

Les modèles d'apprentissage automatique (ML) créés par des Data Scientists représentent une petite fraction des composants qui composent un flux de déploiement en production pour une entreprise.
Pour opérationnaliser les modèles de ML, les Data Scientists doivent travailler en étroite collaboration avec plusieurs autres équipes, telles que les Business Dev et les opérations. Cela représente des défis organisationnels en termes de communication, de collaboration et de coordination. L'objectif du MLOps est de rationaliser ces défis avec des pratiques bien établies. De plus, MLOps apporte une agilité et une vitesse qui sont la pierre angulaire du monde numérique d’aujourd’hui.
Le MLOps permet aux Data Scientists de se concentrer sur la modélisation et l’analyse statistique, facilite l’échange entre les Data Scientists et les autres équipes, donne la possibilité d’avancer vite sur les projets de manière flexible et scalable.
Aujourd’hui je vais vous parler d’une nouvelle solution très utile et très importante, lancée par AWS lors de re:nvent 2020, il s’agit du StageMaker Pipelines.
Amazon SageMaker Pipelines
Amazon SageMaker Pipelines est un service “continuous integration and continuous delivery (CI/CD)” spécialement conçu pour l'apprentissage automatique (ML). Avec SageMaker Pipelines, vous pouvez créer, automatiser et gérer des flux de travail ML de bout en bout à grande échelle.
L'orchestration des workflows à chaque étape du processus d'apprentissage automatique (par exemple, l'exploration et la préparation de données, l'expérimentation de différents algorithmes et paramètres, l'entraînement et le tuning de modèles et le déploiement de modèles en production) peut prendre des mois de développement.
Comme il est spécialement conçu pour l'apprentissage automatique, SageMaker Pipelines vous aide à automatiser différentes étapes du flux de travail ML, y compris le chargement des données, la transformation des données, l'entraînement et le tuning, et le déploiement. Avec SageMaker Pipelines, vous pouvez créer des dizaines de modèles de ML par semaine, gérer des volumes massifs de données, des milliers d'expériences d'entraînement et des centaines de versions de modèles différentes. Vous pouvez partager et réutiliser des workflows pour créer ou optimiser des modèles, vous aidant ainsi à faire évoluer le ML dans toute votre organisation.
Composer, gérer et réutiliser des workflows ML
À l'aide d'Amazon SageMaker Pipelines, vous pouvez créer des workflow ML avec un SDK Python facile à utiliser, puis visualiser et gérer votre flux de travail à l'aide d'Amazon SageMaker Studio. Vous pouvez être plus efficace et évoluer plus rapidement en stockant et en utilisant les étapes du flux de travail que vous créez dans SageMaker Pipelines. Vous pouvez également démarrer rapidement avec des modèles intégrés pour créer, tester, enregistrer et déployer des modèles afin de pouvoir vous familiariser rapidement avec CI/ CD dans votre environnement ML.
Choisir les meilleurs modèles pour le déploiement en production
De nombreuses entreprises ont des centaines de workflows, chacun avec une version différente du même modèle. Avec le registre de modèles SageMaker Pipelines, vous pouvez suivre ces versions dans un référentiel central où il est facile de choisir le bon modèle pour le déploiement en fonction de vos besoins métier. Vous pouvez utiliser SageMaker Studio pour parcourir et découvrir des modèles, ou vous pouvez y accéder via le SDK SageMaker Python.
Suivi automatique des modèles
Amazon SageMaker Pipelines enregistre chaque étape de votre workflow, créant une piste d'audit des composants du modèle tels que les données d'entraînement, les configurations de plate-forme, les paramètres de modèle et les gradients d'apprentissage. Les pistes d'audit peuvent être utilisées pour recréer des modèles et aider à prendre en charge les exigences de conformité.
Apporter la CI/CD au ML
Amazon SageMaker Pipelines apporte des pratiques CI/CD à l'apprentissage automatique, tels que le maintien de la parité entre les environnements de développement et de production, le contrôle de version, les tests à la demande et l'automatisation de bout en bout, en vous aidant ainsi à faire évoluer le ML dans toute votre organisation.
Ce service peut être utile pour les Data Scientists, ainsi que pour les DevOps qui se chargent de l’industrialisation des workflow ML.
La suite de notre article consiste en une prise en main rapide de ce service, afin de vous donner une première vision de ce que cela apporte et comment on peut créer un pipeline end to end avec ce service.
Prise en Main
Créer un projet
Pour commencer on va aller à l’onglet “Launcher” pour créer un nouveau projet :
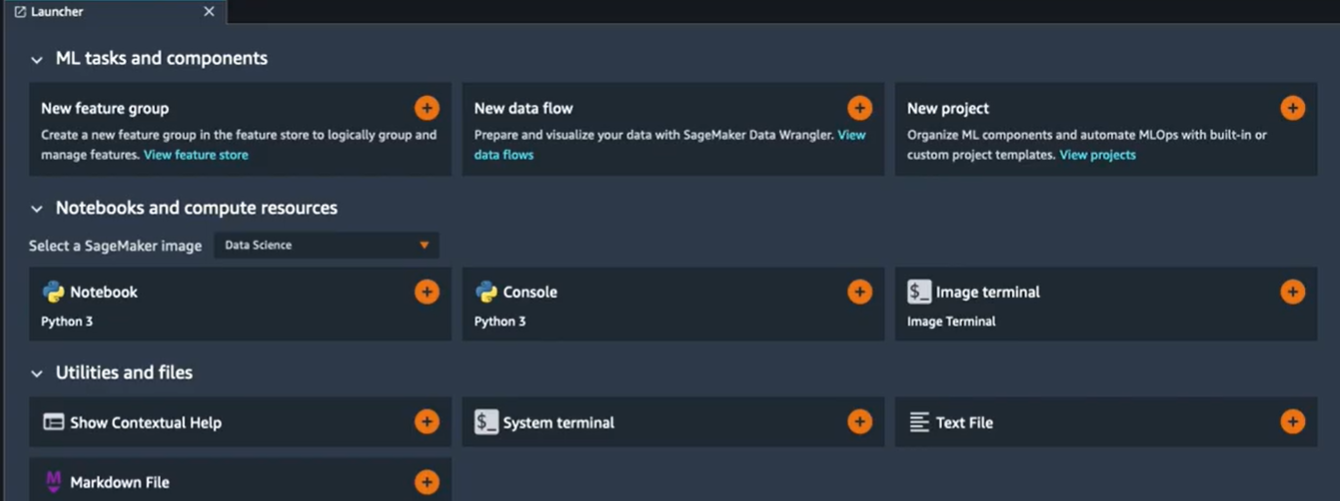
Quand vous créez un nouveau projet, vous arrivez sur une nouvelle interface avec des templates SageMaker proposés pour vous et prêts à être utilisés. Vous pouvez aussi utiliser votre propre template une fois que vous aurez créé vos propres pipelines.
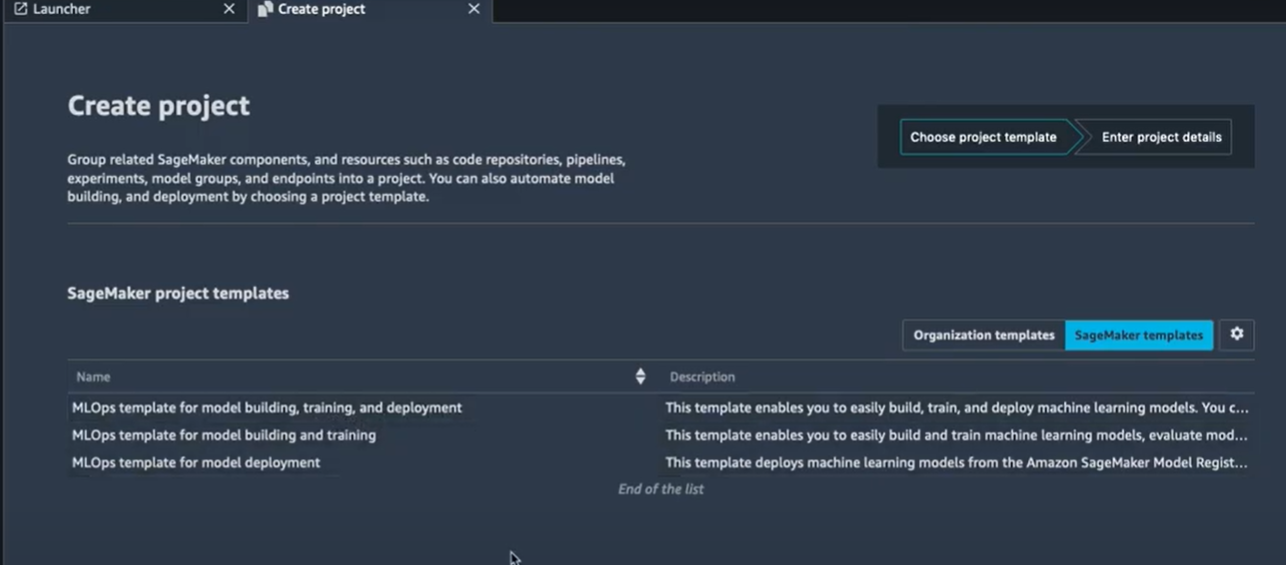
Comme vous pouvez le voir, on a trois templates à utiliser, on va donc utiliser le premier template pour créer un nouveau projet. C’est un template qui va nous permettre de créer, entraîner et déployer un modèle d’apprentissage automatique.
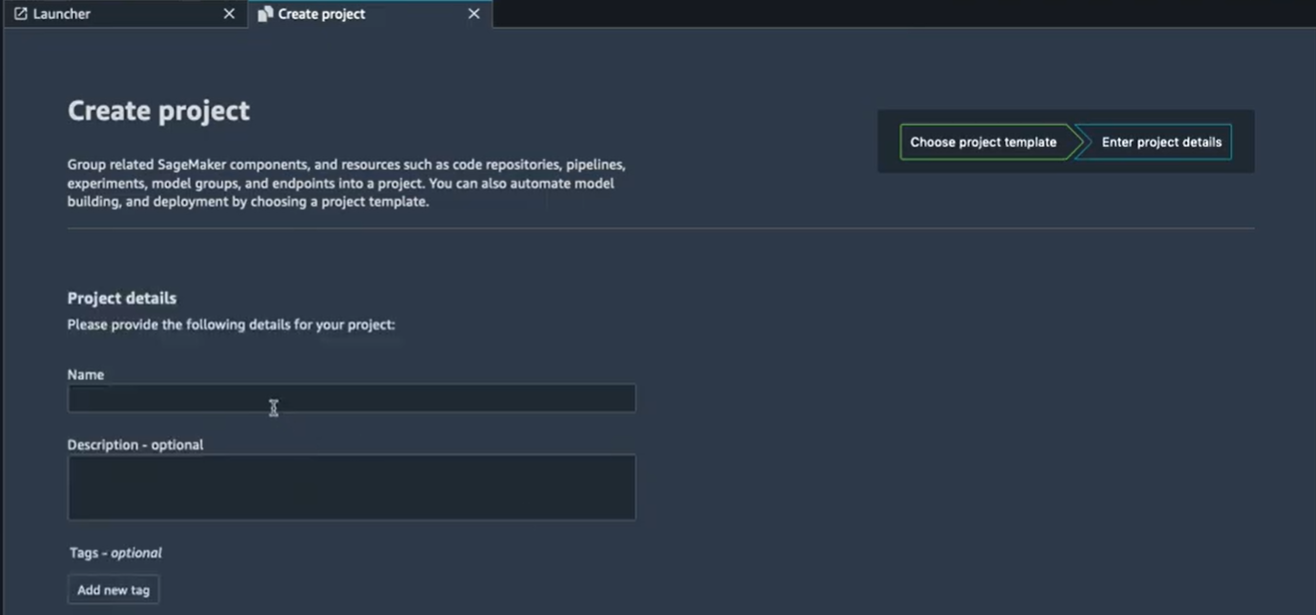
Une fois que le template est sélectionné, on donne un nom au projet (voir l’image suivante) et on attend la création du projet avec le pipeline en question.
Après quelques minutes d’attente, on va avoir un projet créé :
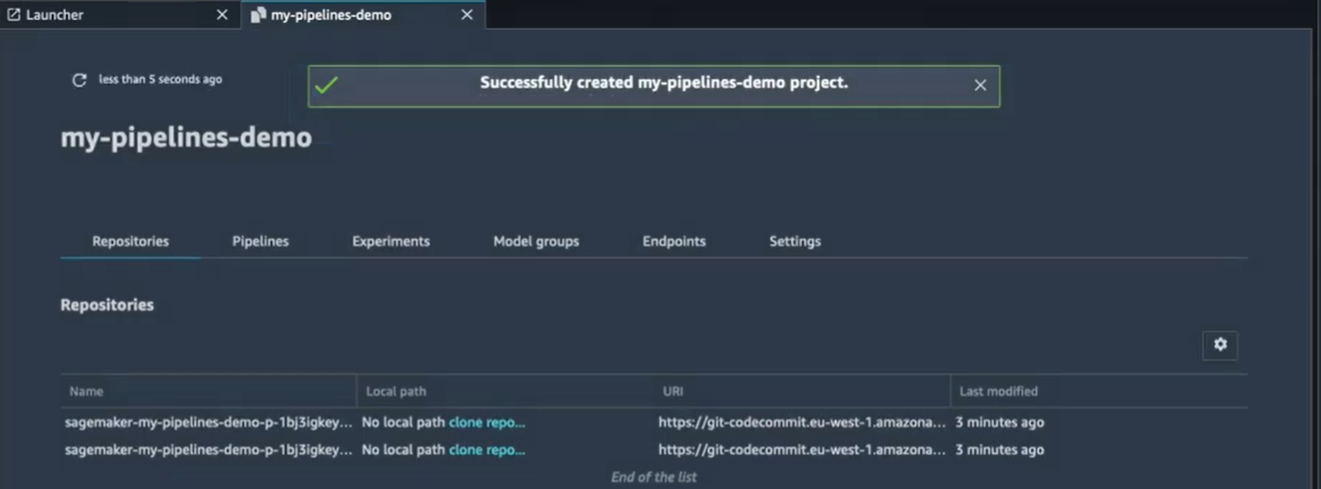
Comme vous pouvez voir dans le projet on a plusieurs onglets, à savoir:
- Repositories,
- Pipelines,
- Experiments,
- Model groups,
- Endpoints,
- Settings.
Les répertoires Build et Deploy
Dans l’exemple on peut voir deux répertoires avec leurs liens git (les commits). Pour utiliser les deux répertoires, on va devoir les cloner en local. Il suffit donc de cliquer sur le bouton “clone repo”.
Le pipeline de la création d’un modèle
- Un premier répertoire sur la création du modèle :
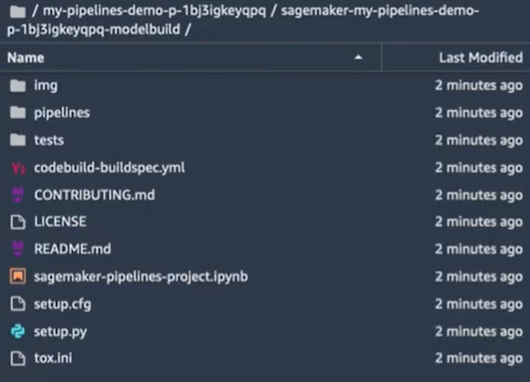
Il contient tous les artefacts dont on a besoin pour créer les pipelines des modèles avec les différentes étapes, les exécuter de façon automatique et enregistrer le modèle entraîné une fois que l’entraînement est terminé. On a donc un notebook Jupyter (sagemaker-pipelines-project.ipynb) qui montre les différentes étapes nécessaires pour créer ce pipeline, un code exemple et un projet exemple sont inclus comme un template avec les

fichiers nécessaires à la création du pipeline. Pour vérifier le code du pipeline et voir comment on peut créer un pipeline, on va ouvrir le fichier Pipeline/abalone/pipeline.py.
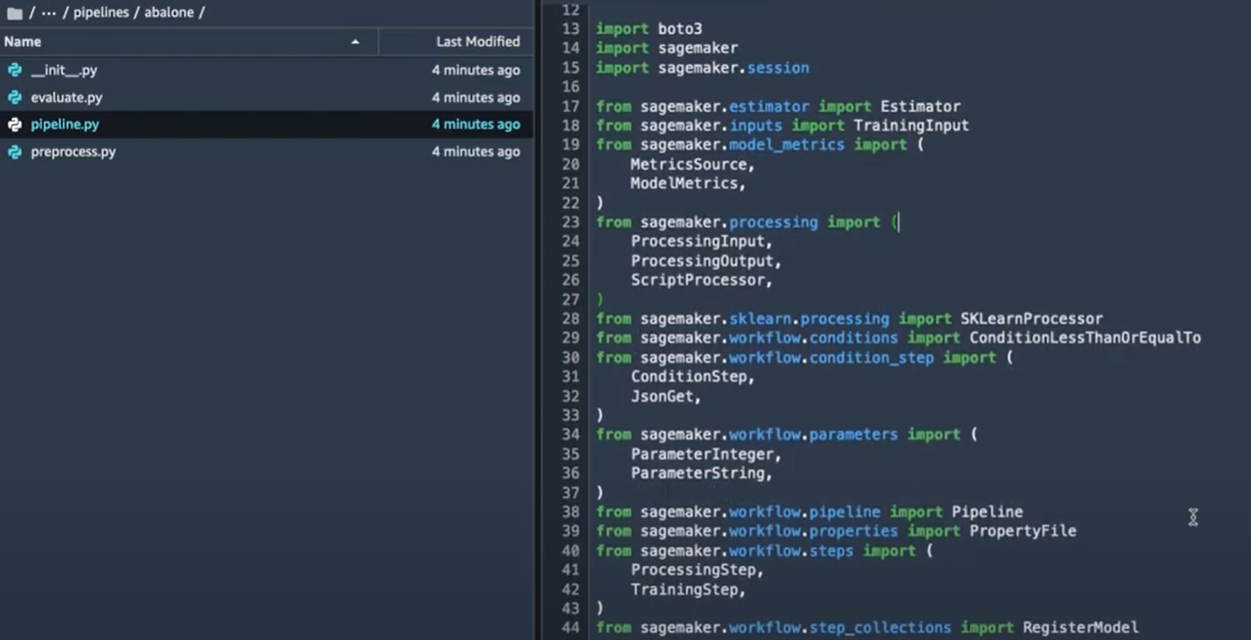
Un pipeline est composé des étapes (comme les step functions). Il faut donc définir chaque étape et puis enchaîner les étapes dans l’ordre pour créer le workflow souhaité.
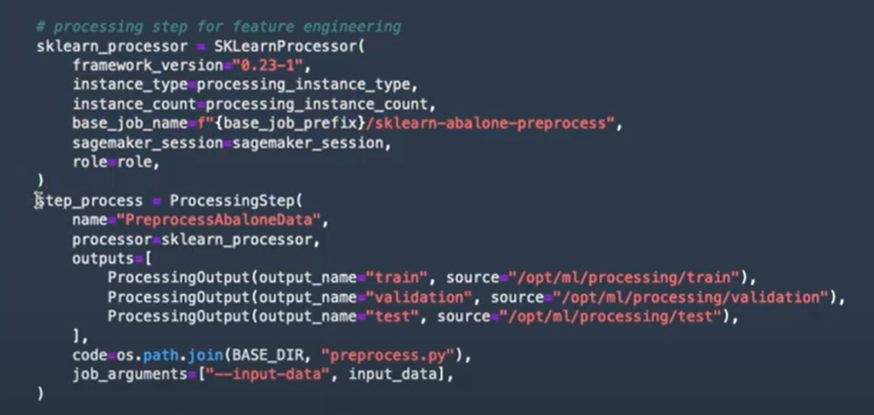
On peut voir, par exemple sur l’image ci-dessous, qu’on va avoir une première étape de preprocessing à l’aide d’un constructeur sklearn. Cela va nous permettre d’utiliser un fichier Python avec les différentes étapes de preprocessing qu’on souhaite appliquer sur le jeu de données, et puis créer un modèle de preprocessing dans SageMaker.
La deuxième étape va consister à entraîner un modèle de prédiction (Xgboost ici dans cet exemple) :
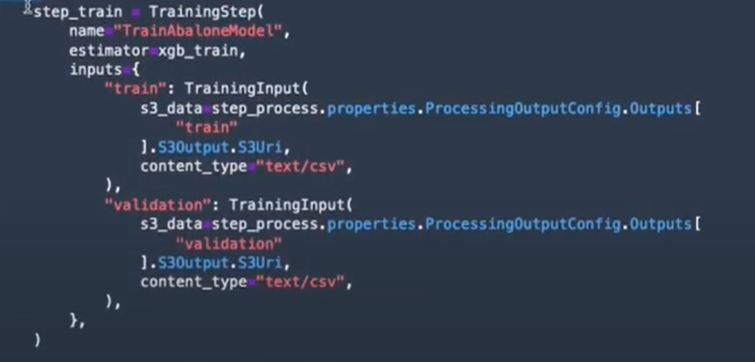
La troisième étape consiste à utiliser un autre script de processing pour l’évaluation des modèles :
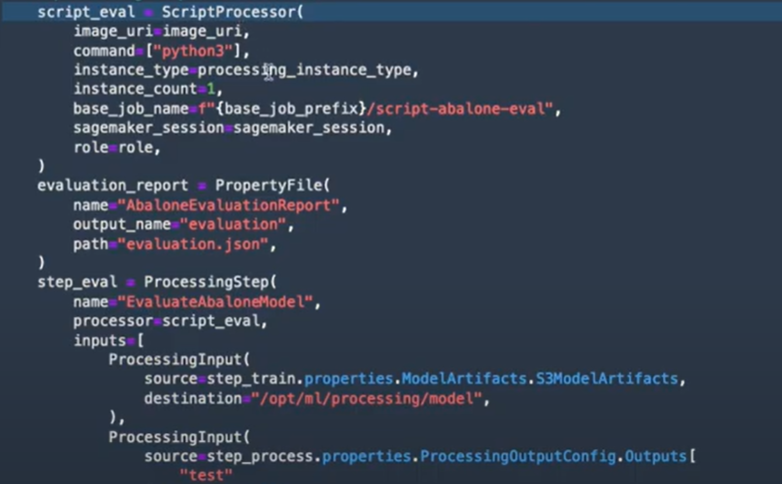
Et puis finalement en se basant sur une étape conditionnelle, un modèle est enregistré si l’erreur est inférieure à 6, sinon le modèle ne sera pas enregistré.
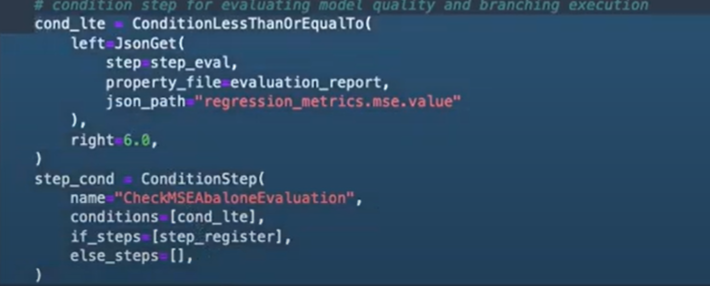
Il suffit donc après d'enchaîner les différentes étapes du pipeline et de le lancer, pour exécuter ses différentes étapes.
Les étapes qu’on vient de voir sont bien sûr juste un exemple, vous pouvez imaginer plusieurs étapes à enchaîner ensemble (dans l’ordre, en parallèle, avec une condition). Vous pouvez aussi rajouter des étapes de monitoring de modèles si c’est nécessaire.
Le déploiement d’un modèle
- Découvrir le deuxième répertoire sur le déploiement du modèle
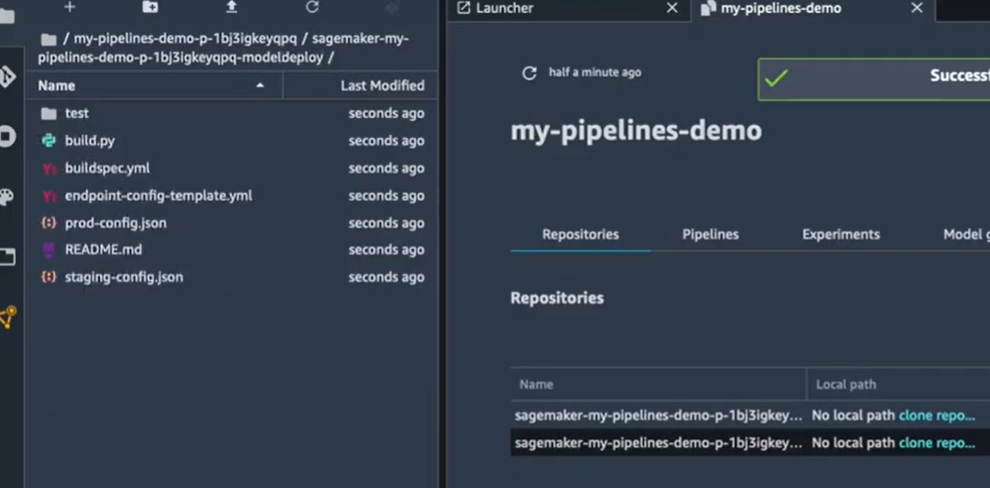
Ici il s’agit de plusieurs fichiers de configuration qui vont permettre de déployer les modèles et les mettre en production si le choix final est fait.
Le pipeline
Une fois que le pipeline est lancé, on peut inspecter les différentes étapes en cliquant sur l’onglet Pipeline et puis le pipeline en cours d’exécution :
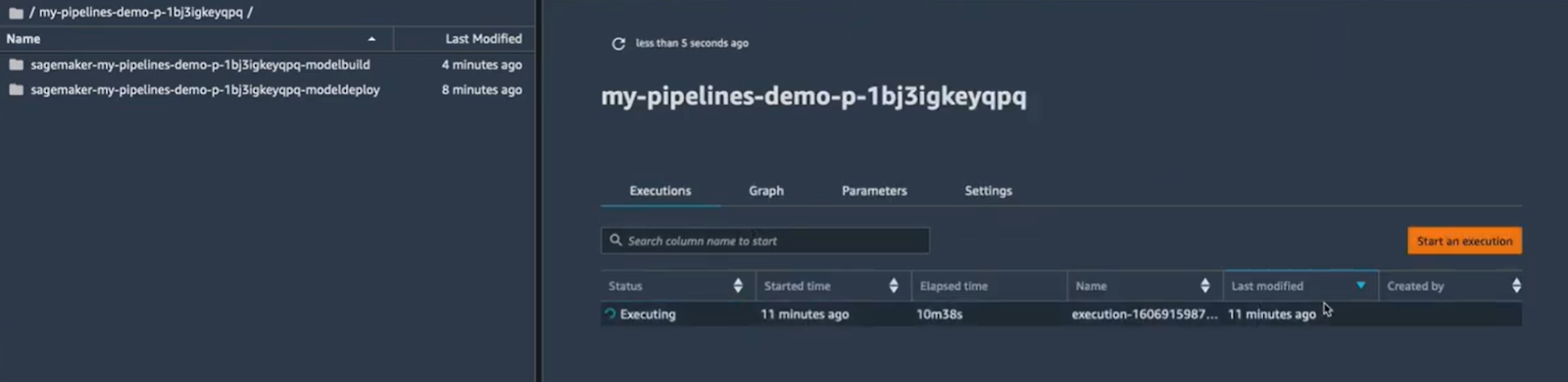
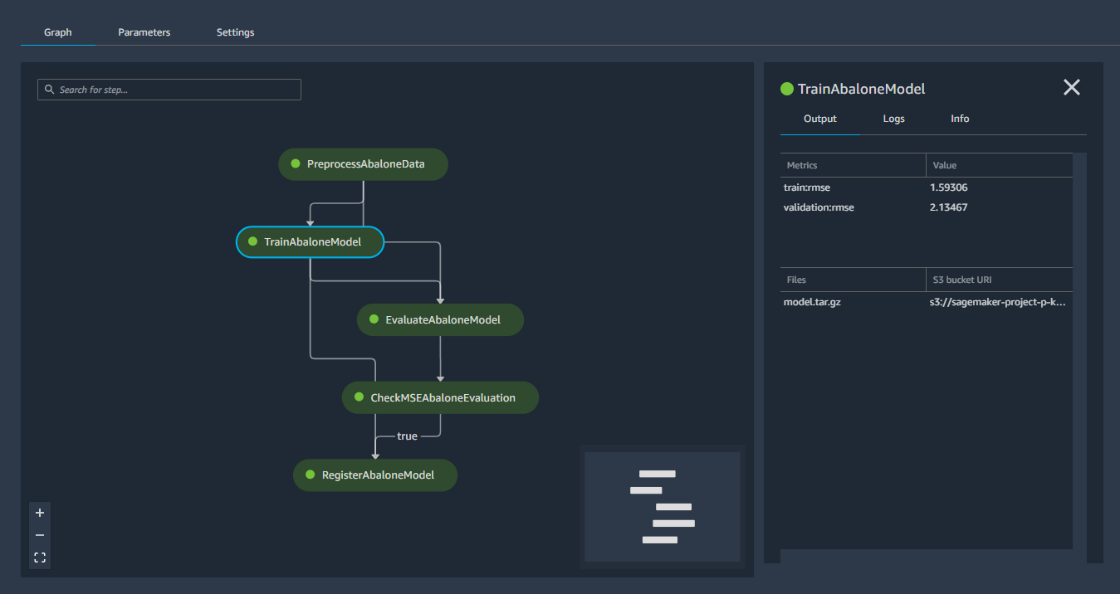
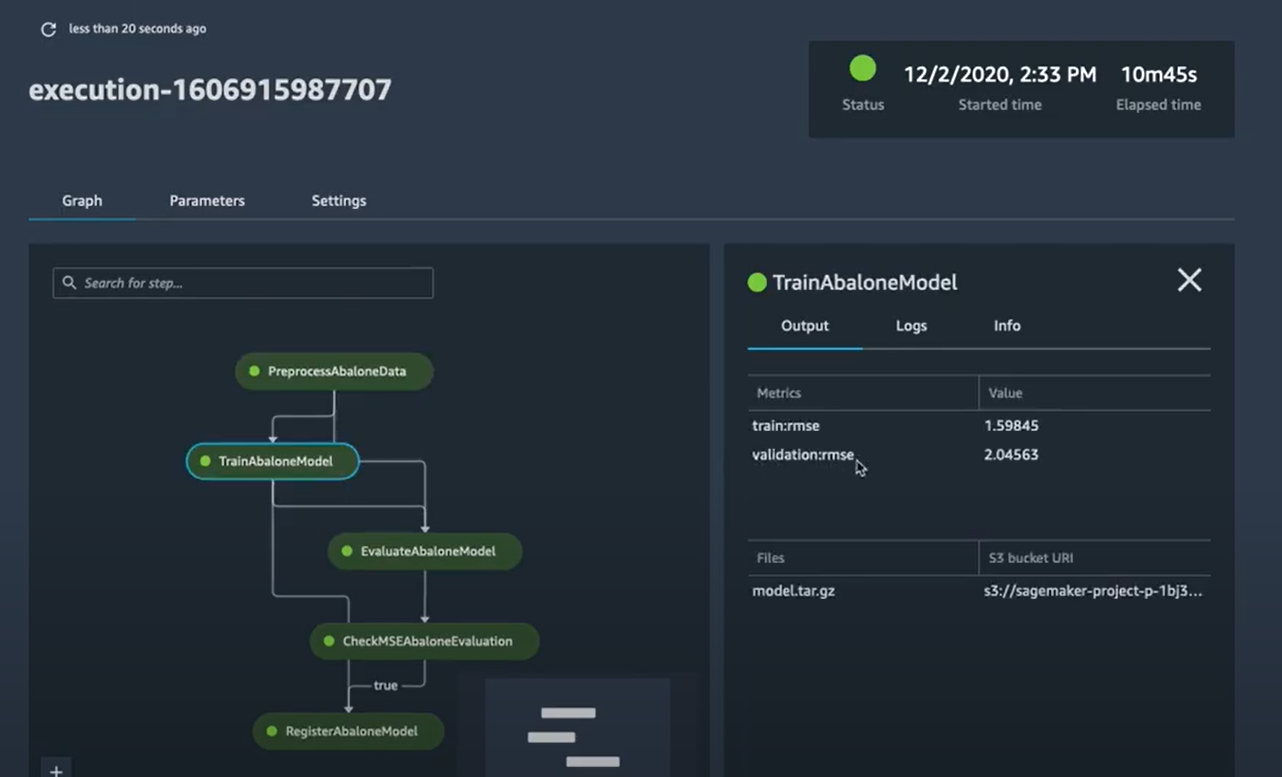
On peut donc voir le graph d’exécution, comme on peut visualiser chaque étape. Par exemple, sur l’image ci-dessous on peut voir l’étape d'entraînement avec les informations nécessaires sur les métriques d'entraînement et de validation.
L’étape conditionnelle affiche “True” parce que l’erreur est inférieure à 6 et donc la condition est respectée. On peut donc enregistrer ce modèle (c’est le pipeline qui le va faire pour nous plutôt).
A cette étape du pipeline, le modèle est enregistré mais n’est pas encore déployé. La raison est que dans le code du pipeline, dans l’étape d’enregistrement, il y’a une condition de donner le choix de déploiement du modèle de façon manuelle.
On peut le voir dans l’onglet paramètres :
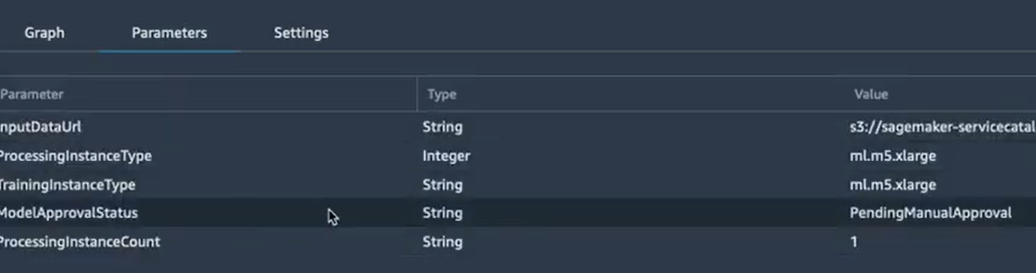
Et on peut le vérifier également dans le code pipeline.py :

Afin de déployer le modèle, il faut donc revenir sur le projet, choisir l’onglet “Model groups”, et puis choisir le groupe qui nous concerne. Dans chaque groupe, il y a une liste de modèles entraînés. On va choisir le modèle qu’on vient d’enregistrer pour le valider.
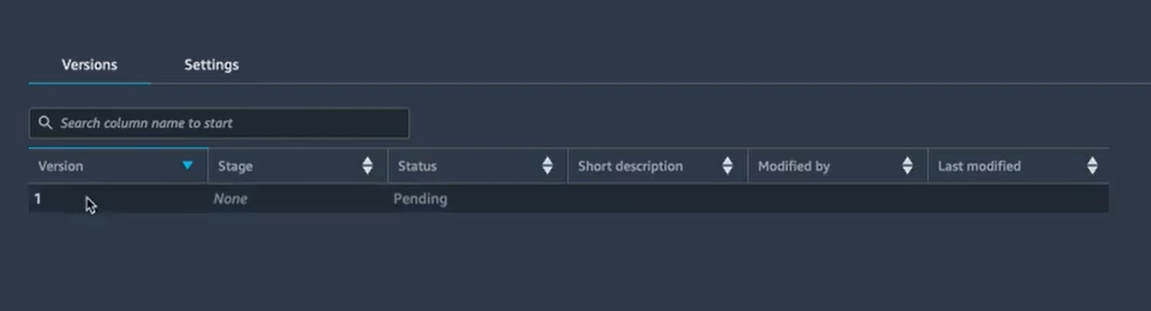
Dans l’exemple on a un seul modèle, on va donc choisir celui-là :
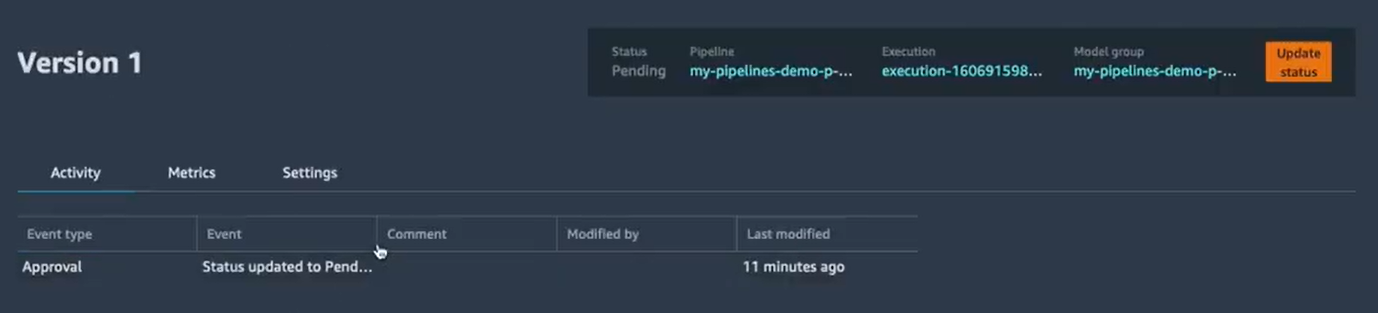
On peut voir que l’état actuel du modèle est “Status updated to PendingManuelApproval”. Pour mettre à jour son état il suffit de cliquer sur “Update status” en haut à droite. Cela va nous permettre d'approuver le modèle en y ajoutant un commentaire :
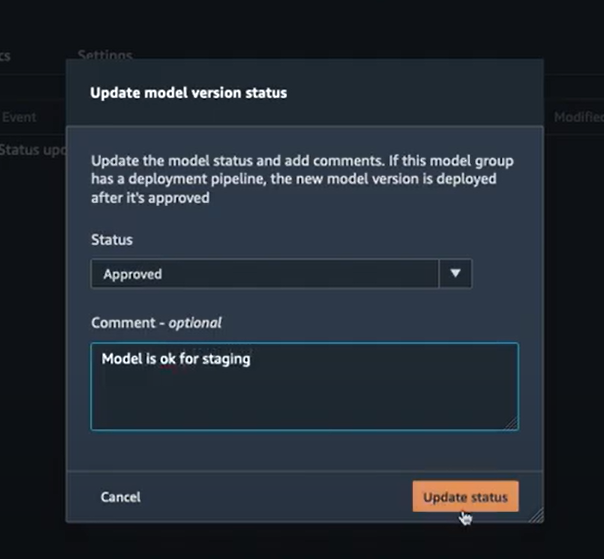
Création du endpoint staging
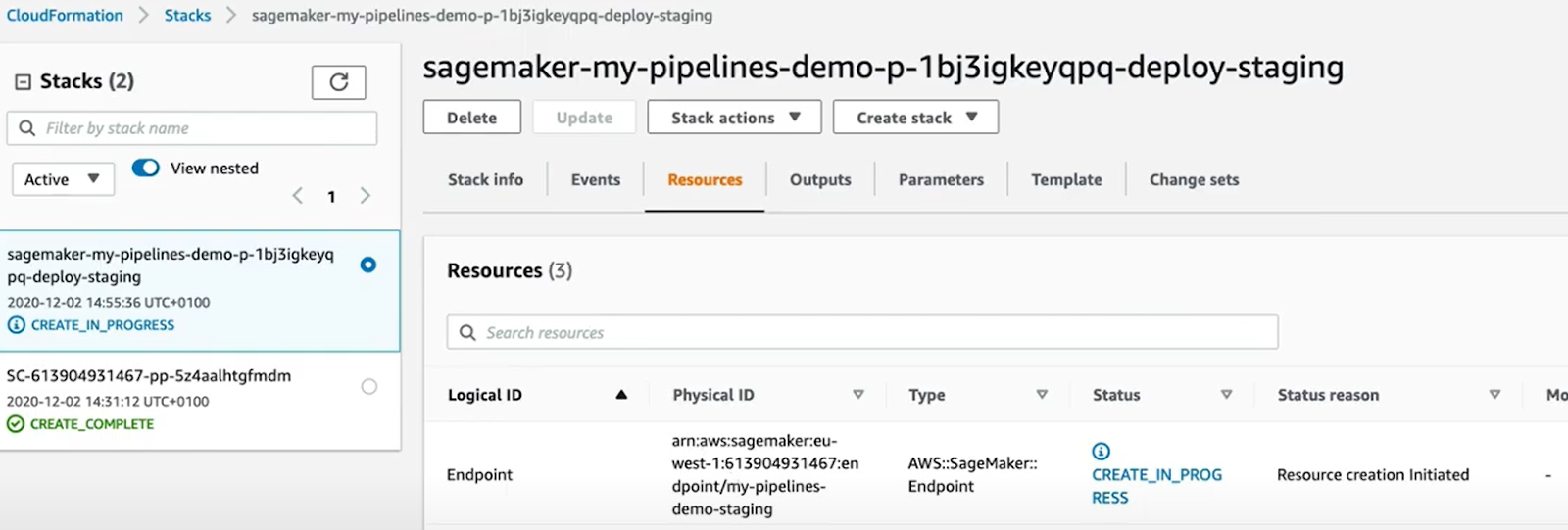
On peut donc vérifier l’état du déploiement dans l’onglet “Endpoints” de notre projet. On peut également le vérifier sur Cloud Formation :
Une fois que le modèle est déployé, on verra le changement du statut du endpoint à “InService” :
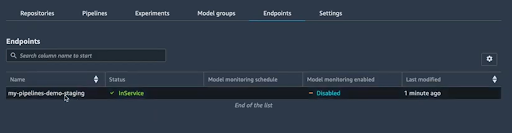
Création du endpoint final pour la prod
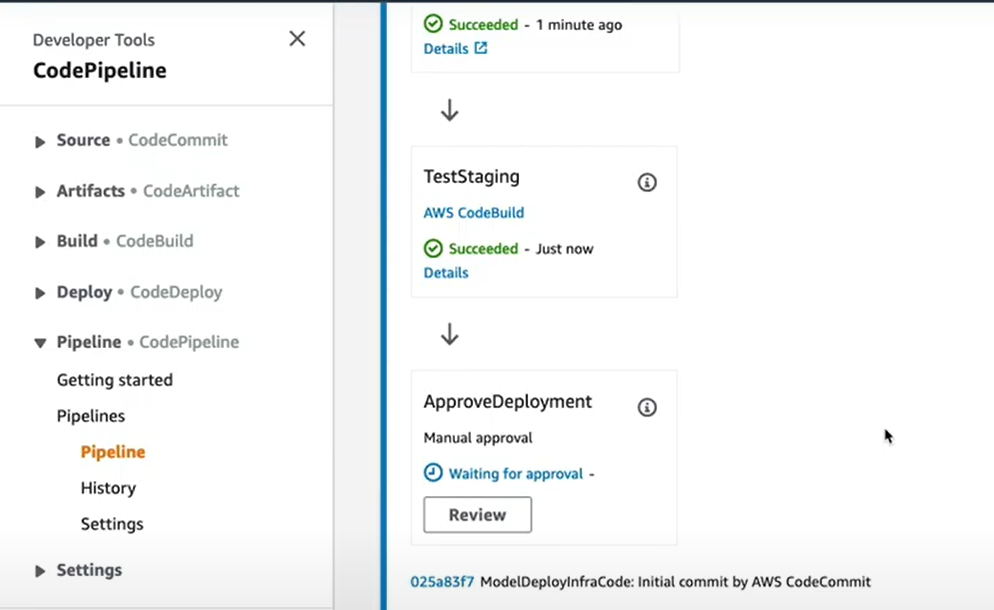
Il faut savoir que ce premier modèle est un modèle de test “Staging” et que notre modèle n’est donc pas encore en prod. À cette étape du pipeline, le Data Scientist peut demander aux DevOps, s’il les résultats du modèle sont satisfaisants, et de le déployer en prod si c’est le cas.
Le DevOps pourra donc aller vérifier le modèle dans AWS CodePipeline pour valider le modèle et le déployer en production.
Git Workflow
Maintenant qu’on a regardé un workflow ML du début à la fin, la prochaine question qu’on peut se poser est : comment les modifications vont être gérées ?
Comme expliqué précédemment, le service SageMaker Pipelines permet d'apporter la CI/CD au ML. On va donc voir comment on peut gérer les modifications de façon simple et rapide : modifier notre code d'entraînement et le déployer à nouveau en utilisant ML Pipeline.
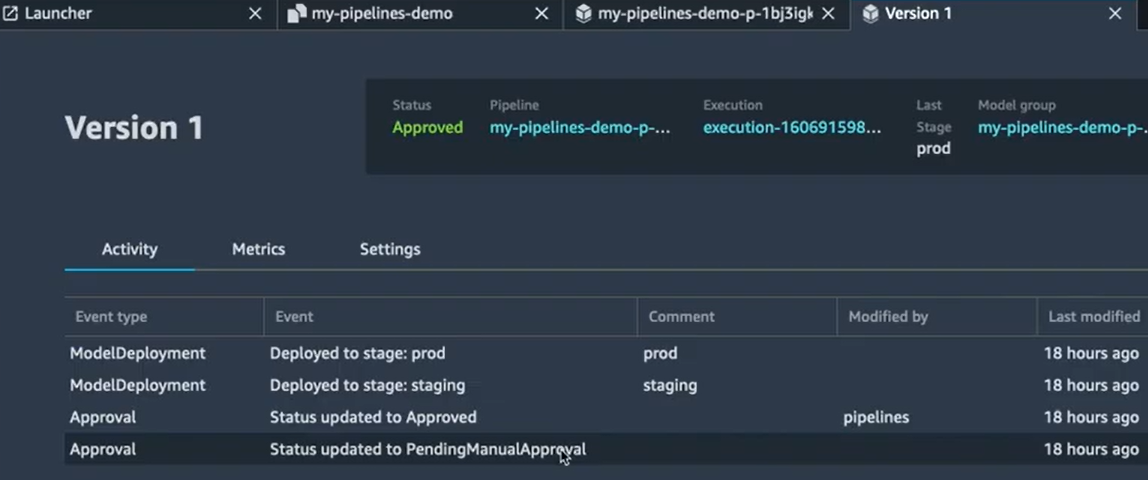
Après avoir exécuté une première version de notre modèle, on a donc un pipeline déjà exécuté avec la Version 1 :
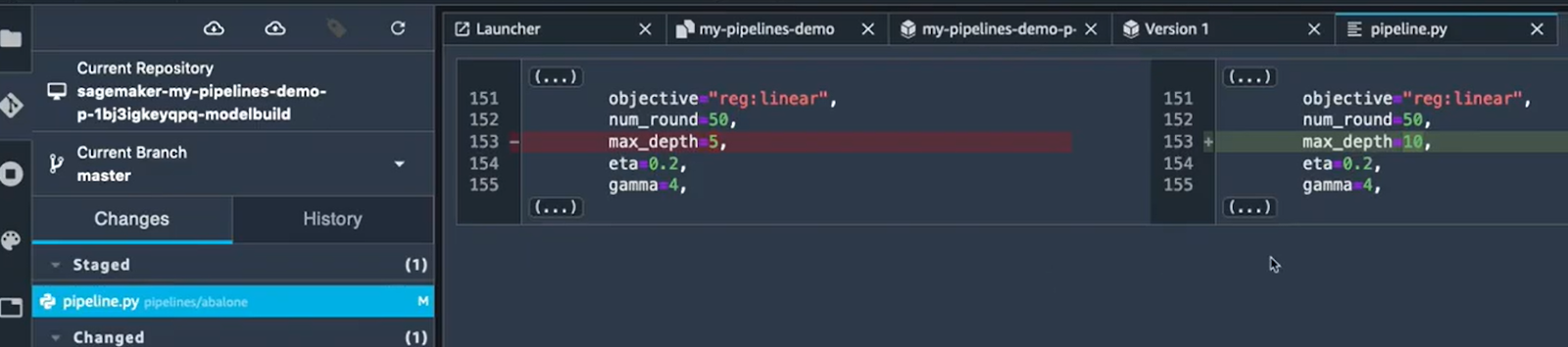
Juste à titre d’exemple, on va essayer de changer les hyperparamètres de l’algorithme d'entraînement. On va remplacer le max_depth qui est 5 par 10. Une fois que le changement est enregistré, on va valider le changement dans l’onglet Git de SageMaker Studio :
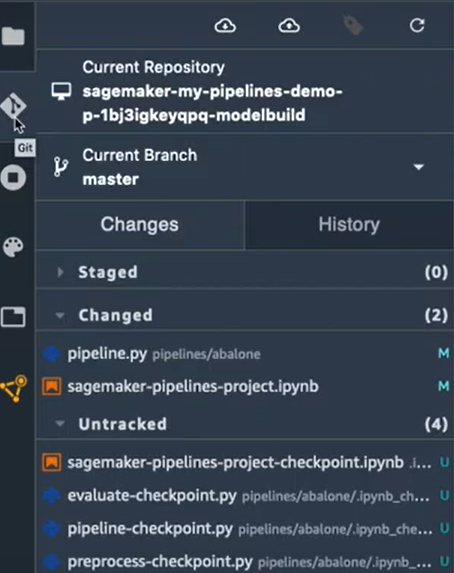
On voit bien qu’il y avait un changement dans le fichier pipeline.py. On passe donc ce fichier à l’étape “Staged” en cliquant sur le fichier et puis sur le bouton “+” :
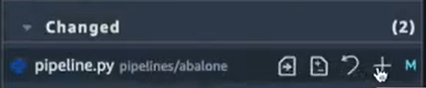
Le fichier modifié est maintenant dans l’étape “Staged” avant le commit, on peut voir les changements en cliquant tout simplement sur le fichier :
Après, on peut passer à la prochaine étape de commit. Il suffit juste de cliquer sur le bouton commit, renseigner le nom et l’email de la personne qui a fait le commit et appuyer sur OK :
Puis on push les commits avec le bouton “push” en haut de l’onglet Git. Le push de commit va automatiquement lancer un nouveau pipeline pour nous avec l’exécution de toutes les étapes comme la première fois.
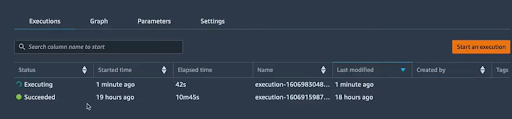
Une fois que le pipeline est terminé, le modèle sera enregistré et restera en attente de validation. Comme on peut voir sur l’image ci-dessous, il est bien mentionné qu’il s’agit d’une deuxième version du pipeline :
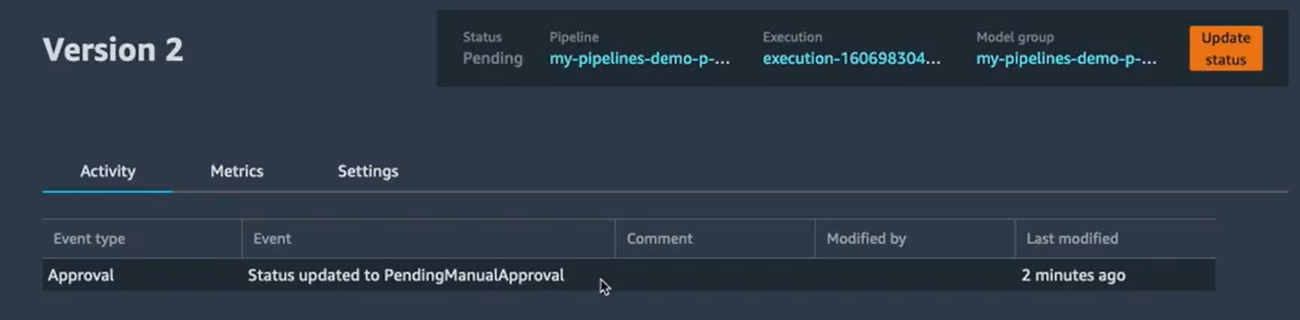
Il suffit d’accepter le modèle pour le déployer en “Staging” ou bien le refuser si les résultats ne sont pas satisfaisants. Si le modèle est accepté, il est déployé en Staging et mis en attente pour une validation finale pour passer en prod.
Conclusion
Dans mon précédent article, on a fait un tour sur le nouveau service SageMaker Data Wrangler, qui permet d’automatiser et d’exécuter les étapes de transformation de données en quelques clics avec des composants prêts à utiliser. Si on ajoute à cela le service SageMaker Pipelines qu’on vient de voir ensemble, on peut dire que les deux formes sont un couple parfait pour automatiser tout le flux des projets Data Science/ML avec une bonne maîtrise et une souplesse remarquable.
