

L’objectif de cet article est de montrer une solution pour pouvoir faire une recherche rapide par mots-clés et paginer ses résultats en appliquant une règle de tri, en utilisant Elasticsearch, Java, Spring et Angular.
Pour effectuer des recherches performantes parmi un large ensemble de données, il faut se tourner vers un moteur d’indexation et de recherche. L’un des leaders du marché est Elasticsearch, qui stocke des “documents” JSON requêtables via une API RESTful. Ces recherches sont paramétrables, avec par exemple ce qu’on appelle le slop, qui est le nombre maximum de termes (i.e. mots-clés) intermédiaires entre deux termes de notre recherche.
Problématique
Prenons un exemple concret : je suis une entreprise qui permet aux inscrits de proposer des services aux autres internautes. Les services des utilisateurs payant un abonnement doivent remonter avant ceux sans abonnement. Voici ce que l’on cherche à avoir :
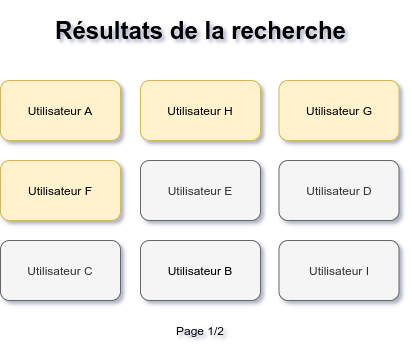
Les résultats de recherche sont classés en deux zones : utilisateurs payants (en jaune) et gratuits (en gris)
Elasticsearch se base sur un score, calculé par le moteur de recherche pour nous renvoyer les résultats les plus pertinents en premier. Ce score est représenté par un nombre réel positif. Plus le score est grand, plus le résultat est pertinent. Donc, pour une même requête, le résultat de la recherche est a priori déterministe.
Oui, mais voilà le couac : c'est toujours le même utilisateur qui remonte en premier parmi ceux qui paient le même prix.
Dans ce cas, une solution serait de mélanger (randomiser) les résultats. Cela permettrait de ne pas afficher tout le temps les mêmes utilisateurs en premier. Partons sur l’hypothèse que, a priori, on pourrait tout simplement demander à Elasticsearch d’ordonner sa liste suivant un score attribué à chaque document. Problème : nos résultats sont censés être paginés. Donc, lors de la requête de la page 2, le score serait recalculé pour chaque document, avant même de récupérer notre page ! On ne garde pas de trace de nos pages précédentes, on peut alors se retrouver avec un utilisateur déjà vu en page 1 dans n’importe quelle autre page, bref, ça n’aurait aucun sens, comme présenté sur le schéma ci-dessous.
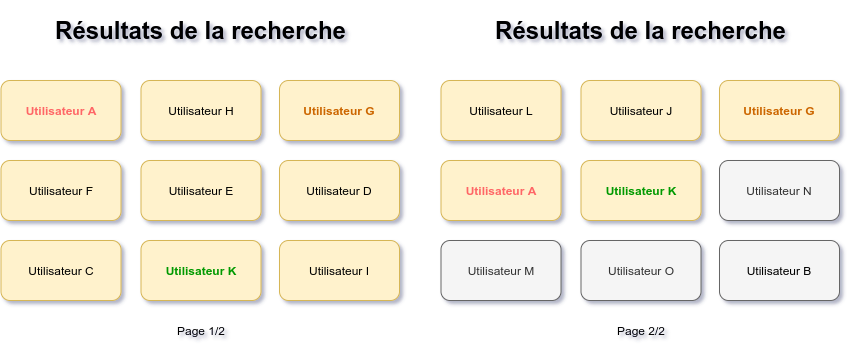
Lors du passage à la page 2, on peut retrouver les mêmes utilisateurs que sur la page 1
Pour pallier ce problème, nous devons donc définir un nombre aléatoire, que nous allons garder en local côté client pour le renvoyer à l’API à chaque demande de nouvelle page. Nous appellerons ce nombre la seed.
Rappels concernant la fonction de randomisation java.util.Random :
La fonction de randomisation (i.e. génération de nombre aléatoire) en Java peut prendre en paramètre un nombre appelé seed, qui servira de graine à la génération de la série de nombres pseudo-aléatoires. À chaque fois que l’on appellera la fonction
next(), un nouveau nombre issu de cette série nous sera renvoyé. Cela implique que si on utilise la même seed, alors nous aurons la même série de nombres pseudo-aléatoires. La fonction Random devient alors déterministe.
Dans notre cas, le besoin demande d’avoir les utilisateurs payants en premier, suivis des utilisateurs gratuits. Dans ce cas, nous utiliserons la seed pour créer un score personnalisé qui servira à doper les scores des utilisateurs payants, comme le montre le schéma ci-dessous.
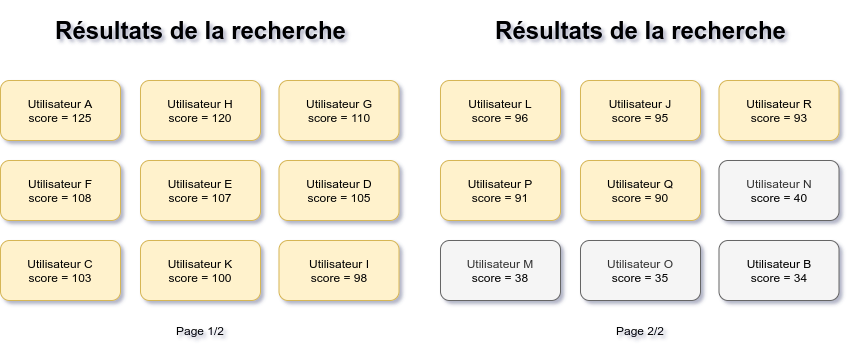
Les scores finaux des résultats de la recherche.
Plantons la graine côté Front !
Pour cela, nous allons générer une seed côté front, et l’intégrer en paramètre à notre URL. Cela nous aidera dans les cas suivants :
- Si l’utilisateur décide de naviguer en arrière, il pourra retrouver les résultats dans le même ordre.
- Si l’utilisateur veut mettre en favoris sa recherche, il retrouvera les résultats dans le même ordre.
- En revanche, si l’utilisateur n’utilise pas le paramètre de l’URL alors la seed sera réactualisée.
Pour permettre aux utilisateurs de sauvegarder l’état de leurs recherches, il faut aussi ajouter le searchText en paramètre de l’URL, en plus du seed. L’utilisateur pourra ainsi mettre en favoris la page, et lors de son rechargement les mêmes paramètres seront envoyés à l’API, et l’ordre de nos résultats sera alors conservé.
Ici, dans notre client Angular, c’est dans le ngOnInit() que nous initialisons notre seed. Nous l’ajoutons en queryParam à notre URL pour les raisons évoquées ci-dessus.
ngOnInit(): void {
this.route.queryParamMap
.pipe(take(1))
.subscribe((params: ParamMap) => {
this.seed = params.get('seed');
if (!this.seed) {
this.seed = Math.random().toString(36)
+ new Date().getTime().toString(36);
}
});
}
La seed que nous générons ici est en fait une chaîne de caractères aléatoires, dont nous récupérerons le hashCode (un entier unique) dans le back-end.
Récupérons notre graine côté Back !
Pour passer notre fameux paramètre seed au back, afin de l’utiliser avec le moteur de recherche Elasticsearch, nous devons donc transformer notre chaîne de caractères générée dans le front-end (voir section précédente). Pour cela, nous prenons le hashCode, qui renvoie un entier signé.
Pour pouvoir contrôler les valeurs de nos scores, nous décidons de situer la seed entre 100 000 et 200 000. En effet, pour pouvoir booster notre score, nous rajoutions arbitrairement la seed dans le paragraphe précédent : si la seed est trop petite, alors le boost n’aura aucun effet. Cette logique est implémentée dans le code ci-dessous :
Map<String, Object> params = new HashMap<>();
params.put("seed", Math.abs(seed.hashCode() % 100_000) + 100_000);
Script script = new Script(
ScriptType.INLINE,
"painless",
scriptString,
params);
Nous stockons nos paramètres dans une HashMap, où ici nous prenons le modulo 100_000 du hashCode de notre seed. La variable scriptString correspond à la string contenant le script Painless que nous allons voir dans la section suivante.
Donnons notre logique à Elasticsearch !
Afin de pouvoir exécuter notre logique, Elasticsearch met à disposition en Java un QueryBuilder auquel nous pouvons fournir un script, ici écrit en Painless, une variante simplifiée de Java fournie par Elasticsearch. Ce script explique au moteur de recherche la façon dont il faut calculer le score pour chaque document. La logique expliquée plus haut est retranscrite dans le script Painless suivant :
double score = Math.abs(
new Random(
params.seed + Integer.parseInt(doc['_id'].value)
).nextInt() % 100);
score += params.seed;
if (doc['paidOrPromoted'].value) {
score += 10 * params.seed;
}
return score;
Le score doit être un double pour fonctionner avec la gestion des scores de Elasticsearch. On se sert de l’id du document (un entier, unique bien sûr 🙂) combiné à notre seed reçue par le front pour initialiser notre Random (cf. les rappels de la fonction de randomisation java.util.Random plus haut). Cela nous permet donc d’avoir toujours le même score pour une seed et un ID donné. Par conséquent, le score d’un document change si et seulement si la seed que nous envoie le front change.
De plus, si le document correspond à un utilisateur payant ('paidOrPromoted'), alors on booste son score en lui ajoutant arbitrairement notre seed plusieurs fois.
On câble tout pour Elasticsearch !
Enfin, nous paramétrons notre requête avec les string à chercher dans les documents, l’ordre que nous souhaitons, les index à utiliser, et le pageable à utiliser.
Ce qui nous intéresse désormais, c’est de pouvoir trier nos résultats. Pour ce faire, on utilise un SortBuilder, qui va prendre notre script Painless en paramètre. On précise bien que l’on veut les résultats dans l’ordre décroissant, pour avoir les scores les plus grands en premier.
sort = SortBuilders
.scriptSort(script, ScriptSortType.STRING)
.order(SortOrder.DESC);
Ensuite on définit notre QueryBuilder, qui permet de faire la recherche Elasticsearch. Ici on demande à Elasticsearch de rechercher un ou plusieurs mots-clés (la variable term) sur notre champ nameField, en autorisant un slop. Le slop est le nombre maximum de termes (i.e. mots-clés) intermédiaires entre deux termes de notre recherche. Par exemple, sur la liste de courses suivante, un slop de 1 permettra de remonter les éléments en verts mais pas ceux en rouges si l’on recherche “lait soja” :
- Lait (pas “soja” dans le résultat)
- Lait de soja (un seul terme entre “lait” et “soja”)
- Lait ultra concentré en soja (trois termes entre “lait” et “soja”)
- Lait de soja vanille (un terme entre “lait” et “soja” et un terme après “soja”)
QueryBuilder query = matchPhrasePrefixQuery(nameField, term)
.slop(PHRASE_PREFIX_NAME_SLOP);
Enfin, on définit la SearchQuery qui va agréger tous les objets définis précédemment. On lui passe donc notre query ci-dessus, notre sort, ainsi que notre pageable, qui nous vient directement de la méthode appelante. Ce Pageable est un objet Spring.
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(query)
.withSort(sort)
.withIndices(DirectorySearch.SOFTWARE_INDEX,
DirectorySearch.SUPPLIER_INDEX)
.withPageable(pageable)
.build();
On peut alors lancer la recherche Elasticsearch avec notre searchQuery et on lui précise d’extraire nos résultats dans notre pageable.
return ElasticSearchTemplate.query(searchQuery, extractResults(pageable));
Verdict ?
Elasticsearch permet donc de personnaliser l’ordre de pertinence de ses réponses, via le score. En utilisant un script Painless adapté, on peut tout à fait paramétrer sa propre logique pour voir apparaître certains résultats en priorité. Cependant, cela demande beaucoup de paramétrage en amont d’Elasticsearch. On peut voir qu’au final beaucoup de lignes sont en fait dédiées à la configuration de l’objet SearchQuery d’Elasticsearch. On y spécifie la Query qui permet de créer la recherche par mot, mais aussi le Sort qui constitue le sujet de cet article. En l'occurrence, on y précise aussi les Indices (Index au pluriel) qui sont requêtés, et le Pageable sur lequel stocker nos résultats.
Aussi, cette solution n’est envisageable que pour une recherche par termes (recherche exacte). Dans le cas d’une recherche full-text, la seed aurait beaucoup trop d’incidence et enlèverait toute la partie pertinente du scoring.
Un inconvénient de cette méthode est que le script Painless doit être écrit dans une String Java, ce qui rend la lecture du code hasardeuse. Un axe d’amélioration serait de pouvoir externaliser ce script Painless dans un fichier ressource que l’on pourrait appeler dans cette méthode. On pourrait aussi trouver une meilleure façon de gérer le taille arbitraire de la seed, qui est actuellement située en 100 000 et 200 000, ce qui pourrait poser un problème si les ID de nos documents venaient à égaler ou dépasser cette valeur.
Un autre point à souligner est que si un nouveau client, payant ou non, est mis en ligne entre deux requêtes, alors l’ordre des clients va changer. On peut, dans notre cas, penser que c’est un cas à la marge qui ne se présentera presque jamais. Cependant, il est important de le garder en tête pour toute autre implémentation.
Enfin, une autre approche aurait été d’utiliser l’API Scroll que propose Elasticsearch. Celle-ci permet de figer le contexte d’une requête et d’en paginer les résultats. On retrouve alors l’idée de stabilité dans les résultats.
Annexe: Implémentation entière
public Page<DirectoryEntryDTO> getSearchResults(String term, String seed, SearchType searchType, Pageable pageable) {
final String nameField = "name";
final SortBuilder sort;
String scriptString = "" +
"double score = Math.abs(new Random(params.seed + Integer.parseInt(doc['_id'].value)).nextInt() % 100);\n" +
"score += params.seed;\n" +
"if (doc['paidOrPromoted'].value) {\n" +
" score += 10 * params.seed;\n" +
"}\n" +
"return score;";
Map<String, Object> params = new HashMap<>();
params.put("seed", Math.abs(seed.hashCode() % 100_000) + 100_000);
Script script = new Script(ScriptType.INLINE, "painless", scriptString, params);
sort = SortBuilders.scriptSort(script, ScriptSortType.STRING).order(SortOrder.DESC);
QueryBuilder query = matchPhrasePrefixQuery(nameField, term)
.slop(PHRASE_PREFIX_NAME_SLOP);
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(query)
.withSort(sort)
.withIndices(DirectorySearch.SOFTWARE_INDEX,
DirectorySearch.SUPPLIER_INDEX)
.withPageable(pageable)
.build();
return ElasticSearchTemplate.query(searchQuery,
extractResults(pageable));
}
