

Elasticsearch est un moteur de recherche open-source basé sur Apache Lucene. Il se présente sous forme d’un cluster d’indexation, qui s’appuie sur une base documentaire NoSQL interne utilisant le format JSON pour le stockage des documents.
Pourquoi indexer vos documents
Pour des projets ou des organisations de grande taille, et/ou ayant un historique de plusieurs années, il n’est pas rare que la documentation s’accumule (manuels, spécifications, documents d’architecture / de conception, procédures, règlements, bug trackers …) au point que le fait de connaître la documentation pertinente (ou un moyen d’y accéder) devienne une compétence-clé. Le souci n’est plus que l’information soit perdue, mais qu’elle ne soit plus accessible – on parle parfois d’”infobésité”.
Dans ces cas là, la capitalisation et le transfert de la connaissance deviennent une problématique majeure ; heureusement, il y a une solution : un moteur de recherche documentaire.

Principes de fonctionnement
Un moteur de recherche documentaire fonctionne de façon très différente des recherches à la mode SQL : « select (attributs) from (source) where (condition) »… Ces requêtes sont qualifiées de « booléennes », car il n’y a pas de notion de pertinence des résultats : soit la donnée satisfait la condition, soit elle n’est pas remontée.
A contrario, un moteur de recherche comme Elasticsearch permet de remonter des données qui correspondent totalement ou partiellement aux critères et à les classer selon une formule de pertinence, basée sur trois principes :
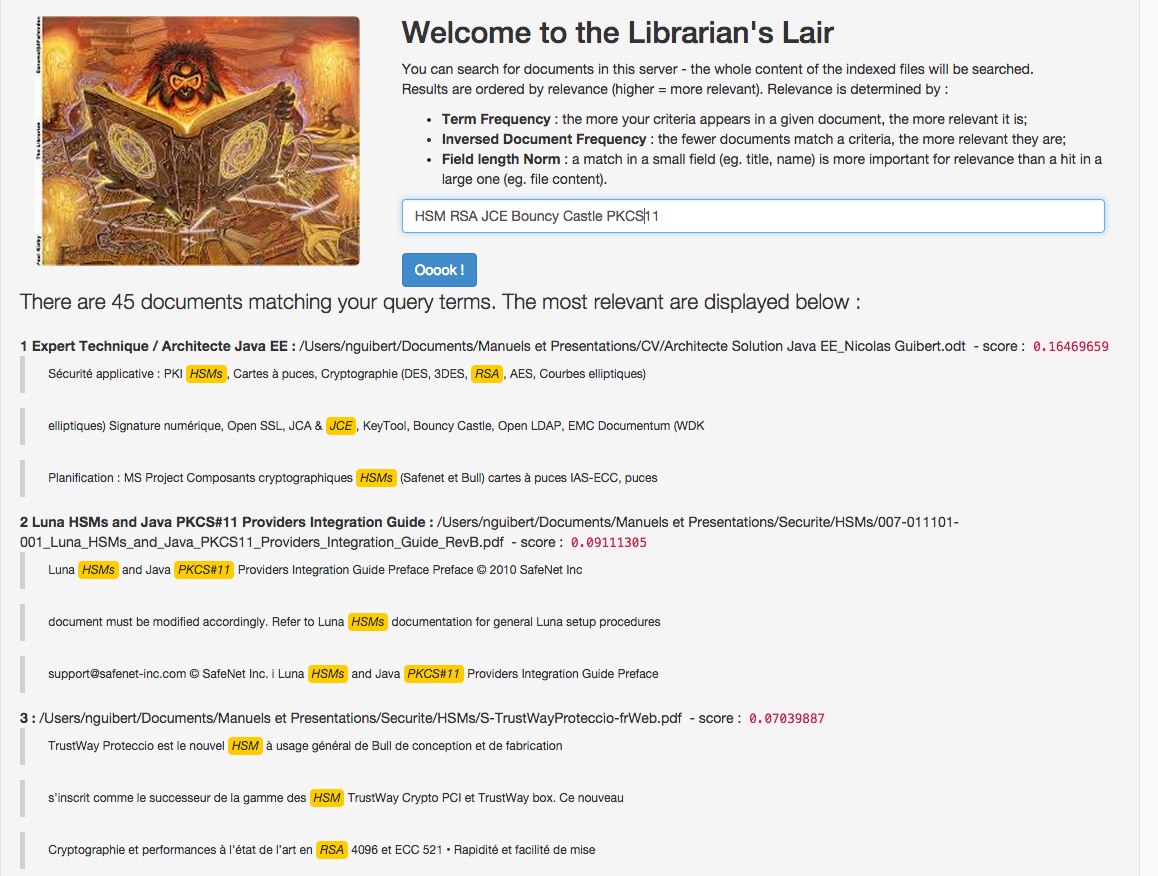
- Term Frenquency (TF) → la fréquence d’apparition des mots-clés de la recherche dans le document (les documents contenants le plus de « matches » sont priorisés)
- Inverse document frequency (IDF) → un coefficient correcteur accordant plus d’importance aux mots-clés apparaissant dans peu de documents
- Field-length norm → un autre coefficient correcteur portant sur la longueur du champ dans lequel le mot-clé est trouvé : ainsi, les matches dans le titre ou le nom du document ont un poids supérieurs aux matches dans le corps du document.
C’est ce mode de recherche que nous allons mettre en œuvre dans ce post pour retrouver l’ensemble des fichiers qui se rapportent à des mot-clés, en recherchant dans le contenu des documents.
Installation du plugin et configuration
Le type de champ « attachment », qui permet d’indexer le contenu d’un fichier, est fourni sous forme de plugin. Ce plugin expérimental est basé sur la librairie Apache Tika et permet d’indexer un grand nombre de formats de fichiers (MS Office, Open Document, ePub, PDF …) – dont la liste est disponible sur http://lucene.apache.org/tika/0.10/formats.html
L’installation d’un plugin se fait en ligne de commande avec la commande du même nom :
plugin -install elasticsearch/elasticsearch-mapper-attachments/2.4.1
Indexation de documents issus d’une arborescence de fichiers
Pour indexer des fichiers entiers en tant que champs de documents Elasticsearch, on doit préalablement définir un mapping adéquat :
curl-X PUT "localhost:9200/fs/docs/_mapping" -d '{ "docs": { "properties": { "file": { "type": "attachment", "fields": { "title": { "store" : "yes" }, "name" : { "store" : "yes" }, "file" : { "term_vector":"with_positions_offsets", "store":"yes" } } } } }}'
En l’occurrence, on indique à Elasticsearch que l’on souhaite stocker dans le base documentaire sous l’index « fs » des documents de type « docs » contenant un unique attribut nommé « file » et de type « attachment ». On précise que l’on souhaite indexer le contenu des fichiers, et les stocker en base avec le nom de fichier et le titre si celui-ci existe. Il existe d’autres méta-données disponibles, telles que « authors » par exemple.
Ensuite, l’indexation et le stockage d’un fichier se fait en appelant l’API RESTful de Elasticsearch, avec la méthode PUT ou POST et comme valeur de l’attribut « file » le contenu binaire du fichier encodé en base64. L’encodage en base64 est une opération standard, qui se fait assez facilement par un langage de script (exemple ci-dessous en Scala) :
import java.nio.file._
/** Serialisation du fichier au format json */
def jsonSerializer(fileobj : Path) :
String = { import org.apache.commons.codec.binary.Base64
val absolutepath = fileobj.toAbsolutePath().toString()
// Lecture et encodage du fichier en base 64
val b64Encoded = Base64.encodeBase64String(Files.readAllBytes(fileobj))
// Injection du contenu encodé en base 64 dans un template JSON
return "{\"file\":{\"_indexed_chars\" : -1, \"_name\" : \"" + absolutepath + "\", \"_content\" : \"" + b64Encoded + "\"}}" }
Dans la structure du document JSON ci-dessus, remarquera l’usage d’attributs prédéfinis :
- _name → le nom du fichier, qui doit être rentré explicitement à l’indexation pour pouvoir être remonté par le moteur de recherche
- _indexed_chars → le nombre maximum de caractères indexés : -1 correspondant à tout le fichier.
- _content → le contenu du fichier, encodé en base 64.
Une fois le fichier sérialisé au format JSON, on le passe en paramètre ‘data’ d’un appel POST ou PUT à l’API d’Elasticsearch, programmatiquement ou en passant par la commande curl comme ci-dessous :
curl -X POST "localhost:9200/fs/docs/" -d @b64_file.json
En réponse, Elasticsearch doit nous renvoyer un statut 201 (« créé ») et comme données une structure JSON contenant entre autres l’ID du document indexé.
Recherche dans le contenu des fichiers avec « highlight »
Une fois l’ensemble des documents indexés, il est nécessaire de paramétrer les requêtes de recherche pour qu’elles n’affichent pas le champ « _source » qui est le fichier encodé en base64 (énorme et illisible) mais un extrait du contenu des fichiers, afin de démontrer la pertinence du résultat.
Pour cela, on utilisera l’attribut « highlight », qui permet d’afficher des fragments de texte dans lesquels les termes de la recherche ont été trouvés (cela permet de voir les termes dans leur contexte). Ainsi, dans l’exemple ci-dessous :
{ "fields"
: ["name", "title"],
"query": { "query_string" : {"query" : "RSA \"PKCS#11\""} },
"highlight":
{ "fields" :
{ "file" :
{ "fragment_size" : 100,
"number_of_fragments" : 3
}
}
}
}
On souhaite afficher les champs « titre » et « nom », ainsi que des extraits du fichier (au maximum 3, dans des fragments de 100 caractères). Cette requête donne le résultat suivant :
"hits": [
{ ...
"_score": 0.16804466,
"fields":{
"file.name": ["CV Architecte Solution Java EE.odt"], "file.title":["Architecte Java EE"] },
"highlight":{
"file":[
"HSMs,Cartes à puces, Cryptographie (DES, 3DES, <em>RSA</em>, AES, Courbes elliptiques), Signature numérique,",
"Cartes à puces (Oberthur ID-ONE et Cosmo64), HSM <em>PKCS#11</em> (Safenet Luna)\n\n\tModélisation : Power AMC 12.5", "
Chiffrement Asymétrique <em>RSA</em>, Signature électronique <em>RSA</em> et ECDSA, PKCS#7, PKCS#10, <em>PKCS#11</em>,PKCS#12\n\n\n\n\n\n\n\n"
]
}
},
{ ...
"_score": 0.010856115,
"fields":{
"file.name": ["Programming Windows Azure.pdf"],
"file.title":["Programming Windows Azure"]
},
"highlight":{
"file":[
"when you create the certificate\n(typically using <em>RSA</em>).The private key portion is sensitive data, and",
"\"CN=Preconfigured Cert\"\n-ss My -len 2048\n-sp \"Microsoft Enhanced <em>RSA</em> and AES Cryptographic Provider\" -sy 24\npreconfig",
"containing a 2,048-bit\nkey pair, signed using the <em>RSA</em> algorithm, and outputs the public portion of the"
] } },
{ ...
"_score": 0.0075854138,
"fields":{
"file.name":["owasp_ippon_technologies_2014.pdf"] }, "highlight":{
"file":[
"For key wrapping, <em>RSA</em> with OAEP padding is preferable because the other choice,<em>RSA</em> 1.5 is known to have",
"have \nvulnerabilities. <em>RSA</em> keys of at least 2048 bits is recommended.\n\ntip\n\nimportAnt\n\n(for Java applications)",
"applications)\nTo use AES 256 or <em>RSA</em> 2048bits keys, you will need to upgrade your JRE with JCE unlimited strength" ] } }
On constate qu’aucun des documents remontés ne contient les mots clés dans le nom du fichier, ni dans la meta-donnée « titre ». Les hits sont encadrés par des tags (le choix du tag est paramétrable), ce qui permet de faciliter l’affichage des highlights en html.
Intéressons nous à l’ordre de ces documents : la présence du terme “PKCS#11” explique que le fichier “CV Architecte Solution Java EE.odt” apparaisse en premier dans le classement – ce terme ne se trouvait dans aucun autre document, et s’est donc vu affecté un fort coefficient de pertinence, conformément au critère de pertinence n°2 “Inverse document frequency (IDF)”. C’est de plus le fichier le plus court, aussi le critère n°3, “Field-length norm” a également joué positivement. Le second fichier par ordre de pertinence est “Programming Windows Azure.pdf” . Bien qu’étant le fichier le plus long, c’est celui qui comprend le plus d’occurrences du terme “RSA” ce qui lui vaut d’être évalué comme plus pertinent que le 3° fichier, en raison du critère n°1 “Term Frenquency (TF)”.
Conclusion
L’indexation du contenu entier de fichiers de type divers par Elasticsearch est une fonctionnalité facile d’emploi qui ouvre de nombreuses possibilités pour mettre en place une base documentaire avec un moteur de recherche à partir de documents existants, qu’il s’agisse de manuels, spécifications, retours d’expérience, compte rendus d’assistance, tickets de support utilisateur etc.
Il est possible de se mettre à l’écoute des modifications d’une arborescence de fichiers – pour mettre à jour automatiquement le cluster – en installant et configurant la FileSystem River (http://www.pilato.fr/fsriver/). L’API RESTful de Elasticsearch facilite par ailleurs la mise en place d’une IHM web de recherche facilement accessible :
Le code complet des extraits présentés dans ce post est disponible sur GitHub :