

PROLOGUE. Qualité de code : le sens et la manière
Repensons quelques instants le mot “qualité” et la façon dont il pourrait résonner. Pour faciliter l’exercice, prenons un objet physique, un objet “banal”, un objet du quotidien, pourtant particulièrement utile et potentiellement complexe : une table en bois. Qu’est-ce qui nous ferait dire qu’une table est de bonne qualité ? Nous pourrions essayer de traduire ce concept en axes identifiables. Nous pourrions considérer la qualité du bois, sa vie et sa provenance, ses conditions de transport et de stockage, la précision des découpes, la finesse du ponçage, les techniques d’assemblage utilisées par l’ébéniste, leur tenue dans le temps, l’état de l’art d’un assemblage sans clou ni vis, la résistance de la table à la charge et aux chocs, le vernis [...] La liste devient rapidement longue.
Transposons ceci à notre code bien aimé, à nos applications bien aimées. Lorsque nous devenons minutieux, nous voyons les lignes de code et les fonctions, la facilité de les comprendre et de cerner le comportement désiré, la testabilité et la couverture pertinente en tests pour s’assurer du bon fonctionnement, le respect des standards, des bonnes pratiques et des conventions… si nous prenons un peu de hauteur, ce qui nous importera sera l’application de patterns pertinents, de concepts architecturaux permettant l’évolutivité via la modularité, mais aussi la mise en œuvre de notions bien plus dynamiques : la résilience, la sécurité, la performance, la robustesse… et pour finir, voyons l’image dans son intégralité, en considérant les raisons mêmes d’avoir souhaité la création de l’application, donc des enjeux métier et des attentes de la part des utilisateurs : l’utilisabilité, la pertinence des fonctionnalités, la facilité à livrer, l’efficacité...
Le bois, les techniques d’assemblage et le lieu de destination de l’objet réalisé sont trois choses fondamentalement différentes. Et pourtant ces trois choses doivent être opérées en concordance pour atteindre une table de qualité. Un ébéniste réalisant de magnifiques assemblages sur du pin non traité, vendu comme une table extérieure à entreposer à même l’herbe... aura produit une table qui sera bonne à changer d’ici de courtes années. Si toutes les conditions citées précédemment ne sont pas au rendez-vous, la qualité ne l’est pas non plus. Pour autant, la qualité n’est pas binaire.
Je ne vous propose pas d'aborder tous les axes présentés précédemment, j'en serais bien incapable, je vais uniquement vous parler d'une façon de mettre en oeuvre une partie de la qualité de code, en utilisant SonarQube. Cet article s'adresse donc à vous qui recherchez une "aide" à la mise en place de la qualité de code, et à vous qui utilisez déjà SonarQube dans votre chaîne d'intégration continue.
PROLOGUE 2... “Damn ! La qualité de code, ce n’est pas déjà derrière nous ?”
… Serait-on tenté de dire. L’assimilation de la qualité de code est une péripétie multi-générationnelle, il faudra toujours convaincre de son utilité, et l’accompagner dans sa mise en oeuvre. Mais nous ne parlerons pas ici d’utilité, où les termes “code smell” et “dette technique” sont censés aiguiller vers la voie de la raison. Rien que le terme “dette”... Personne ne souhaite cumuler des dettes irraisonnablement (surtout quand l’échéance de remboursement est indéfinie, et que le taux d’intérêt n’est pas maîtrisé).
Pour reprendre les notions abordées plus haut, SonarQube s’attèle principalement à l’évaluation du respect des standards, des bonnes pratiques, des conventions et de la couverture des tests vis-à-vis du code. Il essaye également de s’attaquer à des sujets plus dynamiques, tout en restant sur un périmètre d’analyse statique : découvrir des brèches de sécurité et des problèmes de comportement. L'outillage applique un jeu de règles pour tenter de vérifier ou de nous rappeler le respect de ces pratiques.
Disclaimer : Vous devez le comprendre en lisant le prologue, une bonne note donnée par SonarQube ne permet pas de juger un code et un applicatif de qualitatifs. Mais ceci constitue un bon indicateur d'une des composantes de la qualité. Ne pas être tenté par le résumé "SonarQube est content = mon code est qualitatif". Cela ne peut être raisonnablement le cas, sans quoi nous manquerions de voir l'image dans son intégralité.
Disclaimer : La couverture de code mise en évidence par SonarQube et mesurée par des plugins comme JaCoCo (Java Code Coverage) n'évalue pas la pertinence des tests. Cette métrique est factuelle sur le pourcentage de lignes de code et d'expressions couvertes par les tests, souvent unitaires.
J’ai rapidement compris, comme la plupart des développeurs je suppose, le bienfait d’avoir un code propre et maintenable, sans pour autant savoir définir ce que représentaient ces notions. Je voulais simplement écrire un code utile que mes collègues pourraient reprendre avec plaisir, ou tout du moins sans difficulté particulière, et sans me haïr par-dessus tout. On peut légitimement se demander si la motivation de sauver son honneur ne serait-elle pas supérieure à celle d’être simplement bienveillant. Sans entrer dans le détail, je vous indiquerais deux façons de raisonner sur ce point, même si à nouveau, le mode de pensée n’est jamais binaire :
- la recherche d’amélioration perpétuelle, non sentimentale, permettant d’accepter la critique comme une étape vers la progression : “vous n’êtes pas votre code” ;
- la fierté de bâtir son édifice, d’y avoir mis de sa personne, au point de s’y attacher et de prendre la critique à son code comme une critique à “une partie de soi".
J’ai constaté que l’outillage amenait une bonne complétude lors du processus de revue de code, et un compromis entre ces modes de pensée, ou du moins une façon d’amener le mode de pensée favorisant la remise en question, tout en ayant un maximum de tact dans la façon de l’amener. Effectivement, il est difficile de se vexer lorsqu’un outil nous remonte un problème que nous n’avions pas vu. Au mieux, on peut passer ses nerfs sur l’outil, chose qu’il n’est pas souhaitable de faire envers notre collègue… Le fait d’impliquer un outil comme SonarQube permet au développeur de maintenir sa bulle, à la façon des tests automatisés assurant la non-régression fonctionnelle, avant de dévoiler son travail aux yeux de tous.
CHAPITRE 1. Mieux que du dashboarding
La plupart des mises en oeuvre de SonarQube que j’ai pu constater sont basées sur le dashboard SonarQube. C’est-à-dire qu’on ajoute l’analyse SonarQube sur notre master, develop ou je ne sais quelle branche, ce qui va permettre de constater l’évolution de la qualité selon SonarQube au fil des releases, et pour les développeurs bienveillants d’aller voir régulièrement si leur travail a provoqué des régressions sur la qualité. Ça revient à la même chose que positionner le lancement des tests unitaires sur les branches master, develop [...].
Voyons trois problèmes à se contenter de ceci :
Problème numéro 1 : La perte de réactivité
Détecter des problèmes de qualité seulement après avoir effectuer un merge de son travail est dommage. Tout simplement pour le gain de temps, autant réaliser un merge de l’ensemble du code lié à la feature en question. Ceci évite de déranger une deuxième fois son collègue pour lui dire “je viens de soumettre une deuxième demande de revue de code, je n’avais pas vu des imports non utilisés”. Enfin, cela permet de conserver un historique Git propre.
Réactivité apporte satisfaction. On s’efforce de retrouver la notion de “tighten the feedback loop” à tous les niveaux :
- dans le monde DevOps et dans la mise en place de MVP, où le but est d’avoir un feedback du monde réel, celui de la production, via du monitoring et de l’analytics par exemple,
- dans la pratique d’architecture émergente, visant à réduire le TTV,
- dans les pratiques de développement comme le TDD, avec un besoin “local” de s’assurer que tout fonctionne, sans attendre une éternité, avec des tests unitaires vraiment unitaires et vraiment pertinents, évitant les régressions fonctionnelles détectées tardivement,
- et dans les chaînes d’intégration continue, précisément celle dont on va parler.
Dans un monde arc-en-ciel, un plugin comme SonarLint installé sur l’IDE de chaque licorne-développeuse serait largement suffisant, et nous n’aurions même pas besoin d’un serveur SonarQube. Dans ce monde arc-en-ciel, les licornes-développeuses n’oublieraient jamais de corriger les mauvaises pratiques constatées (du moins celles étant pertinentes à corriger) avant même de commit leur travail. Mais nous autres pauvres humains, pouvons ne pas voir, oublier, ne pas avoir le temps, ou tomber momentanément dans la paresse… Dans tous les cas, c’est une très bonne approche d’installer ce plugin, puisque nous venons de le dire, il permettra de réduire fortement la boucle de feedback, permettant de corriger le plus d’erreurs possibles à la source.
Problème numéro 2 : Nous ne sommes pas des robots
Il est terriblement déplaisant lors d’une relecture de code d’avoir l’impression d’être aussi utile qu’un robot : “Ici c’est du camelCase”, “Cet import n’est pas utilisé”, “Tu as du code mort là”. Le robot, l’outil en l'occurrence, peut nous aider à faire ce travail, très certainement mieux que nous lorsqu’il devient répétitif. Il y a un tas de personnes chez SonarQube qui cogite pour poser à plat des règles censées nous aider à détecter nos erreurs, nous fournissant des exemples et des explications pertinentes pour nous améliorer. Ce travail répétitif de vérifier la présence de code mort, d’import non utilisé, de non-respect des conventions de nommage [...], c’est la raison même de l’informatique.
Le relecteur a besoin de se concentrer sur des choses beaucoup plus significatives, comme les problèmes de conception. Et si l’on peut lui faire gagner du temps, c’est toujours cela de pris.
Problème numéro 3 : A la recherche de la vérité vraie.
À l’image des tests unitaires qu’un développeur exécutera en local avant de push, la chaîne d’intégration continue exécutera quand même les tests unitaires pour s’assurer qu’il n’y a pas eu de régression.
De mon expérience, la seule façon concluante pour l’adoption de SonarQube a été, à l’image de la compilation et des tests unitaires [ou tout ce que l’on pourrait brancher sur la chaîne d’intégration continue], de combiner ces 2 approches : chaîne d’intégration continue et relecture de code. L’intégration entre outils est ainsi complète : le développeur crée sa merge request (GitLab) / pull request (GitHub, BitBucket) / revue de code (Gerrit), et sans changer d’outil, il verra directement sur sa requête le statut de la chaîne d’intégration continue, incluant SonarQube. En fait, paradoxalement, je viens de dire que la seule façon concluante pour l’adoption de SonarQube est de cacher SonarQube.
Voici la représentation que je pourrais proposer du workflow complet :
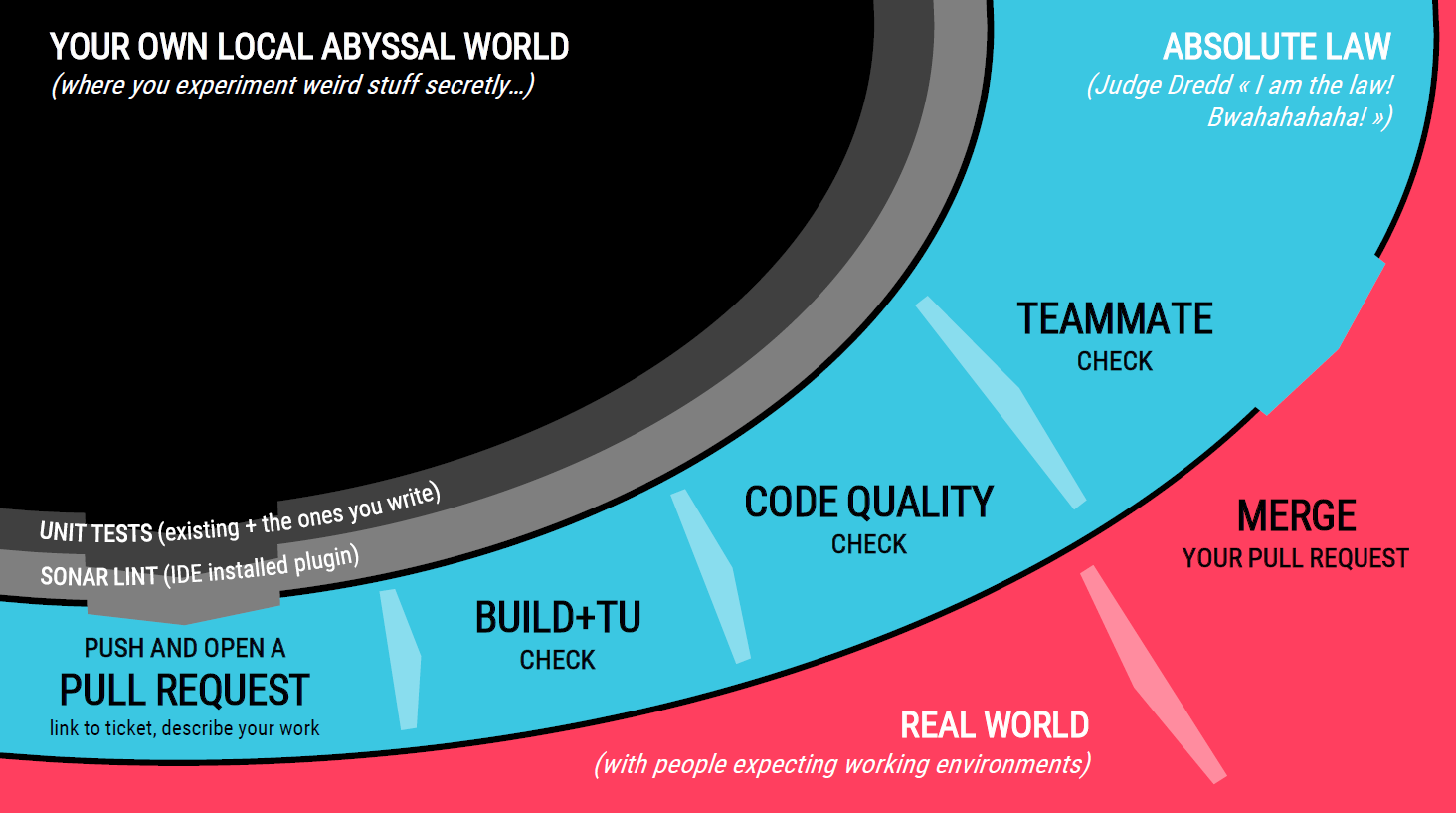
Ici je distingue explicitement 3 zones délimitées par les traits en gras :
- la zone locale, où nous cherchons un feedback extrêmement rapide, avant de solliciter quiconque pour une relecture du code ;
- la “loi absolue”, où une multitude de vérifications automatisées et manuelles sera effectuée, dans laquelle nous glisserons SonarQube ;
- et la suite que je ne détaillerai pas, car hors périmètre de cet article.
CHAPITRE 2. Un peu de concret outillé ?
Disclaimer : Je vais vous parler de la fonctionnalité "Pull Request Decoration" de SonarQube, qui est disponible depuis la version 7 dans un plan payant à partir de la "Developer Edition", ou équivalent sur SonarCloud en mode SaaS. Dans les versions inférieures à 7, le mode d'analyse "preview" permettait gratuitement d'avoir la même réactivité, de manière légèrement dégradée. Je ne touche pas de commission de la part de SonarQube :D mais la Developer Edition est disponible à partir de 120€ par an pour 100 000 lignes de code. Cela signifie que si vous gagnez un quart de journée par an en cumulé sur votre équipe, ce serait déjà rentable.
Pour appliquer le workflow proposé précédemment, nous cherchons à amener visuellement les éléments suivants, directement au niveau de la pull request :
- un feedback général, décisionnel, tranchant : est-ce que SonarQube approuve ou rejette la pull request ? Ceci basé sur la notion de Quality Gate configurable.
- un feedback listant les problèmes dans le cas où la pull request est rejetée, et apportant les solutions (par exemple un lien vers la règle SonarQube).
Le “problème” réside maintenant dans la combinatoire d’outils que vous utilisez. Nous avons une fâcheuse tendance à diversifier nos expériences. Gerrit, GitLab, GitHub, Jenkins, Travis, Azure DevOps, BitBucket… Et je ne parle ici que de SonarQube, je n’ai pas étudié CodeClimate, ou d’autres outils d’analyse statique de qualité.

Je ne pourrais vous proposer de guide exhaustif. La configuration de ce workflow qualitatif sur un mix Gerrit + Jenkins + SonarQube a déjà été présentée ici et le replay de Luca Milanesio au JenkinsWorld 2018 devrait vous combler. Voici toutefois quelques indications sur la réalisation de cette configuration sur un mix GitHub + Jenkins + SonarQube, et plus important encore, le rendu final.
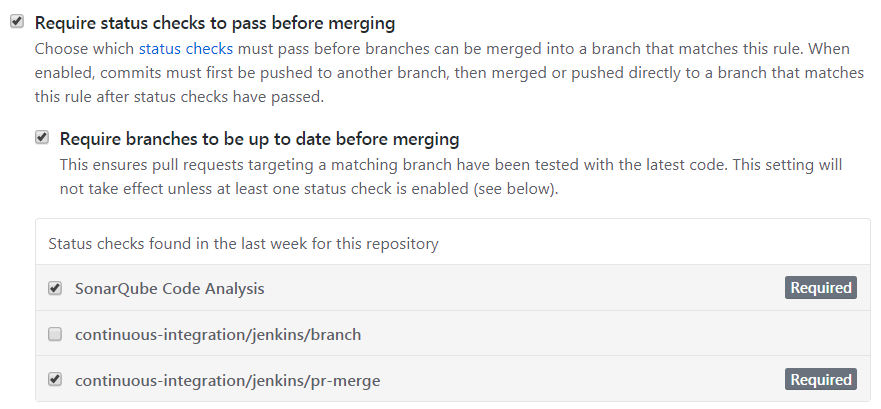
Dans la configuration d’un dépôt GitHub, il est possible d’exiger l’attente de certaines vérifications avant de donner la possibilité de merge une pull request. Dans l’exemple ci-dessous, il est exigé que les branches soient à jour par rapport à la branche de destination, et que l’analyse SonarQube et le build Jenkins valident la pull request. Ceci constitue le “garde-fou” :
Le schéma que nous mettons en place est le suivant :
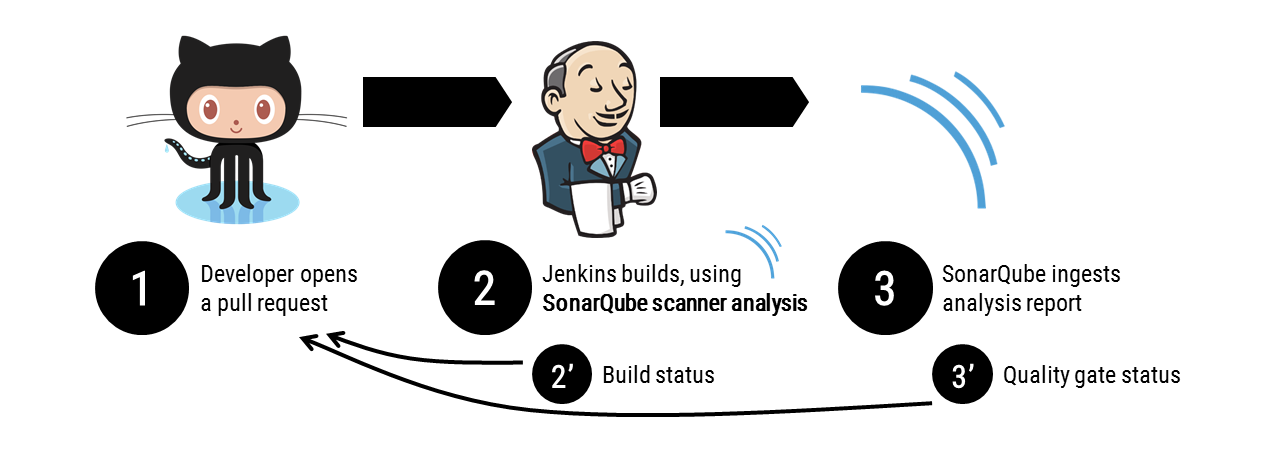
- A chaque fois qu’une pull request va être créée ou mise à jour, Jenkins sera notifié via un pipeline écoutant le dépôt de source.
- La construction Jenkins inclut la compilation, l’exécution des tests unitaires, le calcul de la couverture de code [etc.] et contient une étape d’analyse de code. Cette étape permet l’exécution du SonarQube Scanner sur le nœud esclave Jenkins, et l’envoi du rapport généré à notre installation SonarQube. À la fin du build, Jenkins envoie un feedback à GitHub en (2’). Ce feedback ne contient que le “statut” du build, Jenkins n’est pas conscient à ce moment des potentiels problèmes de qualité de code.
- SonarQube ingère le rapport, et compare avec la branche actuelle (oui SonarQube est sympa, il fonctionne en mode delta, c’est-à-dire qu’il vous accusera uniquement des problèmes que vous avez introduits, pas de ceux qui étaient déjà présents). Suite à cette analyse, il fera lui-même le feedback à GitHub en (3’).
La configuration est distribuée sur tous les outils :

- Une GitHub App permet de s’interfacer avec une solution de manière sécurisée, en déclarant finement les autorisations données à un client. Il s’agit donc de déclarer une app dédiée à SonarQube, afin que ce dernier ait le droit de mettre à jour les pull requests.
- L’utilisation du plugin SonarQube Scanner pour Jenkins va grandement simplifier la tâche. Toutefois, dans le cadre d’un pipeline, une configuration au niveau du
Jenkinsfilesera requise pour aider SonarQube à retrouver la bonne pull request, et pouvoir faire son feedback. - SonarQube offre une intégration aisée avec certains dépôts Git, tel que GitHub, GitLab, BitBucket et Azure DevOps. L’identifiant et la clé sécurisée de la GitHub App doivent être configurées ici. Pour ceci, comme mentionné précédemment, nous utiliserons la fonctionnalité “Pull Request Decoration” de SonarQube en “Developer Edition”.
En détaillant la ligne de commande du SonarQube Scanner, voici ce que ceci donnerait sur un Jenkinsfile pour un projet Java. En utilisant un autre scanner, une grande partie de cette configuration sera automatique. Une attention particulière à porter sur le deuxième bloc contenant les paramètres sonar.pullrequest, qui vont aider SonarQube à retrouver la pull request en attente d’un feedback :
stage('SonarQube code analysis') {
def pom = readMavenPom file: 'pom.xml'
def sonarQubeArgs =
" -Dsonar.scm.provider=git"
+ " -Dsonar.projectKey=AWESOMEPROJECT"
+ " -Dsonar.projectVersion=${pom.version}"
+ " -Dsonar.java.source=11"
+ " -Dsonar.sources=src/main/java"
+ " -Dsonar.tests=src/test/java"
+ " -Dsonar.java.binaries=target/classes"
+ " -Dsonar.java.libraries=target/dependency"
def sonarQubePullRequestArgs = ""
// CHANGE_ID, CHANGE_BRANCH and CHANGE_TARGET are dynamically supplied by Jenkins multibranch pipeline
if (isPRBuild) {
echo "Building a change request : supplying arguments for pull request decoration"
sonarQubePullRequestArgs =
" -Dsonar.pullrequest.key=" + CHANGE_ID
+ " -Dsonar.pullrequest.branch=" + CHANGE_BRANCH
+ " -Dsonar.pullrequest.base=" + CHANGE_TARGET
+ " -Dsonar.pullrequest.github.repository=myorganization/myawesomeproject"
+ " -Dsonar.pullrequest.github.endpoint=https://api.github.com/"
+ " -Dsonar.pullrequest.provider=GitHub"
}
def scannerHome = tool 'SonarQube Scanner'
withSonarQubeEnv('SonarQube') {
sh "${scannerHome}/bin/sonar-scanner ${sonarQubeArgs} ${sonarQubePullRequestArgs}"
}
}
L’attendu final est celui-ci sur la pull request GitHub :
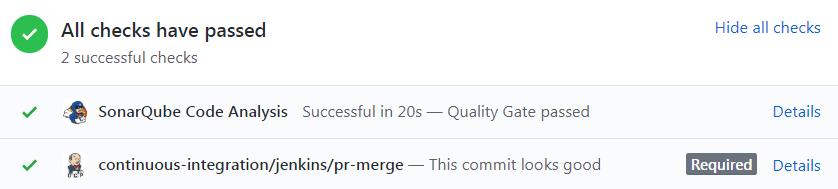
La notion de “Quality Gate” est configurable sur SonarQube. On peut adapter ce seuil de qualité pour interdire toute régression de note, toute erreur bloquante, et bien d’autres options. Sur GitHub, un résumé de l’analyse SonarQube est disponible dans l’onglet “Checks” :
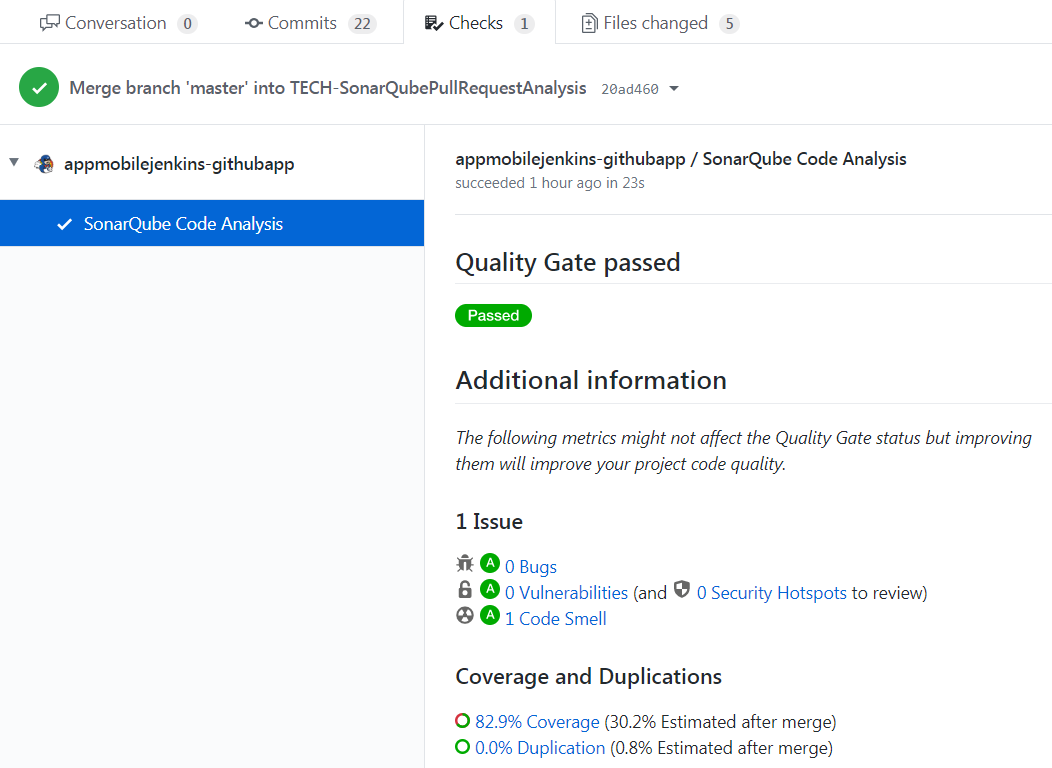
CONCLUSION
J’ai la conviction peut-être naïve que la qualité est préférable à la quantité, que ce soit en amitié, dans les biens, la nourriture… Le développement n’en fait pas exception : une bonne feature en mode MVP vaut mieux que quinze features mal conçues, inutilisables ou inutilisées. Il paraît évident mais impossible à chiffrer que la qualité apporte une réduction globale du coût de maintenabilité, d’évolutivité, d’exploitation, en plus de faire progresser nos équipes, et de leur apporter sérénité.
Dans ce but de contribution à la qualité, la mise en place d’un filet de sécurité qualitatif “a priori” (i.e. avant que le problème ne s’ancre dans le logiciel livré) me semble être une bonne approche. Celle de faire de la qualité à moindre coût, au plus proche du développeur, tant qu’il a encore les mains dans le code, tout en considérant une boucle de feedback appréciable, et une intégration outillée des plus efficaces.
Je finirai avec le même rappel qu’en début d’article : l’analyse de code statique est un des moyens à mettre en œuvre, et elle seule ne suffira pas à considérer un logiciel comme pleinement qualitatif. SonarQube n’analyse que des lignes de code, et y applique une suite de règles. Ses limites à percevoir la qualité sont celles que son angle de vue lui impose. Il faudra chercher du côté des pratiques de design, des concepts architecturaux, et des stratégies de test, pour considérer la qualité sous des angles différents.
Je vous invite à consulter ce comic strip cat.alert traitant du même sujet, mais résumé en 6 trames BD (que ma femme et moi publions).
Icons made by Adib Sulthon from www.flaticon.com
