

Petit rappel
Suite à mon précédent article présentant Prometheus et son fonctionnement, voici un deuxième article comparant Prometheus et les autres solutions de supervision du marché comme :
- Nagios ;
- Zabbix ;
- Sensu ;
- InfluxData.
Prometheus est un logiciel de supervision open-source créé par SoundCloud. En 2013, SoundCloud a décidé d’utiliser Prometheus pour ses infrastructures de Production et a publié la version 1.0 en Juillet 2016.
Prometheus, écrit en GO, s’impose depuis comme la solution de référence pour superviser une infrastructure de type Cloud, SaaS/Openstack, OpenShift (OKD), Kubernetes (K8S).
Par rapport aux autres solutions ?
Il existe de nombreuses autres solutions de supervision sur le marché, chacune ayant ses avantages et ses inconvénients. La suite de l’article présente un comparatif avec les solutions les plus connues du marché.
Nagios
Nagios est le plus ancien système de supervision et fonctionne uniquement par l’exécution de scripts renvoyant une valeur (0,1, 2 ou 3). Il n’y a aucune gestion avancée des alertes comme le regroupement, le routage en fonction du type ou bien la déduplication qui permet de ne recevoir qu’une seule fois l’évènement même si celui-ci se reproduit plusieurs fois.
Architecture
Le(s) serveur(s) Nagios sont indépendants. Toutes les configurations se font au travers de fichiers. Nagios est un système basique pour la supervision de petits systèmes qui n’évoluent pas mais n’est pas adapté à la supervision d’une infrastructure de type Cloud. La supervision de containers ou la récupération des statistiques kubernetes est assez compliquée car il faut écrire ses propres checks.
Modèle de données
Nagios possède uniquement un stockage local et n’a aucune notion de requêtage de données. Il requiert des plugins pour permettre l’historisation des données et par conséquent le stockage. Par défaut, il ne stocke que la dernière valeur d’un check.
Zabbix
Zabbix est un système de supervision créé il y a 20 ans. Avec sa version 4.0, il a su se réinventer mais il reste tout de même dans la lignée de Nagios et de son fork Centreon. Il est développé en C et le front web est en PHP.
Architecture
Zabbix utilise par défaut le mode pull en se connectant aux agents locaux qui sont à déployer sur chaque système à superviser, ou à un agent local au serveur pour effectuer les checks sur les équipements de type réseaux.
Le serveur Zabbix récupère les données depuis les agents et calcule les alertes. La communication entre les agents et le serveur est un protocole maison basé sur du TCP.
Il est possible de trouver un nombre important de templates et de checks sur Internet mais il n’y a pas d’intégration complète avec des systèmes récents de type Cloud comme Openstack, K8S, OKD. Cependant, il est possible de créer ses propres checks mais cela reste compliqué lorsque l’on veut superviser des systèmes modernes.
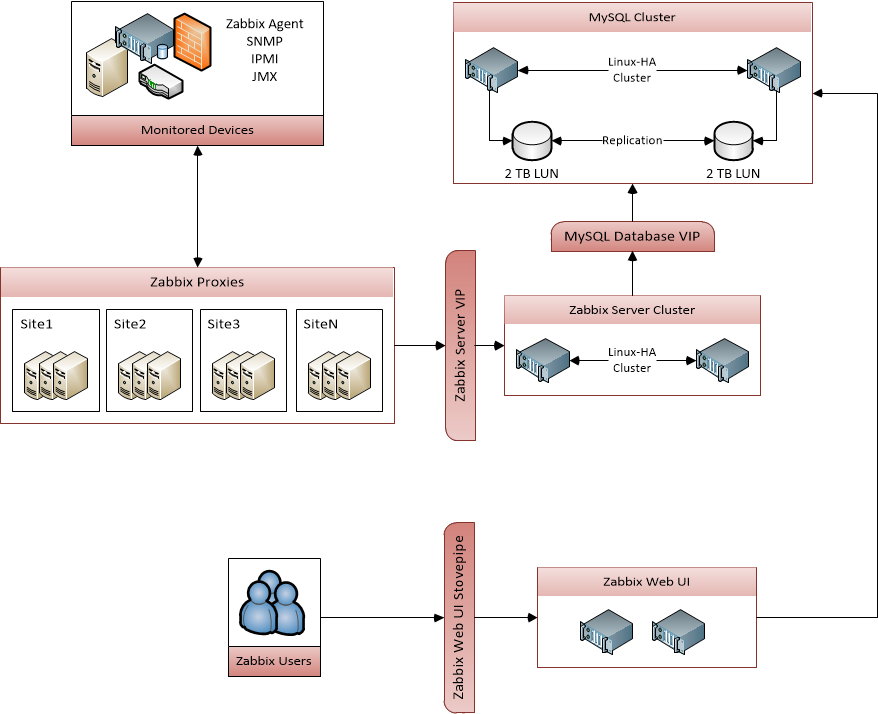
Son ancienneté est un gage de robustesse et convient particulièrement bien pour la supervision de hardware et les services type NTP, serveurs WEB, Nexus, etc... Cependant, il ne convient pas s’il est nécessaire de superviser plus de 10 000 instances et il est très difficile de scaler la partie serveur (acquisition des données), si ce n’est en augmentant la taille du serveur pour avoir de meilleurs performances.
Modèle de données
Zabbix utilise une base de données relationnelle (MySQL, PostgreSQL, Oracle, sqlite) pour stocker les données, la configuration et les évènements. La nouvelle version 4.x permet de stocker des métriques dans un cluster Elasticsearch. Cette fonctionnalité est encore expérimentale et complexifie la maintenance du système de par la gestion d’un cluster Elasticsearch.
Dans le cas où les données sont stockées dans une base de données SQL, il est vivement conseillé de partitionner les tables. Dans le cas de PostgreSQL version 10.x et supérieure, il existe des scripts bash permettant de partitionner les tables stockant les valeurs pour atteindre des performances élevées.
Sensu
Sensu est un framework de monitoring plutôt qu’un système complet de supervision. Sensu se décompose en plusieurs briques :
- Sensu Client ;
- Sensu Server ;
- Sensu API ;
- Uchiwa ;
- Rabbit MQ et/ou Redis.
Architecture
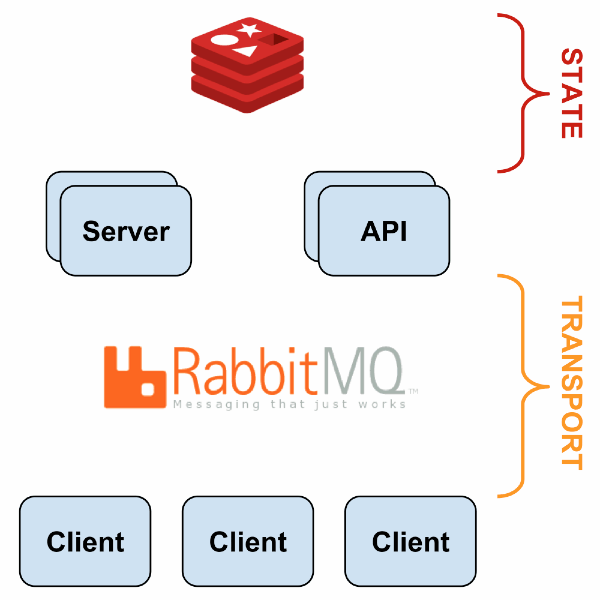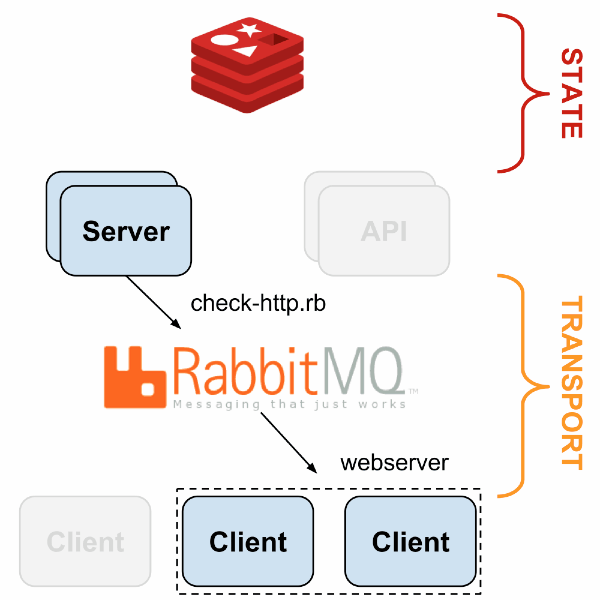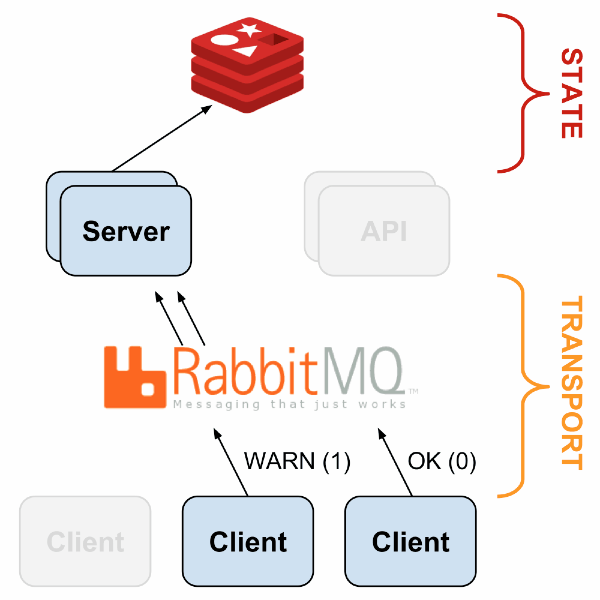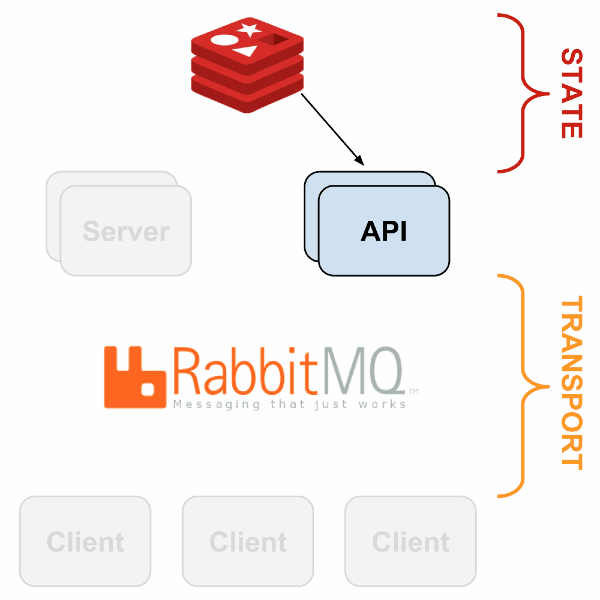
Redis est utilisé pour le stockage tandis que RabbitMQ permet de faire converger toutes les données en provenance des Sensu clients. Uchiwa est l’interface de gestion de Sensu.
Les clients sont déployés sur les différents hôtes à superviser et ils effectuent les checks qui sont identiques à Nagios. Chaque check doit renvoyer un exit code définissant l’état du service (0 : OK, 1 : Warning, 2 : Critical, 3 : Unknown)
Modèle de données
Le modèle de données est identique à Nagios, sauf que par défaut, la gestion du stockage est intégrée et portée par Redis.
Sensu est une bonne solution dans le cas où il existe déjà une supervision Nagios et qu’il y a une volonté de changer de système et/ou de bénéficier de l’enregistrement automatique fourni par Sensu. Dans tous les autres cas, il vaudrait mieux privilégier une autre solution.
InfluxData
InfluxData est une stack de supervision comprenant Telegraf, Kapacitor, InfluxDB et Chronograf. Chaque système à superviser doit avoir un agent local nommé Telegraf qui remonte les données vers le système de collecte Kapacitor.
Architecture
Prometheus et InfluxDB ont des stockages locaux. Cependant, la version commerciale de InfluxDB offre une solution de clustering et scaling native permettant une intégration simplifiée du scaling horizontal mais cela oblige quand même à gérer le stockage distribué.
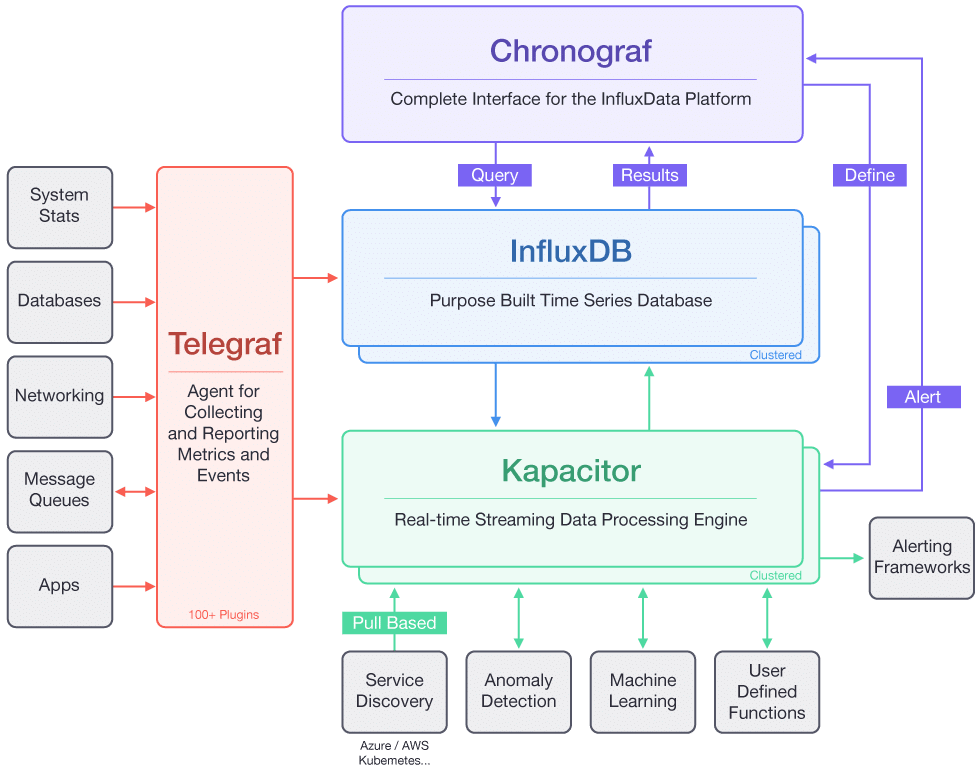
Prometheus et Alertmanager offrent une solution native de distribution / redondance tandis que Kapacitor n’a pas cette fonctionnalité.
InfluxDB est une base de données “Time series” open-source avec une option commerciale pour la partie cluster et scaling.
Chronograf est l’interface de gestion du système de supervision et permet aussi la visualisation. Cependant, il est recommandé d’utiliser Grafana qui a un connecteur vers la base InfluxDB.
Modèle de données
Le modèle de données est sensiblement le même que Prometheus mais supporte un plus grand nombre de types (int64, bool, timestamps avec une résolution à la nano seconde).
Conclusion
Chaque système de supervision possède son cas d’usage mais Prometheus correspond parfaitement à un besoin de supervision de type Cloud, Docker, Kubernetes (K8S) ou OpenShift (OKD). Prometheus a l’avantage d’être directement déployé dans des projets comme Kubernetes (K8S), OpenShift (OKD). Il répond parfaitement aux exigences de supervision temps réel mais n’est pas conçu pour stocker les données des métriques sur une longue période de rétention. Dans ce cas, il conviendrait de coupler Prometheus à un stockage distant comme InfluxDB ou autre.