
Article co-écrit par Laura POUDEVIGNE et Anne JACQUET.
Dans le premier article de cette série, nous présentons le contexte du projet, l’infrastructure supportant l’application web de kwiper, ainsi que les différents éléments constituant l’écosystème technique de l’application. Le deuxième article se concentre sur les problématiques de sécurisation de l’application.
Ce troisième article aborde le projet sous un nouvel angle, celui du développement. Cette présentation commence par les pratiques qui nous paraissent essentielles et pouvant s’appliquer à tout projet, suivi de quelques décisions plus spécifiques au métier de kwiper. Pour finir, l’aspect DevOps est abordé à travers l’outillage et les environnements qui nous permettent de travailler dans de bonnes conditions.
Notre équipe est composée de quatre développeurs, ce qui nous permet d’être flexibles dans notre manière de fonctionner. Nous questionnons régulièrement notre organisation et notre architecture. Ce qui suit est un aperçu de l’état de l’application à l’heure actuelle et de la manière dont nous y sommes arrivés.
Les indispensables
A notre arrivée sur le projet, nous avons commencé par mettre en place les actions qui nous semblaient les plus importantes car permettant de simplifier les développements, éviter les régressions ou automatiser la gestion des modifications de la base de données.
Relecture
Tous les développements font systématiquement l’objet d’une merge request et donc d’une revue par un pair. Nous priorisons la relecture des merge request sur les développements afin qu’elles ne s'accumulent pas.
Liquibase
Pour apporter des modifications à la base de données nous avons mis en place liquibase. C’est un projet open-source qui permet de versionner les changements sur la base de données (création ou suppression d’une table, d’une colonne, …) et de les exécuter. Liquibase est configuré de manière à exécuter les changements sans intervention manuelle : quand le service Spring Boot est démarré, les changements nécessaires sont exécutés.
Tests
Sur les nouveaux développements back-end, le code est systématiquement testé au moins unitairement. Nous augmentons ainsi progressivement la quantité et la qualité des tests de la base de code. Les tests sont réalisés avec JUnit ainsi que les librairies AssertJ et Mockito.
Nous avons mis en place des tests pour le front-end Angular, en utilisant Karma et Jasmine. Les nouvelles fonctionnalités sont là aussi testées unitairement.
En complément de ces tests, nous utilisons SonarQube pour suivre l’évolution de la couverture de tests et de la qualité du code. La configuration de SonarLint au sein de notre IDE nous permet de prévenir au plus tôt les erreurs qui peuvent être détectées par cet outil.
LocalStack
Pour faciliter le lancement de l’application en local, nous utilisons l’outil docker-compose pour avoir les briques applicatives externes sur nos postes. L’outil permet de définir et de lancer plusieurs conteneurs docker. Nous y avons ajouté LocalStack. Cet outil nous permet notamment de reproduire le comportement de services AWS sur nos postes. Nous pouvons ainsi utiliser localement la base de données, S3, Vault et les autres briques déjà dockerisées. Seul le service AWS Cognito n’est pas disponible de cette manière.
Architecture de la base de code
Lorsque nous avons découvert ce projet, il avait déjà fait l’objet d’un an de développement par une autre équipe. L’objectif était alors de montrer la faisabilité dans un périmètre restreint. Il était par exemple possible d’effectuer un bilan successoral, mais avec des règles simplifiées par rapport à la version actuelle et avec des données d’entrée répondant à des contraintes strictes.
Ippon a alors été mandaté pour réaliser un audit de la base de code existante puis pour continuer les développements. Le challenge de nos premiers mois a été d’apporter une qualité satisfaisante sur les parties clés de l’application pour assurer son évolutivité, sa robustesse et une fiabilité suffisante pour mettre en production l’application.
Nous avons priorisé les éléments à mettre en place :
- centraliser les règles métier dans le back-end pour des besoins de sécurité et robustesse : une grande partie des règles métier se trouvant alors dans le front-end ;
- faire apparaître des responsabilités plus claires dans les services ;
- limiter la responsabilité des controller REST à la communication avec le client web ;
- diminuer la quantité de code commun à tous les services afin de les découpler ;
- augmenter la flexibilité et la réutilisabilité de la logique en n’utilisant plus les entity hibernate dans l’ensemble de la logique ;
- mettre en place un contrôle d’accès aux ressources : jusque-là aucun endpoint n’était sécurisé, il suffisait d’avoir un token valide pour accéder à n’importe quelle ressource.
Refactoring progressif
L’esprit de la reprise du projet n’a jamais été de repartir de zéro mais bien de construire autour du prototype existant et de l’enrichir au fur et à mesure, sans rien perdre des fonctionnalités déjà développées.
Nous procédons donc progressivement à l’amélioration du code existant. A chaque fois qu’une nouvelle fonctionnalité a besoin d’appeler le code existant, c’est l’occasion d’y appliquer nos pratiques :
- créer des DTOs pour remplacer les entities hibernate qui se trouvent dans des DTOs ;
- isoler les mapping entre deux objets afin de les tester unitairement et remplacer l’utilisation de ModelMapper par des mapper MapStruct afin d’être notifié à la compilation si un attribut de l’objet cible ne peut pas être rempli automatiquement ;
- créer des objets métier dans la couche business pour ces objets s’ils n’existaient pas ;
- créer ou compléter les tests.
Quand le développement d’une feature nécessite un travail préalable sur le code existant, nous le faisons dans une merge request séparée afin de garder de la lisibilité dans chacune des MR.
Étonnamment, à plusieurs reprises, nous avons fait le pari de ne pas améliorer l’existant mais plutôt de développer un nouveau mécanisme parallèle qui répondait au même besoin. Ainsi, les deux solutions (la nouvelle et la legacy) cohabitent et leurs résultats sont fusionnés.
Cela nous a permis de ne pas refactorer inutilement du code qui a par la suite disparu car il n’était plus d’actualité. De plus, cela nous permet de continuer à apporter de nouvelles fonctionnalités rapidement, sans passer des sprints entiers à modifier l’existant. Enfin, cela laisse la possibilité de se faire une idée sur le nouveau mécanisme : même si une implémentation paraît convenir le jour de son développement, le vrai verdict tombe souvent lors de son utilisation future. On peut alors juger le système de par la facilité ou non que nous avons à le faire évoluer.
Définir les responsabilités
A mesure que notre compréhension du métier s’améliore, nous définissons progressivement mieux les rôles de chaque service back-end.
A titre d’exemple, l’application contient deux applications front-end : une utilisée en interne chez kwiper et une utilisée par les clients. Chacun de ces front-ends avait un service back-end associé. Ces deux services accédaient aux mêmes ressources en base de données et contenaient de la logique similaire.
Au cours de nos développements, nous avons progressivement transformé ces services afin de leur donner des responsabilités claires :
- le premier est responsable de l’administration des utilisateurs de la plateforme et des données qui leur sont associées ;
- le deuxième est responsable des données des clients des experts comptables.
Ce découpage a permis de rendre les deux applications Spring Boot plus cohérentes et moins couplées entre elles.
Ce travail a aussi été réalisé au sein de chaque service, au niveau des différentes notions métiers qui sont maintenant réunies en package. A chaque fois que nous isolons une notion cohérente, et découplée du reste du code, il est plus simple de faire des améliorations au sein de ce regroupement tout en maîtrisant les impacts.
Architecture : le métier au centre
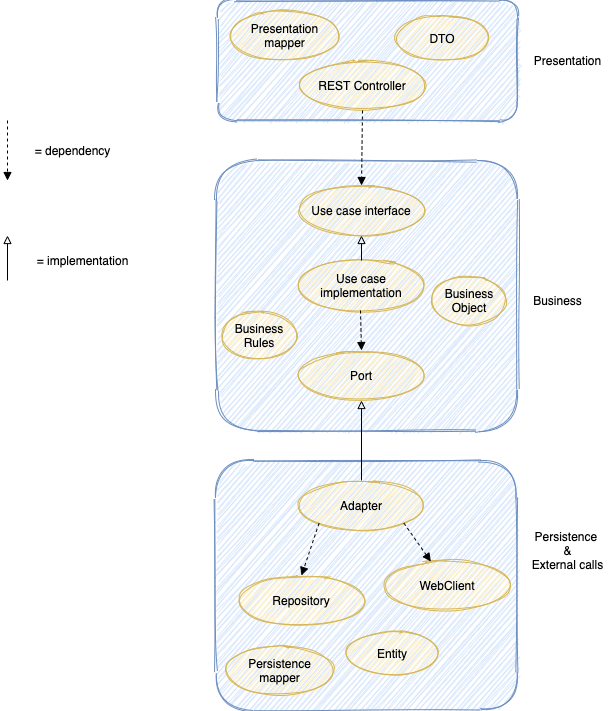
Pour répondre au problème de la logique métier dispersée au sein du code, nous avons mis en place une nouvelle architecture inspirée des principes de clean architecture et d’architecture hexagonale.
Cette architecture simplifiée était adaptée à nos besoins : elle permet d’isoler les traitements métiers et s’intégrait bien dans l’existant. Nous avons pu voir ses avantages assez rapidement. Nous avons notamment gagné en flexibilité puisque les impacts des changements sont limités et maîtrisés.
L'objectif est d'isoler le métier complexe des autres problématiques. On distingue trois catégories dans l’application :
- les adapters entrant : les services fournis à l’extérieur (API) ;
- la business logic : le métier et ses règles ;
- les adapters sortant : les services de persistance (base de données) et les services externes dont nous dépendons (web services externes).
Architecture du code de kwiper
L’un des principes clés est que la business logic ne dépend de rien : ce sont les briques de présentation et de persistence qui dépendent de la business logic. Cette dépendance de l'extérieur vers l'intérieur est possible notamment grâce à l'inversion des dépendances et à la matérialisation des frontières de la business logic par des interfaces.
Design des APIs
L’interface du back-end de l’application est représentée par une API REST. Les URLs sont principalement formées de noms de ressources, au pluriel, et d’identifiants. En voici deux exemples :
POST etudes/{id}/clientsGET etudes/{id}/clients/{id}/strategies/{id}/objectifs/{id}
Dans l’application, un utilisateur ne peut accéder qu’aux informations se trouvant dans son étude. La vérification de l’appartenance de l’utilisateur à l’étude se fait au niveau du Controller, en utilisant les annotations @PreAuthorize de Spring Security. Les Use Cases de la partie business du code exposent des méthodes permettant de récupérer les ressources au sein d’une étude donnée. La vérification de l’appartenance de la ressource à l’étude se fait donc directement dans la couche business de l’application.
L’accès aux endpoints est ainsi limité aux utilisateurs ayant les droits requis. Nous avons aussi dû développer un mécanisme de feature flags permettant de bloquer certains endpoints par environnement car l’application est amenée à être déployée dans des contextes différents. Selon le contexte, certaines fonctionnalités sont désactivées. Pour cela, nous avons créé une annotation qui corrèle l’existence du endpoint annoté à la présence d’une variable d’environnement.
Nous avons maintenant un aperçu de l’architecture du code et des procédés de développement employés sur l’application kwiper. Voyons maintenant le lien entre ces deux parties, à travers l’aspect “DevOps” du projet.
Culture DevOps for devs
Afin de tester et de valider avec le client les fonctionnalités développées, nous avons créé plusieurs environnements, tous déployés sur AWS.
Le premier, appelé integration, est principalement utilisé par les développeurs. Les autres environnements sont staging et prod. Tous ces environnements sont en fait des comptes AWS distincts.
Il existe un autre compte AWS dédié à la gestion des comptes utilisateurs. Tous les développeurs sont des utilisateurs IAM ayant le droit d’endosser un rôle dans les autres comptes. Ce rôle donne accès aux services utilisés : S3, RDS, ECS, ... . Cela permet de centraliser la gestion des droits.
CI/CD
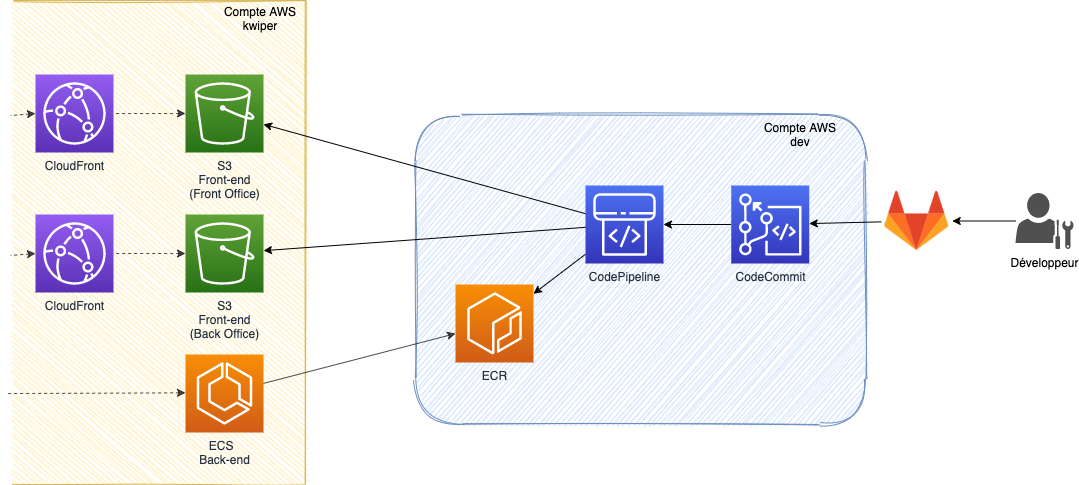
Nous avons créé un dernier compte AWS contenant tout l’outillage CI/CD des différents environnements.
Infrastructure de la CI/CD
Nous avons longtemps utilisé le service CodeCommit pour héberger nos référentiels Git. Mais il offre bien moins de fonctionnalités que ses concurrents et c’est pour cela que nous avons changé pour GitLab. Le repository git existe toujours sur CodeCommit pour les pipelines de CI/CD. Nous utilisons la fonctionnalité de repository mirroring de GitLab pour reporter chaque commit vers AWS.
Les tests sont lancés à chaque nouveau commit sur une merge request, ce qui permet d’augmenter la vitesse de détection d’un build qui échoue.
Le déploiement continu est en place sur tous les environnements, il est réalisé avec CodePipeline. A chaque commit sur la branche de l’environnement, le pipeline est lancé :
- tous les tests sont exécutés ;
- les images docker sont construites, taguées et déployées sur Elastic Container Registry ;
- les applications front-end sont construites et copiées vers le bucket de l’environnement ;
- les tâches ECS sont redémarrées pour prendre en compte les dernières images ;
- les caches CloudFront sont invalidés.
Actuellement, un pipeline met environ 13 minutes à s’exécuter. On pourrait diminuer ce temps en lançant les tests des différents services en parallèle.
Infrastructure as code
Pour gérer cette infrastructure nous utilisons Terraform, un outil d’infrastructure as code, qui nous permet de décrire nos environnements cibles. En effet, comme toute l'infrastructure est décrite dans des fichiers, nous pouvons déployer autant d’environnements que nous voulons avec la certitude qu’ils seront identiques.
Tous les fichiers terraform sont versionnés dans un repository git, ce qui permet d’avoir un historique des changements. Cela permet également d’annuler des changements et donc de facilement revenir en arrière.
Les différentes parties de l’infrastructure sont découpées en modules. Grâce à cela et à la documentation complète de terraform, les développeurs sont autonomes pour modifier les environnements. Un exemple de changements simples qui arrivent fréquemment sont l’ajout de variables d’environnement ou la création d’un nouveau bucket S3.
Ces pratiques DevOps et l’intégration continue sont complémentaires à notre infrastructure et à nos pratiques de développement. Nous venons donc de parcourir l’ensemble des éléments mis en place durant ces derniers mois.
Parmi les points d’amélioration que nous envisageons pour le futur se trouvent : la mise en place d’environnements éphémères liés aux merge requests, l’utilisation de TestContainer dans nos tests ou encore la mise en place d’un système de messaging entre nos services qui communiquent pour l’instant via des appels HTTP.
Conclusion
La collaboration entre l’équipe technique d’Ippon et l’équipe à la tête de kwiper a permis d’améliorer constamment la plateforme.
D’un point de vue métier, l’application a connu de nombreuses évolutions. Des fonctionnalités nouvelles et essentielles pour la commercialisation du produit ont été ajoutées, d’autres ont été entièrement repensées. Le développement de chaque évolution a été l’occasion d’améliorer progressivement la qualité du code et de mettre en place une nouvelle architecture pour le rendre plus évolutif. Les évolutions sont régulièrement mises à disposition des utilisateurs de manière fiable et rapide grâce à l’automatisation des tests et du déploiement.
Côté infrastructure, de nombreux services d’AWS ont été mis à profit. De grands chantiers techniques ont été entrepris afin de rendre le produit viable et commercialisable. Nous avons notamment sécurisé toute la plateforme et mis en place les outils nécessaires afin de réduire le time to market et de respecter les contraintes légales.
La satisfaction de toutes ces exigences a permis de transformer les idées de Nathalie et Thibaut en un produit commercialisé dès le dernier trimestre 2020.

