

Les Nokia Bell Labs ont publié en 2017 une excellente étude comparative de Kafka et RabbitMQ. Après quelques rappels sur le fonctionnement général des middlewares orientés messages et leurs cas d’usage (éléments principalement tirés de notre livre blanc Le Système d’Information 2016-2021), nous vous proposerons une petite synthèse de cette étude, ponctuellement enrichie au regard des récentes nouveautés apportées dans ces solutions.
Quelques rappels sur les Message Oriented Middlewares
Le fonctionnement de base d’un Middleware Orienté Messages (MOM) est très simple : un programme émetteur génère un message et le publie sur un bus chargé de le diffuser vers un programme consommateur, un message étant composé d’en-têtes, de propriétés et d’une série d’octets constituant son corps (une chaîne de caractères, un objet ou toute donnée sérialisable).

L’émetteur ne remettant pas directement lui-même son message au consommateur, la transmission de l’information n’est pas effectuée de façon synchrone mais de façon asynchrone, à la manière d’un envoi de mail : l’émetteur n’est en contact direct qu’avec le bus, qui donne l’assurance que le message sera bien délivré au consommateur, dans un délai plus ou moins court, même si ce consommateur n’est pas disponible au moment de la publication.
Les solutions de cette catégorie font donc partie des briques d’intégration d’un Système d'Information, au même titre qu’un ETL ou un ESB, à ceci près que les patterns d’intégration implémentés se limitent au routage (par exemple un message est transmis à tel ou tel consommateur selon son type ou certaines de ses propriétés) et à différents modes de diffusion (comme le point-à-point pour l’envoi d’un message à un consommateur donné ou la publication/souscription pour publier un message sur un sujet donné qui sera diffusé à tous les consommateurs abonnés à ce sujet) : les MOM ne gèrent pas de transformation ou d’enrichissement de messages, n’embarquent pas de logique évoluée.
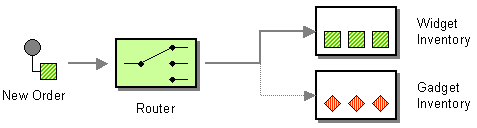

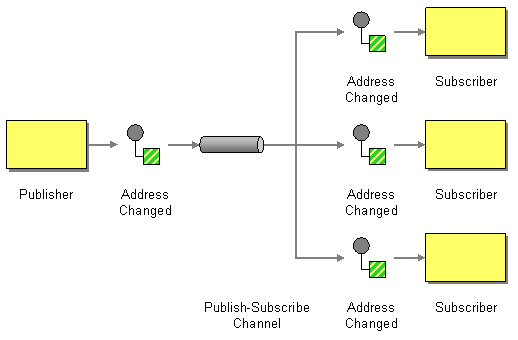
Les cas d’usage d’un MOM
Un MOM sera donc utilisé pour acheminer des événements applicatifs, des demandes de traitement ou toute forme de message (en particulier des données transmises à “haute fréquence”). On pourra de fait retrouver ce type de solution au sein d’architectures orientées événements (CQRS, Event Sourcing) ou d’architectures de services (comme celle des microservices dont l’un des principes phares, “Smart endpoints and dumb pipes”, fait directement allusion aux bus de messages permettant de chorégraphier les services et dont l'action doit strictement se limiter à la bonne livraison des messages publiés).
Les cas d’usage sont nombreux :
- la collecte d’informations issues des objets connectés (Internet of Things - IoT), par exemple dans le domaine de l’analyse des performances sportives ;
- la transmission de métriques diverses relatives aux applications (nombre d’utilisateurs connectés, etc.) ou à leur environnement technique (consommation CPU, consommation mémoire, disponibilité des applications ou de services, etc.) en vue de détection d’anomalies ou d’adaptation automatique de l’environnement d’exécution ;
- l’envoi de mails, SMS et notifications de toutes sortes ;
- la diffusion des actions utilisateurs en vue d’analyses complexes en temps réel (parcours client, détection de fraude, etc.) ;
- la distribution des logs pour constitution de pistes d’audit ;
- effectuer un virement d’un compte bancaire à un autre ;
- les messageries instantanées ;
- etc.
Les solutions MOM sont idéales pour sortir d’une culture batch en privilégiant un mode de traitement au fil de l’eau et apportent un fort découplage technique à votre SI tout en favorisant son élasticité (une même file de messages pouvant être accédée par plusieurs instances d’un même consommateur pour accélérer le traitement) et son évolutivité (de nouveaux consommateurs effectuant des traitement différents peuvent être connectés de façon transparente à une file existante).
Quelle solution utiliser ?
Les solutions Open Source et gratuites sont nombreuses et pour beaucoup matures.
Dans un écosystème 100% Java, et si vous n’avez pas de contrainte de performance particulière, une classique implémentation de la norme JMS comme ActiveMQ ou Joram vous suffira amplement dans beaucoup de cas.
Dans un autre contexte, les solutions à considérer se résument à RabbitMQ et Kafka.
Présentation express de RabbitMQ
RabbitMQ, supporté par l’éditeur Pivotal depuis mai 2013 est utilisé par exemple chez Instagram ou par Clever Cloud pour son offre PaaS.
La solution se base sur une structure de données de type file FIFO dans laquelle les nouveaux messages sont ajoutés en tête (“à gauche”) et sur laquelle les consommateurs lisent le message le plus ancien (= “le plus à droite”).
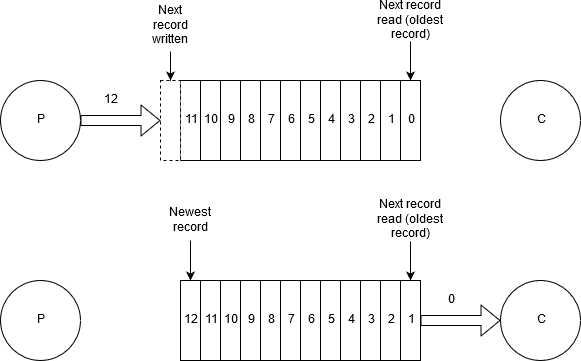
RabbitMQ est une implémentation du protocole AMQP.
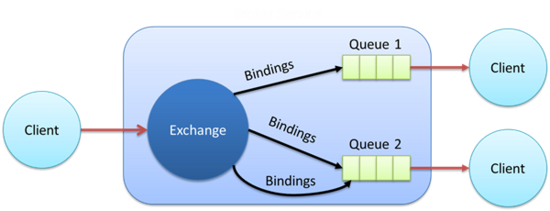
Dans sa version 0.9.1, datant de 2008, le protocole s’attache à définir le format des messages, les trames circulant sur le réseau entre les clients et le bus ainsi que la façon dont le bus doit être mis en œuvre pour diffuser les messages. Ainsi, contrairement à JMS, le producteur n’envoie pas directement son message sur une file de messages mais sur un composant (exchange) chargé de router les messages vers des files à l’écoute de ce composant, suivant différents modes : une clé de routage statique ou dynamique, des en-têtes, en transmettant le message à tous les consommateurs, seulement à un seul, etc. Notez que malgré son numéro de version, il s’agit d’une version stable du protocole implémentée par de nombreuses solutions.
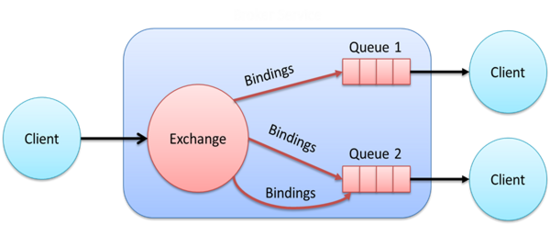
Dans sa version 1.0 publiée en 2012, la spécification ne s’attèle plus qu’à traiter du format des messages et des trames réseau : le cœur du fonctionnement d’un bus n’est plus adressé, les concepts d’exchange et de clé de routage ne sont plus explicités. Avec AMQP 1.0, les éditeurs n’ont donc plus de contrainte particulière sur la façon de mettre en œuvre le bus de messages et se doivent uniquement de respecter le format des messages et le protocole permettant de faire communiquer les clients avec le bus ou plusieurs bus entre eux.
Présentation express de Kafka
Kafka est historiquement utilisé par LinkedIn (son créateur), mais également chez Uber, Netflix, AirBnB, OVH ou Goldman Sachs par exemple.
La structure de données sur laquelle se base Kafka est le Log : de base, les nouveaux messages sont ajoutés à la suite des plus anciens et la lecture s’effectue de gauche à droite nécessitant que les consommateurs gèrent l’indice (offset) du message en cours de traitement (source).
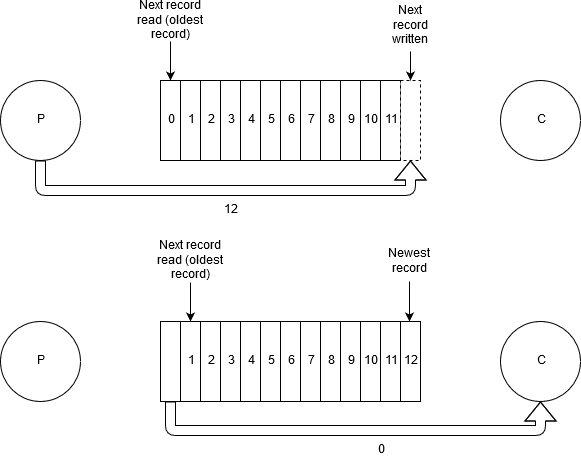
Kafka n’implémente pas un protocole standard et se limite à proposer un mode de diffusion publish-subscribe : tous les messages sont postés sur des topics auxquels s’abonnent les consommateurs, tous les messages postés sur un même topic ayant idéalement trait au même thème.
Le comparatif RabbitMQ/Kafka
Regardons à présent de plus près ces deux solutions à travers la synthèse promise de l’étude des Nokia Bell Labs.
Les fonctionnalités communes
| RabbitMQ | Kafka |
|---|---|
| Stockage des messages | |
| RabbitMQ fonctionne de manière optimale lorsque les files sont vides ou presque vides, c’est-à-dire que les messages doivent être consommés “rapidement”.
Stockage des messages dans une base Mnésia, en mémoire puis, à saturation, sur disque, impactant alors les performances. |
Kafka est architecturé pour permettre de consommer les messages à différentes échelles de temps, ce qui peut entraîner une accumulation importante de données sur un laps de temps relativement long. Stockage des messages sur disque, sous forme de log segmenté en fichiers de tailles équivalentes, un nouveau message étant toujours ajouté à la fin du log. |
| Logique de routage | |
| Règles de routage très flexibles basées sur des clés de routage dynamiques ou sur l’entête des messages. | Routage basique utilisant la notion de topic (une file par thème (topic), tous les messages d’une même file correspondant à un même thème). |
| Garantie de livraison (mode At Least Once, aucun message perdu mais doublons possibles) | |
| Bonne transmission des messages garantie par des mécanismes d’acquittement émis du broker au producteur (après écriture sur disque pour les files persistantes) et des consommateurs au broker (un message consommé étant ensuite supprimé de la file). |
Acquittement envoyé du broker au producteur et stockage du message qui peut être consommé par tout consommateur jusqu’à expiration.
L’acquittement envoyé peut l’être immédiatement après réception du message par le nœud principal (avant ou après écriture sur disque selon configuration), ou après atteinte d’un quorum des nœuds ayant réceptionné le message (avant ou après écriture sur disque selon configuration). |
| Conservation de l’ordre des messages | |
| L’ordre des messages est uniquement conservé pour les messages émis sur un même channel (une connexion TCP multiplexée). A noter qu’il est également conservé en cas d’acquittement négatif d’un consommateur induisant une réinjection en file d’attente. Par contre, après résolution d’un partitionnement réseau, l’ordre n’est plus garanti (messages supprimés de la partition non élue). | L’ordre des messages n’est garanti qu’au niveau d’une unique partition (NB : pour des questions de performance, un topic peut se décomposer en plusieurs partitions réparties entre les différents nœuds d’un cluster, induisant alors une distribution des messages parmi les partitions du topic sur lequel ils ont été publiés). |
| Multidiffusion | |
| Multicast opérationnel grâce à la possibilité de connecter plusieurs files à un même échangeur et chacune des files à un unique consommateur (NB : le message n’est pas répliqué dans chacune des files). | Multicast géré au niveau des groupes de consommateurs : un message n’est envoyé qu’à un seul membre d’un groupe de consommateurs, s’il doit être multidiffusé il doit exister autant de groupes de consommateurs que de consommateurs auxquels transmettre le message. |
| Mise à l'échelle dynamique | |
| Possibilité d’ajouter ou de supprimer des nœuds à un cluster de façon transparente pour les consommateurs.
Plusieurs consommateurs peuvent être connectés à une unique file pour accélérer le traitement (l’ordre des messages n’étant donc plus considéré comme important). Possibilité de choisir entre des disk nodes (pour déversement sur disque) et des ram nodes (stockage uniquement en mémoire) selon les performances souhaitées. |
Dans un cluster Kafka l’ajout et la suppression d’un nœud sont possibles via des opérations manuelles (dans la version communautaire de la solution, automatiquement dans sa version éditeur).
Les topics peuvent être mis à l’échelle grâce à la distribution de leurs partitions sur les différentes instances de broker. Plus il y a de consommateurs dans un groupe de consommateurs, plus la consommation des partitions d’un topic est rapide. |
| Disponibilité | |
| Mécanisme de réplication des différents composants (échangeurs et files -> files miroir) entre les différentes instances RabbitMQ d’un cluster.
En cas de partitionnement réseau du cluster, possibilité de résolution manuelle ou via différents modes de rétablissement automatique (autoheal, etc.), mais perte des messages de la partition non élue. Les messages sont toujours consommés sur la file maîtresse tandis que la publication peut être faite sur n’importe quelle file. Une nouvelle file maîtresse ajoutée à un nouveau nœud est immédiatement accessible pour la production et la consommation de messages. La synchronisation entre les files et les files miroirs rejoignant le cluster (lors de la création d’un nouveau nœud ou de la résolution d’un partitionnement réseau) peut être faite manuellement ou de façon automatique, en masse ou au fil de l’eau via micro-batches, la file maîtresse étant indisponible le temps de la synchronisation et les nouvelles files miroir n’étant accessibles qu’une fois la synchronisation finalisée. |
Haute disponibilité variable basée sur un facteur de réplication : les topics sont subdivisés en partitions et chaque partition peut disposer de multiples réplicas, répartis sur les différents brokers d’un cluster.
Tout comme l’augmentation du facteur de réplication, les opérations d’ajout et de suppression d’un broker au cluster induisent la réaffectation des partitions entre les différents consommateurs disponibles (opération appelée rebalance). Durant ce rebalance, les consommateurs sont temporairement indisponibles. La gestion d’un cluster Kafka est déléguée à un cluster Zookeeper. Ce dernier gère également les configurations ou le mécanisme d’élection des partitions leaders. La gestion des offsets (l’identifiant des messages en cours de consommation) est à la main de Kafka depuis la version 0.9. |
| Disaster recovery | |
| Réplication à travers un WAN possible via le plugin Federation (propagation de brokers en brokers à travers un WAN via le plugin Shovel). |
Réplication inter-datacenters en mode maître-esclave via Mirror Maker ou Replicator (propriétaire). Comparatif disponible ici. |
| Sécurité | |
|
Depuis la v0.9 :
|
Les différences les plus notables entre les deux solutions
Spécificités Kafka
- Il est possible de conserver les messages sur une durée paramétrable, les messages n’étant purgés qu’à expiration du délai spécifié ou lorsque le système de fichiers arrive à saturation (tous les messages ont un timestamp).
- Cette capacité de rétention couplée au fait que Kafka ne conserve aucune information sur les consommateurs permet à ces derniers de consommer plusieurs fois un même message si besoin, à la demande (s’ils sont dans des groupes de consommateurs distincts).
- Kafka offre une fonctionnalité de compactage permettant de ne conserver que le dernier message d’une série de messages possédant un même identifiant (messages stockés de fait sur une même partition).
- De nombreux connecteurs, basés sur Kafka Connect, permettent de transférer facilement de gros volumes de données en provenance ou vers de multiples solutions.
- Kafka Streams apporte la possibilité d’effectuer des traitements parallélisés sur des messages en flux continus, à travers des représentations des topics compactées (KTable) ou non (KStream).
- Le mode exactly once garantit qu’un message soit bien délivré, et ce une seule fois.
- Les transactions sont supportées depuis la version 0.11.0. Les consommateurs peuvent être configurés pour ne pas tenir compte des messages non acquittés, faisant partie d’une transaction non validée. Fonctionnement des transactions côté producteur :
| Étape 0 | Étape 1 - Initialisation de la transaction |
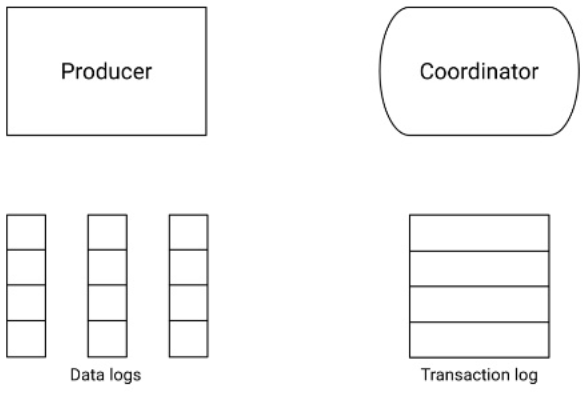
|
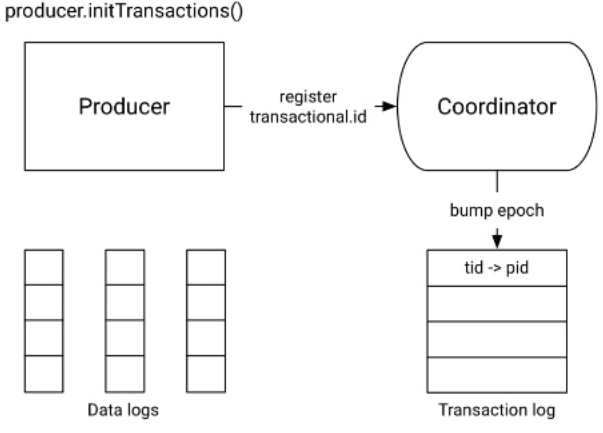
|
| Étape 2 - Démarrage de la transaction et envoi des messages | |
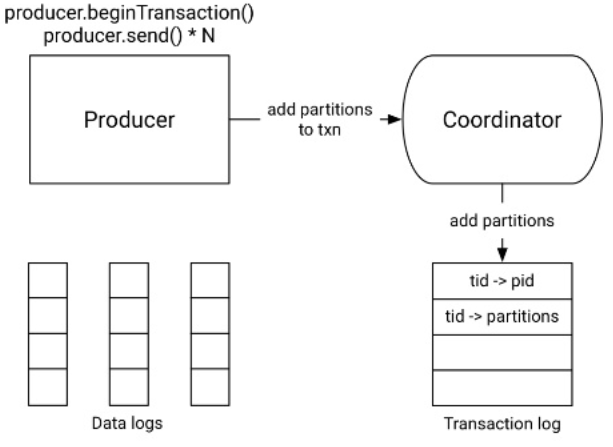
|
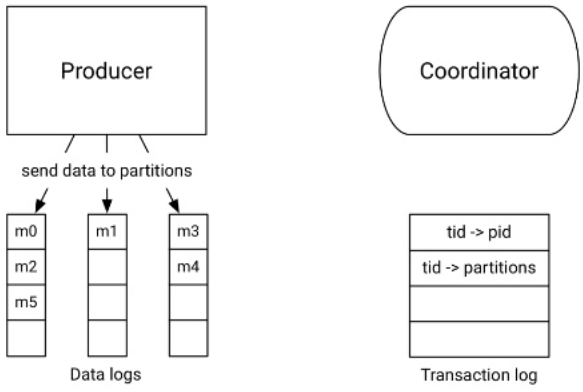
|
| Étape 3 - Commit de la transaction | |
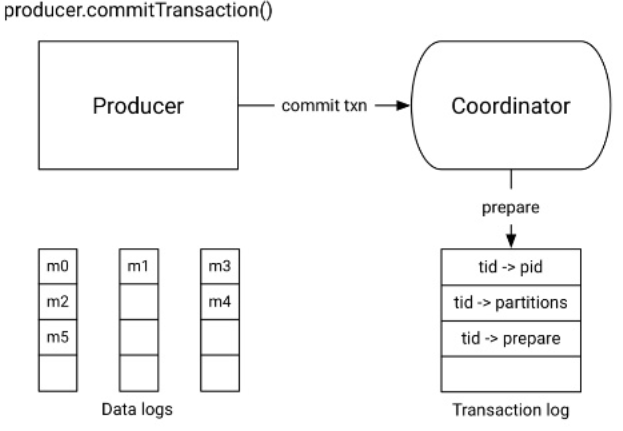
|
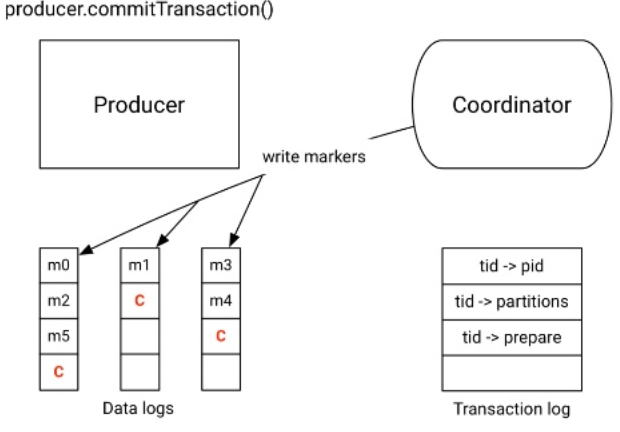
|
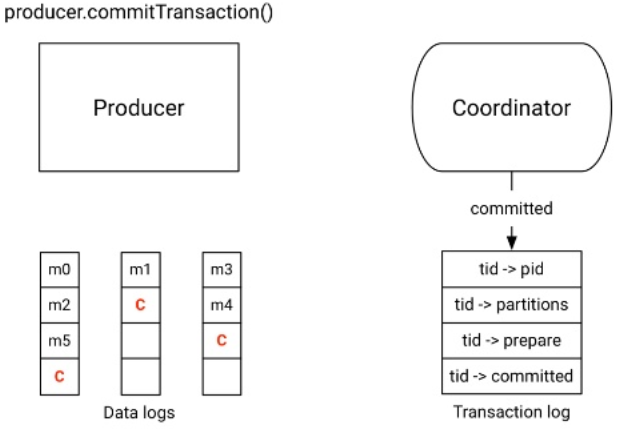
|
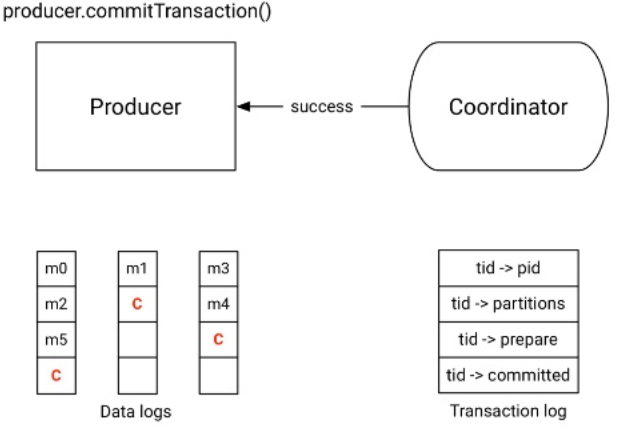
|
Notez qu’à travers sa version éditeur proposée par Confluent, Kafka se voit également doté d’un Schema Registry permettant d’associer un schéma de message à un topic afin que seuls des messages respectant une structure donnée puissent être publiés sur le topic en question.
Spécificités RabbitMQ
- RabbitMQ est une implémentation d’AMQP, un protocole standardisé, ce qui doit garantir une communication facilitée avec d’autres solutions implémentant ce même protocole, voire un remplacement d’une solution par une autre.
- RabbitMQ supporte STOMP pour la communication bi-directionnelle client/serveur à travers des websockets et MQTT pour la communication entre dispositifs dans l’IoT.
- A travers le mécanisme de virtual host d’AMQP, RabbitMQ peut gérer sur un unique broker plusieurs groupes logiques de composantes totalement isolées les unes des autres (files, échangeurs, policies, autorisations, utilisateurs). Composantes facilement paramétrables et monitorables via la console d’administration.
- RabbitMQ peut fonctionner uniquement en mémoire et contrôler le débit des publishers.
- Il est possible de limiter la taille des files de messages (limitation applicable au nombre de messages par file ou à la taille totale des messages dans la file) et d’appliquer une durée de vie à chaque message.
- La gestion des transactions est partielle dans RabbitMQ : côté producteur uniquement pour la publication, les acquittements et les rejets mais sans garantie d’atomicité (pas de retour à l’état initial antérieur à une transaction en erreur) ; côté consommateurs seuls les acquittements sont transactionnels.
Quand préférer RabbitMQ et quand préférer Kafka
A la lumière de ces points communs et de ces différences, l’étude propose quelques cas d’usage pour lesquels préférer RabbitMQ et d’autres pour lesquels on s’orientera plutôt vers Kafka.
Au final, on optera de préférence pour RabbitMQ pour :
- du publish/subscribe classique ou requérant un routage élaboré des messages ;
- la mise en œuvre du pattern RPC grâce à l’entête reply-to et la génération d’une file de callback à la volée ;
- suivre des métriques opérationnelles ;
- l’utilisation des protocoles spécifiques STOMP (Streaming Text Oriented Messaging Protocol, parfait avec des websockets pour afficher des messages en temps réels dans les applications web ou mobiles) et MQTT (Message Queue Telemetry Transport, idéal dans l’IoT et les systèmes embarqués pour garantir une utilisation minimale de la bande passante).
Tandis qu’on préférera Kafka pour :
- la mise en œuvre du pattern publish/subscribe si la logique de routage souhaitée est simple (correspond au fonctionnement des topics) et si le débit par topic est supérieur à ce que peut gérer RabbitMQ ou encore si l’ordre des messages est primordial ;
- ingérer une quantité très importante de données en un minimum de temps, avec un très fort besoin de mise à l’échelle ;
- conserver les messages à plus ou moins long terme ;
- capturer tous les événements induisant un changement d’état d’un élément du SI (grâce à Kafka Connect, pour capter les changements dans une base de données par exemple) ;
- effectuer des traitements parallélisés sur les données ou diffuser ces données vers d’autres solutions de traitements de données ;
- des besoins transactionnels.
Sont également imaginées des utilisations combinées des deux solutions :
- RabbitMQ en amont de Kafka : si seulement certains flux de données requièrent un stockage à long terme, le positionnement de RabbitMQ en tête de pont permettant de garantir un meilleur temps de réponse (meilleure latence) et de filtrer efficacement les messages devant être persistés ;
- Kafka en amont de RabbitMQ : si le débit d’ingestion est très élevé mais que les mécanismes de routage de RabbitMQ s’avèrent nécessaires.
Conclusion
A travers cette synthèse de l’étude des Nokia Bell Labs, vous devriez à présent disposer d’une bonne vision de ce que proposent respectivement RabbitMQ et Kafka. Je vous conseille également ce comparatif en plusieurs épisodes qui aborde notamment plus en détails les différents patterns particuliers à chacune des deux solutions.
Notez enfin, en ce mois de Temps Fort Cloud chez Ippon, que les deux solutions ont des ailes : au-delà de l’offre SaaS du cloud Confluent, le très populaire Kafka peut être déployé sur l’EC2 AWS par exemple (voire utilisé sous sa forme entièrement serverless, Kinesis), et de son côté RabbitMQ n’est pas en reste grâce à l’offre SaaS de CloudAMQP et la démonstration par Zalando qu’il est également possible de déployer la solution de Pivotal sur Amazon.
