

De quoi allons nous parler ? De sécurité dans un environnement Data.
Qu’elle soit big, small, fast, slow,… tout est Data !
Dans ces environnements Data, de plus en plus répandus dans les entreprises, la sécurité est au centre de toutes les attentions.
Selon l’Agence Nationale de la Sécurité des Systèmes d’Informations : “59% des entreprises déclarent que les cyberattaques ont eu un impact sur leurs activités”. Ajoutons à cela les enjeux de la CNIL (Commission nationale de l'informatique et des libertés) sur le droit à la protection des données à caractère personnel (RGPD) et ses sanctions pouvant s’élever jusqu’à 20 millions d’euros ou dans le cas d’une entreprise jusqu’à 4 % du chiffre d’affaires annuel mondial.
La note salée peut freiner ou éteindre beaucoup d’initiatives voire mettre un terme à vos ambitions entrepreneuriales.
Dans les faits, je croise régulièrement des clients, des développeurs Data, des architectes ou C-level qui ont une vision incomplète de la sécurité dans ce type d’environnements.
Cet article a pour but de remettre l’église au centre du village et d’essayer, dans une moindre mesure, de dresser le portrait de ce qu’on peut attendre d’un environnement Data sécurisé.
Les objectifs de la protection des données : CIAA
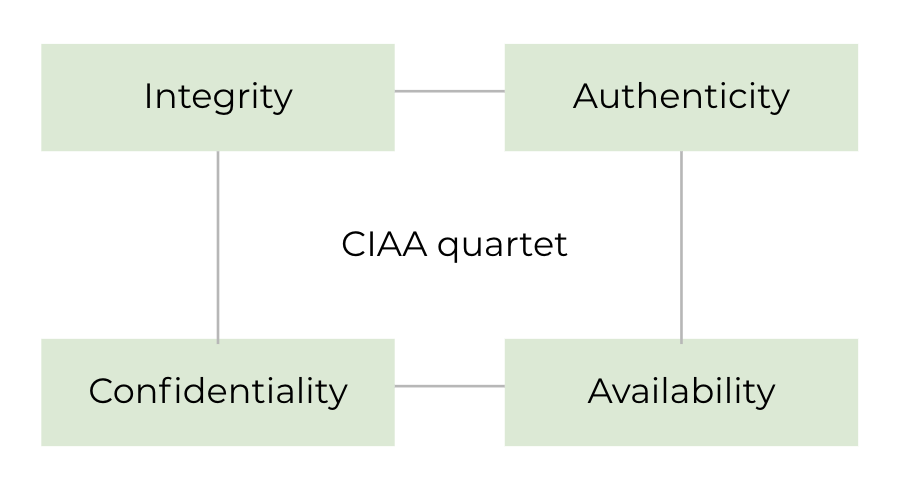
La principale motivation de la sécurité de l'information est de garantir la confidentialité, l'intégrité, l’authenticité et la disponibilité de vos environnements.
Le principe de confidentialité est de protéger contre tout accès non autorisé. C’est un enjeu majeur quand on parle de données personnelles dont la protection est requise par la RGPD. Mais les entreprises ont également intérêt à ce que les données sensibles ne tombent pas entre les mains de la concurrence. La confidentialité des informations peut être assurée par l'attribution appropriée d'autorisations en rapport avec les procédures d'authentification et de chiffrement.
Le terme intégrité fait référence à l'exactitude des données, dans le sens où les données sont à la fois complètes et inchangées. D’un côté l’intégrité fait référence à la connaissance et le traçage de la donnée, d’un autre côté elle fait référence au bon fonctionnement des systèmes informatiques.
Les données, les systèmes informatiques et les applications sont disponibles s'ils sont accessibles aux utilisateurs et fonctionnent comme prévu. La défaillance d’un serveur ou le chiffrement malveillant de vos données par un cybercriminel représentent des violations de la disponibilité. Les restrictions de disponibilité peuvent à bien des égards entraîner des pertes financières et de réputation pour les entreprises.
Une personne est authentique si son identité et ses déclarations sur son identité correspondent. Par exemple, en échangeant l’auteur d’un message, on perd son authenticité. Avant que l'accès ne soit accordé, un utilisateur doit pouvoir s'authentifier.
Les 5 piliers d’un environnement Data sécurisé
Je vous propose d’orienter cette étude autour de 5 piliers :
- Le management de la donnée,
- Le management des accès et des identités (IAM),
- La protection et la confidentialité de la donnée,
- La sécurité du réseau,
- La sécurité et l’intégrité de l’infrastructure.
Ces 5 piliers sont divisés en sous-sections, toutes critiques afin d’assurer la sécurité de votre environnement et d’atténuer les risques. Ils forment ensemble ce que je vous propose d’appeler un “Framework de sécurité” qui se présente ainsi :

Rentrons maintenant dans le détail de ce framework.
Si vous pensez avoir mis en place toutes ces briques sur votre environnement, ne lisez pas la suite, je ne souhaite pas vous frustrer. Si vous avez des doutes ou si rien n’est entrepris encore, foncez !
Data Management
Le Data Management est une discipline qui tend à valoriser la donnée en tant que ressource numérique. Dans un contexte RGPD tendu, la connaissance approfondie (classification, cartographie et traçabilité) de ces données devient un enjeu majeur.

Une classification efficace de la donnée est sûrement une des composantes les plus importantes pour appliquer un contrôle efficace de la donnée dans un environnement Data. Quand une entreprise traite une grosse quantité de données, il est important d’identifier quelles données sont importantes, quelles données doivent être chiffrées, quelles données méritent une protection accrue. Cette étape demande une collaboration avec les entités légales, finance, propriété intellectuelle et sécurité de votre entreprise afin de connaître les données que vous manipulez.
Sur ces données :
- vous réaliserez un contrôle de sécurité (emplacement de la donnée, chiffrement appliqué, cartographie des accès utilisateurs et systèmes),
- vous évaluerez la valeur de ces données en cas d’attaque (données sensibles, valeur sur le marché noir, propriété intellectuelle),
- vous déterminerez la conformité et l’impact sur les revenus,
- vous étudierez l’impact des données sensibles sur le propriétaire (le client par exemple) de ces données.
Par cet exercice, en premier lieu, vous aurez une meilleure visibilité de vos données et vous pourrez construire aisément une roadmap de mise en place d’un environnement sécurisé.

Le manque de connaissance de vos données expose l’entreprise à des risques de sécurité ou de redondance de l’information. Il est alors nécessaire de cartographier finement où se trouvent les données sensibles dans votre écosystème et par conséquent appliquer les mesures de protections appropriées comme le masquage, la documentation, la tokenization ou encore le chiffrement.
La découverte vous assurera une meilleure compréhension de ces données en :
- définissant et validant les données et leurs schémas,
- collectant les métriques (count, unique count) afin de déterminer si la donnée est dupliquée par exemple,
- étiquetant les données sensibles (pour les données structurées, un étiquetage des données sensibles par champ/colonne peut être très utile).
Par ce biais, vous pourrez alors partager vos résultats avec vos Data Scientists afin de mettre en place des modèles d’analyse de menaces ou encore évaluer l'intérêt d’utiliser des formats de données portant leurs schémas (Apache Parquet par exemple). Vous pourrez également apprendre de vos expériences réussies dans le chiffrement ou la tokenisation de données hautement sensibles et l’appliquer à tout votre environnement.

Le data tagging permet de comprendre le flux de vos données de bout en bout en apportant une attention particulière à vos sources et vos destinations. Il est le socle pour construire une solution de Data Lineage.
Par un suivi fin de la donnée, le tagging apporte de la visibilité aux données et améliore leur compréhension.
Le balisage de vos données vous permettra alors :
- d'assurer la réutilisabilité de vos données et éviter la duplication de vos travaux,
- de connaître le cheminement de vos données et par quels processus elles sont manipulées afin d’identifier les impacts d’un changement de modèle par exemple,
- d'aider à identifier les données personnelles sensibles afin que l'accès puisse être correctement géré,
- d'aider à signaler et à filtrer les données éthiquement douteuses ou autrement questionnables avant qu'elles ne soient utilisées dans la prise de décision ou dans des solutions d'intelligence artificielle.
IAM (Identity and Access Management)
La Gestion des Identités et des Accès est l’ensemble des processus mis en œuvre par une entité pour la gestion des habilitations de ses utilisateurs à son système d’information. Il s’agit donc de gérer qui a accès à quelle information à quel moment.

L'authentification est le processus permettant de déterminer si l'identité des utilisateurs, services, et les hôtes sont ceux qu'ils prétendent être. Le processus d’authentification est généralement basé sur un système d’utilisateur/mot de passe.
Dans les systèmes informatiques, l'authentification est différente de l'autorisation, elle vérifie simplement que l'entité est celle qu’elle prétend être mais ne donne pas de droits d'accès aux objets système. L'authentification et l'autorisation doivent fonctionner en tandem pour assurer une sécurité efficace.
Dans les entreprises, il est fréquent de rencontrer le terme de Single-Sign-On (SSO) permettant d’accéder à plusieurs services en ne procédant qu’à une seule authentification.
Il existe un niveau de sécurité supérieur à la simple authentification, l’authentification multifactorielle (Multi-Factor Authentication ou MFA) qui est une méthode d'authentification électronique dans laquelle un utilisateur n'a accès à une application ou un service qu'après avoir présenté avec succès deux ou plusieurs éléments de preuve (ou facteurs) à un mécanisme d'authentification :
- connaissances (ce que seul l'utilisateur sait),
- possession (quelque chose que seul l'utilisateur possède),
- héritage (quelque chose que seul l'utilisateur est).
Par ce biais, ce mécanisme protège l'utilisateur contre une personne inconnue qui tente d'accéder à ses données.

L'autorisation est le processus permettant de déterminer quelles permissions une personne est censée avoir sur des données, des services ou des systèmes.
Dans les systèmes informatiques multi-utilisateurs, la gouvernance définit les utilisateurs autorisés à accéder au système, ainsi que les privilèges d'utilisation auxquels ils sont éligibles (par exemple, accès aux répertoires de fichiers, heures d'accès, quantité d'espace de stockage alloué).
L'autorisation peut être considérée comme à la fois le paramétrage préliminaire des autorisations par un administrateur système et la vérification de ces autorisations lorsqu'un utilisateur obtient l'accès. L'autorisation est généralement précédée d'une authentification.
Il est conseillé de définir finement les autorisations au niveau des services, du réseau, des serveurs, des frameworks mais aussi au niveau des bases de données, des tables ou des vues. Certaines solutions permettent même d’appliquer des autorisations au niveau des lignes de vos bases de données ou même de vos champs.

Afin de rendre aisée et cohérente l’attribution des habilitations, il convient de définir certains mécanismes. On parle alors de modèles d’habilitation. Ces modèles d’habilitation permettent de garantir, au sein de votre environnement, un contrôle d’accès efficace sur les ressources et les services IT. Ils permettent également de rationaliser le processus de demande d’accès des utilisateurs.
Si je devais vous en présenter deux, je vous parlerais des contrôles d’accès basés sur les attributs (ABAC) et les rôles (RBAC).
Dans le premier modèle (ABAC), les droits d’accès sont accordés aux utilisateurs grâce à l’utilisation de règles combinant des attributs (attributs d’utilisateur, de ressource, d’environnements, etc.). Il permet de gérer les accès très finement en appliquant une logique booléenne. Cependant, attention, il est très complexe à mettre en place, je le déconseille aux néophytes.
Dans le deuxième modèle (RBAC), l’accès aux ressources du système d’information s’appuie sur des rôles tels qu’ils sont définis dans l’organisation de votre environnement. L’accès aux objets se fait via le rôle de l’utilisateur et des règles qui lui sont appliquées. C’est le plus utilisé par les entreprises mais il est moins dynamique. Ajouter un accès revient à modifier un rôle et donc autoriser des accès à toutes personnes assumant ce rôle.
Ces dernières années, nous avons vu émerger la stratégie de sécurité nommée “Zero Trust”. Chaque élément de votre environnement se voit allouer un niveau de confiance de zéro (d’où le zéro trust). Ce modèle se base sur le concept de micro-segmentation qui traite chaque connexion vers chaque application comme un environnement distinct, avec ses propres exigences de sécurité, totalement transparente pour l’utilisateur. Par définition, la micro-segmentation considère chaque paire utilisateur-ressource comme indépendante, à la fois de l’origine de la connexion, mais aussi des autres connexions applicatives qui pourraient être actives sur le même terminal. S’appuyant sur un modèle Policy Based Access Control (PBAC), nous atteignons là un niveau élevé de sécurité, de granularité mais également de complexité.
Data Protection & Privacy
La confidentialité et la protection des données sont deux problématiques de gouvernance interdépendantes. Par la protection des données, nous allons assurer leur confidentialité. La mise en œuvre de la sécurité et la confidentialité des données de l’entreprise fait partie intégrante de votre stratégie.

Le data masking ou anonymisation est typique dans la gestion des données sensibles et PII (Personally Identifiable Information). Il existe deux approches :
- l’anonymisation en amont afin d’assurer qu’aucune donnée sensible n’est stockée dans votre environnement,
- l’anonymisation dynamique où la donnée est stockée complète mais masquée à la volée en fonction du rôle de l’utilisateur connecté.
Cette étape va de pair avec l’étape de Data Tagging et permettra de garder, en cas d’audit, certaines briques de votre environnement en dehors du scope d’intervention.
L’anonymisation consiste à remplacer les données sensibles par des données fictives là où ces données sensibles ne sont pas utiles. A partir du moment où les informations privées (nom, prénom, adresse, etc.) ne sont plus utiles, masquez les ou supprimez les.

La tokenization a pour but de substituer une donnée par une valeur aléatoire unique, nommée token. Cette pratique permet, entre autres, de supprimer les PII facilement en supprimant toutes les données référencées par cette clé.
Lors de la tokenization, un serveur stocke les relations entre les valeurs d'origine et de jeton. Lorsqu'une application a besoin des données d'origine, le système recherche la valeur du jeton (token) pour la récupérer.
Ce chiffrement permet d’offrir une excellente granularité de sécurité mais se fait au détriment d'une intervention manuelle pour déterminer les champs qui nécessitent d’être chiffrés et où et comment autoriser le déchiffrage.

Ce n’est pas la première fois que j’utilise ce mot, il est temps de le mettre en lumière : le chiffrement. Nous allons parler du chiffrement au repos ou at-rest.
Le chiffrement au repos, c’est le chiffrement au niveau du disque. Il consiste à protéger ces données, une fois stockées, c’est à dire les rendre inexploitables en cas de vol puisque impossible à déchiffrer.
On utilise une clé de chiffrement pour chiffrer la donnée et une clé de déchiffrement pour la déchiffrer. Lorsque ces deux clés sont identiques, on parle de chiffrement symétrique. A contrario, lorsqu’elles sont différentes, on parle de chiffrement asymétrique : une paire composée d'une clé publique, servant au chiffrement, et d'une clé privée, servant à déchiffrer.
La protection de vos données peut également être assurée par un chiffrement d’enveloppe qui consiste à chiffrer des données à l'aide d'une clé DEK (Data Encryption Key), puis à chiffrer la clé DEK avec une clé racine que vous pouvez intégralement gérer.

La prévention des pertes de données (DLP) est une stratégie qui empêche les utilisateurs d'envoyer des informations sensibles ou critiques en dehors du réseau de l'entreprise. Le terme décrit également les logiciels qui aident les administrateurs de réseau à contrôler les données que les utilisateurs envoient.
Le but d’une telle solution est d’identifier les flux par lesquels peuvent transiter les données, et dans ces flux identifier les champs, données, formules, données personnelles en mouvement.
Network Security
Plus on descend dans ce framework, plus on s’éloigne de la donnée (enfin, pas totalement vu que tout est Data). Données ou pas, RGPD ou pas, la sécurité du réseau est une composante bien connue des systèmes sécurisés assurant l’intégrité de votre réseau.

Quand on parle de chiffrement au niveau réseau, on parle de chiffrement en transit ou in-transit. Ce chiffrement est nécessaire pour éviter les interceptions de messages qui transitent sur le réseau. On utilisera des protocoles cryptographiques qui chiffrent les données et authentifient une connexion lors du transfert comme TLS ou SSL.
Nous connaissons le protocole HTTPS (HyperText Transfer Protocol Secure) quand on est sur notre navigateur web, ce n’est rien de plus que le protocole HTTP appliquant un layer de chiffrement sécurisé SSL ou TLS.
Dans un objectif d’environnement sécurisé, ces protocoles doivent être appliqués à la fois lors des communications client-cluster mais également cluster-cluster, c'est-à-dire à l'intérieur de notre environnement, entre nos services.

Une security zone est une partie d’un réseau (un sous-réseau ou subnet) qui répond à des exigences de sécurités spécifiques définies. Chaque zone se compose d'une seule interface ou d'un groupe d'interfaces, auxquelles une politique de sécurité est appliquée (network policy).
Le trafic est autorisé ou refusé en fonction d'un ensemble prédéterminé de règles appelé liste de contrôle d'accès (ACL).
Par exemple, c’est le travail d’un firewall qui doit être résistant aux attaques et doit être en mesure de filtrer le trafic.
Ce découpage du réseau en sous-réseaux implémentant des politiques spécifiques est primordial. Il permet, par exemple, de n’autoriser les accès à internet qu’aux services nécessitant cette connexion et limiter l’exposition des autres services.
Si on prend un exemple dans nos environnement Data, dans un contexte Hadoop avec HDFS, un utilisateur final ne doit jamais avoir accès à nos DataNodes mais uniquement à nos NameNodes, il sera commun d’appliquer des ACL pour ne pas exposer nos DataNodes
Infrastructure Security & Integrity
Last but not least, la sécurité et l’intégrité de l’infrastructure. Par intégrité, j’entends une infrastructure capable de résister à la falsification, de fonctionner conformément aux normes ou politiques prescrites et d'avoir une mission claire. Pour ce faire, il vous faudra superviser activement votre environnement.

L’audit de sécurité est une évaluation complète de votre organisation, système et environnement.
Il comprend, entre autres :
- les interviews des personnes impliquées sur votre environnement,
- l’exécution d’analyses de vulnérabilité en matière de sécurité,
- l’examen des accès aux services, applications,
- le contrôle des accès physiques aux systèmes,
- l’analyse de la traçabilité des actions menées sur vos environnements.
Côté technique, l’audit se base sur des audit logs. Ces logs tracent la totalité des actions faites sur votre système que ce soit les accès aux services ou les opérations menées sur ces derniers (ajout/suppression de nœuds) comme les actions faites sur vos données (ajout/suppression de données).
Les audits ne doivent pas être vus comme quelque chose de négatif mais contribuent à assurer la sécurité optimale de vos environnements.
Stocker les audit logs c’est bien, en tirer partie c’est mieux. Ils vous permettront d’obtenir, en temps réel, des informations précieuses sur la sécurité de votre environnement et de réagir rapidement en cas d’attaque si une supervision est active. On voit apparaître des outils basés sur du Machine Learning aidant à détecter les activités suspicieuses sur le réseau (Amazon Guard Duty, Azure ATP par exemple), voire même les données sensibles d’une entreprise (AWS Macie par exemple).

Cela correspond à tirer partie d’un autre type de logs, les logs d’activité. Mettre en place une supervision de l’activité de votre environnement, vos services, vos applications c’est s’assurer que votre système est opérationnel. Si la supervision est active, elle vous permettra d’anticiper les problèmes et d’éviter, par exemple, la perte de données.
Conclusion
Si vous avez tenu jusque là et que cet article vous a intéressé, mettez un pouce bleu (bon ici, sur ce blog, on ne peut pas… dommage !).
Plus sérieusement, parce que la sécurité est un sujet important, si vous avez mis en place toutes les briques de ce framework dans votre entreprise :
- vous avez identifié et catégorisé vos données sensibles, vitales pour votre entreprise et cartographié vos flux ;
- vous vous êtes assuré d’une part que les seules personnes autorisées ont bien un accès conforme à leur profil et, d’autre part que vos données sont correctement utilisées, partagées, de façon contrôlée, et ce, de bout en bout ;
- vous avez protégé vos données par chiffrement et réduit le scope de votre environnement susceptible de manipuler des PII ;
- vous avez sécurisé votre réseau, borné et sécurisé vos différents services par zones ;
- vous êtes en mesure de réagir à toute faille de sécurité en quasi temps réel et êtes en capacité de suivre le mouvement de vos données.
Il y a la théorie et il y a la pratique. Que ce soit on-premise ou dans le cloud, vous trouverez aisément chaussure à votre pied si vous vous lancez dans la sécurisation de votre environnement. Je ne vous ferai pas une liste détaillée des solutions qui existent sur le marché sinon j’y serais encore. Avec une longueur d’avance, les solutions cloud (de par la quantité de services qu’ils proposent) offrent plus de flexibilité et de facilité de mise en œuvre dans la configuration et l’exploitation du framework de sécurité que je viens de vous présenter.
Je ne vous souhaite pas une attaque de votre environnement… Mais, en tout cas, maintenant vous êtes prêts à relever n’importe quel challenge !
Je finirai par citer Guillaume Poupard, patron de l'agence française de cyberdéfense (Anssi) qui a dit qu’oublier la cybersécurité, c'est “rouler à 200 km/h à moto sans casque".
