

Cluster permanent VS Cluster éphémère à la demande
La démocratisation des services Cloud type “Hadoop As A service” a constitué une évolution majeure dans le monde du Big Data et du calcul distribué. Cette accessibilité simplifiée (10 min pour AWS) à une ressource jusqu’alors complexe a permis l’émergence d’un nouveau paradigme d’architecture : l’éphémérité.
Avant cette démocratisation, la grande majorité des datalakes étaient on-premises, monde où les clusters étaient par nature permanents ce qui a répandu cette pratique d’utiliser un cluster unique (par environnement) pour soumettre tous les jobs d’un développeur, d’une équipe, d’une DSI comme la norme de cette époque.
Ce mode de fonctionnement présente plusieurs inconvénients :
- Les clusters ont tendance à fonctionner 24/7, même la nuit et quand il n’y a pas besoin de ressources de calcul. Même s’il est possible d’éteindre le cluster cela ne fera économiser que de l’électricité et ne diminuera pas l'investissement matériel ni les coûts opérationnels.
- Le cluster possède une capacité déterminée (nombre de nœuds, mémoire et CPU par nœuds…) et commune à tous les jobs quand bien même les besoins en ressources seraient différents pour ces derniers.
- Pour partager un cluster Hadoop il faut mettre en place du multi-tenant entre les différents utilisateurs (par exemple une queue Yarn par projet), ce qui augmente la complexité opérationnelle.
- Un cluster permanent implique de faire les mises à jour des services du cluster ce qui induit une complexité opérationnelle loin d’être négligeable.
- Enfin bien qu’il soit possible maintenant d’utiliser des systèmes de fichiers externes comme CEPH ou un stockage objet, pour découpler la scalabilité en compute de celle du storage (qui n’est pas présente avec HDFS), il est toujours compliqué en terme d’opérations d’avoir à gérer du scale up & down.
Avec les services Cloud, l’approche est complètement différente puisque je peux bénéficier à la demande d’un cluster Hadoop en moins de 10 minutes. L’intérêt de faire tourner le cluster en 24/7 est finalement assez rare. On passe à un paradigme de cluster transient : chaque job de calcul (Spark, Flink etc..) est associé à un code d’infrastructure propre aux besoins en ressources (CPU, RAM) du job. Pour réaliser un quelconque traitement, on va donc instancier un cluster spécifiquement pour ce traitement. Une fois le cluster créé, le job de calcul se lance puis, son exécution terminée, le cluster sera automatiquement détruit.
Cette approche impose d’utiliser un système de fichier externe comme EMRFS (système de fichiers AWS compatible Hadoop basé sur S3) au lieu de HDFS car les données ne peuvent pas être persistées au sein du cluster. Nos données seront donc stockées sur S3 (capacité de stockage illimitée) et on configurera le cluster Hadoop avec les ressources de calcul nécessaires pour faire tourner le job. Les avantages de cette approche sont les suivants :
- Le storage et le compute sont découplés et peuvent scaler indépendamment.
- La configuration du cluster est parfaitement adaptée au besoin Job.
- La tarification est pay-as-you-go ; on ne paye que pour ce que l’on consomme car lorsque le job est terminé le cluster est détruit.
- Pas de risque de conflit de ressources entre les différents jobs.
- On peut profiter de l’utilisation des instances préemptibles (instance dont le prix varie en fonction de l’offre et de la demande). Par exemple si un batch doit tourner entre 22h et 6h du matin on va pouvoir lancer la création du cluster et le lancement du job au moment où le marché de l’instance sera le plus bas.
L’utilisation des clusters éphémères présente de nombreux avantages mais impose un changement de paradigme dans la façon de penser le traitement de la donnée.
Cela implique également de penser en terme d’infrastructure as code automatisée plutôt que de créer manuellement les ressources sur l’interface du Cloud provider ou d’utiliser la console shell. On doit également être en mesure de variabiliser notre code d’infrastructure en fonction de l’environnement et des ressources en compute nécessaires pour chaque job (qui varieront selon les environnements).
Contexte de l’article et Use case
Le but de cet article est de présenter cette implémentation réalisée dans un contexte client réel. En effet dans le cadre d’une ré-implémentation fonctionnelle d’un système legacy vers un nouveau système bâti entièrement sur des services managés AWS, j’ai travaillé sur la migration d’un jeu de données conséquent depuis l’ancien système vers le nouveau. Ces données nous ont été mises à disposition par une autre équipe dans un bucket S3 pour les enregistrer dans notre base de données de référence DynamoDB ainsi que dans notre moteur de recherche : ElasticSearch Service. Il s’avère que l’on doit appliquer des transformations sur ces données pendant leur transit (nettoyages, jointures et agrégations principalement) ainsi que de valider que le format des données respecte la spécification Swagger définie entre nos deux équipes.
C’est cette non trivialité en terme de transformations et le volume qui nous ont fait opter pour Spark exécuté depuis AWS EMR plutôt que d’autres solutions envisagés initialement (Athéna et AWS Glue notamment).
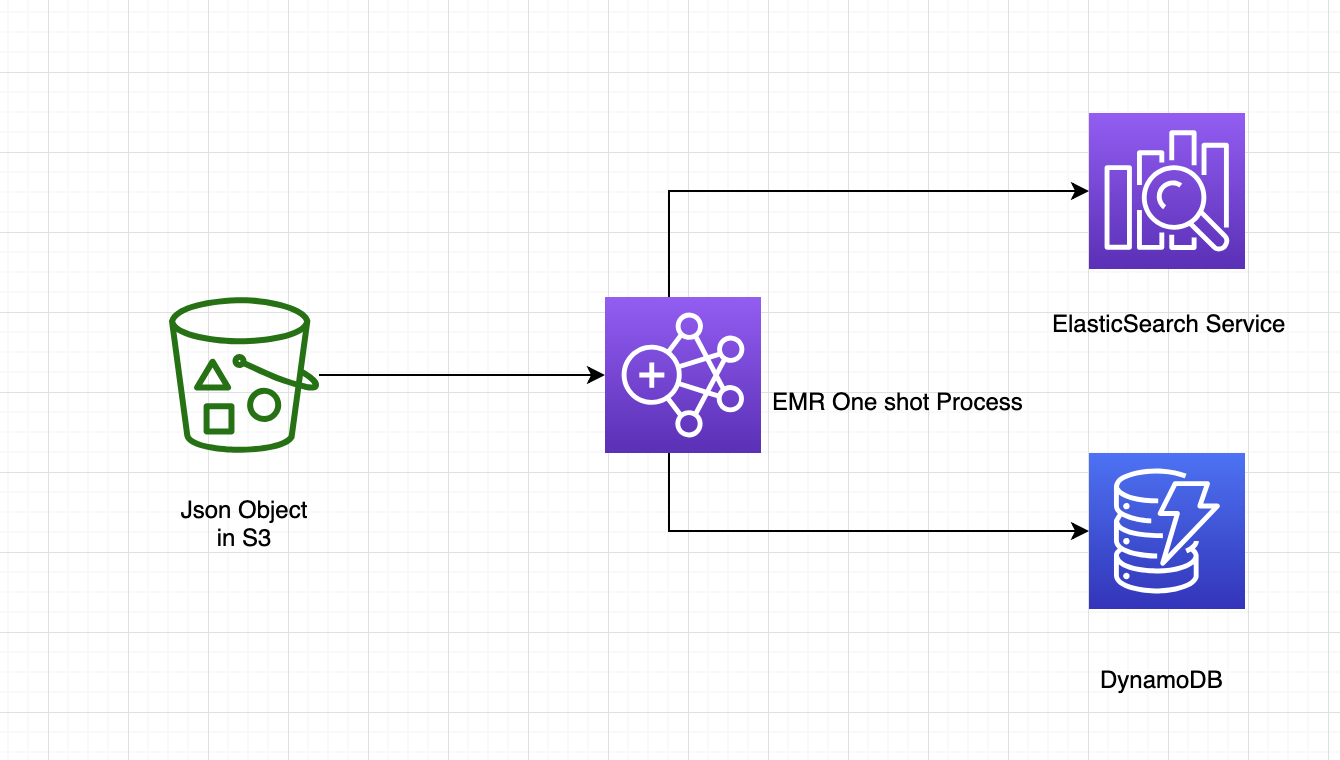
Vous l’aurez compris, cet exemple sera fortement lié à AWS mais les mêmes principes sont applicables chez les autres Cloud providers.
Lorsque j’ai commencé ce projet, j’ai été surpris du peu de ressources disponibles sur le sujet surtout sur la partie implémentation de cluster éphémère sur AWS, c’est une des raisons qui m’ont poussé à écrire cet article.
Pour le code d’infrastructure la technologies utilisée est Terraform pour une raison très simple liée à mon contexte client, c’est l’unique moyen autorisé pour déployer de l’infrastructure au niveau de la DSI (console AWS en read-only à partir de l’environnement d'intégration, ce qui est plutôt une bonne chose quand on y pense).
Ceci dit, ce choix n’est pas surprenant, Terraform étant une des technologies d’infrastructure les plus matures sur le marché et plus simple à utiliser que CloudFormation qui est basé sur du YAML et bien plus difficile à modulariser. À noter quand même qu’AWS a sorti récemment Cloud development Kit qui permet de faire de la “vraie” infra as code en JavaScript (et donc simplifier la gestion des tests pour l’infrastructure), prometteur donc.
On distinguera, dès le début de l’article, 2 repositories de code séparés :
- Le répertoire de code Spark Scala qui contient le code ETL applicatif et le pipeline d’intégration continue,
- Le répertoire de code Terraform qui contient le code d’infrastructure et le pipeline de déploiement continu.
La Continuous Integration du code applicatif a pour objectif de lancer les tests, packager un binaire avec les dépendances, pousser ce binaire sur un bucket S3 (qui fera office de gestionnaire d’artifacts) et enfin de déclencher l’exécution du code d’infrastructure pour lancer un pipeline de Continuous Deployment où sera effectuée la commande qui va déployer l’infrastructure.
terraform apply
Nous nous intéresserons dans cet article uniquement à la partie code d’infrastructure en partant du postulat que l’on a à disposition dans un bucket S3 un JAR contenant le code Spark et les dépendances. On fera également abstraction de toute la partie IAM en partant du principe que l’on a :
- Les droits en lecture sur le bucket d’artifact où est stocké le JAR,
- Les droits en lecture sur le bucket contenant les données,
- Les droits en écriture dans une table DynamoDB existante,
- Le Security Group lié à ElasticSearch Service qui autorise le trafic venant d’EMR
- Les Security Groups du master et des slaves correctement configurés.
Néanmoins, dans la vraie vie ces problématiques liées à la sécurité et l’Identity Access Management sont centrales et souvent les plus difficiles à comprendre et à mettre en place, mais c’est un autre sujet :)
Implémentation d’un cluster Spark à la demande avec Terraform et EMR
EMR est un service de cluster Hadoop managé sur AWS qui utilise un cluster d’instances EC2 avec Hadoop pré-installé et configuré.
Terraform met à disposition une ressource nommée aws_emr_cluster qui permet de créer un cluster Hadoop sur AWS. Ainsi, cette ressource attend un certain nombre de paramètres en entrée :
Tout d’abord il faut spécifier la version d’EMR souhaitée via l'option release_label (les versions d’EMR sont référencées dans la documentation AWS). Comme EMR est composé d’une constellation de services, chaque version d’EMR correspond à un ensemble de versions pour chacun des services qui le composent. AWS garantit la cohérence des versions des services et le bon fonctionnement entre les différentes versions.
On peut se rendre compte de cet aspect “composition de services” sur l’image ci dessous.
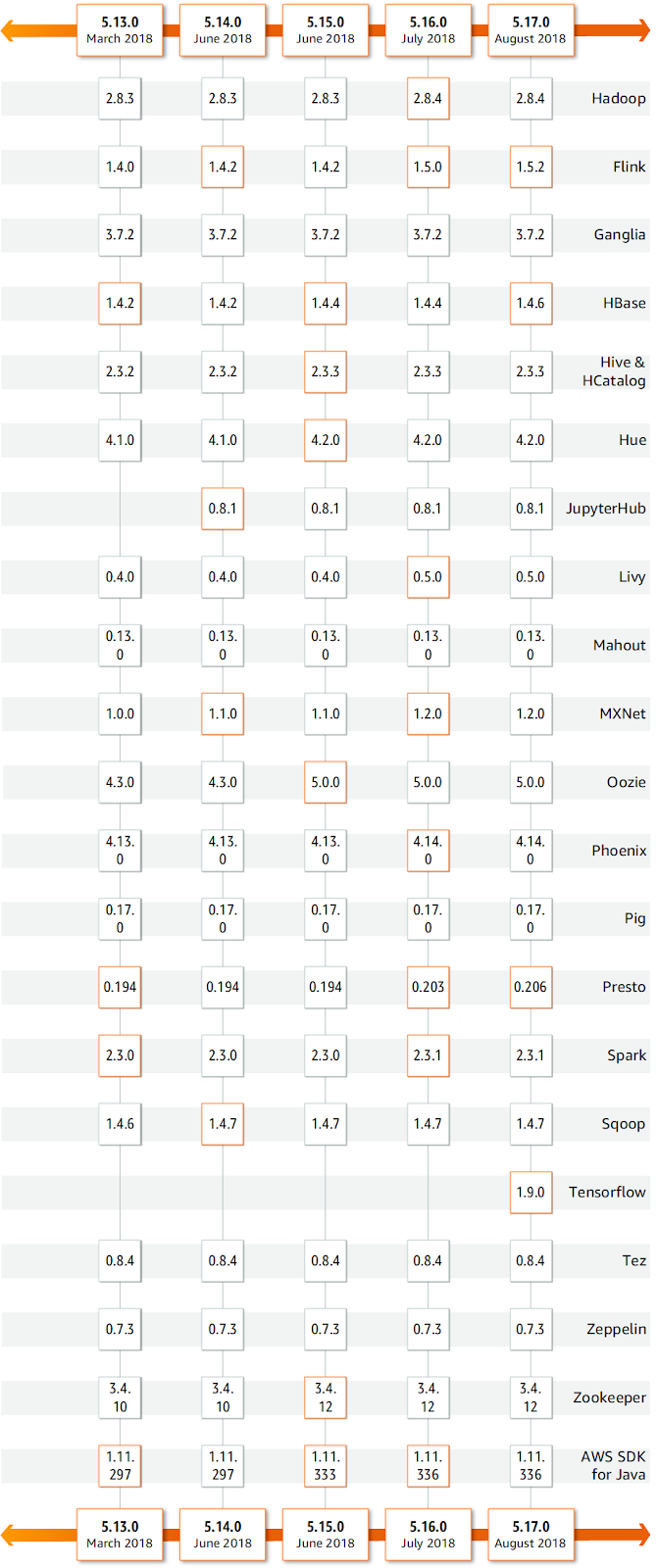
release_label = "emr-5.20.0"
Ensuite on va indiquer à EMR les services que l’on veut utiliser sur le cluster (dans notre cas, Hadoop, Spark et Ganglia pour le monitoring) :
applications = ["Hadoop","Ganglia","Spark"]
On peut également transmettre un fichier JSON de configuration à la ressource. C’est ce fichier de configuration qui permet de spécifier les options propres à Spark (nombre de partitions, mémoire par exécuteur, cœurs par exécuteur etc..) :
[
{
"Classification": "spark-defaults",
"Properties": {
"spark.executor.memory": "4G"
}
}
]
Il faut indiquer que le cluster doit être supprimé automatiquement une fois le job terminé grâce au paramètre keep_job_flow_alive à false. C’est cette option qui permet de déployer un cluster éphémère, qui se détruira une fois le job terminé. Par défaut la valeur est à true et correspond donc à un cluster permanent
keep_job_flow_alive_when_no_steps = false
Une autre option importante est log_uri qui permet d’indiquer à EMR le bucket S3 où il devra enregistrer les logs :
log_uri = "s3n://aws-logs-<account_id>-<region>/elasticmapreduce/"
Cette option est très importante et permet de collecter les logs Spark et surtout les logs YARN, indispensables pour le debug, dans un bucket S3 et également directement visualisables depuis la console graphique.
À noter que les logs sont disponibles sur S3 avec une latence de 5 à 10 minutes, rendant compliqué le suivi en temps réel du job.
On pourrait imaginer une bootstrap_action qui installerait un agent quelconque sur les instances pour envoyer les logs et métriques dans un outil externe pour un suivi en temps réel.
Enfin il faut associer un rôle IAM à notre cluster EMR via l’option service_role. Rôle qui servira à ajouter des IAM policy à notre cluster (comme les droits d’écriture dans DynamoDB) :
service_role = "<your_service_role_arn>"
Un des paramètres importants est la définition des EC2 attributes. En effet, il faut définir les types d’instance, la puissance, etc., des machines EC2 utilisées.
C’est donc naturellement ici que l’on associerait les instances à une key pair et à un security group autorisant le port 22 pour le SSH, mais ce ne sera pas notre cas vu que l’on n’aura pas besoin de se connecter à un cluster éphémère :)
Les options pour les EC2 sont les suivantes :
subnet_idafin de savoir dans quel VPC créer le cluster,emr_managed_master_security_group, le master étant une instance, il vient forcément avec un security group dédié où l’on autorise le trafic sortant.emr_managed_slave_security_group, les slaves étant un ensemble d’instances, ils viennent forcément avec un security group dédié où l’on autorise le trafic sortant.instance_profilequi permet de configurer un profil pour nos instances. On utilise un statement très simple qui permet à nos instances d’assumer le rôle ec2.amazonaws.com.
On doit également fournir la composition du cluster via l’option instance_group. On passe un tableau d’instances (pour la master et les slaves) avec des informations sur le nombre souhaité d’instance master, le rôle de l’instance, le type d’instance et enfin le nombre d’instances slave :
La bonne pratique est de redonder les instances master en passant le nombre à 3 (un par zone de disponibilité). Cela permet de garantir que le cluster pourra continuer de fonctionner même si un des datacenters subit une coupure de service.
À noter que dans les instances slaves il est possible d’utiliser des instances Spot et de préciser une enchère maximale via l’option bid_price.
Dans notre cas les instances seront créées uniquement si le bid_price est inférieur ou égal à 0.30$.
La définition du nombre d’instances slaves, du rôle d’instance (core ou task- et du type d’instance dépend entièrement des spécificités et du besoin en ressources du job mais aussi de l’environnement (cluster plus léger en développement qu’en production par exemple).
C’est ici qu’on se rend compte de toute la souplesse que nous offre cette approche en permettant d’associer la meilleur configuration de cluster possible en fonction des besoins d’un unique job.
instance_groups = [
{
name = "MasterInstanceGroup"
instance_role = "MASTER"
instance_type = "m4.large"
instance_count = "3"
},
{
name = "CoreInstanceGroup"
instance_role = "CORE"
instance_type = "m4.xlarge"
instance_count = "3"
bid_price = "0.30"
}
]
Une fois tout ceci correctement configuré, notre cluster est prêt à lancer des jobs Spark à la demande. Il nous reste à ajouter des étapes via l’option bien nommée step.
Les steps correspondent aux actions à effectuer sur le cluster. On peut soumettre de multiples steps mais dans notre cas d’exemple on en aura une seule pour notre job Spark d’ETL.
Une step attend plusieurs options :
action_on_failure : si la step part en erreur faut il détruire le cluster ou non,
name : chaque step est identifiée par un nom,
hadoop_jar_step: c’est ici que l’on va définir le lancement de notre job.
Lors de la création d’un cluster EMR, un binaire d’AWS est automatiquement présent sur le cluster command_runner.jar. C’est à partir de ce binaire qu’on est capable d’exécuter une commande (Spark ou autre).
On va ensuite passer un certain nombre d’arguments à ce command_runner :
spark-submit: pour indiquer que l’on va lancer un job Spark,deploy-mode cluster: pour lancer le job en mode cluster (indispensable pour un cluster transient),class <la_main_class_applicative>,master yarn: pour indiquer le type de déploiement,<chemin vers le jar sur S3>.
Plus d’éventuels arguments à passer en paramètre au job Spark (tel que l’environnement par exemple, pour savoir quel fichier de configuration utiliser au niveau applicatif).
step {
action_on_failure = "TERMINATE_CLUSTER"
name = "Launch Spark Job"
hadoop_jar_step {
jar = "command-runner.jar"
args = ["spark-submit","--deploy-mode","cluster","--class","${var.spark_main_class}","--master","yarn","s3://${var.artifact_bucket}/${var.spark_artifact_name}", "${var.environment}"]
}
}
On peut (doit !) également bien évidemment rajouter des tags sur la ressource EMR que l’on est en train de créer, notamment pour la gestion des coûts sur la plateforme AWS.
Conclusion
Comme on l’a vu cette approche permet de lancer des clusters Spark à la demande pour exécuter un traitement distribué. Néanmoins le combo Terraform + EMR n’est pas la seule solution possible pour résoudre ce problème.
En restant dans le monde AWS, Glue est un service qui permet d’exécuter des jobs Spark à la volée. Néanmoins Glue vient avec certaines limitations et une couche d’abstraction à Spark (utilisation des DynamicFrame) rendant le produit intéressant mais trop limité et pas suffisamment mature pour être envisagé en production. Glue est à ce jour prévu pour fonctionner avec un script Python ou Scala ce qui est préjudiciable pour la séparation du code Spark en package distinct. Glue est également limité en terme de métriques et logs et l’accès aux logs YARN est déterminant pour développer avec Spark.
Un autre outil venant du monde open source est Flintrock qui permet d’instancier des clusters Spark à la volée sur des EC2 via une CLI. Néanmoins il s’intègre mal avec Terraform qui ne pourra pas gérer les security groups propres au cluster instancié. De plus pour une implémentation qui sera déployée en production il peut être risqué de dépendre d’un outil externe. Mais cela peut être une bonne alternative pour les phases de développement.
À noter qu’OVH propose depuis peu un service de cluster Spark à la demande nommé Analytics Data Compute qui aurait pu être intéressant si le choix du provider n’avait pas été une des conditions initiales !
Cet article vous donne une bonne base pour instancier vos propres clusters EMR éphémères avec Terraform. Néanmoins avant d’utiliser cette implémentation en production il faut porter une attention toute particulière à la sécurité d’une part via l’Identity Access Management, les Bucket Policy et les Security Groups mais d’autre part en s’assurant que les données sur S3 sont chiffrées (chiffrement at rest) mais surtout s’assurer du chiffrement des données entre les nœuds du cluster (chiffrement in transit).
J’espère que cet article vous aura convaincu des avantages des clusters Hadoop éphémères par rapport aux clusters permanents et qu’il vous permettra d’implémenter rapidement cette approche sur vos projets :)
Twitter https://twitter.com/lulufrego
