plus clair, voici un petit exemple. La table comporte 400 éléments et est configurée en mode provisionné, avec 50 unités de lecture par seconde et 10 unités d’écriture. Pour lire 200 éléments (de taille inférieure à 4Ko) avec une cohérence à terme, le temps minimum est de 4 secondes. Pour écrire 10 nouveaux éléments de 3Ko chacun, il faudra 30 unités et donc 3 secondes. Pour optimiser les temps en lecture, les requêtes de type query sont à favoriser par rapport à celles de type scan.
Scan vs Query
Deux types d’opérations sont disponibles en lecture : scan et query. Une opération de scan va analyser toute la table afin de répondre à la requête, qui peut porter sur n’importe quel attribut, tandis qu’une opération query recherche des éléments précis en se basant sur leur clé primaire.
Scan
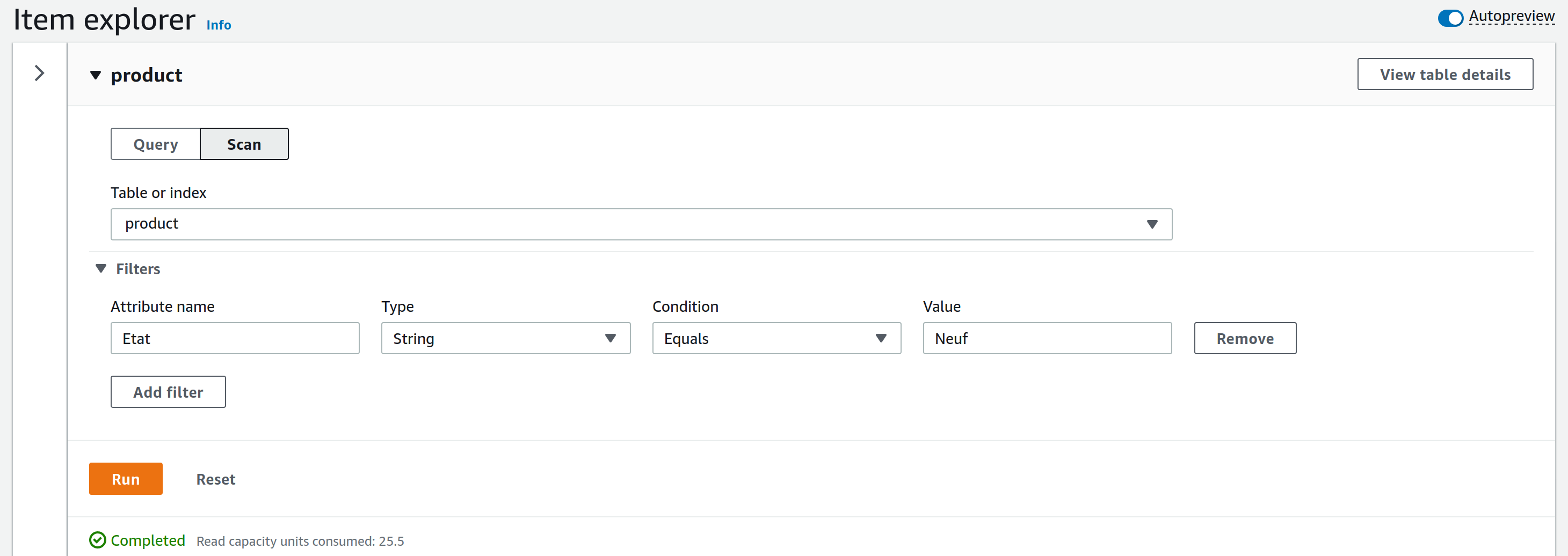
Lors d’un scan, il est possible de spécifier des filtres afin d’affiner la recherche, mais celle-ci portera sur la table entière. Si des filtres sont spécifiés, ils sont appliqués après avoir extrait les données de la table. De ce fait, une opération avec filtres consomme autant de capacités que sans. La taille maximale des éléments retournés par un scan est de 1Mo.
L’image ci-dessous présente la console DynamoDB lors d’une requête scan. Ici, un filtre est appliqué sur l’attribut “Etat”, afin de retourner uniquement les éléments dont l’attribut est égal à “Neuf”. Une fois la requête effectuée, les unités de capacités de lecture consommées sont affichées, ainsi que les résultats de la requête, limités à un affichage de 300.
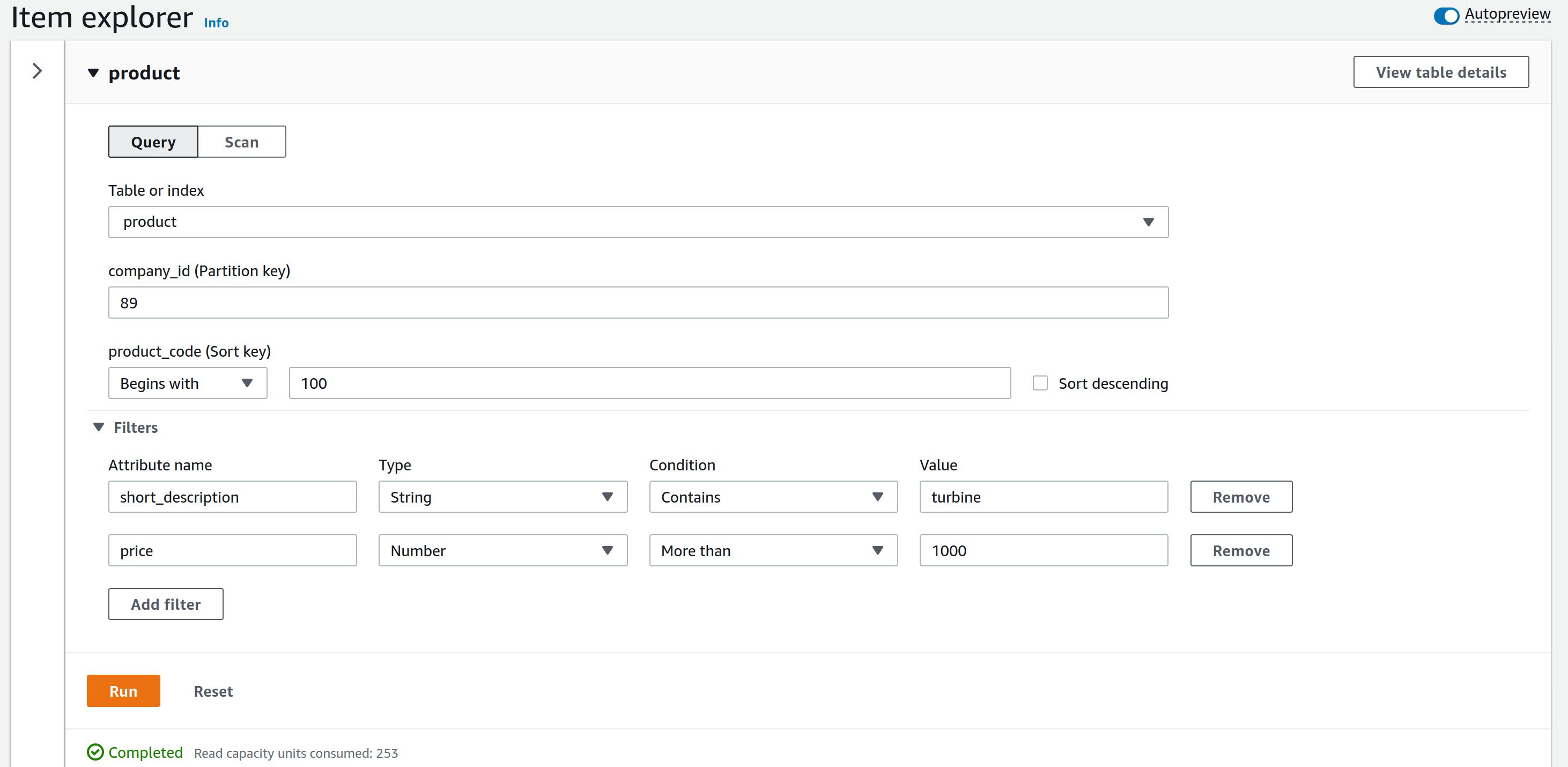
Query
Pour une query, la clé primaire doit être renseignée afin de rechercher un élément en particulier. Il est possible de rechercher plusieurs éléments en spécifiant un ensemble de valeurs possibles pour la clé de tri : par exemple en spécifiant une limite pour cette clé et récupérer les valeurs supérieures ou inférieures, spécifier une valeur contenue dans l’attribut et obtenir tous les éléments contenant cette valeur. Cependant, la clé de partition ne peut pas être variable : elle est fixe et une égalité est nécessaire pour qu’un élément soit retourné.
L’image ci-dessous présente une requête query. A la différence du scan, il a été nécessaire de spécifier des valeurs pour la clé primaire. Pour cet exemple, la clé de tri recherchée doit commencer par 100 ; il n’est pas nécessaire de renseigner une valeur précise. Des attributs peuvent être filtrés : ici, une turbine est recherchée de prix supérieur à 1000.
Capacités nécessaires
Lors de l’exécution des requêtes, peu importe l’opération, les capacités utilisées dépendent de la taille des éléments auxquels la recherche a accédé, et pas seulement des éléments retournés. Notamment, dans le cas de filtres, tous les éléments sont accédés pour ensuite être filtrés.
Encore une fois, un exemple éclaircira le concept. Dans le cas d’une table de 100 éléments de taille 150 octets, la taille complète de la table est donc de 15Ko. Dans le cas d’une cohérence forte, une unité de lecture correspond à la lecture de 4Ko de données. Ainsi, lors d’une opération de scan, tous les éléments sont retournés et donc 4 unités de lecture sont nécessaires (contre 2 seulement pour une cohérence à terme).
Le fonctionnement est identique pour les query. Si l’on recherche 10 éléments, chacun d’une taille de 150 octets, la taille totale est de 1.5Ko et donc une unité de lecture est nécessaire. Cependant, si l’on recherche maintenant 10 éléments d’une taille de 1Ko chacun, le nombre d’unités de lecture nécessaires est de 3 en cohérence forte ou 2 en cohérence à terme (10 éléments x 1 Ko / 4 Ko = 3).
Pour en revenir à la mission, les deux opérations sont utilisées, bien que la query soit favorisée puisque beaucoup plus optimisée. Pour récupérer les informations de certains produits, afin de les mettre à jour ou de comparer leurs attributs, l’opération de query est utilisée, étant donné que les informations sont recherchées pour une clé précise.
L’opération de scan quant à elle est utilisée pour extraire toutes les données de la base. Pour cela, plusieurs scan sont appelés séquentiellement, en utilisant une pagination : chaque appel s’effectue sur une page (une succession d’éléments dont la taille totale est égale à 1Mo) différente en spécifiant à chaque fois la fin de la page précédente. L’opération étant très gourmande, il faut faire attention lors de son utilisation, et elle ne doit en aucun cas servir à faire une sauvegarde de la table.
Pour réaliser une extraction de la base, une solution est désormais proposée afin d’exporter la table vers AWS S3, depuis la console (attention, seulement la version 2 de DynamoDB le propose), la CLI, les SDKs (pas encore pour Python) ou via une API. Cette méthode ne consomme pas de capacités sur la table. Cependant, seuls deux formats d’export sont disponibles : DynamoDB JSON ou Amazon Ion. Malheureusement, ces deux formats ne sont pas les plus simples à visualiser : DynamoDB JSON est relativement lourd du fait du typage de chaque attribut tandis qu’Amazon Ion est une surcouche à JSON qui ne permet pas de lire simplement les données.
Index secondaires
Les deux modes de requêtage sont limitants : le scan n’est vraiment pas optimisé pour faire des recherches tandis que la query nécessite de spécifier des valeurs pour la clé. Pour remédier à ce problème et faire des requêtes sur des attributs non présents dans la clé, les index secondaires sont la solution. Ils sont associés à la table de base mais définissent une nouvelle clé primaire qui peut alors être requêtée.
Deux types d’index existent : l’index secondaire global ou l’index secondaire local. Le premier définit un schéma de clé primaire différent de la table de base : la clé de partition comme la clé de tri peuvent être différentes de celles de la table de base. Pour le second, seule la clé de tri est différente, la clé de partition reste la même que celle de la table de base.
Le nombre d’index secondaire global maximum par table est de 20 ainsi que de 5 pour les index secondaires locaux.
Voici un exemple d’une table avec sa clé primaire et deux index. Une couleur représente une clé et le bloc rempli de couleur indique la clé de partition. La clé primaire de la table de base est la clé bleue : “company_id” est la clé de partition et “product_code” est la clé de tri. La clé verte est un index secondaire local : sa clé de partition est identique à celle de la table de base. Le rouge est un index secondaire global : sa clé de partition est différente de celle de base.
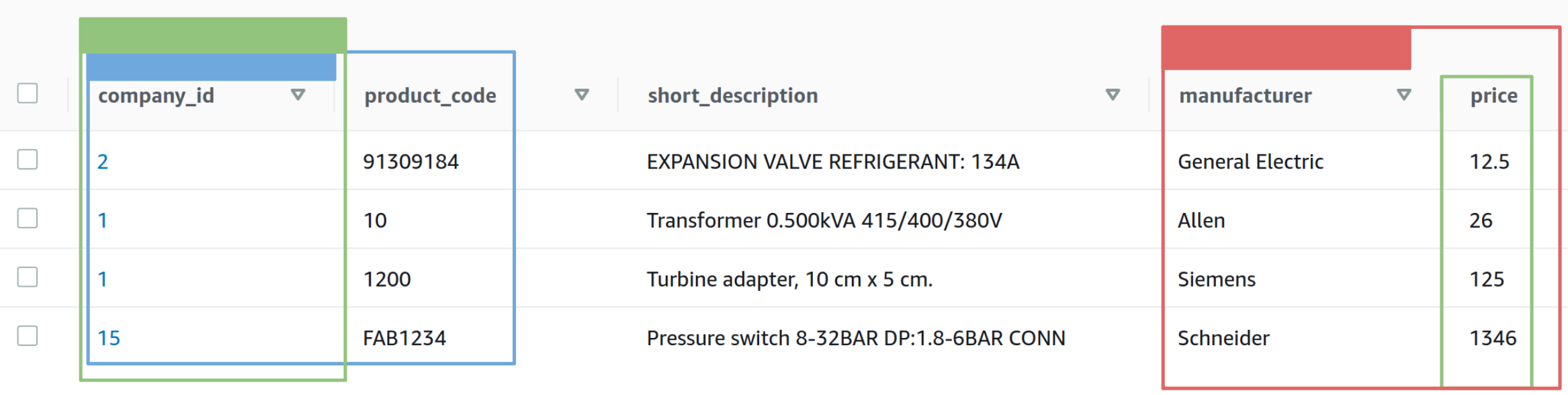
Les deux types d’index sont maintenus automatiquement : toute action sur la table de base est répercutée sur l’index. Lors de la création de l’index, il faut spécifier les attributs à projeter, ceux qui seront retournés lors des requêtes ; les attributs de la clé de la table de base sont projetés par défaut.
Dans l’exemple précédent avec la table produit et ses index, la clé primaire de la table de base est composée du “company_id” ainsi que du “product_code”. Cependant, il est parfois nécessaire de rechercher des produits pour un certain fabricant. Ainsi, grâce à l’index secondaire global (en rouge), la recherche peut utiliser l’opération de query, en filtrant sur la valeur du champ “price”. Sans cet index, il aurait fallu faire un scan avec un filtre sur la table, ce qui aurait été bien plus long.
Et bien d’autres fonctionnalités
Dans la continuité du service managé, une sauvegarde automatique des données est proposée, en utilisant le service AWS Backup. Il est également possible de restaurer les données d’un instant dans le passé, pouvant aller jusqu’à 35 jours. Bien sûr, une sauvegarde peut être effectuée à tout instant à la demande.
Dans une même optique de sécurisation des données, celles-ci sont répliquées automatiquement sur trois zones d’accessibilité au sein d’une même région (Availability Zones). Par défaut, la table n’est pas répliquée sur différentes régions, mais cette fonctionnalité est possible en utilisant une table globale, où la réplication entre régions devient automatique.
Une fois les données stockées, elles sont chiffrées au repos à l’aide de clés de chiffrement, stockées dans AWS KMS. Ce chiffrement est transparent à l’utilisateur et assure une protection des données et une conformité à certaines attentes.
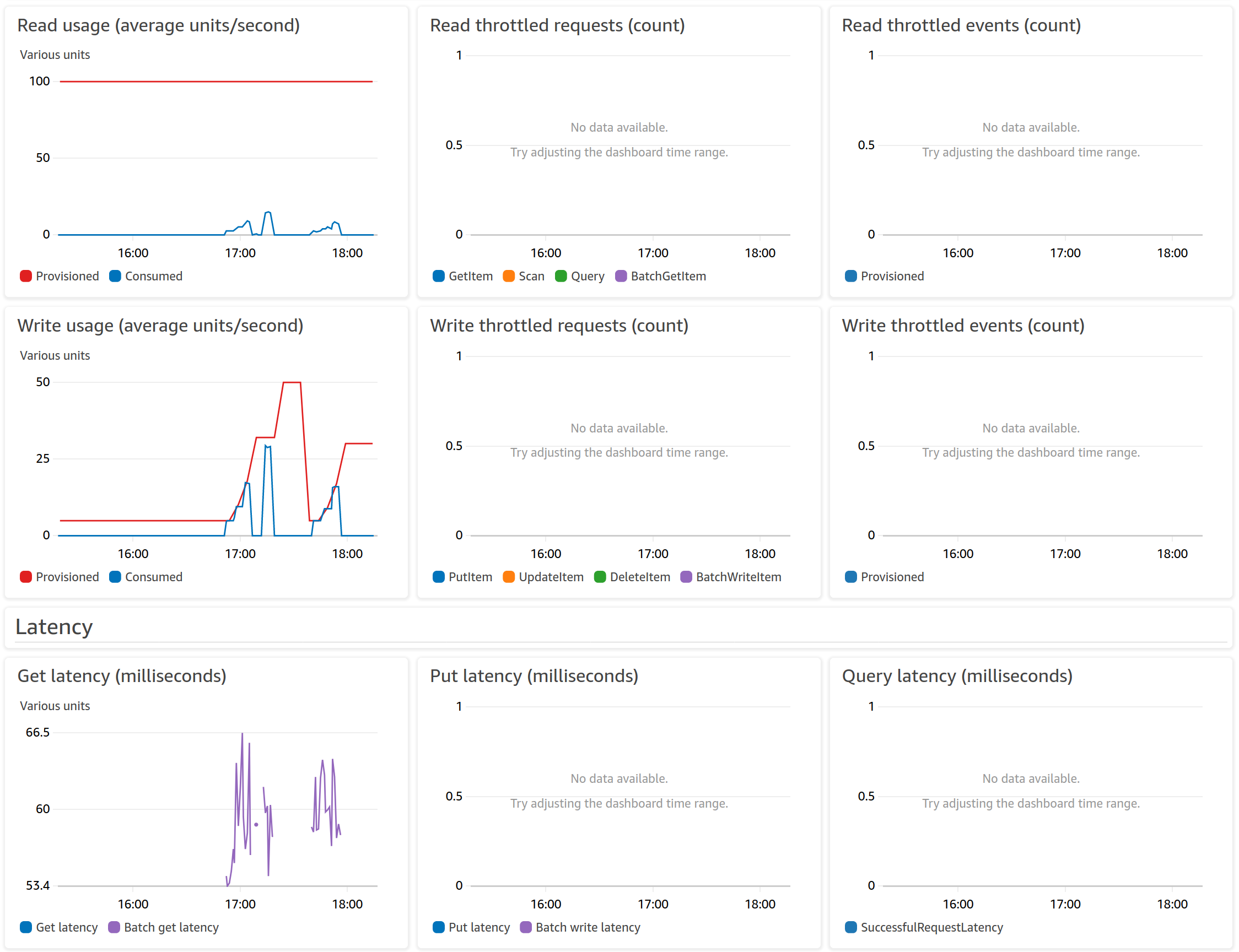
DynamoDB propose également une surveillance intégrée : des graphiques présentent la consommation des capacités, les temps de latence ou encore les erreurs survenues. Ces graphiques offrent de bons résultats pour surveiller les métriques de la table, mais des alertes peuvent être ajoutées dans le cas d’une utilisation intensive, qui sont à configurer dans AWS CloudWatch.
L’image suivante montre certains graphiques disponibles depuis la console DynamoDB, et particulièrement l’évolution des capacités. Notamment, l’auto-scaling de la table ajuste les capacités selon le besoin, comme on peut le voir sur le graphique de consommation en écriture.
Conclusion
DynamoDB est un service qui entre entièrement dans les éco-systèmes serverless du fait de ses caractéristiques : l’auto-scaling se base sur la charge applicative, un paiement calculé sur les actions consommées, pas de serveur à gérer et bien d’autres fonctionnalités qui rendent sa prise en main simple.
Évidemment, de nombreux sujets n’ont pas été évoqués pour ne pas alourdir, mais des outils sont disponibles pour aller plus loin et optimiser les tables ou intégrer DynamoDB au sein de son environnement. Par exemple, DynamoDB Flux propose la capture d’évènements sur la table pour enregistrer toutes les modifications apportées aux éléments, afin de déclencher d’autres services, tels que des Lambdas pour traiter les modifications.
Bien que très simple à prendre en main, DynamoDB présente ses limites à un certain niveau d’utilisation. Nous avons notamment vu que la création de requêtes depuis un client peut être fastidieuse. Également, la base de données ne propose pas d’outils de requêtes, ce qui rend une analyse de données difficile. Par exemple, il aurait été intéressant de pouvoir brancher Quicksight, le service AWS de gestion de tableaux de bord, sur une table DynamoDB. Une solution de contournement est d’associer les services Glue et S3.
