

L’édition 2016 de dotScale a eu lieu lundi 25 avril au Théâtre de Paris. dotScale fait partie des conférences dot d’ampleur européenne. La particularité de dotScale est qu’elle est dédiée à la scalabilité. J’ai eu la chance d’y participer.

Le sujet en lui-même est vaste. Il concerne aussi bien les devs, les ops et les devops. Il y est question d’infrastructure, de conteneurisation, de machine learning, de graph processing et de calcul réparti à large échelle. Tout ceci en considérant des volumes de données ou d’interactions grandissants. Ces sujets étaient abordés dans la conférence.

dotScale 2016 était divisée en trois sessions de talks, plus une session de lightning talks. Je vous propose ici un résumé des talks de la journée.
Première session
La conférence a commencé par une présentation du langage Erlang et de son modèle d’acteurs. La présentation a été faite par Mickael Rémond, lead developer sur ejabberd et CEO de ProcessOne. Le modèle Erlang se base sur un ensemble de principes simples comme share nothing (zéro partage) ou let it crash (laisser s’effondrer) — qui se rapproche du fail fast bien connu dans l’agilité. Le modèle des acteurs comme processus léger représente ainsi une référence pour les systèmes scalables et permet de mettre en place des patterns avancés en terme d’informatique répartie, tout en évitant le callback hell. Ce fût une présentation assez enthousiaste sur le modèle des acteurs. Mais pour le coup, il y avait assez peu de regard critique, notamment dans le cas d’une trop grande multiplication des acteurs.
Nous avons eu ensuite une présentation assez intéressante de Vasiliki Kalavri, committer Apache Flink, sur un état de l’art autour du distributed graph processing. État de l’art qui incluait les différents algorithmes et solutions de traitement de graphes ayant un volume important de noeuds autour du calcul du PageRank : algorithmes de propagation (superstep, signal-collect, gather-sum-apply), algorithmes de parcours, algorithmes basés sur des sous-graphes (voisinage proche, motifs de sous-graphe).
Sandeepan Banerjee, de ClusterHQ et ancien responsable de la data chez Google, nous a expliqué qu’il est devenu nécessaire de gérer conjointement conteneur et données dans les environnements de mise en production (dev / staging / prod). D’autant que le problème a pris de l’ampleur avec l’apparition des microservices. La solution proposée par Sandeepan consiste à mettre en place un “Github” pour la donnée avec une sémantique à la Git (push, pull, commit, branch, etc.) et un cloud volume manager pour des conteneurs stateful. Pour cela, ClusterHQ a développé un outil appelé Flocker qui se base sur ZFS, intégrant un système de snapshot et un algorithme de hashage basé sur l’arbre de Merkle.
La présentation suivante était impressionnante : Oliver Keeble du Worldwide LHC Computing Grid (WLCG) du Cern est venu nous présenter la solution qu’ils ont mis en place pour traiter les 40 milliards de collisions de particules produites par le Large Hardon Collider (LHC). Ce volume nécessite 400K CPUs et 300 petaoctets de données le tout réparti sur 150 sites de traitement éparpillés dans le monde. L’ensemble se base sur des outils propres au Cern, comme le File Transfer Service pour le transfert de données ou EOS pour le stockage. La prochaine version du LHC (le HL-LHC) promet 10 fois plus de collisions, soit 10 fois plus de stockage et 50 fois plus de CPUs. (Note : à ce propos, le Cern a mis à disposition du public 300 teraoctets de données de collision du LHC sur son site d’opendata (ref).)

Oliver Keeble
Deuxième session
Juan Benet est venu nous parler d’IPFS (pour InterPlanetary File System). Sous ce nom ambitieux, Juan nous propose un protocole peer-to-peer basé sur BitTorrent distribuant du contenu versionné basé sur Git. Le contenu est divisé en blocs adressables et accessibles par hyperliens, formant ainsi un arbre de Merkle. IPFS permet de bénéficier d’un réseau plus rapide où la suppression de contenu serait plus difficile. De plus, ce protocole est bien plus décentralisé que WorldWideWeb, les noeuds n’ont pas besoin de se faire mutuellement confiance. IPFS ne possède pas de point unique de défaillance.
Nous avons vu Greg Lindahl de Internet Archive. Internet Archive est un organisme à but non lucratif situé aux États-Unis qui s’est donné comme but de stocker des documents de toute sorte au format électronique (livres, vidéos, audios, images, logiciels, etc.). Cela inclut notamment les snapshots de sites Web via sa WayBack Machine, qui contient 478 milliards de captures sur le Web. Internet Archive se base sur deux datacenters dont un en Californie et un autre en Égypte. Pour le stockage, la capacité est de 25 petaoctets de données le tout déposé dans des disques en RAID-1.
Sean Owen, directeur de la Data Science chez Cloudera et committer Apache Spark, nous a montré dans le cadre d’un exemple de machine learning comment améliorer les performances des calculs sur des volumes de données importants. Sa méthode se base sur un partitionnement intelligent des blocs de données, une reformulation au niveau mathématique et aussi le fait de se baser sur des bibliothèques natives pour les calculs mathématiques, et ce même dans le cas de la JVM. Pour ce dernier point, Sean nous conseille netlib-java (qui est intégré dans les dernières versions de Spark) sur la base de BLAS/MKL, la bibliothèque d’algèbre linéaire développée par Intel.
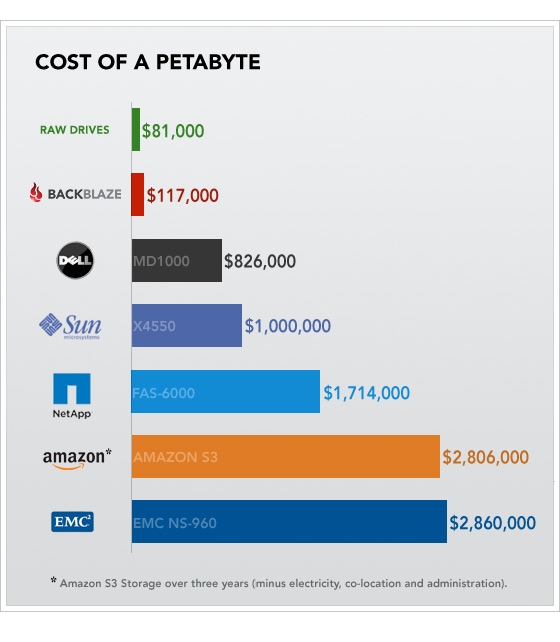
Nous avons vu Gled Budman, CEO de Backblaze. Backblaze est une société qui propose du stockage en ligne. L’originalité de Backblaze est d’avoir mis en place une méthode “agile pour le hardware” afin d’avoir une meilleure maîtrise des coûts et éliminer au détail près tous les surplus inutiles dans la construction de leur datacenter. L’objectif étant de “brancher des disques durs sur Internet”. Ainsi, Gled nous a expliqué (non sans humour) leur approche incrémentale en créant rapidement des prototypes, allant jusqu’à récupérer des alimentations d’ordinateurs de bureau plutôt que des alimentations dédiées aux clusters, récupérer des disques durs à partir de disques externes récupérés chez le vendeur du coin, créer leurs propres boîtiers (appelés Pod) avec une solution pour limiter la propagation des vibrations entre disques ou trouver un moyen de refroidir les baies à ventilation de CPU ou de climatisation. Le résultat : un prix du petaoctet extrêmement bas sur un espace de stockage total de 200 petaoctets. Faite un tour sur leur blog montrant l’évolution de leur pods.

Gled Budman sur scène
Troisième session
Intervention de Ted Dunning
Ted Dunning est connu pour être committer sur Apache Mahout, Drill et Zookeeper, ainsi qu’architecte chez MapR. Le constat qu’il présente est qu’à échelle croissante la valeur de la donnée croît de moins en moins vite (formant une courbe logarithmique) et que son coût augmente de plus en plus vite (formant une courbe exponentielle). La valeur nette (ie. valeur – coût) de la donnée est ainsi hautement contrainte et son pic est atteint dans des échelles de valeurs relativement petites.

Ted Dunning
Pour pallier ce problème, Ted nous présente des solutions afin d’avoir un modèle coût / valeur linéaire en terme de valeur nette. Cela vient en deux phases. En terme de traitement, il faut à la fois être capable de gérer les anciennes données tout en ayant une flexibilité suffisante dans le schéma des nouvelles données (ce que gère Apache Drill). Il ne faut plus représenter le maintenant, mais l’avant et l’après (gérés par la plupart des bases de données à grande échelle ou par Google Spanner ou MapR DB). Et il faut baser les traitements sur de la gestion de flux (streaming), que Ted présente comme omniprésent et performant. En terme de développement, sa vitesse est influencée par la taille des équipes, à laquelle il faut soustraire la quantité de communication et le couplage entre les équipes.
Pour Ted, si la scalabilité est inévitable, alors l’approche microservices doit être adoptée : “microservice wins, not ESB”.
Intervention d’Eric Brewer
Eric Brewer est presque une légende vivante. C’est lui qui est derrière le CAP theorem, théorème qui porte aussi son nom ! Il est actuellement VP de l’infrastructure chez Google.

Eric Brewer lors de la scéance de questions
Le talk d’Eric s’intitulait Cloud Native Design, dans le sens de mettre en place des applications Cloud qui se soucient plus de la valeur apportée par le code que des difficultés liées aux infrastructures (peu de “ops”), pour lesquelles les ressources sont supposées infinies et exécutées par dessus une myriade de services.
Il est venu nous parler dans un premier temps de Kubernetes. Kubernetes se base sur la notion de conteneur comme avec Docker. Les conteneurs sont répartis dans des pods. Chaque pod est colocalisé et permet de partager un volume à l’ensemble de ses conteneurs. Les pods sont répartis et dupliqués sur des machines physiques appelées noeuds. Cette répartition est assurée par les services qui gèrent les pods. Les services permettent aussi de load-balancer les pods.
Là dessus, Eric insiste d’un côté sur la notion d’immutabilité qui implique la notion de robustesse : construire un graphe immutable de ressources, mais aussi un graphe immutable de déploiement. D’un autre côté, il montre l’importance de mettre en place une typologie des éléments du cluster (load-balancer, VM, disk, …). Ceci permet de bénéficier d’une configuration pilotée par les types et diffusable au moment du déploiement.
Suite à quoi, Eric nous a montré une démonstration (une vidéo en fait) affichant la mise à jour progressive de 500 instances du même service en moins d’une minute. Ce n’était pas sans effet waouh !
Et aussi
Un ensemble de lightning talks parlaient de monitoring et comment il permettait d’améliorer ses infrastructures et ses applications, de conflict-free/convergent replicated data type (CRDT), d’arbre de Merkle et de l’intérêt d’avoir à la fois du mono et du multi-repository dans les projets en se basant sur des commandes Git bas niveau (dont git tree).
Spencer Kimball, CEO de Cockroach Labs et co-créateur de Gimp, est venu nous parler de CockroachDB et de son système de transaction, basé notamment sur le protocole raft.
Eliot Horowitz, CEO de MongoDB, nous a parlé d’un talk qu’il a intitulé The case for cross-service joins. Par service, Eliot entend des services comme, par exemple, MongoDB Cloud Service, Jira, Salesforce, MongoDB University, etc. Ces services génèrent des données que nous avons tendance à conserver dans un datalake, qu’Eliot voit comme un “coûteux dépôt d’ordures”. Eliot insiste sur le fait d’avoir une base de données par service et d’éviter de tout mélanger.
Conclusion
Le problème de la scalabilité peut se définir comme suit : conserver, transférer, répartir et traiter des volumes de données de plus en plus importants et appliquer dessus des processus fins.
Si dotScale 2016 est représentatif de la vision en terme de scalabilité cette année, les solutions présentées par les speakers peuvent se diviser selon différents axes complémentaires. En terme de données, elles doivent être immutables. Mieux, celles-ci représentent des événements et il est possible de les traiter sous forme de flux. Des aspects que traite l’event sourcing. La validation (ou certification) et la sécurisation des données (au sens tolérance à la panne et lutte contre la falsification) est un aspect sur lequel le blockchain (arbre de Merkle, CRDT) apporte une solution sur des échelles importantes. Sur le plan logiciel, le découpage en petites entités (de traitement, de calcul) est nécessaire pour paralléliser le travail et le répartir sur un cluster. Cela pose le problème du provisionnement et du déploiement. Il convient dans ce cas de mettre en place une typologie claire des éléments de l’infrastructure (load balancer, disk, vm, etc.). L’immutabilité (à nouveau) permet alors de garantir la reproductibilité du déploiement dans les différents environnements de mise en production. Sur le plan économique, l’agilité et les approches semblables permettent d’apporter une meilleure maîtrise des coûts lorsque les volumes de données augmentent. Ceci se fait en observant plus finement les infrastructures mises en place et les communications entre les équipes IT.

Les speakers et le staff de dotScale 2016
Au final, dotScale 2016 a été pour moi une conférence inspirante et présentant des speakers de qualité, passionnants et plutôt visionnaires, qui vivent la scalabilité au quotidien. Peu de véritables démos ou de live coding. Mais des talks centrés sur la transmission d’idées. La session 2017 aura lieu le 24 avril. Un dotAI plus orienté machine learning fera d’ailleurs son apparition cette même année.
Note : l’ensemble des photos de l’article (en dehors de la première) sont mis à disposition par dotConferences et sont disponibles sous licence Creative Commons (CC BY-NC-SA 3.0 FR). Les autres photos de dotScale 2016 sont disponibles sous Flickr.
