

Suite à l’édition 2016 du BDX.IO, j’ai souhaité rédiger un article sur la conférence de Yan Bonnel intitulée Postgresql – la nouvelle base de données orientée document. Lors de ce talk les fonctionnalités apportées par les types JSON et JSONB de PostgreSQL ont été présentées.
Vidéo de la présentation: https://www.youtube.com/watch?v=cuf0Ov6_PxU
Introduction
Depuis la fin des années 2000, de nouveaux SGBD dits NoSQL ont commencé à se démocratiser. En effet, on distingue généralement cette nouvelle famille de SGBD (MongoDB, Redis, Cassandra, ArangoDb, etc.) aux SGBD classiques, à savoir les bases de données relationnelles (MySQL, PostgreSQL, SQL Server, Oracle). Il est clair que chaque SGBD présente des caractéristiques et des avantages spécifiques : les SGBD NoSQL apportent notamment de la scalabilité et la possibilité de traiter des données déstructurées. Lorsqu’on commence un nouveau projet, on en vient souvent à se demander si l’on doit utiliser une base de données NoSQL ou une base de type relationnel. On peut aussi décider d’utiliser plusieurs bases de types différents au risque d’augmenter la complexité de l’application et de son environnement.
PostgreSQL dans sa version 9.3 (2013) puis 9.4 (2014) a introduit respectivement les types JSON et JSONB. JSONB est une version binaire de JSON permettant notamment d’indexer les documents. Le JSONB permet d’avoir une nouvelle approche : pourquoi ne pas mélanger les mondes NoSQL et SQL ?
Ces types de champ, venant avec un lot d’opérateurs et de fonctions, permettent en effet de mélanger les notions relationnelles classiques de PostgreSQL avec une approche orientée document semblable à MongoDB. À travers cet article je vais vous présenter certaines fonctionnalités clés des types JSON. Cet article étant une introduction à ces fonctionnalités, elles ne seront pas toutes abordées. Je vous invite à consulter la documentation de PostgreSQL pour approfondir les notions présentées dans l’article (https://www.postgresql.org/docs/current/static/functions-json.html).
PostgreSQL et JSON dans la pratique
Opérateurs JSON
Accès aux données
Les types JSON permettent donc d’avoir, dans une table classique, des colonnes stockant des chaînes de caractères au format JSON. Ces colonnes peuvent cohabiter avec des colonnes classiques : numériques, dates, chaînes de caractères, etc. Comme nous allons le voir, de nouveaux opérateurs permettent ensuite de manipuler directement ces données déstructurées.
Pour mon premier exemple, j’ai stocké dans une table des données JSON venant de l’API Google Place. La structure de la table est simple :
|
Nom de la colonne |
Type |
|---|---|
|
data |
JSONB |
{ "geometry":{ "location":{ ... } }, "icon":"https://maps.gstatic.com/mapfiles/place_api/icons/lodging-71.png", "id":"52ca2f666b8d240ef271a989608c5afa564a3a15", "name":"Mama Shelter Bordeaux", "opening_hours":{ "open_now":true }, "photos":[ { ... } ], "place_id":"ChIJLbJeUtsnVQ0RBUfcelEwIEQ", "rating":3.8, "reference": ..., "scope":"GOOGLE", "types":[ ... ], "vicinity":"19 Rue Poquelin Molière, Bordeaux" }
Nous allons maintenant utiliser PostgreSQL pour trouver les 3 meilleurs bars à vin ouverts à côtés de l’agence. Commençons par écrire des requêtes sur nos données JSON.
SELECT data->>'name' as NAME, data->>'vicinity' as ADDRESS FROM bar
|
NAME |
ADDRESS |
|
“Mama Shelter Bordeaux”“The Connemara” “La Brasserie Bordelaise” “Le Rohan” “5th Avenue” “LE QG DE MONBADON” “La Cigale” “Le Noailles” “Aux quatre coins du vin” “Le trou duck” “Restaurant les Sens Ciel” “Lantre de Peggy” “Le Bar à Vin” “Le Wine Bar” “Chez les Ploucs” “Restaurant LOliveraie” “Dubern” “Calle Ocho” “Le Karma” |
“19 Rue Poquelin Molière, Bordeaux”“14-18 Cours Albret, Bordeaux” “50 Rue Saint-Rémi, Bordeaux” “1 Place Pey Berland, Bordeaux” “10 Rue Montesquieu, Bordeaux” “43 Rue Lafaurie Monbadon, Bordeaux” “42 Rue du Maréchal Joffre, Bordeaux” “12 Allées Tourny, Bordeaux” “8 Rue de la Devise, Bordeaux” “33 Rue Piliers de Tutelle, Bordeaux” “59 Rue du Palais Gallien, Bordeaux” “45 Rue de la Devise, Bordeaux” “3 Cours du 30 Juillet, Bordeaux” “19 Rue des Bahutiers, Bordeaux” “10 Rue des Faussets, Bordeaux” “33 Rue du Cancera, Bordeaux” “44 Allée de Tourny, Bordeaux” “24 Rue Piliers de Tutelle, Bordeaux” “43 Rue du Pas-Saint-Georges, Bordeaux” “11 Rue Parlement Sainte-Catherine, Bordeaux” |
L’opérateur ‘->>’ permet de récupérer toutes les valeurs associées aux clés name et vicinity présentes dans notre colonne data sous forme de chaîne de caractères comme s’il s’agissait d’une colonne classique. La requête nous retourne donc ici le nom et l’adresse de tous les bars à vin à proximité : plutôt simple, non ?
Allons plus loin en filtrant uniquement les bars ouverts. Grâce à ces nouveaux opérateurs, les données JSON peuvent être exploitées comme n’importe quelle autre donnée.
SELECT data->>'name' as NAME, data->>'vicinity' as ADDRESS FROM bar WHERE data->'opening_hours'->>'open_now' = 'true'
|
NAME |
ADDRESS |
| “The Connemara”“Le Rohan”
“5th Avenue” “Le Noailles” “The Houses Of Parliament” | “14-18 Cours Albret, Bordeaux”“1 Place Pey Berland, Bordeaux”
“10 Rue Montesquieu, Bordeaux” “12 Allées Tourny, Bordeaux” “11 Rue Parlement Sainte-Catherine, Bordeaux” |
SELECT data->>'name' as NAME, data->>'vicinity' as ADDRESS, (data->>'rating')::NUMERIC as RATE FROM bar WHERE data->'opening_hours'->>'open_now' = 'true' ORDER BY RATE DESC LIMIT 3
|
NAME |
ADDRESS |
RATE |
| “The Houses Of Parliament”“The Connemara” “5th Avenue” | “11 Rue Parlement Sainte-Catherine, Bordeaux”“14-18 Cours Albret, Bordeaux”
“10 Rue Montesquieu, Bordeaux” | 4.34.1
3.9 |
Vérification de structure de documents
Pour notre deuxième exemple, nous allons manipuler des fruits. Considérons la structure de table suivante :
|
Nom de la colonne |
Type |
| Id | NUMERIC |
| data | JSONB |
{ "name" : "apple", "quantity" : 6 }
{ "name" : "banana", "quantity" : 1, "variety" : "tiger"}
Les documents stockés dans cette table sont plus simples, mais varient selon les lignes. Ce qui lève une nouvelle problématique : comment récupérer les données correspondant à une structure voulue ?
Un autre opérateur de PostgreSQL permet de s’affranchir de ce problème. Il s’agit de l’opérateur ‘?’. Cet opérateur permet de tester si une clé est présente dans un document. Ainsi, la requête suivante permet de faire la somme de la quantité de toutes les bananes ayant une variété :
SELECT SUM((data->>'quantity')::NUMERIC) AS quantity FROM fruits
WHERE data ? 'variety' AND data->>'name' = 'banana'
|
Quantity |
Résultat |
| 0 | 1 |
Ecriture
Insertion
L’écriture de nouveaux éléments dans une table contenant du JSON est proche de ce que l’on connaît en SQL classique. Les documents JSON sont des chaînes de caractères. Cependant, PostgreSQL possède un validateur syntaxique du JSON qui permet d’assurer l’intégrité des documents.
La requête suivante permet donc d’insérer une nouvelle ligne dans notre table fruits.
INSERT INTO fruits VALUES (10, '{ "name" : "banana", "quantity" : 1, "variety" : "tiger"}')
Modification
À mon sens, la modification de valeur dans un document JSON de PostgreSQL est laborieuse. Comme nous l’avons vu, un document JSON est en réalité une chaîne de caractères pour PostgreSQL. Il n’existe pas de syntaxe spécifique permettant de modifier un document JSON via les opérateurs. Il faut modifier la chaîne JSON dans son intégralité. Des fonctions PostgreSQL telles que Jsonb_set() apportent une solution pour modifier des documents. Jsonb_set() modifie la valeur associée à une clé pour un document donné. Elle retourne le document modifié dans son intégralité.
Par exemple, la requête suivante permet de modifier la quantité de banane de la variété golden :
UPDATE fruits SET data = Jsonb_set(data, '{quantity}', '3') WHERE data->>'name' = 'banana' AND data->>'variety' = 'golden';
Des solutions peuvent permettre de modifier des documents dans des cas simples comme le nôtre. Mais pour des requêtes plus complexes, PostgreSQL devient rapidement verbeux et difficile à utiliser.
Indexation
Entre autres, JSONB a introduit la notion d’indexation de clés de document. On peut donc tirer parti des avantages apportés par les indexes SQL directement dans des documents JSON. L’exemple ci-dessous montre la création d’un tel indexe :
CREATE UNIQUE INDEX variety ON fruits ((data->>'variety'));
Cette indexation permet de bloquer la requête suivante en cas de duplication de valeurs :
INSERT INTO fruits VALUES (11, '{ "name" : "banana", "quantity" : 1, "variety" : "golden"}')
ERROR: duplicate key value violates unique constraint "variety"<br></br>``DETAIL: Key ((data ->> 'variety'::text))=(golden) already exists.
Les indexes apportent évidemment de nombreux autres avantages, notamment concernant :
- la gestion relationnelle des tables sur des documents,
- les performances de recherche dans les documents,
- l’intégrité des données.
Quelques fonctions JSON
Pour finir la présentation technique de JSON au sein de PostgreSQL, je vous propose de détailler les principales fonctions. On distingue donc deux grandes familles de fonctions JSON / PostgreSQL : des fonctions de création et des fonctions de traitement. Cet ensemble de fonctions et d’opérateurs JSON vient enrichir les fonctionnalités classiques de PostgreSQL et apporte un outil puissant. Il permettent de stocker facilement des documents JSON dans un contexte relationnel et proposent des outils de lecture performants et simples.
Pour illustrer ces fonctions, nous allons utiliser une table SQL classique contenant des informations sur des utilisateurs. La structure de la table users est la suivante :
|
Nom de la colonne |
Type de la colonne |
| id | NUMERIC |
| nom | VARCHAR |
| prénom | VARCHAR |
row_to_json()
Cette fonction peut s’avérer très utile, notamment dans le cas de construction d’API REST simple. Elle permet de retourner une ligne SQL directement sous la forme d’un document Json.
SELECT row_to_json(users) AS users FROM users
|
Users |
Résultat |
| 0 | “{“id”:1,”nom”:”Doeuf”,”prenom”:”John”}” |
| 1 | “{“id”:1,”nom”:”Saisrien”,”prenom”:”Jean”}” |
array_to_json()
Pour aller encore plus loin dans la récupération d’objets au format JSON, cette fonction permet de convertir un tableau PostgreSQL en tableau d’objets JSON.
SELECT array_to_json(array_agg(row_to_json(users))) AS userarray FROM(SELECT id, nom from users) users
|
UserArray |
Résultat |
| 0 | “[{“id”:1,”nom”:”Doeuf”},{“id”:1,”nom”:”Saisrien”}]” |
json_array_length()
Les fonctions que nous venons de voir permettent de transformer la donnée brute SQL d’un résultat de recherche au format JSON. PostgreSQL propose aussi des fonctions d’analyse et de traitement des champs au format JSON. Par exemple, la fonction json_array_length() retourne le nombre d’éléments contenus dans un tableau JSON.
SELECT json_array_length(array_to_json(array_agg(row_to_json(users)))) AS numberofelements FROM(SELECT id, nom from users) users
|
NumberOfElements |
Résultat |
| 0 | 2 |
json_object_keys()
La fonction json_object_keys permet de récupérer toutes les clés associées à des données JSON. Ainsi, la requête suivante :
SELECT DISTINCT json_object_keys(to_json(users)) AS keys FROM(SELECT * FROM users) users
|
Keys |
Résultat |
| 0 | prenom |
| 1 | nom |
| 2 | id |
Maintenant que nous savons quelles sont les possibilités apportées par PostgreSQL et JSON, voyons ensemble les cas d’utilisation.
Cas d’utilisation : la fin du modèle clé/valeur
La présentation de Yann Bonnel m’a particulièrement intéressé, car j’ai pu la mettre en perspective avec le projet sur lequel je travaille actuellement. Je travaille sur un portail applicatif “legacy” qui utilise PostgreSQL sans les fonctionnalités JSON. Lors de la conférence, je n’ai pu m’empêcher de penser aux avantages que l’utilisation de JSON pourrait nous apporter.
Dans notre base de données, nous sommes régulièrement amenés à stocker des données ayant une structure en partie statique mais ayant aussi une partie variable selon les cas et pouvant évoluer. Le modèle relationnel, manquant de flexibilité, ne permet pas directement de s’adapter aux besoins actuels et à venir. Nous avons donc recours à la solution classique consistant à avoir une table clé/valeur jointe à une table ayant une structure de données statique. Ainsi, l’ajout de données mappées sur des clés identifiées nous permet d’avoir une structure “dynamique”.
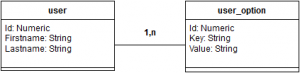
Cette solution fonctionne. Mais elle amène beaucoup de complexité à l’utilisation. Entre autre, lorsque l’on veut récupérer plusieurs valeurs issues de la table clé/valeur, on doit faire autant de jointures que de données à récupérer. L’utilisation d’une colonne de type JSON aurait permis dans une seule et même table de stocker nos valeurs statiques dans des colonnes classiques et de stocker dans un document JSON toutes nos données à structure variable.

Cette structure nous permet de nous appuyer sur la flexibilité apportée par JSON pour adapter notre schéma de données au besoin. De plus, les nouveaux opérateurs apportés par PostgreSQL auraient facilité la manipulation de nos données.
Rétrospective sur la technologie
Comme nous l’avons vu, ces fonctionnalités apportent à PostgreSQL de la flexibilité venant d’une capacité à traiter des données dont la structure peut différer. Ceci dit, ces fonctionnalités sont à utiliser dans des cas d’utilisation tirant pleinement partie de l’aspect hybride : SQL / orienté documents.
Les types JSON ont été introduits dans des versions relativement anciennes de PostgreSQL et sont souvent disponibles dans les environnements actuellement en production. Leur adoption ne nécessite donc pas de mise à jour ou le déploiement d’outils tiers.
Ces fonctionnalités apportent un outil puissant, mais leurs cas d’utilisation sont, selon moi, limités. Je ne pense pas que PostgreSQL puisse être considéré comme une base de données orientée document à proprement parler. Mais dans le contexte d’applications “legacy”, les types JSON peuvent être une bonne solution pour amorcer une transition vers NoSQL.
Même si son utilisation comme un SGBD orienté document est envisageable, elle présente rapidement des limites :
- La gestion des données JSON en écriture est difficile et verbeuse.
- PostgreSQL/JSON souffre d’un manque de technologies permettant d’exploiter ces fonctionnalités.
Ces technologies n’étant pas spécialement récentes (plus de 2 ans), on peut supposer un mauvais accueil des différentes communautés (Java, .NET, C++). Les outils les plus populaires permettant d’utiliser PostgreSQL à haut niveau (ORM) ne proposent souvent pas d’implémentation permettant une utilisation facile des types JSON. En effet, il n’existe par exemple pas d’implémentation de JPA permettant l’utilisation directe des types JSON de PostgreSQL.
De notre point de vue, l’utilisation de SGBD orienté document tel que MongoDB est plus adapté pour bien des raisons dans un contexte non relationnel. Il faut cependant garder à l’esprit que ces fonctionnalités existent et peuvent permettre de répondre à des problématiques de stockage de données déstructurées dans un contexte relationnel.

{kind=link}