

Vous avez des besoins spécifiques avec Elasticsearch ? Elasticsearch ne vous permet pas de personnaliser vos données en temps réel ? Le plugin est probablement la solution qui vous conviendra.
Après ces deux questions dignes d’un show télé, je vais vous donner un rapide aperçu de ce qu’il peut être possible de faire. Lors d’un projet Market Place B to B, les prix sont donnés en fonction des clients. Il est utile d’enrichir les données avec le prix sur plusieurs index pour profiter des avantages d’Elasticsearch. Ou pour un second exemple, si vous avez besoin d’avoir des logs à l’heure Parisienne et pas l’heure New-Yorkaise mais que votre Data Center est à New-York. Il est possible de supprimer l’heure de New-York et d’enrichir les données avec l’heure de Paris.
Pourquoi j’ai écrit cet article ?
Dans cadre d’un projet client, il nous a été demandé de mettre en place un plugin d’enrichissement de données. Malheureusement, les ressources disponibles étaient limitées et pas en adéquation avec la version que nous utilisions. Nous avons fini par y arriver et je vous propose de partager ce savoir faire au travers de cet article !
A qui s’adresse cet article ?
Cet article s’adresse aux personnes souhaitant créer leur premier plugin Elasticsearch pour enrichir ou transformer des données qui vont être indexées. Ce dernier aura donc pour but de vous guider dans la création d’un ingest plugin jusqu’à la création du zip contenant votre plugin.
Les technologies
Il sera réalisé en Java 8, avec maven sur les versions 6.5 et 6.6 d’Elasticsearch et Docker en 18.09.2.
Exemple de plugin
Ce type de plugin nous offre la possibilité d'intercepter un document pour le transformer ou l’enrichir selon vos souhaits. Voici un exemple concret de ce que peut offrir un plugin. Le plugin OpenNLP permet de faire de l’entity extraction (extraction d’information dans des corpus documentaire).
Les sources de cette démonstration sont disponibles à cette adresse :
https://github.com/julienconte/ingest-plugin-elasticsearch
Cette démonstration intègre directement Kibana et Elasticsearch afin de tester et visualiser les données enrichies.
Les ingests plugins plébiscités par Elasticsearch
Pour l’heure, Elasticsearch met en avant 3 plugins :
Ingest attachment processor plugin
Extrait des données sous forme de fichier PPT, XLS ou PDF
Ingest Geoip Processor Plugin
Enrichit votre document en lui ajoutant un champ geoip. Ce champ va indiquer la position géographique de l’adresse IP lors de l’envoi des données.
Ingest User Agent Processor Plugin
Extrait les données du User-Agent (le type d’application, le software à partir duquel sont envoyées les données)
*Les deux derniers plugins n’existent plus sur la version 6.7.0. Ils sont directement intégrés en tant que module à partir de cette version.
Comment ça marche?
Des définitions :
Ingest node :
Un ingest node est un node qui est créé pour intercepter les requêtes bulk et les requêtes d’indexation. Il va exécuter une tâche avant l’indexation du document.
Ingest plugin :
Un ingest plugin permet d’étendre les possibilités qu’offre un node Elasticsearch. Le node utilisé sera alors appelé un ingest node.
Il permet d’utiliser des pipelines qui feront appel à des plugins permettant de transformer ou modifier un document entrant avant indexation.
Processor :
Un processor est un processus qui va englober notre plugin. Il prend en entrée un document (la donnée qui va être indexée). Il transforme ensuite ce document et le renvoie pour qu’il soit indexé avec la bonne transformation.
Chaîne de fonctionnement des données avec un ingest plugin :
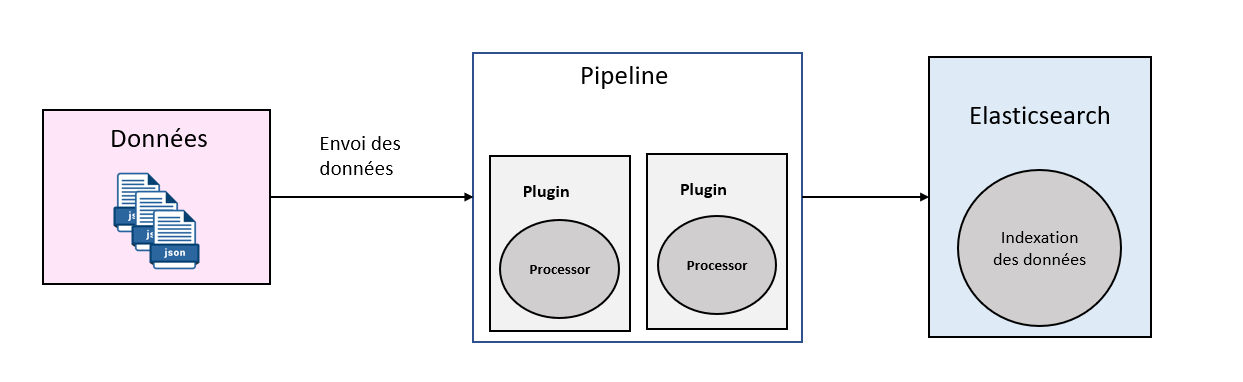
Passons à la technique !
Pour rappel, les exemples ci-dessus sont les bases de la réalisation d’un plugin orienté enrichissement de document. Ce squelette est commun à tous les plugins Elasticsearch pour les versions 6.5.4 et 6.6.
Préparation de notre POM (Project Object Model) :
Il faut commencer par créer un projet avec maven. Pour plus de facilité et pour être plus rapide, il est préférable de faire du maven assembly pour regrouper les dépendances, le jar et le fichier property dédié à notre processor dans un zip au lieu de tout créer à la main.
Il faudra rajouter ces diverses propriétés dans le POM :
<properties>
<elasticsearch.version>6.6.1</elasticsearch.version>
<output.directory>./docker-ek/elasticsearch/plugin</output.directory>
<!-- Cette propriété indique où sera dirigé le zip après sa création. Ici, il est redirigé --> <!-- directement dans le dossier elasticsearch pour plus de facilité -->
</properties>
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
<filtering>false</filtering>
<excludes>
<exclude>/elastic-properties/*.properties</exclude>
<!-- On exclue la lecture du properties pour Elasticsearch -->
</excludes>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.3</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.6</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<outputDirectory>${output.directory}</outputDirectory>
<descriptors>
<descriptor>${basedir}/src/main/assemblies/plugin.xml</descriptor>
<!-- On indique le descriptor de maven assembly -->
</descriptors>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
Configuration de l’exportation format zip :
Passons à la définition du descriptor, contenu dans le fichier plugin.xml. Il nous permet d’avoir le code, les dépendances et le fichier property directement dans le zip :
<?xml version="1.0"?>
<assembly>
<id>plugin</id>
<formats>
<format>zip</format>
</formats>
<includeBaseDirectory>false</includeBaseDirectory>
<files>
<file>
<!-- On ajoute notre properties à notre zip -->
<source>${project.basedir}/src/main/resources/plugin-descriptor.properties</source>
<outputDirectory>/</outputDirectory>
<filtered>true</filtered>
</file>
</files>
<dependencySets>
<dependencySet>
<outputDirectory>/</outputDirectory>
<useProjectArtifact>true</useProjectArtifact>
<useTransitiveFiltering>true</useTransitiveFiltering>
</dependencySet>
</dependencySets>
</assembly>
Création du fichier properties pour Elasticsearch
Il faut créer un fichier plugin-descriptor.properties, pour donner des informations sur notre plugin à Elasticsearch. Il sera situé dans notre dossier resources :
description=${project.description}
version=${project.version}
name=ingest-enrich
classname=org.elasticsearch.plugin.ingest.search.EnrichPlugin
java.version=1.8
elasticsearch.version=${elasticsearch.version}
Partie Java :
L’arborescence :
Commençons déjà par créer cette arborescence :
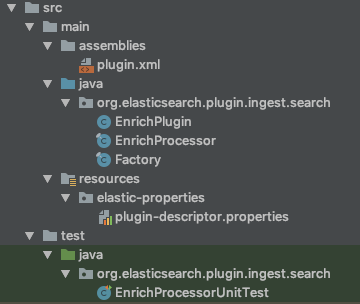
- plugin.xml est notre maven assembly que vous avez vu plus haut dans cet article.
- EnrichPlugin permet d’informer les processors qui composent le plugin.
- EnrichProcessor contient le coeur de votre plugin. C'est là que nous allons décrire notre traitement pour par exemple enrichir notre document.
- Factory est là pour configurer notre processor. Elle est obligatoire car elle fait partie de l’architecture de la conception d’un plugin pour Elasticsearch.
- Plugin-descriptor contient les méta-données de notre plugin comme le nom de la classe du plugin, la description.
Je ne rentrerai pas dans les détails pour les tests mais sachez qu’il y a un exemple de test unitaire disponible sur le github donné à la fin de l’article. Il est aussi possible de faire des tests d’intégrations que je n’ai pas détaillés dans la démo.
La classe EnrichPlugin :
package org.elasticsearch.plugin.ingest.search;
public class EnrichPlugin extends Plugin implements IngestPlugin {
@Override
public Map<String, Processor.Factory> getProcessors(Processor.Parameters parameters) {
return Collections.singletonMap(EnrichProcessor.NAME, new Factory());
}
}
La méthode getProcessors répertorie les processors enregistrés par notre plugin. Ici, nous n’en avons qu’un, donc nous retournons une collection avec un seul élément. On appelle la factory pour créer un processor avec son nom. Comme expliqué plus haut, elle est présente pour configurer notre processor. Il n’y a que peu de configuration à réaliser ici mais elle n’en reste pas moins obligatoire et pourrait servir à créer plusieurs processors si besoin.
La classe Factory :
package org.elasticsearch.plugin.ingest.search;
import org.elasticsearch.ingest.Processor;
import java.util.Map;
public final class Factory implements Processor.Factory {
@Override
public EnrichProcessor create(Map<String, Processor.Factory> registry,
String processorName,
Map<String, Object> config) {
return new EnrichProcessor(processorName);
}
}
On définit la méthode create pour créer les Processors de manière générale ce qui permettra, suivant le besoin, de créer divers processors pour un seul plugin.
On lui donne un nom de Processor (le processorName) qui permettra d’identifier de manière unique le processor.
La classe EnrichProcessor :
package org.elasticsearch.plugin.ingest.search;
import org.elasticsearch.ingest.AbstractProcessor;
import org.elasticsearch.ingest.IngestDocument;
public final class EnrichProcessor extends AbstractProcessor {
static final String NAME = "enrich";
EnrichProcessor(String name) {
super(name);
}
@Override
public IngestDocument execute(IngestDocument document) {
document.setFieldValue("enrich", true);
return document;
}
@Override
public String getName() {
return NAME;
}
}
La méthode execute consiste à récupérer un ingestDocument. Cet ingestDocument est le document qui est en cours d’indexation. Par conséquent, en l’état, il n’est pas encore dans Elasticsearch. Vous pouvez donc l’enrichir en ajoutant, par exemple, un nouveau champ. Ici, le processor ajoute le champ “enrich” avec comme valeur true. Et pour finir, elle retourne le document pour l’indexer dans Elasticsearch.
Installation du plugin Elasticsearch :
Une fois votre plugin java terminé, il faut le récupérer en zip. Si vous avez bien préparé le terrain avec ce qui est expliqué plus haut concernant le POM, il vous suffit d'exécuter dans un terminal la commande :
mvn package
Un zip est généré dans votre dossier target que vous allez récupérer. Dans votre dossier Elasticsearch, créez un dossier plugin et collez-y votre zip. Puis installez votre plugin dans Elasticsearch à l’aide de la commande suivante :
sudo /usr/share/elasticsearch/bin/elasticsearch-plugin install file:////usr/share/elasticsearch/plugin/
Votre plugin est enfin fonctionnel. Il faut ensuite créer une pipeline.
Il faudra procéder à un appel REST avec curl (ou autre suivant ce que vous utilisez) pour créer la pipeline en indiquant son nom. Voici un exemple :
curl -H 'Content-Type: application/json' -XPUT 'localhost:9200/_ingest/pipeline/nom_pipeline --data-binary @create_pipeline.json;
Le port 9200 correspond au port par défaut d’Elasticsearch.
Le fichier create_pipeline.json est le contenu de la requête REST. Il va indiquer la liste des processors à créer :
{
"processors": [
{
"enrich": {}
}
]
}
Le nom enrich correspond au nom du processor donné à la classe EnrichPlugin.
Utilisation :
Pour l’utiliser, il faut faire une requête en indiquant, à la fin de celle-ci, “&pipeline=nom_pipeline” lors de l’insertion de données.
curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/data-enrich/_doc/_bulk?pretty&pipeline=enrich' --data-binary @data.json;
Voici les données, qui correspondent à notre data.json, avant enrichissement :
{ "index" : { "_id" : "1" } }
{ "name": "first", "number": 1}
{ "index" : { "_id" : "2" } }
{ "name": "first", "number": 2}
et voici après enrichissement, affichées via kibana :

On peut voir que le document a bien été enrichi avec le champ enrich à True.
En conclusion
Voici une bonne base pour créer l'ingest plugin dont vous avez besoin. Dans ce tutoriel, il est question de création d’un plugin d’enrichissement mais la base ne change pas d’un plugin à l’autre.
Vous pouvez aussi récupérer des informations d’un Elasticsearch déjà lancé ou du même Elasticsearch sur un autre index si vous le souhaitez.
Dans la démonstration, comme je l’ai dit au début de l’article, les tests unitaires sont déjà présents mais il manque les tests d’intégration.
Maintenant, il ne vous reste plus qu’à adapter ce plugin à votre besoin et d’y ajouter des tests d’intégrations si vous le souhaitez.