
Aujourd'hui, avec la popularité grandissante du Serverless, nous voyons de plus en plus d'applications complexes et distribuées reliant de multiples services. Pouvoir orchestrer et faire communiquer entre eux ces différents services devient une réelle problématique.
Dans le cadre d’une mission, j’ai pu mettre en œuvre des workflows Step Functions qui ont permis de fournir une solution à certaines de nos problématiques, comme le fait de pouvoir enchaîner ou paralléliser de nombreux traitements, chacun se basant sur le résultat du traitement précédent, le tout en gérant proprement les cas d’erreur.
Cet article a pour objectif de vous présenter le service et de vous en donner une connaissance générale, tout en vous présentant quelques cas d’utilisation concrets.
Introduction
Apparu le 1er Décembre 2016, AWS Step Functions est un orchestrateur Serverless de services AWS. Il est en passe de devenir un incontournable pour les architectes Cloud. En effet, comme nous allons le voir dans cet article, l’utilisation de Step Functions peut simplifier de manière significative des tâches d’orchestration qui n’étaient pas forcément triviales auparavant.
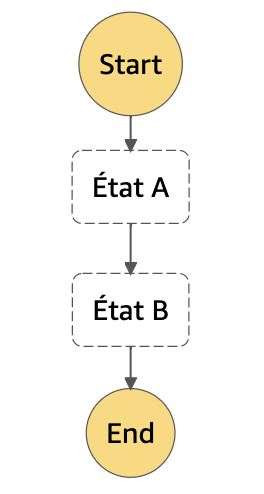
Le service repose sur des machines à états dont les deux composants sont les états, et les transitions entre ces états.
Voici ci-dessous une machine avec deux états : État A et État B, avec une transition sans condition entre les deux. On passe de A à B lorsque l’état A aura terminé son traitement. Les états Start et End marquent le début et la fin du workflow.
Pour qui ? Dans quels cas ?
Step Functions s’intègre avec un grand nombre de services AWS dont voici les principaux :
Exécution de tâche :
- Invocation de fonctions Lambda
- Traitement de jobs AWS Batch
- Traitement de jobs Glue
- Traitement d’une tâche dans un Amazon Elastic Container Service (ECS)
- Requête sous Athena depuis peu, ainsi qu’une intégration à API Gateway
Base de données :
- Insérer ou récupérer un objet dans Amazon DynamoDB
Messages et notifications :
- Publication sur un topic Amazon SNS
- Envoi d’un message dans Amazon SQS
Invocation d’un autre workflow Step Functions*
* Un use case très intéressant pour découpler encore plus votre logique et simplifier au maximum vos workflows tout en les rendant réutilisables en utilisant des variables
De plus, l’utilisation de Lambdas permet d’étendre le scope d’action des Step Functions, à condition d’écrire son propre connecteur.
Comme tout service, Step Functions présente des avantages et des inconvénients, dont voici les principaux que j’ai pu relever.
Pour ce qui est des avantages :
- Serverless : Nous pouvons profiter d’une architecture 100% Serverless.
- Rendu visuel : On dispose d’un rendu graphique de la machine à états du workflow Step Functions. Il est assez intuitif et vous pouvez même le présenter à vos clients sans entrer dans les détails techniques de l’implémentation d’un état afin qu’ils aient une vue d’ensemble de ce qu’il se passe dans votre workflow.
- Traitement des erreurs : En cas d'erreur, Step Functions identifie directement l’étape incriminée (par exemple pour une Lambda, un lien direct vers les logs AWS CloudWatch est généré), un réel avantage lors de l'exécution d’un workflow complexe.
- Création de séquences de tâches complexes : Il est facile d’implémenter des comportements tels que le Retry ou le Catch d’une erreur, qui sont gérés par la machine à états, on peut donc laisser nos composants inchangés.
- Parallélisation : Vous pouvez paralléliser vos tâches et ainsi obtenir de meilleures performances, tout en ayant un comportement bien plus facile à déboguer et anticiper. Vous pouvez voir en temps réel l’état des tâches.
- Découplage : Permet de séparer la logique propre au workflow de l’application et la business logic afin de garder des composants les plus clairs et réutilisables possible (on évite donc par exemple les Lambdas qui appellent un autre service AWS à la fin de leur exécution…).
Les inconvénients d’AWS Step Functions :
- Syntaxe : Un workflow Step Functions est écrit en JSON. Cela peut rendre le code difficile à maintenir et faire évoluer à partir d’un certain nombre d’états. En effet, le JSON d’un workflow avec plusieurs branches et un grand nombre d’états sera difficile à lire et à faire évoluer. A noter cependant que le SDK Python permet de rendre cette tâche plus accessible.
- Découplage : Bien que cela permet de rendre les composants réutilisables et scalables, cela peut également rendre le code plus difficile à comprendre pour quelqu’un d’extérieur, qui devra faire le lien avec la logique implémentée dans Step Functions.
- Limitations dans l’utilisation des variables : Dans certains cas, je me suis confronté à des limitations avec le passage de variables dans un workflow (impossible par exemple de passer certains arguments à un job Glue comme vous allez le voir plus tard dans l’article). De plus, imaginons un état C qui a besoin d’une variable contenue dans un état A, il faudra que A passe cette variable à un état B qui n’en a pas besoin et donc créer un couplage inutile, ou alors passer par un service externe comme un ParameterStore.
À noter que le pricing de Step Functions est de 4000 utilisations gratuites par mois, et 0,025 USD pour 1000 transitions d’état au-delà). Il ne faut donc pas se priver de ce service si son utilisation peut faire sens dans votre projet, mais il faut anticiper son coût pour une utilisation dans une application web à grande échelle dans laquelle le workflow serait appelé à chaque upload d’une image par un utilisateur par exemple.
Fonctionnement de Step Functions
Il y a plusieurs notions à connaître avant d’utiliser des Step Functions. Dans cette partie, je vais vous fournir les bases afin de vous permettre de construire votre propre workflow ou simplement de comprendre un workflow en place.
Les états Task, Choice, Parallel...
Les états d’un workflow Step Functions se déclinent sous forme de différents types. Nous retrouvons donc par exemple :
- Le type Task : Il s’agit d’un état qui permet d’effectuer une tâche, comme invoquer une Lambda, un job Glue...
- Le type Pass : Permet de passer l’input à l’output sans effectuer de traitements, utile à des fins de débogage par exemple.
- Le type Choice : Divise le workflow en plusieurs branches et permet de définir la branche à choisir selon une condition.
- Le type Parallel : Comme son nom l’indique, il permet d’exécuter plusieurs états en parallèle. A noter cependant qu’on ne passera à l’état suivant que lorsque toutes les tâches effectuées en parallèle seront terminées.
- Les types Succeed et Fail qui permettent de déclarer le succès ou l’échec d’un workflow.
De plus, on peut ajouter le champ Catch dans la majorité des états, afin de définir le comportement attendu en cas d’erreur (on peut catch une seule erreur ou la totalité des erreurs possibles). Dans le champ Catch, nous pouvons ensuite faire un Retry pour tenter une nouvelle exécution de l’état ou passer à un nouvel état qui peut par exemple envoyer un email informant de l’échec.
Le sélecteur
L’élément de base pour manipuler des variables. Il permet de choisir une partie ou la totalité d’un élément. Sa valeur de base est $ et signifie que l’on souhaite tout sélectionner.
Soit l’input suivant pour un état :
{
"comment": "Example for InputPath.",
"elem1": {
"val1": 1,
"val2": 2,
"val3": 3
},
"elem2": {
"val1": "a",
"val2": "b",
"val3": "c"
}
}
Le sélecteur $ renverrait donc tout l’input. Cependant, on peut également spécifier une portion de l’élément, en utilisant par exemple le sélecteur $.elem1 qui renvoie :
{
"val1": 1,
"val2": 2,
"val3": 3
}
InputPath, OutputPath, ResultPath…
Lors de l’exécution d’un workflow, vous avez la possibilité de passer du JSON en input à destination du premier état. Ensuite, l’information circule entre chaque état en utilisant :
L’InputPath : L’input d’un état. Pour le premier état, il correspond au JSON que vous fournissez lors de l’exécution du workflow, ensuite, ce sera l’output de l’état précédent, passé par l’OutputPath.
L’OutputPath : L’output d’un état. Il correspond au JSON que vous allez transmettre à l’état suivant (et qui sera donc disponible dans son InputPath). Vous pouvez par exemple l’utiliser pour filtrer ce que vous passez vers un autre état.
Le ResultPath : Pour les états de type Task, il correspond au path sur lequel écrire le résultat du traitement. Définir "ResultPath": "$" écrasera donc complètement l’input reçu par l’état et passera seulement à l’état suivant le résultat retourné par la tâche (une Lambda par exemple). Si vous définissez "ResultPath": "$.lambda_result" vous allez ajouter un champ lambda_result à l’input reçu par l’état et le passer à l’état suivant (ou surcharger celui déjà présent dans l’Input si un champ porte le même nom).
Passage de variables
Vous pouvez passer des paramètres dans un état en utilisant le champ Parameters.
Notez que si un paramètre utilise une variable contenue dans son InputPath, son nom doit finir par .$, on aura par exemple :
"Parameters": {
"comment": "Passing some variables that I care about.",
"MyObject": {
"name.$": "$.name",
"age.$": "$.age",
"staticVariable": "a static value"
}
}
Petite limitation sur ce point, comme je l’ai évoqué précédemment dans les inconvénients de Step Functions, pour un job Glue, les variables se passent cette fois dans un champ Arguments et il n’est donc pas possible d’utiliser une variable provenant du path comme réalisé ci-dessus. J’obtenais sous Glue le nom de la variable (par exemple $.name) au lieu d’obtenir sa valeur.
Maintenant que vous avez toutes les cartes en main, je vais vous présenter quelques cas d’utilisations de Step Functions, ainsi que leur implémentation afin de comprendre par l’exemple la puissance de ce service.
Le chef d'orchestre entre en action
Pour chaque exemple, notez que vous devrez accorder à votre workflow Step Functions les permissions IAM nécessaires pour accéder aux différentes ressources mises en jeu (invocation de Lambda, publication sur un topic SNS, exécution de job Glue…).
Ensuite, vous pouvez démarrer un workflow manuellement, en utilisant un évènement CloudWatch pour le lancer périodiquement, ou encore en utilisant boto3.
1. Attendre la fin d’un traitement pour en effectuer un autre. Le workflow “classique” sous Step Functions.
Imaginez un job Glue qui doit peupler le catalogue, une Lambda qui doit effectuer une requête Athena une fois le catalogue rempli, et, soyons fou, envoyer une notification à votre client avec le résultat de la requête : rien de plus simple avec Step Functions !
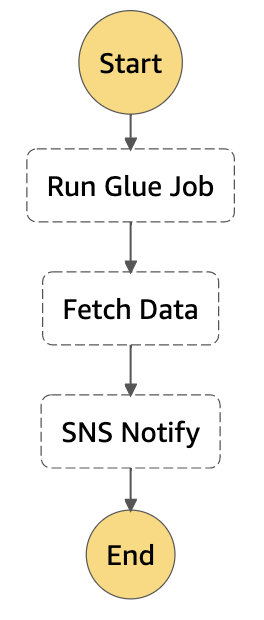
{
"StartAt": "Run Glue Job",
"States": {
"Run Glue Job": {
"Type": "Task",
"Resource": "arn:aws:states:::glue:startJobRun.sync",
"Parameters": {
"JobName": "GLUE_JOB_NAME"
},
"Next": "Fetch Data"
},
"Fetch Data": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:function:FUNCTION_NAME",
"ResultPath": "$.data.lambdaresult",
"OutputPath": "$.data",
"Next": "SNS Notify"
},
"SNS Notify": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"TopicArn": "TOPIC_ARN",
"Subject": "[SQL QUERY]: Here's your query result",
"Message.$": "$.data.lambdaresult"
},
"End": true
}
}
}
On utilise ici 3 états de type Task pour chacun des services, vous noterez l’utilisation du path pour le passage des résultats entre l’état qui invoque la Lambda et l’état qui publie sur SNS.
2. Capturer l’erreur lors d’un traitement et avertir mon client ? Pas de problème.
Ajoutons maintenant un catch au composant qui exécute le job Glue afin de notifier notre client par mail de l’échec de l’exécution.
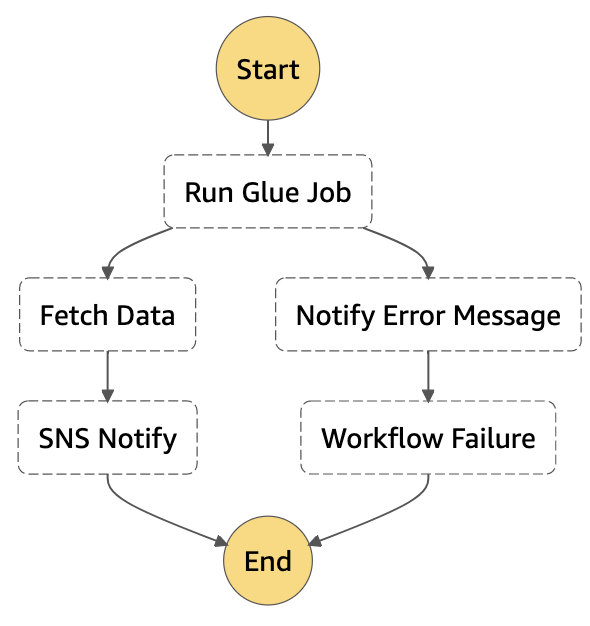
{
"StartAt": "Run Glue Job",
"States": {
"Run Glue Job": {
"Type": "Task",
"Resource": "arn:aws:states:::glue:startJobRun.sync",
"Parameters": {
"JobName": "GLUE_JOB_NAME"
},
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.error",
"Next": "Notify Error Message"
}
],
"Next": "Fetch Data"
},
"Fetch Data": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:function:FUNCTION_NAME",
"ResultPath": "$.data.lambdaresult",
"OutputPath": "$.data",
"Next": "SNS Notify"
},
"SNS Notify": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"TopicArn": "TOPIC_ARN",
"Subject": "[SQL QUERY]: Here's your query result",
"Message.$": "$.data.lambdaresult"
},
"End": true
},
"Notify Error Message": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"TopicArn": "TOPIC_ARN",
"Subject": "[ERROR]: Step Functions workflow failed",
"Message.$": "$.error"
},
"Next": "Workflow Failure"
},
"Workflow Failure": {
"Type": "Fail"
}
}
}
Nous avons ici ajouté un Catch dans l’état qui exécute le job Glue afin de lui indiquer quoi faire en cas d’erreur. On utilise States.ALL pour gérer toutes les erreurs, mais on peut aussi le faire de manière plus fine. Notez également qu’à la fin on ajoute un état de type Fail pour indiquer l’échec du workflow (autrement, le workflow aurait envoyé le message d’erreur sur le topic SNS, mais le workflow aurait terminé avec le statut succeeded, ce qui n’est pas le comportement attendu).
3. Lancer un job A ou un job B en fonction du résultat d’un traitement précédent ? Chef, oui chef !
Pour finir, imaginons que notre client nous demande de lancer un job Glue différent selon le résultat renvoyé par une Lambda de configuration. Nous allons ici mettre en œuvre une tâche de type Choice qui utilisera le résultat de la Lambda pour décider de l’état vers lequel aller.
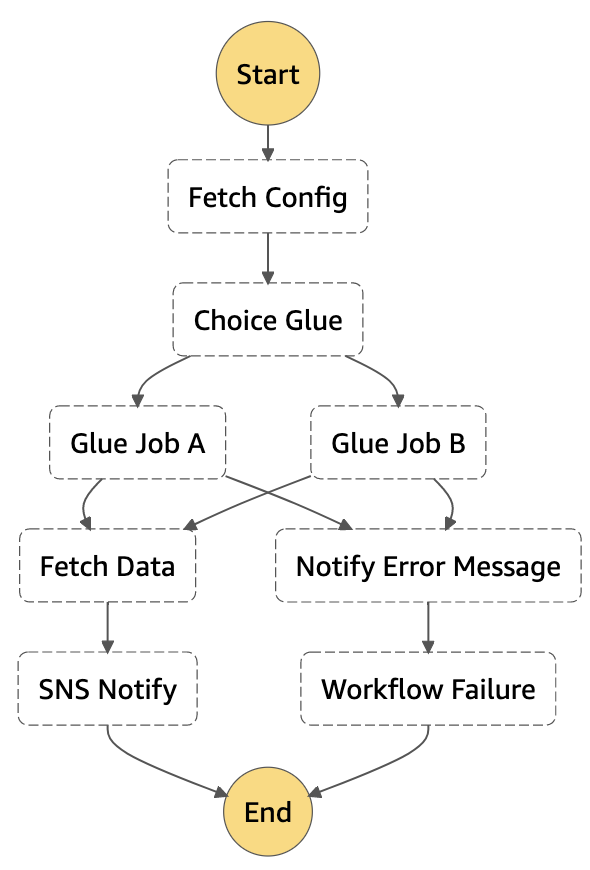
{
"StartAt": "Fetch Config",
"States": {
"Fetch Config": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:function:FUNCTION_NAME",
"ResultPath": "$.data.configuration",
"OutputPath": "$.data",
"Next": "Choice Glue"
},
"Choice Glue": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.configuration",
"StringEquals": "Choice A",
"Next": "Glue Job A"
},
{
"Variable": "$.configuration",
"StringEquals": "Choice B",
"Next": "Glue Job B"
}
],
"Default": "Glue Job A"
},
"Glue Job A": {
"Type": "Task",
"Resource": "arn:aws:states:::glue:startJobRun.sync",
"Parameters": {
"JobName": "GLUE_JOB_A_NAME"
},
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.error",
"Next": "Notify Error Message"
}
],
"Next": "Fetch Data"
},
"Glue Job B": {
"Type": "Task",
"Resource": "arn:aws:states:::glue:startJobRun.sync",
"Parameters": {
"JobName": "GLUE_JOB_B_NAME"
},
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.error",
"Next": "Notify Error Message"
}
],
"Next": "Fetch Data"
},
"Fetch Data": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:function:FUNCTION_NAME",
"ResultPath": "$.data.lambdaresult",
"OutputPath": "$.data",
"Next": "SNS Notify"
},
"SNS Notify": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"TopicArn": "TOPIC_ARN",
"Subject": "[SQL QUERY]: Here's your query result",
"Message.$": "$.data.lambdaresult"
},
"End": true
},
"Notify Error Message": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"TopicArn": "TOPIC_ARN",
"Subject": "[ERROR]: Step Functions workflow failed",
"Message.$": "$.error"
},
"Next": "Workflow Failure"
},
"Workflow Failure": {
"Type": "Fail"
}
}
}
Ici, nous avons donc utilisé un composant de type Choice et ajouté un état correspondant aux choix possibles. De plus, nous avons défini le job Glue A comme étant l’état Default, il sera choisi en cas de non correspondance de la configuration reçue par la Lambda.
Nous avons donc vu par l’exemple comment répondre à plusieurs cas d’utilisation que vous pouvez rencontrer en mission et comment incrémentalement faire évoluer un workflow sans avoir à modifier le comportement intrinsèque de nos composants (nous n’avons pas modifié les Lambdas, les jobs Glue ni le topic SNS).
Conclusion
Bien qu’assez récent parmi les services AWS, Step Functions reste très complet et permet de simplifier et d’améliorer les architectures Serverless. Sa grande force réside dans la simplicité de sa mise en place et son efficacité pour traiter de manière simple et efficace différents cas d’usage sans modifier le comportement des composants mis en jeu.
Bien évidemment il existe des alternatives à AWS Step Functions comme par exemple : Azure Logic Apps, Apache Airflow sur lequel se base le service de GCP Cloud Composer, GCP propose également workflow, un service en bêta actuellement, Prefect, Luigi ou enfin Dagster dont le code source est disponible sur GitHub.
J’espère que cet article vous aura permis de découvrir ou d'approfondir vos connaissances sur ce service et qu’il vous donnera envie d’expérimenter afin de découvrir toutes les possibilités qu’il peut vous offrir.
