

Pourquoi Prometheus ?
Prometheus est un logiciel de supervision open-source créé par SoundCloud. En 2013, SoundCloud a décidé d'utiliser Prometheus pour ses infrastructures de Production et a publié la version 1.0 en Juillet 2016.
Prometheus, écrit en GO, s'impose depuis comme la solution de référence pour superviser une infrastructure de type Cloud, SaaS/Openstack, OKD, K8S.
Plusieurs autres solutions de supervision sont disponibles sur le marché :
- Zabbix ;
- Nagios ;
- Centreon ;
- Sensu ;
- InfluxData.
Chaque solution offre ses avantages et ses inconvénients. Prometheus est fourni par défaut comme outil de supervision pour OKD et K8S.
Architecture de Prometheus
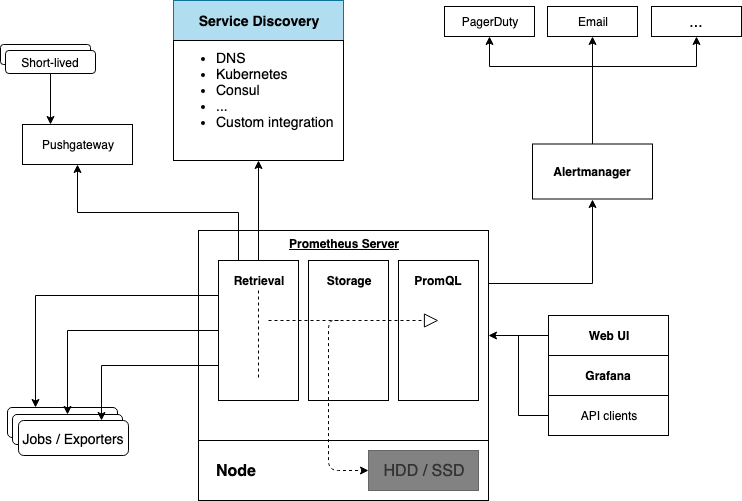
Comment fonctionne-t-il ?
Prometheus collecte les données en provenance des clients nommés Exporters installés sur les instances distantes. Il interroge à intervalle régulier ces agents pour récupérer les données.
Le back-end de Prometheus intègre sa propre base de données de type Time Series similaire à OpenTSDB.
Par défaut, le stockage des métriques s'effectue sur les disques locaux du serveur ce qui rend la scalabilité et la durabilité du stockage complexes et ne le rend pas résilient à la panne puisque le stockage n'est pas distribué. Pour un environnement de production, il sera donc nécessaire d'utiliser un système de fichier distribué et résilient comme du glusterFS ou un système de stockage distant. En fonction du type de stockage distant choisi, seule l'écriture ou lecture / écriture est possible.
La durée de rétention est de 15 jours lors de l'installation du serveur Prometheus. Il est possible d'augmenter la rétention en fonction de la taille de stockage disponible.
Comment récupérer les données enregistrées ?
Il embarque un puissant langage de requêtage nommé PromQL qui permet :
- Filtrage des indicateurs par labels (inclusion, exclusion, expressions rationnelles);
- Génération de vecteurs (plusieurs valeurs d'un indicateur sur une fenêtre temporelle par exemple) sur lesquels il est possible d'appliquer des fonctions et opérateurs d'agrégation (min, max, moyenne glissante, somme …).
Le résultat de chaque requête peut être visualisé sous forme de graphe, tableau ou être mis à disposition de systèmes externes via l'API HTTP.
Chaque résultat est généré sous forme d'un des 4 types suivants :
- String : Chaîne de caractères ;
- Numérique : Un nombre décimal ;
- Un vecteur instantané : un ensemble de séries temporelles contenant un seul échantillon pour chaque série, toutes partageant le même horodatage ;
- Un ensemble de vecteurs : un ensemble de séries temporelles contenant une plage de points pour chaque série.
Voici quelques exemples de requêtes :
http_requests_total
http_requests_total{job="apiserver", handler="/api/comments"}
http_requests_total{status!~"4.."}
sum(rate(http_requests_total[5m])) by (job)
topk(3, sum(rate(instance_cpu_time_ns[5m])) by (app, proc))</pre>
A quoi servent les Exporters ?
Prometheus utilise le protocole HTTP et nécessite l'instrumentation des applications en utilisant les librairies clientes disponibles pour différents langages.
Il existe différents Exporter :
- Des Third-party Exporters, permettant de récupérer des métriques de tout type. L'un des Exporters important est le System Exporter permettant de récupérer toutes les métriques systèmes ;
- Des Blackbox Exporters qui permettent de récupérer des métriques à travers différents protocoles ;
- D'autres outils comme Telegraf permettant d'exposer des données à Prometheus ;
- Créer ses propres Exporters si ceux fournis par défaut ne correspondent pas aux besoins.
Fonctionnement mode Pull / Push
Par défaut, Prometheus fonctionne en mode Pull, c'est à dire que le serveur interroge à intervalle régulier les instances clientes sur lesquelles les Exporters sont installés.
Il est possible, quand cela s'avère nécessaire de fonctionner en mode Push en utilisant le projet Prometheus Push Gateway. Le seul cas où ce module aurait un intérêt serait pour la supervision de jobs asynchrones. Ces jobs pourraient envoyer des données au Prometheus Server.
Utilisation de Prometheus derrière un ou plusieurs Firewalls
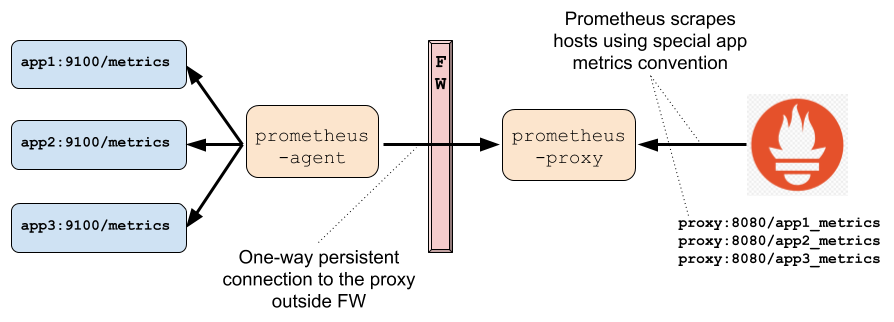
Pour superviser une infrastructure complexe qui comporte plusieurs niveaux d'isolations, le mode Pull devient problématique. Au lieu d'utiliser le mode Push qui vient à l'esprit naturellement, Prometheus fourni un proxy permettant de conserver le modèle Pull, et de superviser tous les systèmes derrières le(s) Firewall(s).
Le Proxy est décomposé en deux parties :
- Le proxy qui s'exécute sur la même zone que le serveur ;
- L'agent qui s'exécute derrière le firewall et gère les requêtes en provenance du Proxy.
L'agent peut s'exécuter :
- Comme standalone serveur ;
- Embarqué dans un autre serveur ;
- Comme simple Agent Java.
Un proxy peut gérer un ou plusieurs agents.
Alerting dans Prometheus
Prometheus peut se connecter à un module nommé Alertmanager qui est capable de transmettre les alarmes à différents types de média (Mail, Pager Duty, etc…). Le module Alertmanager possède les fonctionnalités suivantes :
- Grouper les alertes : une seule notification, regroupant toutes les alertes des N dernières secondes / minutes, est envoyée ;
- Suppression des notifications : les alertes relatives à une conséquence ne sont pas envoyées si l'alerte concernant la cause racine a déjà été envoyée ;
- Rendre muettes les alertes : ne pas envoyer la même alerte pendant une période déterminée ;
- Haute disponibilité : Alertmanager supporte la configuration en mode Cluster permettant la haute disponibilité.
L'ensemble de l'alerting est configurable par les fichiers de configuration.
Scalabilité et haute disponibilité
Scalabilité de Prometheus Server
Par défaut, une instance de Prometheus server est capable de gérer des millions de séries de données (https://www.robustperception.io/scaling-and-federating-prometheus) :
- La solution la plus simple consiste à déployer un deuxième serveur Prometheus avec du stockage local, chacun récupérant les mêmes données. Le module d'alerting s'occupe de dédupliquer les alertes ;
- La deuxième solution est la fédération : plusieurs Prometheus sont déployés, chacun s'occupant de récupérer une partie des systèmes à superviser. Une instance Master s'occupe de récupérer les données en provenance des Slaves ;
- La troisième solution, dans le cas ultime, serait d'utiliser un projet comme Thanos qui permet d'avoir une solution de haute disponibilité ainsi qu'une solution résiliente en terme de stockage.
Scalabilité de l'Alertmanager
Alertmanager peut fonctionner en cluster pour garantir la disponibilité du service. Par défaut, il est conseillé d'avoir la configuration suivante pour garantir une disponibilité du service.
Pour ce faire il faut :
- Avoir deux instances de Prometheus Server ;
- Avoir deux instances du modules Alertmanager et de les configurer en mode réseau ;
# On a machine named "am-1":
wget https://github.com/prometheus/alertmanager/releases/download/v0.15.3/alertmanager-0.15.3.linux-amd64.tar.gz
tar -xzf alertmanager-*.linux-amd64.tar.gz
cd alertmanager-*
./alertmanager --cluster.peer=am-2:9094
# On a machine named "am-2":
wget https://github.com/prometheus/alertmanager/releases/download/v0.15.3/alertmanager-0.15.3.linux-amd64.tar.gz
tar -xzf alertmanager-*.linux-amd64.tar.gz
cd alertmanager-*
./alertmanager --cluster.peer=am-1:9094
- Configurer les serveurs Prometheus pour s'interfacer à l'Alertmanager.
# On a machine named "prom-1":
alerting:
alert_relabel_configs:
- source_labels: [dc]
regex: (.+)\d+
target_label: dc
alertmanagers:
- static_configs:
- targets: ['am-1:9093', 'am-2:9093']
# On a machine named "prom-2":
alerting:
alert_relabel_configs:
- source_labels: [dc]
regex: (.+)\d+
target_label: dc
alertmanagers:
- static_configs:
- targets: ['am-1:9093', 'am-2:9093']</pre>
Intégration avec Grafana
Prometheus fournit par défaut une interface Web qui permet d'effectuer des requêtes pour voir les données présentes en base, mais cette interface n'est absolument pas pratique pour exploiter et superviser l'infrastructure.
Grafana est un logiciel Open Source pour la visualisation et la supervision d'une infrastructure. Ce logiciel propose une connexion native à Prometheus et propose une liste de dashboards pré-générés pour récupérer les informations en provenance de Prometheus.
Gestion des utilisateurs
La gestion des utilisateurs se fait au niveau de Grafana. Grafana peut se connecter facilement à un LDAP ou Active Directory externe. Il est donc très facile de gérer les accès à la supervision avec cette méthode.
Le LDAP est activé dans Grafana en modifiant les fichiers de configuration suivants :
Dans le fichier /etc/grafana/grafana.ini
[auth.ldap]
enabled = true
config_file = /etc/grafana/ldap.toml
allow_sign_up = true
Dans le fichier /etc/grafana/ldap.toml
# To troubleshoot and get more log info enable ldap debug logging in grafana.ini
# [log]
# filters = ldap:debug
[[servers]]
# Ldap server host (specify multiple hosts space separated)
host = "<ldap host>"
# Default port is 389 or 636 if use_ssl = true
port = 636
# Set to true if ldap server supports TLS
use_ssl = true
# Set to true if connect ldap server with STARTTLS pattern (create connection in insecure, then upgrade to secure connection with TLS)
start_tls = false
# set to true if you want to skip ssl cert validation
ssl_skip_verify = false
# set to the path to your root CA certificate or leave unset to use system defaults
# root_ca_cert = "/path/to/certificate.crt"
# Authentication against LDAP servers requiring client certificates
# client_cert = "/path/to/client.crt"
# client_key = "/path/to/client.key"
# Search user bind dn
bind_dn = "bind_dn"
# Search user bind password
# If the password contains # or ; you have to wrap it with triple quotes. Ex """#password;"""
bind_password = '<ldap user password>'
# User search filter, for example "(cn=%s)" or "(sAMAccountName=%s)" or "(uid=%s)"
search_filter = "(uid=%s)"
# An array of base dns to search through
search_base_dns = ["ou=people,dc=ldap,dc=cloud,dc=dune"]
## For Posix or LDAP setups that does not support member_of attribute you can define the below settings
## Please check grafana LDAP docs for examples
#group_search_filter = "(&(objectClass=posixGroup)(memberUid=%s))"
#group_search_base_dns = ["ou=groups,dc=grafana,dc=org"]
# Specify names of the ldap attributes your ldap uses
[servers.attributes]
name = "cn"
surname = ""
username = "uid"
member_of = "gidNumber"
email = "Email"
# Map ldap groups to grafana org roles
[[servers.group_mappings]]
group_dn = "cn=admins,dc=grafana,dc=org"
org_role = "Admin"
# To make user an instance admin (Grafana Admin) uncomment line below
# grafana_admin = true
# The Grafana organization database id, optional, if left out the default org (id 1) will be used
# org_id = 1
[[servers.group_mappings]]
group_dn = "cn=users,dc=grafana,dc=org"
org_role = "Editor"
[[servers.group_mappings]]
# If you want to match all (or no ldap groups) then you can use wildcard
group_dn = "*"
org_role = "Viewer"
Et la sécurité ?
Prometheus et tous ses composants ne fournissent pas d'authentification, d'identification, ni le chiffrement des données. C'est pourquoi il est vivement conseillé d'utiliser un serveur nginx comme reverse Proxy.
Toutefois, le TLS est parfaitement et nativement supporté entre la ou les instance(s) serveur(s) Prometheus et les instances à superviser.
Conclusion
Ce premier article présente Prometheus, qui est un système de supervision complet. Bien qu'il soit récent sur le marché, comparé à Nagios, Centreon ou Zabbix, il se développe rapidement avec une communauté dynamique qui ne cesse de croître.
Il correspond aux besoins modernes de supervision d'une infrastructure de type Cloud avec pour principales qualités :
- Robustesse ;
- Intégration complète dans des systèmes comme OKD, K8S, Openstack ;
- Un système d'alerting configurable.
Un second article présentera un comparatif des autres solutions de supervision du marché avec Prometheus.