
Introduction
Nous utilisons le service EC2 d’AWS presque tous les jours, et la facture peut vite grimper si nous n’y faisons pas attention.
Dans cet article, nous vous proposons de comprendre ce qui se cache derrière les instances T d’AWS, les différents modes de configuration des crédits possibles, et dans quels cas il est avantageux de préférer des instances T.
Nous ne détaillerons pas l’utilisation d’instances réservées ou d’instances spot, mais ce que nous allons voir concernant les instances T est valable quelle que soit l’option d’achat d’instance choisie.
Les instances de performance à capacité extensible
Grâce à l’analyse des charges de travail de leurs nombreux clients et sur plusieurs années, AWS s’est rendu compte que la majorité des charges de travail ne nécessite pas une utilisation soutenue du CPU.
Autrement dit, les charges de travail consomment en moyenne très peu par rapport à la capacité en CPU des instances, et consomment la plupart du temps sur de courts intervalles de temps, aussi appelés bursts, comme nous pouvons le voir sur le graphique d’AWS suivant :
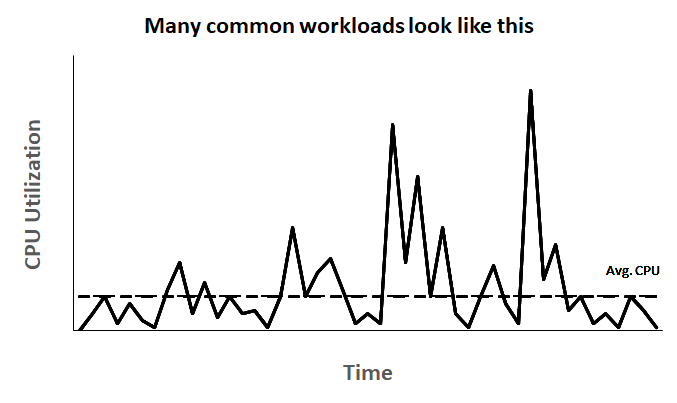
La majorité des charges de travail entraîne donc un gaspillage des cycles CPU, et donc un gaspillage financier. C’est pour cette raison que AWS a introduit les instances de performance à capacité extensible: la famille T.
D’après la définition d’AWS : “La famille d'instances T offre les performances d'une UC de base avec la possibilité d'aller au-delà à tout moment et aussi longtemps que nécessaire”, l’utilisation CPU de base étant définie pour répondre aux besoins de la majorité des charges de travail.
UC est l’abréviation d’Unité Centrale de calcul, ou en anglais Central Processing Unit (CPU)
Cette famille d’instances peut vous faire économiser jusqu’à 15 % de coûts par rapport à des instances M, toujours selon AWS, moyennant quelques contraintes que nous détaillons ci-dessous.
Concepts clés
Avant de voir les différents modes de configuration des crédits disponibles pour ces instances T, il est nécessaire d’en comprendre les concepts principaux.
Ce qu’il faut retenir, c’est que la famille d’instances T est la seule à utiliser un système de crédits pour l’utilisation du CPU. Mais qu’est-ce que cela signifie ? Et comment cela fonctionne-t-il ?
Pour chaque type d’instance de la famille T, AWS définit une utilisation ou ligne de référence, aussi appelée baseline, allant de 5 % à 40 % d’utilisation du CPU en fonction du type d’instance.
Reprenons le schéma d’AWS pour bien comprendre :
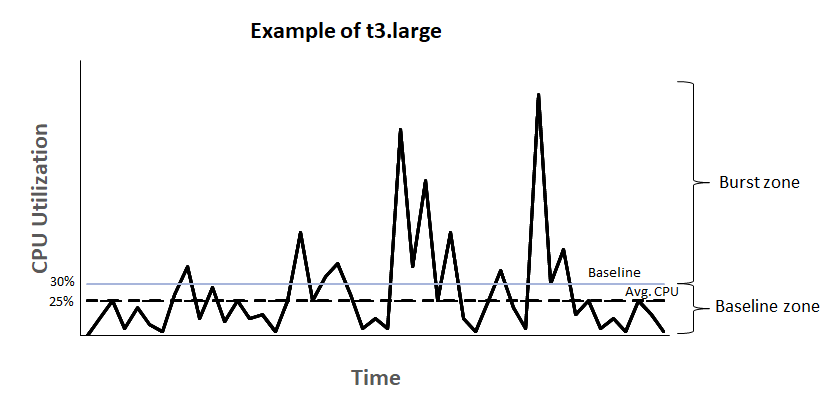
Le principe est le suivant : chaque instance de cette famille va gagner des crédits quand son utilisation CPU reste en dessous de la ligne de référence, soit 30 % pour une t3.large, et dépenser des crédits quand son utilisation dépasse cette ligne. C’est grâce à ce fonctionnement et aux crédits “gagnés” que ces instances peuvent burst lorsque nécessaire, tout en consommant peu en moyenne.
Détaillons à présent les calculs et les formules pour mieux comprendre comment ces instances gagnent et dépensent des crédits.
Un crédit d’UC ou unité de temps de vCPU est régie par la loi suivante :
1 crédit d’UC = 1 vCPU * 100 % d’utilisation * 1 minute
= 1 vCPU * 50 % d’utilisation * 2 minutes
= 2 vCPU * 25 % d’utilisation * 2 minutes
Autrement dit, consommer un crédit revient à consommer 100 % d’un vCPU pendant une minute. Si nous généralisons, nous obtenons la formule suivante :
Crédits d'UC dépensés par heure = % d’utilisation de l'UC * nombre de vCPU * 60 minutes
Maintenant, pour calculer le nombre de crédits gagnés par heure, il faut utiliser une autre formule magique :
Nombre de crédits gagnés par heure = % d’utilisation de référence * nombre de vCPU * 60 minutes
Ce qui donne pour une t3.large possédant 2 vCPU et une ligne de référence à 30 % :
Nombre de crédits gagnés par heure = 0,3 * 2 * 60 = 36
Vous commencez à comprendre, toutes ces formules et cette mécanique autour des crédits permet à AWS de définir une ligne de référence par type d’instance à partir de laquelle consommer plus de vCPU revient à dépenser plus de crédits que ce que l’instance en gagne.
Si nous reprenons notre exemple avec une instance de type t3.large ayant une ligne de référence de 30%: si nous consommons 30 % de la capacité totale de vCPU pendant une heure, alors nous sommes à l’équilibre puisque nous gagnons 36 crédits par heure que nous dépensons.
En revanche, si nous ne consommons que 15 % de la capacité totale de vCPU pendant une heure, cela revient à dépenser 0,15 * 2 * 60 = 18 crédits. Comme nous en gagnons 36 par heure avec ce type d’instance, cela nous donne une différence positive de 18 crédits. Qu’en est-il de ces crédits restants ? Sont-ils perdus ?
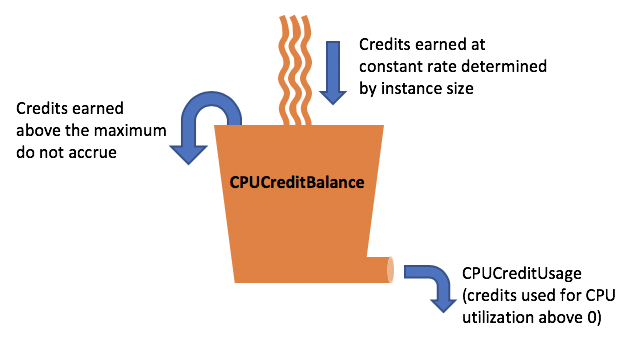
Il est temps d’aborder le sujet des crédits accumulés. En effet, dans l’exemple ci-dessus, les 18 crédits restants sont accumulés et mis de côté, afin de pouvoir être dépensés plus tard si besoin. C’est ce qui permet à une instance de burst, c'est-à-dire consommer plus que sa ligne de référence pendant un certain laps de temps. Dans ce cas, l’instance dépense plus de crédits que ce qu’elle en gagne, et la différence est prélevée dans les crédits accumulés.
Cependant, il est important de noter que cette accumulation de crédits n’est pas illimitée. Cette limite dépend de la taille de l’instance, mais de manière générale elle est égale au nombre maximal de crédits gagnés en 24 heures.
Si nous reprenons une nouvelle fois l’exemple de notre t3.large, cela nous donne 36 * 24 = 864 crédits accumulés maximum.
Le schéma d’AWS suivant résume bien cette notion de crédits accumulés :
Maintenant que vous commencez à mieux comprendre le fonctionnement des instances de type T, vous vous posez sans doute la question suivante : que se passe-t-il si mon instance dépense plus de crédits que ce qu’elle en gagne (ie mon instance consomme plus de vCPU que la ligne de référence), et que la réserve de crédits accumulés est vide ?
C’est là qu’interviennent les modes de configuration des crédits : illimité (le cas par défaut) et standard.
Le mode de configuration des crédits illimité (mode par défaut)
Dans ce mode illimité, une instance T peut dépenser des crédits excédentaires si elle consomme plus que la ligne de référence et qu’elle ne possède plus de crédits accumulés en stock.
Si l’utilisation moyenne du CPU de cette instance diminue en-dessous de la ligne de référence, les crédits accumulés sont utilisés pour rembourser les crédits excédentaires dépensés plus tôt.
En revanche, si l’utilisation moyenne du CPU dépasse la ligne de référence pendant une période de 24 heures, l’utilisation supplémentaire est facturée selon un tarif supplémentaire fixe par heure de vCPU.
Le schéma d’AWS suivant permet de se rendre compte de l’ordre de grandeur de cette facturation additionnelle :
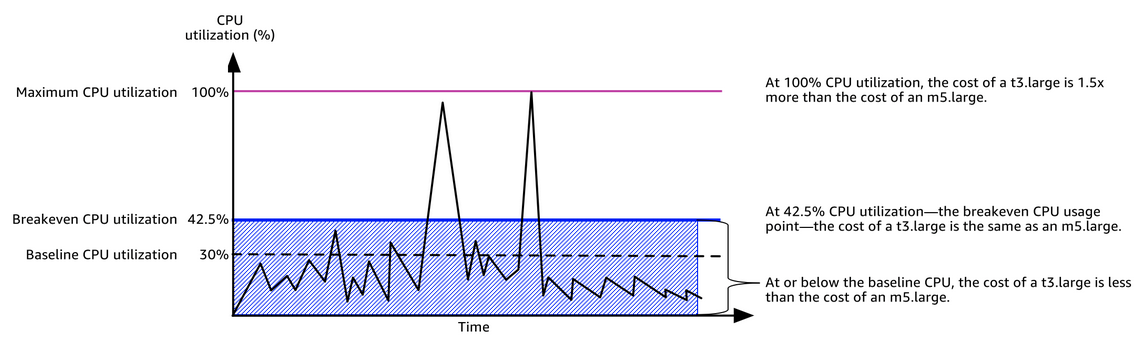
Si la facturation additionnelle vous fait peur, il existe un deuxième mode de configuration des crédits : le mode standard.
Le mode de configuration des crédits standard
Dans ce mode standard, il n’y a pas de crédits excédentaires.
Lorsque l’instance consomme plus que la ligne de référence et qu’elle ne possède plus de crédits cumulés, son utilisation CPU diminue progressivement pour atteindre le niveau de référence. Les processus sont en quelque sorte ralentis afin de ne pas consommer plus que la ligne de référence.
Bien que ce mode soit rassurant d’un point de vue facturation (pas de facturation supplémentaire possible), il faut faire très attention en l’utilisant, car cela peut impacter vos charges de travail et de fait vos utilisateurs.
Cas d’utilisation : quand est-il pertinent de choisir le type d’instance T ?
Maintenant que nous avons vu la théorie, nous allons voir dans quel cas il est pertinent de choisir le type d’instance T, l’idée étant de vous présenter une démarche reproductible afin que vous puissiez l’adapter à votre contexte.
Comparons donc des instances similaires : une t4g.large en mode crédits illimités et une m7g.large.
Consommation constante
Voici un tableau récapitulatif du prix de ces instances en fonction de l’utilisation CPU au moment où nous écrivons ces lignes, et pour la région eu-west-3 :
| Instance / Pourcentage d’utilisation CPU | % <= baseline (ici 30 %) | 55 % (équivalence) | 100 % |
|---|---|---|---|
| m7g.large | 2,2848 $ / jour | 2,2848 $ / jour | 2,2848 $ / jour |
| t4g.large | 1,8048 $ / jour | 2,2848 $ / jour | 3,1488 $ / jour |
Détaillons à présent les calculs.
Le prix d’une instance de type m7g.large est stable et vaut 2,2848 $ pour 24h d’utilisation, quel que soit la consommation de CPU.
Le prix d’une instance de type t4g.large pour une consommation de CPU au niveau de sa baseline (30 %) ou en dessous vaut 1,8048 $ pour 24h d’utilisation.
Comme nous l’avons vu précédemment, AWS applique un tarif supplémentaire aux crédits excédentaires, qui est actuellement de 0,04 $ par heure de vCPU pour les instances t4g, ce qui nous donne le prix d’un crédit excédentaire, à savoir 0,04 / 60 $ (pour rappel : 1 crédit d’UC = 1 vCPU * 100 % d’utilisation * 1 minute).
Nous pouvons donc calculer le prix d’une instance de type t4g.large pour une consommation de CPU de 100 %. Sachant qu’elle possède 2 vCPU, nous obtenons :
Crédits d'UC dépensés par heure = % d’utilisation de l'UC * nombre de vCPU * 60 minutes
= 100 % * 2 * 60
= 120
Une t4g.large consomme donc 120 * 24 = 2880 crédits en 24h lors d’une consommation de CPU de 100%. Or, nous savons qu’elle gagne 36 crédits par heure, soit 864 crédits en 24h. Nous avons donc un excédent de 2880 - 864 = 2016 crédits en 24h, soit 2016 * 0,04 / 60 = 1,344 $.
Le prix d’une instance de type t4g.large pour une consommation de CPU de 100 % est donc de 1,8048 + 1,344 = 3,1488 $ pour 24h d’utilisation, soit 1,38 fois le prix d’une m7g.large.
Un autre cas intéressant à analyser est le pourcentage d’utilisation de CPU à l’équivalence, c’est-à-dire lorsque le prix d’une instance t4g.large est égal au prix d’une instance m7g.large. Cela peut se faire assez simplement en calculant la différence entre le prix d’une instance m7g.large et d’une t4g.large à la baseline (sans consommation excédentaire), pour ainsi obtenir le nombre de crédits supplémentaires qu’il faudrait pour atteindre ce prix d’équivalence. Nous obtenons donc (2,2848 - 1,8048) * 60 / 0,04 = 720 crédits.
Transformons ces crédits en consommation effective de CPU. Pour rappel, 1 crédit d’UC = 1 vCPU * 100% d’utilisation * 1 minute, ce qui nous donne :
% d’utilisation = nombre de crédits d’UC / (nombre de vCPU * nombre de minutes)
= 720 / (2 * 24 * 60)
= 0,25
Les 720 crédits de différence correspondent donc à 25 % d’utilisation de CPU. Sachant que la baseline d’une instance t4g.large est de 30 %, nous obtenons une équivalence à 30 + 25 = 55 % d’utilisation de CPU. Cela signifie qu’il devient plus intéressant d’utiliser une instance m7g.large lorsque la charge de travail consomme en moyenne plus de 55 % du CPU disponible (dans cet exemple 2 vCPU).
Nous avons donc une idée un peu plus précise de quand il est intéressant de privilégier une instance m7g.large par rapport à une t4g.large. La démarche peut bien évidemment s’appliquer à tous les types d’instances. Mais qu’en est-il si nous prenons un exemple de consommation de CPU non constante, et de fait, un peu plus réaliste ?
Consommation variable
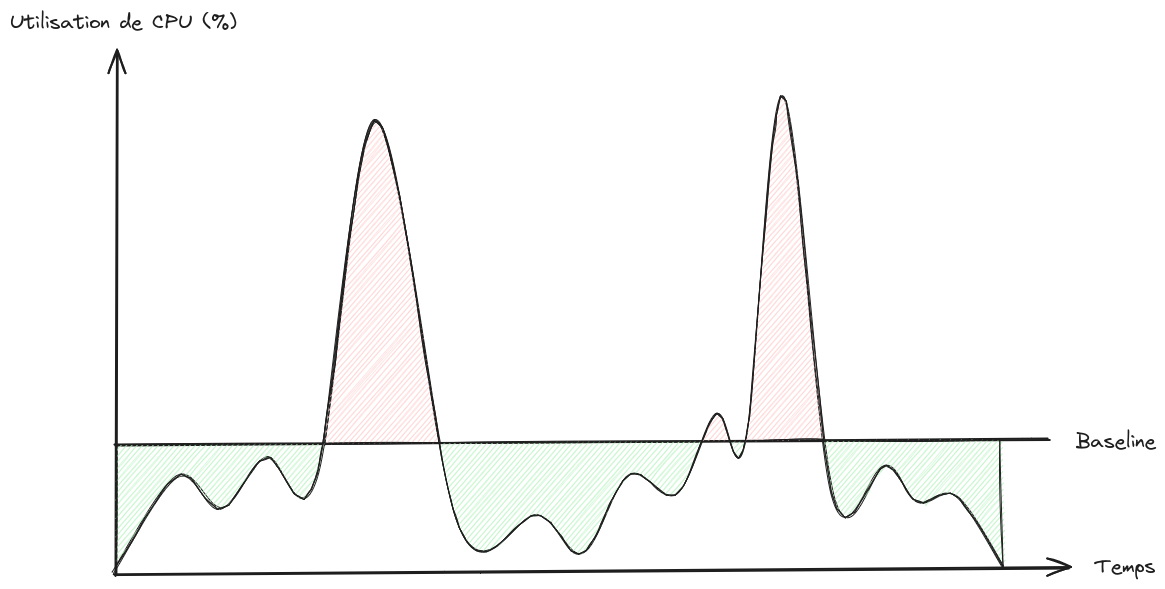
Prenons l’exemple d’une charge de travail non constante :
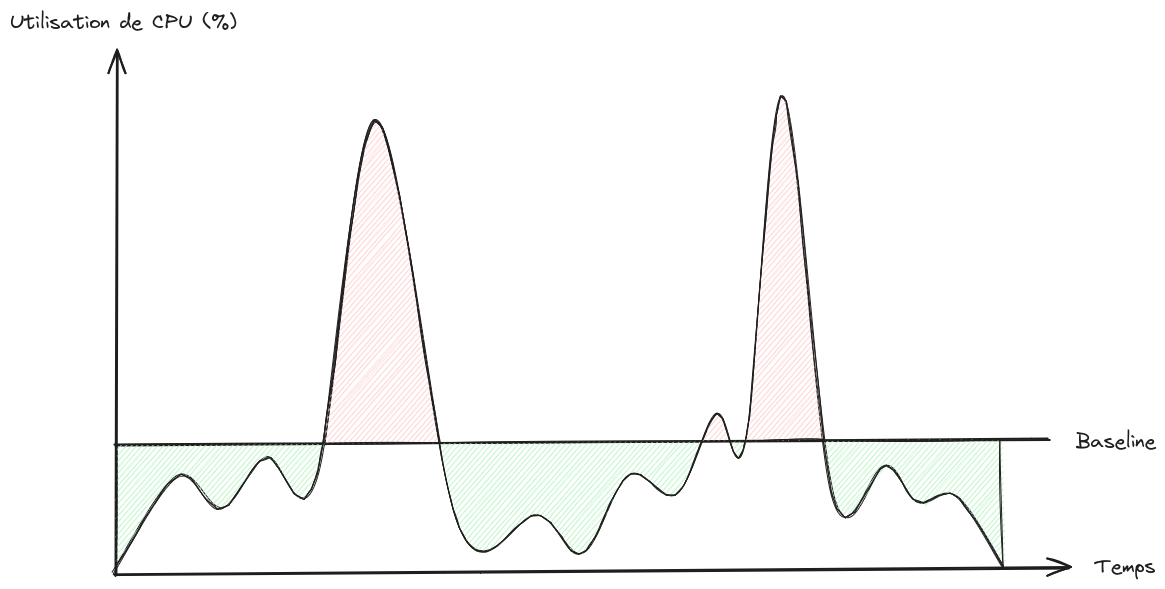
Ici encore, l’idée est de se concentrer sur la démarche plus que les chiffres.
Dans le cas d’une telle charge, comment calculer le coût d’une instance T, notamment lorsque la consommation de CPU moyenne dépasse la baseline ?
Les plus matheux d’entre vous auront très vite remarqué qu’il s’agit ici d’un calcul d’aire entre la courbe de consommation réelle et la ligne de référence de l’instance. En effet, et comme nous l’avons vu jusqu’à présent, dans le cas où la consommation est en-dessous de la ligne de référence, l’instance gagne plus de crédits que ce qu’elle en consomme, et met l'excédent de côté. À l’inverse, lorsque la consommation est au-dessus de la ligne de référence, l’instance consomme plus de crédits que ce qu’elle en gagne, et consomme donc les crédits mis de côté tant qu’il en reste.
Il suffit donc de calculer la somme des aires représentées en rouge sur le schéma ci-dessus, et de soustraire à ce résultat la somme des aires représentées en vert. Si le résultat est inférieur ou égal à 0, nous sommes dans le cas d’une consommation moyenne de CPU inférieure ou égale à la ligne de référence, et nous ne payons donc pas de crédits supplémentaires. En revanche, si le résultat est strictement supérieur à 0, nous payons des crédits supplémentaires.
Pour calculer le coût de ces crédits supplémentaires, nous pouvons diviser le résultat du calcul des aires par une durée, par exemple 24h, et ainsi retrouver le pourcentage d’utilisation de CPU supplémentaire à la ligne de référence sur cette durée.
Ainsi, si nous obtenons 25 % de consommation supplémentaire pour une durée de 24h, nous pouvons le convertir en nombre de crédits (ici nous gardons l’exemple d’une t4g.large) :
nombre de crédits d’UC = nombre de vCPU * % d’utilisation * nombre de minutes
= 2 * 0,25 * 24 * 60
= 720
Dans le cas d’une t4g.large, 25 % d’utilisation de CPU équivaut à 720 crédits, soit 720 * 0,04 / 60 = 0,48$ de supplément.
Exemples de cas d’usages
Vous l’aurez compris, les instances T ne sont pas faites pour des charges de travail nécessitant une consommation soutenue de CPU sur la durée, mais plutôt pour des applications qui auraient besoin d’une forte consommation sur des intervalles de temps courts, aussi appelés bursts, sans dépasser la consommation de référence le reste du temps. Les applications ayant une forte consommation de CPU la journée mais peu la nuit bénéficient également des avantages offerts par ce type d’instance, les crédits pouvant être stockés et permettant de rembourser des “dettes” passées dans un intervalle de 24h maximum.
À l’inverse, un bon exemple de charges de travail où il n’est pas recommandé d’utiliser des instances T est l’utilisation d’instances pour des worker nodes Kubernetes. En effet, dans un tel contexte, nous allons essayer de faire tourner un maximum de pods par nœud afin d’éviter une sous-utilisation de ces derniers, ce qui implique une forte probabilité de consommer plus que la ligne de référence et donc de devoir payer des crédits excédentaires.
Un autre exemple de cas d’usage non adapté à ce type d'instance est l’utilisation de runners GitLab ou toute autre tâche d’automatisation qui consommerait beaucoup de CPU avant de résilier l’instance. Dans ce cas, l’instance n’aurait pas le temps d’accumuler assez de crédits afin de compenser les crédits excédentaires consommés plus tôt.
Conclusion
Dans cet article, nous avons souhaité aborder un sujet méconnu mais pourtant important d’un point de vue FinOps. Nous avons vu comment AWS nous permet de faire des économies grâce aux instances T, mais nous avons aussi et surtout vu dans quels cas il n’était pas intéressant de les utiliser, au risque de payer plus cher que des instances équivalentes telles que les instances M.
Heureusement, et pour simplifier la gestion de ce type d’instances, Cloudwatch permet de surveiller cette consommation de crédits CPU, notamment au travers de quatres métriques : CPUCreditUsage, CPUCreditBalance, CPUSurplusCreditBalance et CPUSurplusCreditsCharged, cette dernière étant directement liée aux potentiels frais supplémentaires.
Sources
- https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/burstable-performance-instances.html
- https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/burstable-credits-baseline-concepts.html
- https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/burstable-performance-instances-unlimited-mode-concepts.html
- https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/burstable-performance-instances-monitoring-cpu-credits.html

