

Il y a maintenant 2 ans et demi, j’avais écrit un article d’Introduction aux coroutines dans Kotlin, dont le but est d’exécuter du code asynchrone et non-bloquant. Il s’agissait alors de l’une des grandes nouveautés depuis que Kotlin est supporté par Google en tant que second langage pour le développement Android en 2017. Depuis son support officiel, ce langage n’a eu de cesse de s’imposer et, 2 ans plus tard, il devient le langage recommandé par Google, reléguant ainsi Java au second plan.
Flow étant une nouvelle librairie s’appuyant sur kotlinx.coroutines, j’ai choisi de vous la présenter à travers cet article de blog.
Vous pouvez aussi retrouver une “version vidéo” de cet article puisque j’ai parlé de Kotlin Flow lors d’un Meetup organisé par le FRAUG (French Android User Group) le 26 novembre dernier sur leur chaîne Twitch. La vidéo est disponible ici.
Tout d’abord, je vais vous présenter (ou vous rappeler) ce qu’est l’asynchrone, puis nous nous intéresserons aux solutions apportées pour écrire du code asynchrone dans une application Android et enfin, nous terminerons par une partie pratique à travers une app que nous aurons développée.
C'est quoi l'asynchrone ?
Dans une application mobile, sur Android comme sur iOS, nous avons ce que l’on appelle un thread principal (aussi appelé UI thread). Son but est de gérer les interactions utilisateurs ainsi que l’affichage. Par défaut, l’ensemble des opérations s’exécutent sur ce thread, les unes après les autres.
Le souci vient par exemple lorsque l’application effectue un appel réseau (un appel à un web service pour récupérer des informations par exemple). Admettons que cet appel dure 10 secondes, et bien cela signifie que si l’appel réseau s’effectue sur le thread principal, l’interface graphique sera bloquée pendant tout ce temps et l’utilisateur ne pourra donc plus interagir avec. On dit que ces tâches sont alors synchrones, c’est-à-dire que l’on doit attendre que l’une soit terminée avant de lancer la suivante.
Vous l’aurez compris, exécuter l’ensemble des tâches sur le thread principal est loin d’être la solution optimale car cela gâche complètement l’expérience utilisateur. On apprécie en effet d’avoir une application fluide et réactive.C’est ici que les traitements asynchrones tirent tout leur intérêt, car ils vont permettre de réaliser des traitements en arrière-plan sans bloquer le thread principal. Dans notre exemple, l’appel réseau va pouvoir être exécuté dans un thread autre que le thread principal, et ainsi empêcher de bloquer temporairement l’interface graphique.
Et JetBrains intégra les coroutines
La toute première solution intégrée dans l’API 1 du SDK Android pour réaliser du développement asynchrone était sobrement appelée Thread. Puis nous avons vu les AsyncTask intégrées dans l’API 3, conçues pour être moins gourmandes en ressource, et donc plus adaptées au monde Android.
Enfin, avec la mise en avant de Kotlin par Google, sont arrivées les fameuses coroutines, ces threads légers que l’on peut utiliser sans affecter grandement les ressources d’un device Android.
Lors de l’écriture de l’article sur les coroutines, celles-ci en étaient au stade expérimental dans la version 1.1 de Kotlin. La version stable a été intégrée dans la version 1.3 de Kotlin, sortie en octobre 2018.
Les coroutines sont, comparativement aux Threads, plus légères. Elles permettent d’exécuter du code de façon asynchrone. De par leur légèreté, on peut lancer plusieurs coroutines, et donc plusieurs fils de code, simultanément sans affecter les ressources matérielles comme la RAM ou le processeur par exemple.
C’est un élément très important car de façon générale, un téléphone Android est, par définition, un système embarqué. Il y a donc des contraintes de ressources, même si de nos jours, les téléphones bénéficient de matériel de plus en plus puissant, qui peut quasiment être comparé aux ordinateurs que nous avions il y a quelques années. Mais restant des systèmes embarqués, les coroutines répondent parfaitement au besoin “d’économie” de ressources.
D’autre part, les coroutines ont une notion de hiérarchie, c’est-à-dire qu’on va pouvoir par exemple définir une coroutine mère et plusieurs coroutines filles, et faire en sorte que si la coroutine mère s’arrête, elle arrête aussi les coroutines filles. Ce système de hiérarchie n’existe pas dans les Threads classiques.
Enfin, les coroutines remplissent même le besoin de pouvoir être suspendues et reprises plus tard, ce qui n’est pas le cas des threads classiques . Sur le principe, une coroutine doit être liée à un Thread pour être exécutée, comme le montre le schéma suivant :

Dans cet exemple, on remarque que la première coroutine est lancée puis suspendue pour laisser place à la seconde coroutine, elle aussi suspendue. La première coroutine peut alors être reprise puis terminée. Mais dans les faits, une coroutine peut très bien démarrer dans un premier Thread, puis reprendre dans un autre, comme l’explique ce très bon article de Piotr Minkowski.
Le schéma suivant montre un exemple de cas d’utilisation dans lequel on peut contextualiser une coroutine dans une application Android :
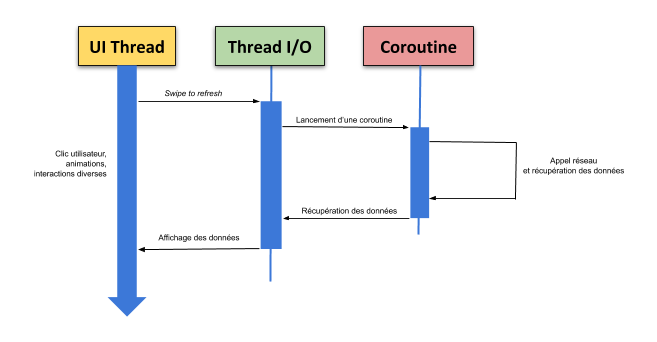
Dans un premier temps, l’utilisateur effectue un swipe to refresh (un mouvement de swipe vers le bas en partant du haut de l’écran, ce qui déclenche une action), ce qui lance une coroutine sur le Thread I/O. Cette coroutine effectue un appel réseau pour récupérer des données, qui sont ensuite envoyées et affichées sur l’interface utilisateur.
Pendant tout ce process de lancement de coroutine et d’appel réseau, l’utilisateur peut réaliser tout type d’interactions avec l’interface, sans bloquer l’application. Cela montre ainsi que la coroutine ne bloque pas le thread principal.
Si vous voulez plus d’informations au niveau performance entre Thread et coroutines, je vous conseille cet article de Gaurav Goyal.
De façon générale, on pourra illustrer les 3 modèles de développement avec le schéma suivant (la flèche représentant la ligne du temps) :
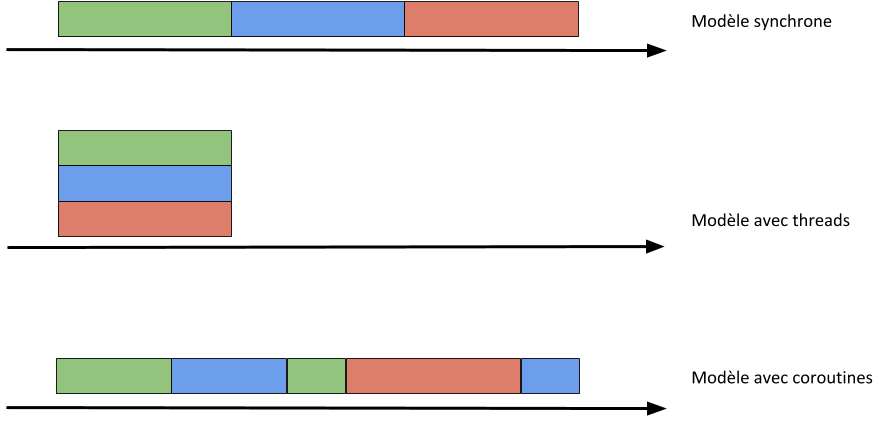
Dans le modèle synchrone, les 3 tâches ne peuvent être exécutées que les unes après les autres. Dans le second modèle, on peut les exécuter les unes en même temps que les autres et enfin, dans le modèle avec les coroutines, on peut lancer la première coroutine, puis la stopper pour lancer la seconde, stopper celle-ci pour terminer la première, lancer la 3e coroutine, et enfin terminer la seconde.
OK, mais du coup, c'est quoi Kotlin Flow ?
Pour rappel, le lien avec les coroutines est que cette librairie se base sur Kotlin Coroutines pour son utilisation. Elle est ainsi fournie par kotlinx.coroutines.flow.
Cette librairie est arrivée en version stable avec la version 1.3.0 de kotlinx.coroutines, fin août 2019.
Kotlin Flow s’appuie sur le principe des coroutines pour gérer des flux de données de façon asynchrone et réactive, et de manière séquentielle. On pourrait donc définir un Flow par une séquence de valeurs asynchrones et qui évoluent au fil du temps :

Un petit exemple pour illustrer
Sur le principe, on crée un Flow grâce à une première coroutine émettrice qui va donc émettre des données (en réalité, on appelle cela un Flow builder). On verra différents cas d’utilisation plus tard, mais dans un premier exemple, on pourra considérer que notre Flow émet une suite d’entiers de 1 à 4 :
fun emettreEntiers(): Flow<Int> = flow {
for (i in 1..4) {
emit(i)// Emission de l’entier
}
}
Et de l’autre côté, on pourra avoir une coroutine consommatrice qui va donc récupérer ces 4 entiers, un par un, et les afficher. On dit qu’elle consomme le Flow :
fun main() = runBlocking<Unit> {
// Consommation du flow grâce au collect
emettreEntiers().collect { value ->
println("Valeur consommée : $value")
}
}
On aura ainsi le résultat suivant :
Valeur consommée : 1
Valeur consommée : 2
Valeur consommée : 3
Valeur consommée : 4
Vous pouvez tester cet exemple ici.
Les opérateurs intermédiaires et terminaux
Vous aurez remarqué dans l’exemple précédent la présence du mot-clé collect. Il s’agit en fait d’un opérateur terminal, c’est-à-dire qu’il va déclencher la production de données, qu’on pourra, dans l’exemple, afficher. Dans les opérateurs terminaux, on pourra aussi retrouver single (qui permet d’attendre qu’une valeur en particulier soit émise), reduce (qui accumule toutes les valeurs d’un Flow pour les réduire en une seule valeur), toList (comme son nom l’indique, cet opérateur permet de transformer un Flow en une liste de données, un Flow d’entiers en liste d’entiers par exemple), etc.
Il est à préciser que les opérateurs terminaux sont soit des suspending functions (comme ceux que nous venons de voir), soit des opérateurs qui vont permettre de démarrer la collection de données dans un scope donnée (comme launchIn).
Mais on peut aussi utiliser des opérateurs intermédiaires, comme map ou filter pour les plus basiques. Il s’agit, au contraire des opérateurs terminaux, d’opérateurs qui ne vont pas déclencher la production de données. Ils vont simplement permettre de “manipuler” le Flow lorsqu’on l’utilisera avec un opérateur terminal.
Quelques caractéristiques et comparaison aux Channels
Flow est un flux froid, cela signifie que si aucune coroutine ne consomme les données d’un Flow, elles ne seront pas produites ni émises. Donc, tout simplement, si on n’appelle pas un Flow, aucune donnée ne sera produite. D’autre part, si un Flow n’est pas consommé, il n’utilisera absolument aucune ressource matérielle.
Il est d’ailleurs possible de consommer plusieurs fois un Flow (via plusieurs coroutines consommatrices), mais cela donnera lieu à une consommation unique, dans le sens où chaque coroutine consommatrice recevra potentiellement des données différentes puisque, pour rappel, le Flow sera produit à la demande, et ses données changent potentiellement au cours du temps.
Autrement dit, un Flow ne sera jamais produit et émis dans le vide, au contraire d’un Channel qui lui est un flux chaud et sert par exemple à partager des mêmes valeurs.
Si on devait retranscrire un Channel et un Flow dans la réalité, un exemple de Channel sera votre téléviseur : votre téléviseur et vous êtes la coroutine consommatrice, tandis que l’émission télé et les antennes émettrices sont la coroutine productrice, la Channel étant ainsi les ondes radio qui transportent l’information. Si vous éteignez votre télévision, l’émission télé ne s’arrêtera pas, et vous perdrez donc des informations émises.
Votre cafetière, quant à elle, est un bon exemple d’un Flow : elle est posée dans votre cuisine, prête à produire du café, mais tant que vous n’avez pas appuyé sur le bouton, elle ne consommera aucune ressource et ne produira pas de café. Et lorsque le café sera produit, elle s’arrêtera.
Un Channel se prêtera très bien à de la synchronisation de données, ou lorsque vous souhaitez utiliser des connexions entrantes, où vous ne maîtrisez pas la donnée, c’est-à-dire son type ou quand est-ce qu’elle arrivera, pour faire de la synchronisation d’agenda typiquement.
Enfin, Flow supporte la back pressure :
Un Channel, contrairement à Flow, va émettre des données même si elles ne sont pas consommées derrière. Donc par exemple si aucune coroutine n'écoute ces données, elles seront tout simplement perdues. D’autre part, un Channel émet continuellement des données de façon asynchrone sans connaître l’état du receveur. Et il peut arriver que ce receveur mette plus de temps à traiter les données, que le Channel à les envoyer. On peut alors rapidement arriver à un dépassement mémoire.Le principe de la back pressure est donc de temporiser la production des données (donc la production du Flow) en attendant que le receveur ait le temps de les traiter. Un receveur peut ainsi stopper temporairement la production d’un Flow si nécessaire. Cela permet ainsi de ne pas surcharger le receveur et de ne pas perdre de données.
Et dans une application Android ?
Maintenant que nous avons vu le fonctionnement de base d’un Flow, nous allons pouvoir voir son utilisation au sein d’une application Android.
Nous allons ici développer une app qui permet de récupérer la météo des villes de Nantes et de Paris. Nous récupérerons ces données grâce à la libraire Retrofit qui permet de réaliser des appels à des webservices REST, et nous utiliserons l’API Open Weather Map. Ces données seront stockées grâce à Room.
L’application est disponible à cette adresse, et possède l’interface suivante :
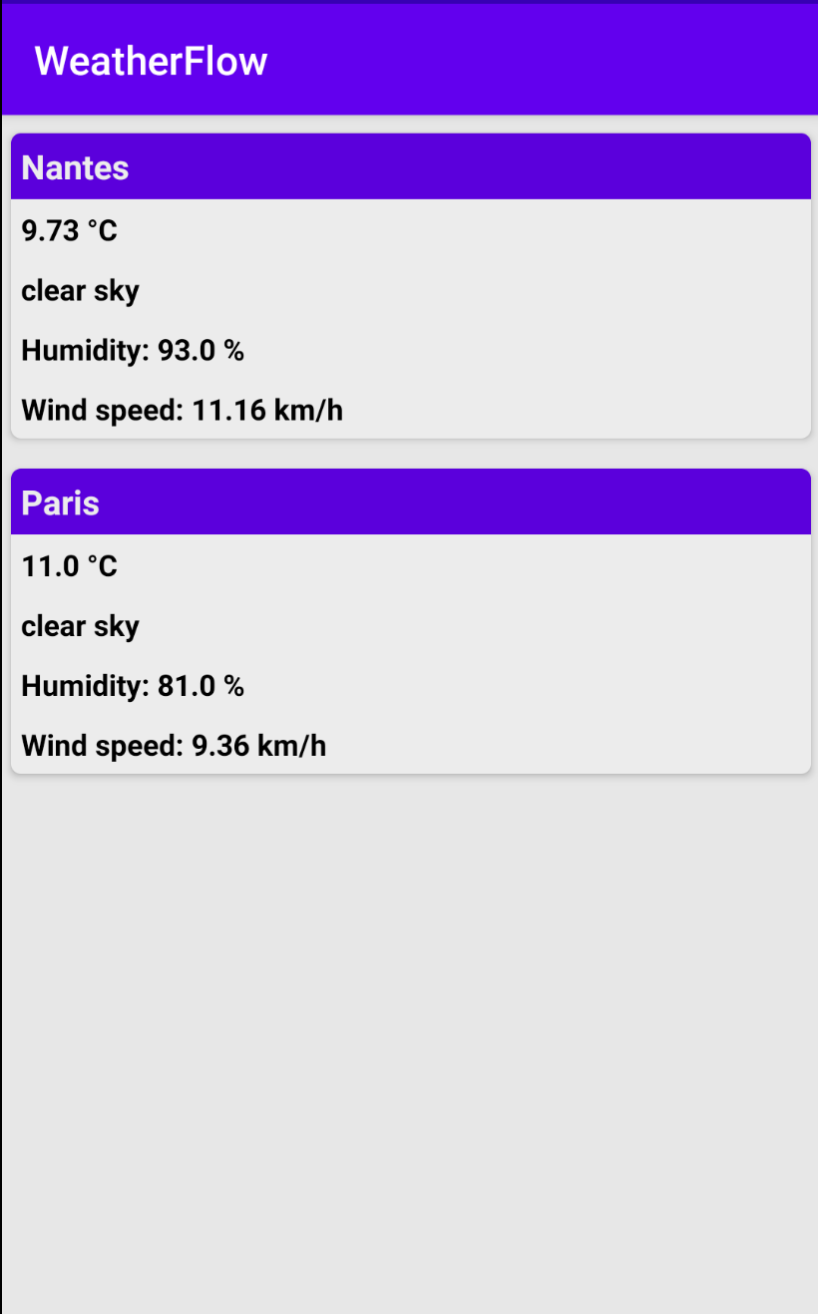
Présentation de l'application
Je vais ici vous présenter de façon assez globale l’application. Si vous souhaitez en savoir plus sur chacunes des briques techniques utilisées, elle est basée sur les Android Architecture Components.
L’application possède l’architecture suivante :

La View (MainActivity) affiche les données récupérées grâce au ViewModel. Celui-ci utilise pour cela un Repository qui permet d’ajouter une couche d’abstraction de la façon dont sont récupérées les données (en appelant l’API ou en les récupérant de la base de données). Enfin, les rectangles blancs représentent le type de donnée sous lequel les infos météorologiques seront acheminées jusqu’à la View.
L’application est composée des packages suivants :
- le package
api: nous allons retrouver tout ce qui concerne la partie récupération des données de l’API ainsi que le Deserializer, ce qui va permet de parser nos données vers notre objetCityWeather; - le package
db(database) : les éléments tels que notre objetCityWeatherainsi que le DAO ou encore la base de données, pour gérer les accès à la base locale SQLite ; - le package
di(dependency injection) : les éléments gérant l’injection de dépendance ; - le package
model: leCityWeatherViewModelpermet de récupérer les données et de rafraîchir la base de données en appelant l’API ; - le package
repository: la classeCityWeatherRepositorypermet de centraliser l’appel à l’API ainsi que le stockage des données dans la base SQLite ; - le package
ui(User Interface) : il regroupe laMainActivityainsi que leCityWeatherAdapterqui va permettre d’afficher les données dans la RecyclerView.
Et l'utilisation de Flow dans tout cela ?
Dans un premier temps, voici un schéma expliquant le cas d’utilisation de Flow dans l’application. Il s’agit du schéma repris plus tôt dans cet article mais avec quelques ajouts :
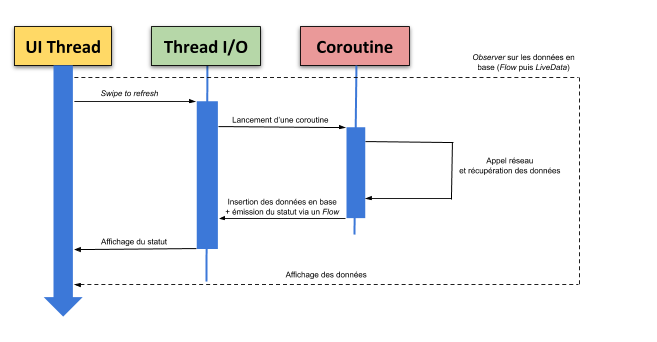
Une coroutine sera lancée via un swipe to refresh, et récupèrera les données météorologiques via un appel réseau. Elle utilisera un Flow afin d’émettre en temps réel le statut de la récupération des données (loading, success ou error). Une fois les données récupérées, elles seront insérées en base.
Pendant ce temps, les données insérées sont continuellement récupérées dans un Flow, transformé en LiveData pour être observé par la MainActivity qui les affichera.
Le fetch des données
Dans le fichier CityWeatherRepository.kt, nous avons ce bloc de code :
suspend fun refreshCityWeathers() = flow {
emit(Status.LOADING)
cityWeatherService
.getWeathers()
.fold(success = { response ->
emit(Status.SUCCESS)
cityWeatherDao.insertAll(response.data)
}, failure = {
emit(Status.ERROR)
})
}.flowOn(Dispatchers.IO)
Il s’agit d’un premier Flow qui va appeler le service getWeathers() (afin d’appeler l’API OpenWeather) et d’émettre un statut en fonction du résultat de la requête. Si la requête récupère bien des valeurs dans un JSON, ce dernier est désérialisé et inséré dans la base de données grâce au DAO. Ce Flow est exécuté à partir d’une coroutine présente dans CityWeatherViewModel, elle-même appelée dans le MainActivity via une coroutine. Enfin, on exécutera cette coroutine à chaque swipe refresh, c’est-à-dire à chaque fois qu’on glissera notre doigt en haut de l’écran, à la manière des apps Facebook ou encore Instragram. Le flowOn à la fin va permettre de définir sur quel contexte le Flow doit être exécuté. Nous choisissons ici de l'exécuter sur le thread I/O (pour In/Out).
La récupération des données par la MainActivity
Une fois nos données insérées en base, un second Flow va nous permettre d’écouter chaque mise à jour.
Pour cela, regardons d’abord l’appel du DAO dans le CityWeatherRepository.kt :
val cityWeathers = cityWeatherDao.getAll().flowOn(Dispatchers.IO)
Ici, le getAll() est au final une requête SQL faisant un SELECT * et qui retourne un objet de type Flow. Le résultat de cette requête va donc être envoyée dans le stream d’un second Flow, qui sera récupéré dans le CityWeatherViewModel grâce à ce bloc :
val cityWeathers: LiveData<Array<CityWeather>> = cityWeatherRepository.cityWeathers.asLiveData(Dispatchers.IO)
Ici, le asLiveData() va permettre, comme son nom l’indique, de transformer le Flow en LiveData, pour pouvoir ensuite être envoyé au MainActivity.
Enfin, dans le MainActivity, on pourra observer les changements de données du LiveData grâce à ce code :
this.cityWeatherViewModel.cityWeathers.observe(this, this.updateCityWeather)
L’updateCityWeather est un Observer, c’est-à-dire qu’il va s’exécuter à chaque changement d’une variable, en l'occurrence, le LiveData cityWeathers.
Ce second Flow présente tout son intérêt, dans le sens où, si à tout moment, on arrête de l’écouter, la mise à jour de l’UI ne se fera plus et le Flow n’utilisera plus de ressources. Ce n’est pas très parlant pour une petite application comme celle-ci, mais ça le sera pour des applications beaucoup plus conséquentes et avec plusieurs appels réseaux et plusieurs insertions et extractions en base de données.
Pour aller plus loin
Si vous lancez l’application en local, des premières données météorologiques seront récupérées et affichées.
Dans Android Studio, grâce au Database Inspector, vous pouvez voir et même modifier les données de la base Room. Vous devez au préalable avoir votre Android Studio à jour, et l’inspecteur est accessible via un onglet en bas de l’IDE :

Si vous modifiez une des données de la base, l’UI est automatiquement mise à jour. Et si vous swipez en haut de l’écran… Magie ! D’autres données apparaissent suite à un second appel réseau. Si vous cochez Live updates dans l’inspecteur, vous verrez alors les nouvelles valeurs.
Cela montre que le Flow est constamment réceptionné par le MainActivity.
Conclusion
Cet article a pour but de vous familiariser avec la notion de Flow au travers d’exemples et d’une app de démo.
Cette nouvelle librairie nous ouvre beaucoup de possibilités quant à la programmation réactive, notamment dans le monde Android, car elle permet de limiter l’utilisation des ressources matérielles, tout en conservant des interfaces utilisateurs réactives et performantes. Toujours du fait que c’est un flux froid, elle permet d’éviter les pertes de données comme ça peut être le cas avec les Channels.
Toutefois, il ne faut pas considérer Flow comme un concurrent à Channel. Ce dernier conserve tout son intérêt pour des utilisations telles qu’un modèle événementiel où la production de données n’est pas maîtrisée par le développeur, ou lorsque les données existent sans une demande de l’application (connexions réseaux, flux d’événements, etc.). Enfin, Channel garde aussi son intérêt pour la concurrence et la synchronisation, ce qui n’est pas possible avec Flow.
Finalement, Flow est une façon plus simple mais plus restreinte de gérer des flux asynchrones.
D’autre part, la compatibilité avec des librairies comme LiveData, Room ou encore Paging 3 (en alpha à l’heure où j’écris cet article), promet un bel avenir à Flow. A cela s’ajoutent les StateFlow et SharedFlow, ajoutés dans la version 1.4 de Kotlin, que je vous laisserai découvrir… ;-)
Sources
- Kotlin Flows and Coroutines :
https://medium.com/@elizarov/kotlin-flows-and-coroutines-256260fb3bdb - Understand Kotlin Coroutines on Android (Google I/O'19) :
https://www.youtube.com/watch?v=BOHK_w09pVA - LiveData with Coroutines and Flow :
https://www.youtube.com/watch?v=B8ppnjGPAGE - Kotlin Flow for Android: Getting Started :
https://www.raywenderlich.com/9799571-kotlin-flow-for-android-getting-started - La documentation sur les coroutines :
https://developer.android.com/kotlin/coroutines - La documentation sur Flow :
https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/-flow/ - La documentation sur flowOn :
https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/flow-on.html
Un très grand merci à Thomas BOUTIN pour sa participation au développement de l’appli !
