
Lors de la conférence MongoDB internals de BDX.IO, Tugdual Grall nous a présenté en détail les mécanismes d’écriture et de réplication de MongoDB.
Les “Replica set”
Un replica set est un groupe d’instances mongod qui contiennent les mêmes données. Une instance mongod est déclarée comme étant le noeud primaire et va recevoir toutes les lectures et écritures. Cela permet à MongoDB d’être consistent à tout instant (à tout moment on est certain que ce qu’on lit est vraiment la dernière version des données).
Voici un exemple de replica set avec 3 noeuds. Un primaire et deux secondaires. 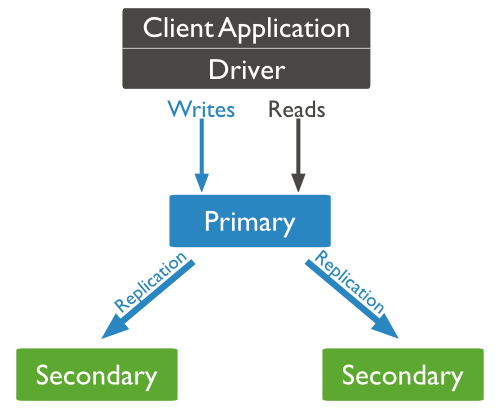 La réplication entre le primaire et les secondaires est transparente. Elle est gérée par MongoDB avec un système de “Heartbeat” entre les noeuds, toutes les 2 secondes.
La réplication entre le primaire et les secondaires est transparente. Elle est gérée par MongoDB avec un système de “Heartbeat” entre les noeuds, toutes les 2 secondes.
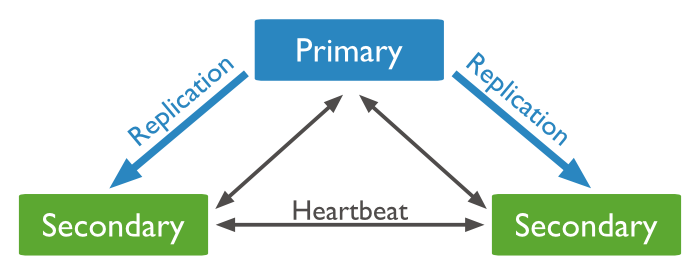
Un Replicat Set peut être composé de 2 à 12 noeuds. Cela permet de faire de la haute disponibilité (HA), de la reprise sur erreur (Disaster Recovery) ou tout simplement de la maintenance de serveurs. En effet, nos données seront tout le temps accessibles. On peut éteindre un serveur, faire une maintenance, une mise à jour de version, etc…, cela sera transparent pour l’application.
Si on perd un noeud secondaire, ce n’est pas grave. Il recopiera depuis le noeud primaire les données qu’il n’a pas eu pendant son downtime dès qu’il sera remis en route.
Si on perd le primaire, il y aura une élection du nouveau primaire au prochain heartbeat qui part en timeout (10 secondes). L’élection a différents critères, comme la priorité qu’on a attribué à chaque noeud (priority) ou qui possède la dernière version des données. Attention car une élection nécessite une majorité dans les votes (un vote par noeud). Si on perd trop de noeud on peut arriver dans une situation où on ne peut pas avoir de majorité et aucun noeud primaire ne peut être élu. On peut alors ajouter des noeuds appelés arbitre, qui n’interviennent que dans le processus d’élection. Ils ne contiennent pas les données.
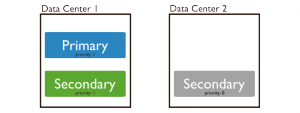
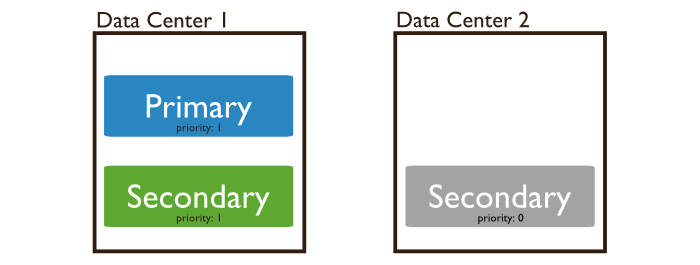
Un noeud avec une priority à 0 ne peut pas devenir primaire. Cela peut se révéler utile pour séparer les noeuds entre data center, mais vouloir garder le noeud primaire tout le temps sur le data center principal.
 Le “Sharding”
Le “Sharding”
Le Sharding permet de faire de la scalabilité horizontale. Pour de très gros volumes de données, au lieu d’augmenter le CPU/RAM/disk d’une machine (scalabilité verticale), on ajoute d’autres serveurs.
Avec MongoDB, pas la peine de faire du sharding à moins de 200Go de données. Pour ces volumes, un Replica Set suffit largement.
Pour faire du sharding, il faut lancer des instances mongos sur chaque machine contenant l’application. Ces process se chargent de router les requêtes. Ces routages se font à partir des metadatas contenues dans les Config Server, qui doivent être au nombre de 3, chacun sur son propre serveur.
Chaque shard est ensuite un Replica Set, avec ses noeuds primaire et secondaires.
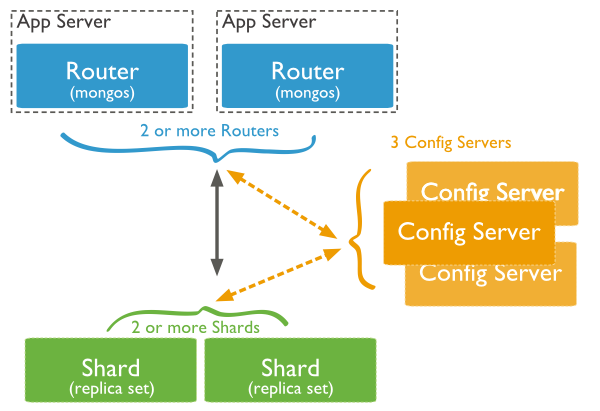
Mongo distribue les données d’une collection entre les shards selon une “shard key”. Cette clé peut être un index de la collection par exemple, mais doit être présente dans chaque document de la collection. Mongo va diviser cette clé en morceaux et distribuer ces morceaux entre les shards. Cette division en morceaux peut se faire selon 3 manières :
-
range based : si l’index est un nombre par exemple, allant de 1 à 1 000 000, Mongo va répartir les documents de 1 à 250 000 dans le shard 1, de 250 001 à 500 000 dans le shard 2, etc…
-
hash based : un hash est appliqué à l’index et Mongo répartit les données entre les shards. Cela permet d’assurer que 2 documents dont l’index se suivent ne se retrouvent pas dans le même shard.
-
tag aware : un administrateur peut décider de la répartition entre les shards en associant des tags aux segments d’index et en associant les tags aux différents shards. Par exemple pour répartir les données selon leur langue ou leur localisation.
Si un shard contient trop de données par rapport aux autres shard, Mongo peut faire de la répartition automatique pour garder des proportions équivalentes dans chaque shard.
Oplog
Les “operations log” est une collection Mongo spéciale qui contient les enregistrements tournants des données modifiées. A chaque modification d’une donnée (insertion, modification, suppression), une log est ajoutée avec un identifiant incrémenté. Chaque noeud secondaire demande ensuite au noeud primaire, lors de chaque heartbeat, tous les nouveaux items de son oplog qui ont un id supérieur au dernier oplog du secondaire.
L’oplog a une taille fixe (configurable avec la propriété oplogSizeMb). Quand l’oplog arrive au bout de sa taille, il recommence à écrire au début. Donc si un noeud est down trop longtemps, l’oplog du primaire n’est plus consistent, et le noeud doit donc recopier toutes les données du primaire. Il faut donc configurer la taille de l’oplog pour que l’activité de l’application ne le remplisse pas plus vite qu’un temps moyen d’arrêt d’un noeud (maintenance, temps pour redémarrer un noeud tombé).
Write concern
Le write concern est la façon dont Mongo va écrire sur les noeuds du Replica Set :
- w=0 : on ne sait pas si l’écriture s’est bien passée ou pas. On n’a pas de retour.
- w=1 : par défaut : sauve sur le noeud primaire et rend la main immédiatement : la réplication sur le noeuds secondaires est asynchrone
- w=majority : attend d’avoir écrit sur la majorité des noeuds
- w=2 à 12 : attend d’avoir écrit sur N noeuds
- w=all : attend d’avoir écrit sur tous les noeuds du Replica Set.
Dès que w > 1, si Mongo n’a pas réussi à écrire sur le nombre de noeuds spécifié (car l’un est down par exemple), Mongo attendra indéfiniment d’avoir écrit sur le bon nombre de noeuds. Attention donc à ce paramétrage.
On peut y ajouter la propriété de journalisation (j=true). Mongo va alors attendre de journaliser les données avant de nous retourner sa réponse.

On peut aussi spécifier un timeout avec la propriété wtimeout. Si les écritures mettent plus de temps que ce timeout (par exemple si on veut écrire sur 4 noeuds mais que seulement 3 sont up), Mongo nous rend la main. Cela évite d’attendre indéfiniment, pratique 🙂
Exemple avec 3 noeuds et un writeConcern=2 :
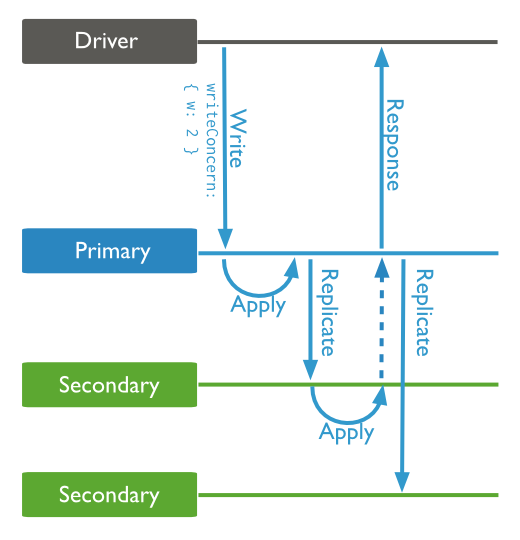
Il est recommandé de lister au moins 2 serveurs (primaire et secondaire) dans la configuration de votre connexion de votre application.
Si un secondaire tombe, cela sera transparent pour le code. Au redémarrage du noeud, il récupérera les données manquantes du primaire.
Si le primaire tombe, on ne peut plus insérer, et le code doit le gérer :
- attend et ré-essaie : après l’élection du nouveau primaire, l’insertion passera
- pas grave et on décide de continuer
- …
Conclusion
Voilà donc encore une belle présentation de MongoDB par Tug. BDX.IO a eu lieu pour la première fois le 17 Octobre à Bordeaux, avec 300 participants et une quarantaine de speakers. Rendez-vous l’année prochaine pour une conférence encore plus grande on l’espère, et à très vite sur ce blog pour d’autres retours sur le BDX.IO.
