
Contexte
Notre cluster de stockage Ceph contient 32 disques SATA (4To) et 8 disques SSD (500Go) pour la partie Rados Block Device. Ce stockage en mode bloc est la base du cloud privé chez Ippon Technologies.
L’augmentation de sa capacité a été faite au fil des années en conservant les anciens disques et en y intégrant des nouveaux. Afin d’anticiper les problèmes sur les moins récents (ajoutés au cluster il y a plus de 5 ans) nous avons procédé à leur remplacement.
Cela a impliqué le changement de :
- 12 disques SATA
Noeuds de stockage, chaque disque SATA exécute un Object Storage Daemon (OSD) intégré au cluster. Les OSDs sont des services communiquant entre eux et qui sont en charge du stockage distribué. Dans un cluster Ceph en production, sur un disque SATA ne s’exécute qu’un unique OSD (pour éviter les conflits).
- 3 disques SSD
Noeuds de journal où les lectures/écritures sont intenses. Dans notre infrastructure chaque SSD est responsable d’un groupe de 4 OSDs.
Le schéma suivant illustre la composition d’un de nos serveurs dédiés à Ceph, et les liens que les différentes entités entretiennent entre elles en son sein.
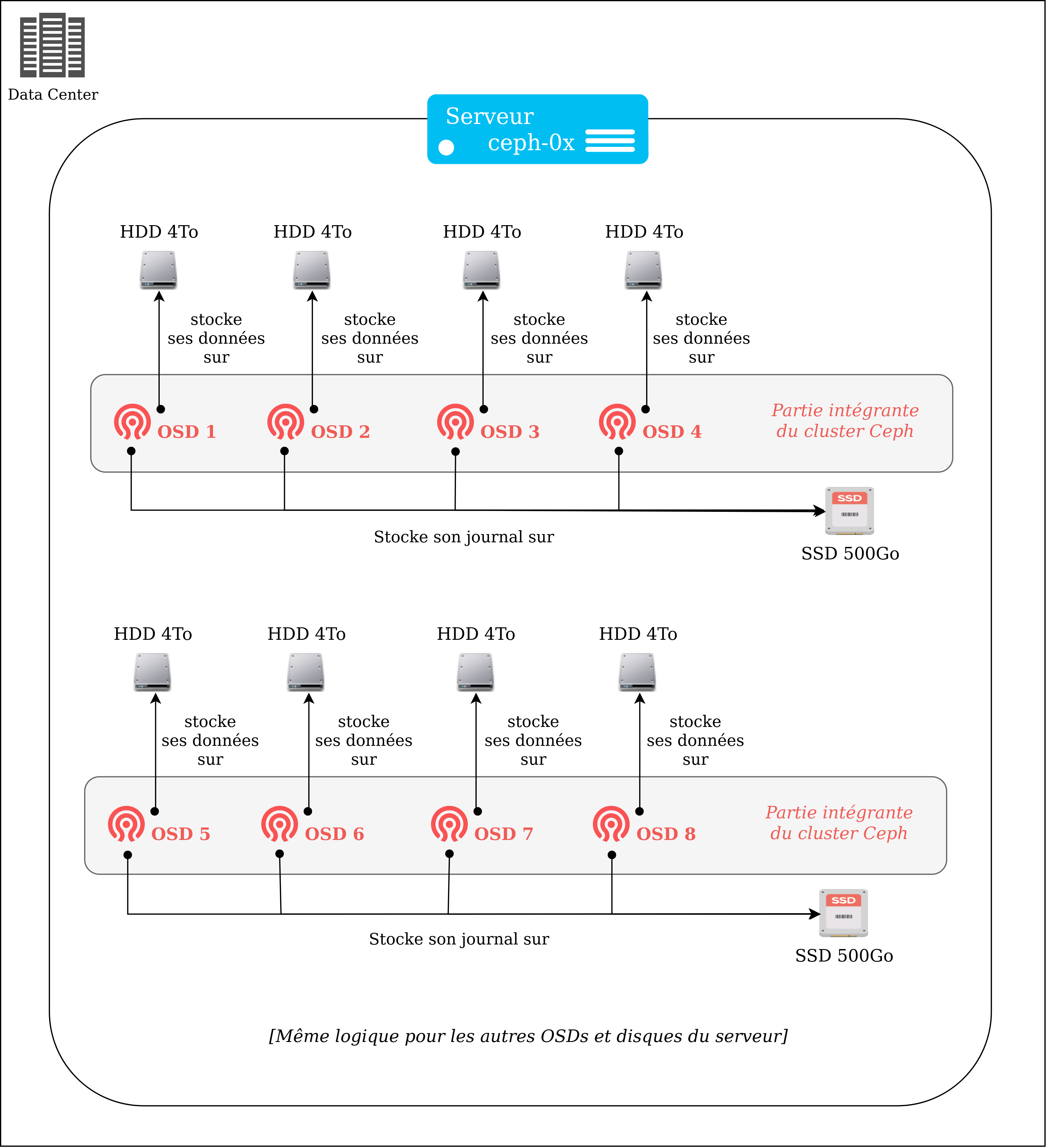
L'opération a été effectuée sur 3 serveurs de ce type. Pour ne pas impacter l’utilisation du cluster par les clients, les opérations ont été découpées en plusieurs parties. Pour chaque serveur la procédure a été la même :
- Sortie des OSDs du cluster : Ralentissement potentiel
- Remplacement physique des disques en datacenter : Aucun impact
- Intégration des nouveaux OSDs dans le cluster : Ralentissement potentiel
Note
Le peu d’informations précises disponibles sur internet et la volonté d’un retour d’expérience sur ce type d’opération sensible ont motivé l’écriture de cet article. Étant un article assez technique, une relative expérience sur Ceph rendra sa lecture plus confortable ; mais les notions clés seront expliquées le long de l’article. Hang in there ! 💪
Actions réalisées
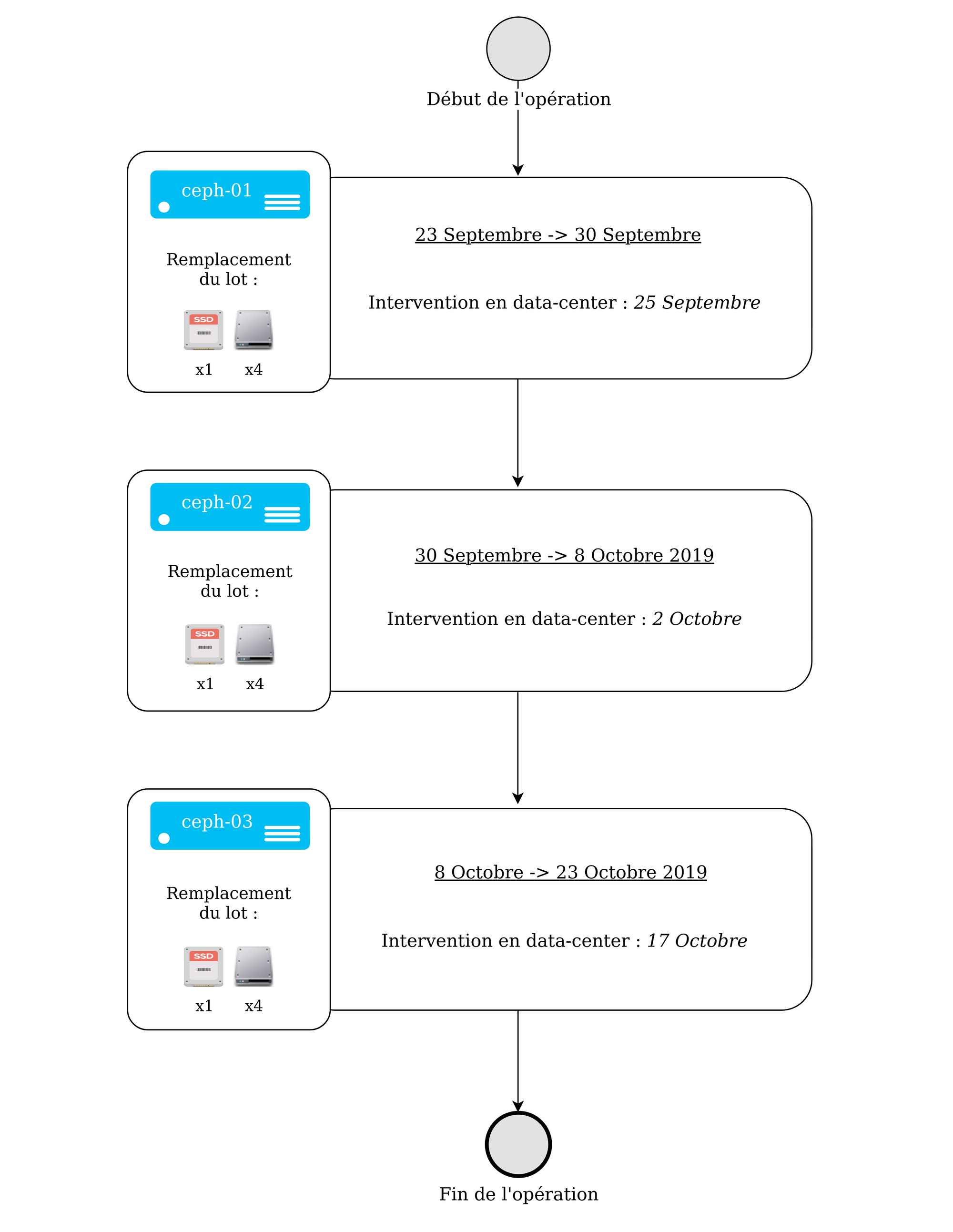
Chaque déplacement en data-center correspondait au remplacement physique de nos disques. Nous avons recensé quelques remarques quant-aux trois principales étapes du remplacement de nos disques, notamment un imprévu qui a changé le rythme de l’intégralité de l’opération.
ceph-01
Il y a eu environ 20To de données transférées lors de cette première intervention, contre 10 attendus. Un double mouvement de données a été repéré et nous a contraint d’attribuer deux fois plus de temps que prévu à l’opération totale. Nous avons commencé à chercher une manière de nous en affranchir.
ceph-02
Une solution pour éviter le double rebalancement des données a été étudiée sur notre cluster de test. Aucun ralentissement client noté pour une nouvelle fois 20To de données déplacées.
ceph-03
Moins de temps a été accordé à ce dernier serveur car nous avions d’autres projets importants en parallèle et pas de limite de temps critique à respecter. Le double mouvement de données est désormais évité après avoir mis en place une nouvelle procédure, testée et validée sur notre cluster de développement.
Une explication détaillée est disponible en fin d’article pour les plus curieux.
Procédure
Pour remplacer les disques de chaque serveur (ceph-0x), la procédure a été la suivante :
- Connexion en ssh sur le serveur cible (doté des 4 SATA liés à 1 unique SSD de journal à remplacer) afin de pouvoir commencer les manipulations.
- Récupération des identifiants des OSDs liés aux disques et partitions que l’on souhaite remplacer. (e.g. on souhaite sortir le disque sdc du serveur ceph-01 et on identifie que c’est l’osd.7 qui s’exécute dessus). Une fois la liste des identifiants établie, nous pouvons lancer nos commandes.
- Sortie des OSDs du cluster par l'exécution des commandes suivantes :
ceph osd out XX
# Marquage de l’OSD comme non disponible au cluster
# 1er mouvement de données, ~10To rebalancés
stop ceph-osd id=XX
# arrêt de l'exécution de l’OSD sur le serveur
ceph osd crush remove osd.XX
# Sortie logique de l’OSD du cluster
# 2nd mouvement de données (non prévu), ~10To rebalancés
ceph auth del osd.{osd-num}
# suppression des clés d’authentification de l’OSD au cluster
ceph osd rm {osd-num}
# suppression définitive de l’OSD du cluster
où XX est l’identifiant de l’OSD en question.
Cette suite de commandes a donc été lancée 4 fois par serveur, une fois par OSD. Quelques commandes utiles d’optimisation sont détaillées en fin d’article.
- Une fois les 4 OSDs sortis du cluster, déplacement en data-center et face à nos racks, identification des disques physiques à sortir grâce à leur led (ledctl).
- Sortie successive des disques durs du serveur puis insertion des nouveaux.
- Une fois les 4 disques et le SSD remplacés, nous procédons à un test d’écriture sur les disques de fichiers lourds comme d’une multitude de fichiers légers (dd -if= … ) afin de nous assurer du bon fonctionnement de nos nouveaux disques.
- Création puis ajout d’un nouvel OSD dans le cluster.
- Utilisation de l’outil de déploiement ceph-deploy pour créer et ajouter les nouveaux OSDs au cluster :
ceph-deploy --overwrite-conf osd create ceph-0X:sdY:/dev/sdZ
où sdY représente l’emplacement du disque de stockage (SATA) réservé à l’OSD ; et sdZ l’emplacement de son journal associé (SSD). Sur un même server ceph-0X, les 4 OSDs partageront le même sdZ.
- Pour le premier ajout dans le cluster, nous avons pour habitude de rester au datacenter pour s'assurer que tout se passe bien au premier rebalancement des données et être prêt à intervenir en cas de besoin.
- Ajout par la suite des autres OSDs au cluster en suivant la même procédure, de manière distante.
Remarque : Il ne présente pas de soucis d’enlever le SSD journal à chaud, une fois que l’on s’est assuré que plus aucun OSD n’écrit dessus. C’est d’ailleurs son unique fonction sur le serveur.
La procédure engendre de lourds mouvements de données, et garder un oeil sur notre cluster lors de ce genre d’opération sensible est essentiel. Constamment, l’état de notre cluster est monitoré et nous permet d’être réactif aux métriques importantes : c’est ce que nous allons voir dans la prochaine section.
Monitoring du cluster lors de l’opération
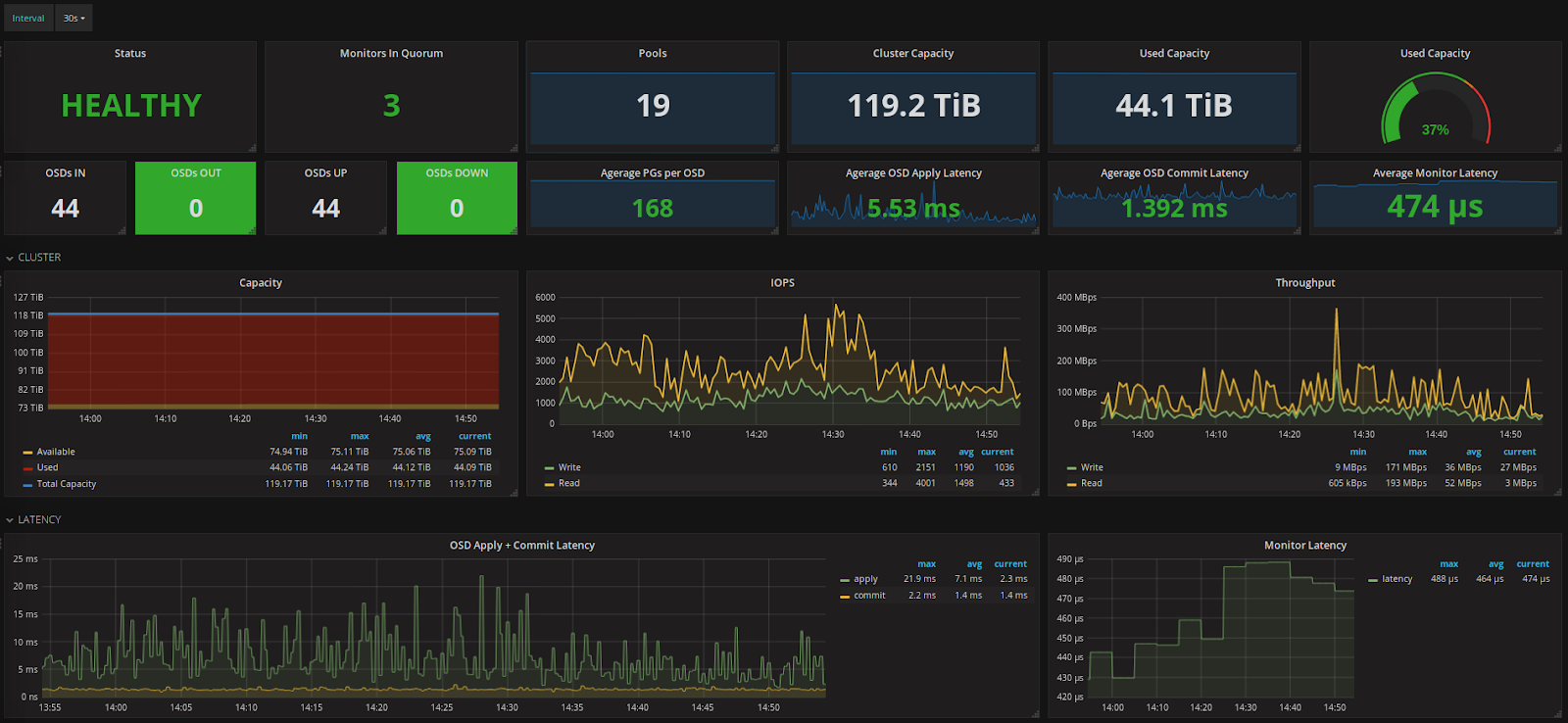
Nous utilisons plusieurs dashboards Grafana pour surveiller l’état de notre cluster, en y étant d’autant plus attentif lors de cette opération de remplacement.
Exemple de dashboard Grafana
Analyse des Placement Groups
L’analyse des Placement Groups (PGs) est une composante essentielle à l’ajout / suppression d’OSDs de manière successive. Basiquement, les PGs sont les paniers, groupes logiques où sont placées les données du cluster. Chaque OSD est en charge d’un certain nombre de ces PGs.
Lorsqu’un OSD est ajouté à notre cluster, il va devenir responsable d’un certain nombre de PGs. Ceux-ci étant stockés sur les autres OSDs, un transfert de données va s’opérer afin de remplir le nouvel OSD et d’alléger les autres.
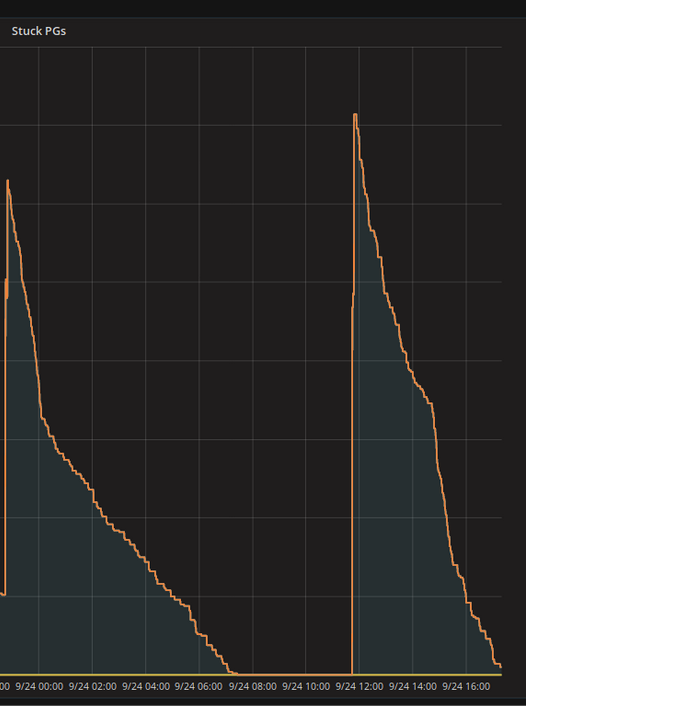
L’analyse des PGs et la fin de leur migration étaient nos indicateurs principaux avant de continuer sur la prochaine étape de l’opération (nouvel ajout/suppression d’un nouvel OSD).
Utilisation des disques du cluster
L’utilisation des disques est une métrique importante dans notre cas, car il est témoin direct de la charge de notre cluster. Une importante écriture de la part d’un client, un transfert d’information intense ou encore une vérification de la cohérence des données au sein du cluster seront tous retranscrits en terme d’entrées et sorties (d’utilisation) de nos disques.
On voit ci-dessous que l’ajout d’un OSD à 8h42 ce matin-là a engendré une montée en charge des différents disques de notre cluster (chacun représenté par une ligne de couleur). Les OSDs rentrent dans un premier temps dans une phase de peering, puis s’occupent du rééquilibrage des PGs par un processus de backfilling (transfert progressif des données entre les OSDs). Au début de cette phase, l’utilisation des disques atteint quasiment 100%.
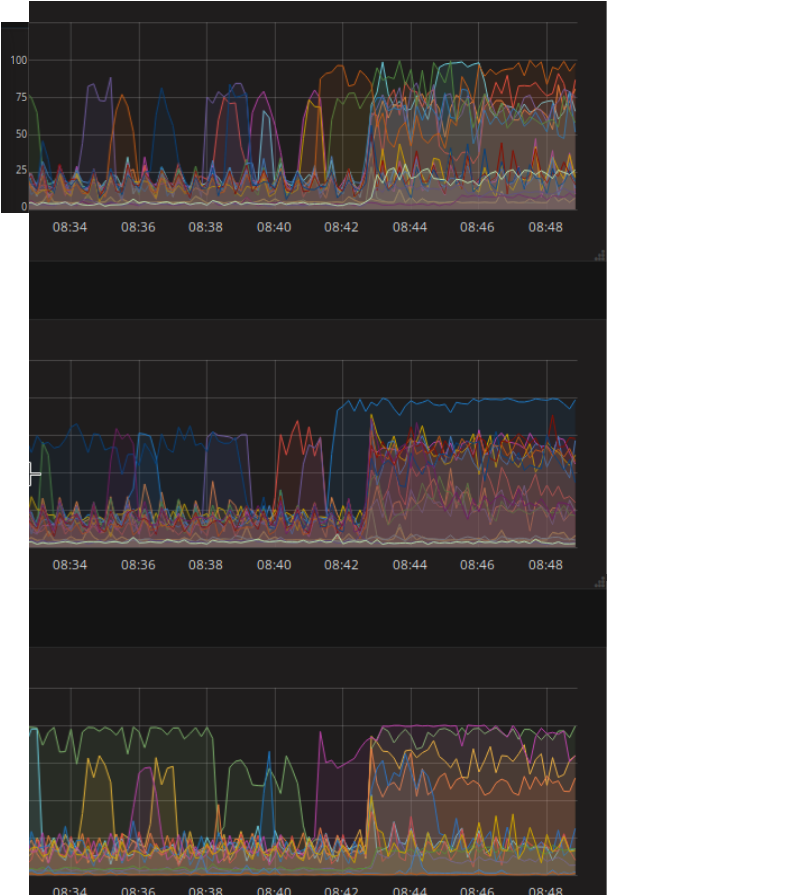
Nous savons que la charge sur notre cluster à travers ces opérations est très lourde : les équipes étaient prévenues et nous n’entamions pas d’autres manipulations qui auraient pu avoir des conséquences sur les performances auprès de nos clients. Pour plus d’informations quant aux PGs et au backfilling, vous pouvez vous référer à cet article. Encore une fois pour les curieux, des informations sur leur optimisation seront données en fin d’article.
Gestion de l’espace disque
Notre cluster va constamment chercher à garder le bon nombre de réplicats de ses objets défini dans sa configuration (la crushmap). Si l’on prend finalement l’exemple de la suppression d’un OSD, le cluster va donc recréer des PGs sur les OSDs restants en respectant la politique de placement définie dans la crushmap.
Cela consiste au transfert des PGs de l’OSD à supprimer vers les autres OSDs du cluster.
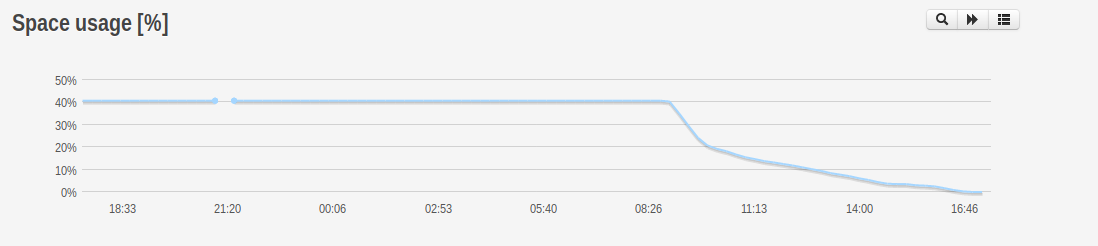
Pour cette raison, les opérations ont été divisées par serveur et étalées dans le temps : l’idée n’est pas de surcharger les OSDs restants du cluster en enlevant tous les disques d’un coup, mais bien de diluer les conséquences de ces ajouts et suppressions autant que possible.
Remarques post-opération
Éviter le double mouvement des données
Comme énoncé précédemment dans l’article, nous avons été gênés par un double mouvement de données non attendu lors de la sortie des OSDs du cluster en suivant la procédure officielle. Au lieu de déplacer une fois 10To de données, 20To étaient déplacés pour chaque OSD. En comptant que l’on ait 12 disques (donc OSDs) à remplacer, cela nous ramène à un mouvement données de 240To contre 120To planifiés. Au lieu de durer 2 semaines, l’opération en durera le double. Pour y pallier, nous avons pensé à une autre manière de faire :
Dans un premier temps, nous avons remarqué que pour chaque ceph osd out XX mais également ceph osd crush remove osd.XX de la procédure, nous assistions à un rebalancement des données entre nos OSDs. Ceci était prévu que lorsque l’on marquait notre OSD out, mais pas une seconde fois lorsqu’on le supprimait de la crushmap. Afin de nous réduire à un seul mouvement de données, nous avons légèrement modifié la procédure.
Chaque OSD est doté d’un poids dans le cluster, un pourcentage en fonction de sa capacité de stockage en général. On peut le définir dans notre crushmap pour chacun d'entre eux.
Avant même de lancer la première commande (ceph osd out XX), nous avons réduit le poids de notre OSD dans le cluster à 0 :
ceph osd crush reweight osd.XX 0.
Réduire son poids à 0 revient en soi à le rendre responsable de 0% de la taille du cluster : donc qu'il faille le vider de toutes ses données. Nous avons testé cette procédure sur notre cluster de développement, afin d’éviter quelconque effet de bord non prévu en production.
Ceci a été concluant : ni le ceph osd out XX ni le ceph osd crush remove osd.XX n'engendraient alors plus de mouvement de données. Une fois la nouvelle procédure validée, nous l’avons donc mise en place sur l’environnement de production.
Elle sera également utilisée à l’avenir, ayant pour autre avantage que la valeur du poids de l’OSD puisse être graduellement réduite, afin d’éviter de gros rebalancements dans le cluster. La nouvelle procédure s’articule alors comme suit :
ceph osd crush reweight osd.XX 0.
# Passage du poids de l’OSD à 0 (progressivement ou non).
# Mouvement de données, ~10To rebalancés.
ceph osd out XX
# Marquage de l’OSD comme non disponible au cluster.
# Pas de mouvement de données.
stop ceph-osd id=XX
# arrêt de l'exécution de l’Object Storage Daemon.
ceph osd crush remove osd.XX
# Sortie logique de l’OSD du cluster.
# Pas de mouvement de données.
ceph auth del osd.{osd-num}
# Suppression des clés d’authentification au cluster
ceph osd rm {osd-num}
# Suppression définitive de l’OSD du cluster.
Nous sommes confiants sur le fait que ce double mouvement de données, engendré bien qu’en suivant la documentation et les recommandations officielles, soit fixé sur les versions supérieures de Ceph.
Optimiser le backfill pour un transfert de données plus rapide
La configuration de l‘osd_max_backfill correspond au nombre de PGs maximum rebalancé à la fois par un OSD. Un backfill à 1 (par défaut) autorisera un transfert de données plus lent mais aura pour avantage de ne pas surcharger le cluster.
La commande ceph tell osd.XX injectargs '--osd_max_backfills Y' a été très utile pour justement contrôler le processus de mouvement de données en fonction de la charge du cluster.
Par bonne pratique, le backfill était mis à 1 au préalable d’un nouvel ajout ou suppression d’OSD dans le cluster. Une fois l’utilisation de disques plus calme (à la fin du peering entre les OSDs notamment), le backfill était ensuite monté à 2 pour accélérer l’opération.
Un backfill plus grand encore engendrait une occupation trop importante des ressources du cluster et n’a donc pas été mis en place.
Faire attention lorsqu’on a des serveurs à capacité hétérogène
Avec du recul, nous aurions sûrement dû prendre moins de temps lors de l’opération sur notre dernier serveur Ceph, ceph-03. En effet, il s’agit de notre plus petit noeud (avec le moins d’OSD et de capacité de charge) : si ceph-01 ou ceph-02 était tombé pendant l’opération sur ceph-03, la charge aurait été très lourde à gérer (car plus d’⅓ du cluster aurait été down).
Ceci aurait pu causer de sérieux ralentissements chez nos clients. Le fait d’avoir une procédure plus optimisée a néanmoins équilibré le temps d’opération sur ce dernier disque.
Conclusion
Un article assez technique, si vous l’avez suivi jusqu’au bout sans jamais avoir entendu parler de Ceph, honnêtement bien joué ! Le changement d’un tiers d’une architecture de stockage distribué en production nécessite des connaissances précises et c’est ce que cet article essaie d'amener : poser la pierre sur laquelle nous n'avons pas pu nous reposer pour effectuer cette opération.
Ceph est une technologie bluffante (et ce déjà sous Jewel). Lorsque bien configurée et maîtrisée, elle est incroyablement résiliente et permet la mise en place d’un cloud privé à très hautes performances (nous sommes plus rapide en écriture sur notre cluster qu’en local sur SSD).
Avec ces nouveaux disques en production, nous voilà rassurés et prêts à attaquer la suite !
