

Tester son application via son interface graphique constitue un passage obligatoire lors du développement d’une application web. Il existe différentes solutions pour réaliser ces tests, parmi lesquelles Selenium.
Nous allons expliquer ici, dans les grandes lignes, comment prendre en main Selenium WebDriver et également introduire ce que sont les tests automatisés à la lumière de mon retour d'expérience sur cet outil que j’ai pu découvrir lors d’une mission chez un client.
Cet article cible plus spécifiquement les lecteurs ayant un poil d'intérêt pour le domaine du test. J’y expliquerai comment utiliser Selenium WebDriver pour créer des scénarios de tests simples et la manière dont je l’utilisais au quotidien.
Description de Selenium
Selenium est une suite d’outil permettant d’interagir avec un navigateur web en simulant les actions d’un utilisateur. Il existe un IDE (integrated development environment) Selenium qui est intégré dans le navigateur web Firefox pour pouvoir enregistrer les actions d’une personne (remplissages de champs, clics ..) lorsqu’il teste une application pour pouvoir rejouer ce scénario à l’identique sans intervention humaine.
Nous ne détaillerons pas la manière de prendre en main cet IDE puisque je ne l’ai jamais utilisé et qu’il faudrait un article à part entière pour en parler en profondeur. Nous parlerons plutôt de Selenium en tant que bibliothèque de tests que l’on peut intégrer à un projet quel que soit le langage de programmation utilisé. On nomme ce Framework Selenium WebDriver.
Expliquons tout d’abord l'intérêt de Selenium WebDriver. C’est un Framework de tests automatisés dédié aux tests d’une application web. Un développeur cherchant à tester une fonctionnalité va pouvoir, au travers de différents cas d'utilisation, créer plusieurs scénarios de test qui vont s’exécuter sur un navigateur. On pourra visualiser le déroulement de ces scénarios sur le navigateur.
Une fonctionnalité à tester peut être, par exemple, la création d’un utilisateur sur notre application.
Le contexte
J’ai intégré un projet qui datait déjà de plusieurs années (~2011) au sein d’une grosse équipe de développement découpée en sous-équipes. Au départ, ma contribution ne se faisait que par la prise en main de Selenium WebDriver et la création de nouveaux scénarios de test. Il y avait 2 ou 3 personnes qui s’occupaient exclusivement de la rédaction de ces tests depuis environ 3 ans.
Le pourcentage de l’application testée via Selenium WebDriver était d’environ 60%.
Le fait de ne pas tout de suite créer de nouvelles fonctionnalités pour cette application était voulu et les tests que je rédigeais m’ont permis de comprendre la partie métier en détail.
J’ai endossé ce rôle pendant environ 3 mois pour ensuite intégrer une nouvelle équipe et m’attaquer au développement de nouvelles fonctionnalités, à la correction de bugs, etc…
L’ensemble des tests étaient lancés au moins une fois avant chaque mise en production mais n’était pas déclenchés de manière périodique.
Il n’y avait pas beaucoup d’anciens tests Selenium à réécrire puisque la plupart des évolutions du projet consistaient essentiellement en des rajouts d’écrans ou bien des rajouts de champs dans des écrans existants.
Enfin, il est à noter que la recherche des scénarios de test ne s’effectuait pas par mes soins mais plutôt ceux d’autres personnes dont le travail était de tester au plus vite une fonctionnalité réalisée par une équipe de développement manuellement, ces derniers étant plus accessibles en terme de temps et de technicité. Une fois ces tests terminés, ces personnes revenaient ensuite vers nous pour nous soumettre une série de scénarios à implémenter avec Selenium pour les automatiser.
Initialisation d’un projet Selenium
La première chose à faire est de télécharger GeckoDriver qui va jouer le rôle de proxy entre le code développé et le navigateur pour interagir avec les éléments des différentes pages web. Puis on l’ajoute dans la variable d’environnement PATH courante. On peut le trouver directement sur leur Github : https://github.com/mozilla/geckodriver/releases
Il va falloir ensuite ajouter dans nos dépendances la bibliothèque Selenium :
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>${selenium.version}</version>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-firefox-driver</artifactId>
<version>${selenium.version}</version>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-server</artifactId>
<version>${selenium.version}</version>
</dependency>
Passons ensuite à l’initialisation d’une classe Test :
1 private WebDriver driver;
2 private String baseUrl;
3 private Actions actions;
4 @Before
5 public void setUp() {
6 // Instantiate driver (gecko)
7 System.setProperty("webdriver.gecko.driver","/path/geckodriver-v0.26.0-linux64/geckodriver");
8 // Now you can Initialize marionette driver to launch firefox
9 FirefoxOptions firefoxOptions = new FirefoxOptions();
10 firefoxOptions.setCapability("marionette", true);
11 driver = new FirefoxDriver(firefoxOptions);
12 baseUrl = "http://localhost:8080";
13 driver.manage().timeouts().implicitlyWait(30, TimeUnit.SECONDS);
14 actions = new Actions(driver);
15 }
Pour l’initialisation il s’agit d’aller chercher le GeckoDriver en local en indiquant le chemin vers celui-ci (ligne 7). On va ensuite spécifier au driver d’utiliser le protocole Marionette pour communiquer avec le navigateur (lignes 8-10).
Enfin, à la ligne 13 on va introduire une notion importante : l’attente implicite. Lorsque le driver communique avec le navigateur, l’application web déployée traduite en Javascript va être chargée dans le navigateur qui va afficher les différents éléments de la page. Certains éléments ne sont pas chargés immédiatement sur la page et peuvent apparaître après quelques secondes.
Cette instruction permet donc d’attendre quelques secondes si l’on ne trouve pas tout de suite un élément de la page avant de lever une exception.
Ca donne quoi en pratique ?
Connexion et Cookies
1 @Test
2 public void createNewUser() throws Exception {
3 driver.get(baseUrl + "/uaa/login");
4 Cookie ck = new Cookie("token", "cookieToSet");
5 driver.manage().addCookie(ck);
J’ai pu travailler sur des applications qui nécessitait des cookies pour y accéder (authentification avec un token). Pour instancier ces cookies on procède de la sorte :
on demande à la ligne 3 la connexion à la page de login de l’application, puis, si la page a besoin d’un cookie pour accéder à certaines ressources on le lui spécifie en créant un objet Cookie et en l’ajoutant au driver (lignes 4/5).
La prochaine étape va consister à aller manipuler les pages web pour récupérer ces éléments.
Les localisateurs
Les localisateurs permettent de repérer les éléments d’une page web tels que les boutons, champs textes, labels, liens, etc …
Il existe plusieurs méthodes exposées par l’API du Webdriver de Selenium pour cibler ces éléments :
driver.findElement(By.id("emailId"))
Lorsque l’on code une application côté Front, on va souvent attribuer des ids aux différents éléments de la page web quelle que soit leur nature. Ceci est une bonne pratique puisque l’on va pouvoir aisément les retrouver avec la méthode ‘findElement’ qui va scruter le DOM de la page courante avec un localisateur ‘By.id’ qui va chercher tous les éléments dont l’id est ‘emailField’.
C’est le localisateur que je privilégiais lorsque un id était définit sur l’élément que je souhaitais récupérer (celui-ci étant censé être unique).
driver.findElement(By.name("password"))
driver.findElement(By.linkText("Envoyer"))
driver.findElement(By.className("control-label"))
Ces localisateurs permettent de trouver des éléments en fonction de leur nom (définit au moment du développement du Front), de la valeur du texte, ou encore du type de classe.
Prenons un exemple pratique, la page de connexion de Gmail :
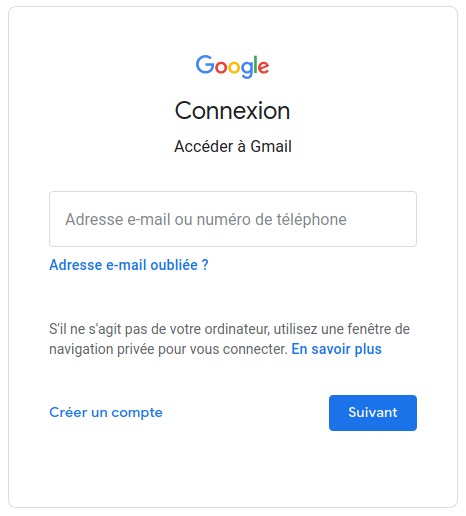
On peut localiser le champ de l’adresse mail de différentes manières comme vu précédemment. Avec le localisateur ‘linkText’, cela donnerait :
driver.findElement(By.linkText("Adresse e-mail ou numéro de téléphone"))
Supposons que le nom choisi pour le bouton ‘Suivant’ soit ‘nextStep’. En procédant à une analyse du DOM via l’outil d’inspection du Navigateur Web, on récupérerait l’élément comme ceci :
driver.findElement(By.name("nextStep"))
Le localisateur XPath
Il est également possible de localiser un élément grâce à son emplacement dans le DOM. On va alors utiliser le localisateur XPath de Selenium pour repérer ces éléments dynamiques lorsqu’aucun id, nom ou encore classe n’aura été défini sur ces éléments. Il y a deux moyens de spécifier le chemin dans le DOM vers l’objet que l’on souhaite récupérer : en renseignant le chemin relatif ou absolu.
Pour le chemin relatif, il suffit de le récupérer sur le Navigateur avec par exemple une extension comme ‘XPath Finder’ pour Firefox, par exemple :
driver.findElement(By.xpath("/html/body/div[2]/div/form/div/input"))
Cette méthode n’est pas seulement peu esthétique et longue, mais le DOM peut être amené à évoluer à chaque fois que l’on ajoute un nouvel élément dans page et la recherche ne s’adapte pas d’elle-même, il faudrait à chaque fois réévaluer la position de l’élément.
La syntaxe est un peu particulière pour le chemin absolu mais elle est à préférer. Elle sera toujours de la forme : XPath=//tagname[@attribute='value']
Voici un exemple où tagname = div, attribute = class et value = form-group pour la première partie :
driver.findElement(By.xpath("//div[@class=’form-group’]//input"))
Dans cet exemple on va chercher au départ dans tout le DOM (car il y a des ‘//’) un div dont l’attribut classe est ’form-group’ qui contient un sous-élément de type input et le récupérer.
Les actions
Les actions à effectuer sur les éléments sont variées, on pourra par exemple nettoyer ou remplir un champ texte pré rempli, cliquer sur un bouton, envoyer un formulaire …
En reprenant l’exemple précédent de la page de connexion à Gmail, on peut effacer le texte ‘Adresse e-mail ou numéro de téléphone’ comme ceci :
driver.findElement(By.linkText("Adresse e-mail ou numéro de téléphone")).clear()
La méthode clear() permet d’effacer ce qu’il y a dans le champ de renseignement de l’e-mail.
driver.findElement(By.className("control-label")).sendKeys("my-mail@gmail.com")
Ici, on remplit le champ précédemment recherché avec une adresse mail (my-mail@gmail.com) avec sendKeys(“stringToType”).
driver.findElement(By.id("buttonSubmit")).submit()
On peut également envoyer un formulaire précédemment renseigné en ciblant le bouton (ici par son id) et appliquer la méthode submit().
Il est aussi possible de tester si un champ ou un bouton est affiché ou sélectionné grâce aux méthodes ‘isDisplayed()’ et ‘isSelected()’.
Cette liste n’est pas exhaustive mais regroupe les méthodes d’action principales sur les différents éléments de l’IHM (Interface Homme-Machine).
Les annotations et le PageObjectPattern
Il s’avère qu’à un certain moment, la tâche peut paraître assez rébarbative si l’on repart toujours du début pour réécrire un test dans son ensemble. De plus, pour des contraintes de maintenabilité, dans le cas où il faudrait modifier une partie commune à plusieurs tests, il faudrait repasser sur tout ceux-là.
Pour pallier ces deux problèmes, il est possible de se tourner vers la solution du PageObjectPattern. Il s’agit de représenter des pages ou des morceaux de page Web en une classe Java avec les mécanismes/actions de base pour manipuler les éléments de ces pages.
Pour travailler directement sur les éléments d’une page Web, il est possible de les récupérer via les annotations Selenium.
On représente ici une page dédiée à l'authentification d’un site contenant deux champs : email
et password ainsi qu’un bouton pour soumettre ces informations afin de se connecter :
1 import org.openqa.selenium.WebDriver;
2 import org.openqa.selenium.WebElement;
3 import org.openqa.selenium.support.FindBy;
4 import org.openqa.selenium.support.PageFactory;
5 public class RegistrationPage {
6 private WebDriver driver;
7 @FindBy(id = "exampleInputEmail1")
8 private WebElement emailField;
9 @FindBy(id = "exampleInputPassword1")
10 private WebElement passwordField;
11 @FindBy(id = "buttonSubmit")
12 private WebElement submitBtn;
13 public RegistrationPage(WebDriver driver) {
14 this.driver = driver;
15 PageFactory.initElements(driver, this);
16 }
17 public void fillEmailAndPwd(String email, String password) {
18 emailField.sendKeys(email);
19 passwordField.sendKeys(password);
20 }
21 public void submitForm() {
22 submitBtn.submit();
23 }
Depuis une classe de test on pourra, à chaque fois que l’on veut se loguer à l’application, remplir les données du mail et du mot de passe pour se connecter en appelant la fonction fillEmailAndPwd puis cliquer sur le bouton de connexion via la méthode submitForm.
Les éléments sont récupérés via le localisateur qui est sous forme d’annotation (@FindBy), puis on spécifiera si on veut une recherche par id, nom de classe, xpath , etc...
La méthode à la ligne 17 sert à remplir le champ email avec les informations transmises par le test appelant.
Conclusion
L’intégration de Selenium WebDriver s’avère être un gros atout sur un projet pour rejouer des scénarios de test rapidement sans intervention humaine. J’ai pris conscience qu’il fallait régulièrement lancer ces tests pour déceler les régressions au plus tôt.
Je regrette de ne pas avoir vu en pratique comment intégrer ces tests à une CI, ce qui m’aurait permis de voir la chaîne de développement de bout en bout de la réalisation des nouvelles fonctionnalités jusqu’aux tests Selenium. La prochaine étape : comparer Selenium WebDriver avec le Framework Cypress qui s’avère en être un concurrent de plus en plus visible.