
Le but de cet article est de montrer qu’il est possible de prédire le cours d’une action sur un horizon de temps allant jusqu’à deux minutes grâce aux réseaux de neurones. Deux articles récents, publiés en 2020 et 2021, montrent des résultats très intéressants quant à la prédiction des cours des actions à l’aide des carnets d’ordres. La majorité de l’article se concentre sur le premier papier (Zhang et al. 2020) qui utilise un réseau de neurones LSTM sans mécanisme d’attention (DeepLOB). Dans cet article, nous allons, dans un premier temps, rappeler quelques notions sur les réseaux de neurones et le mécanisme d'attention. Puis nous verrons que le réseau qui utilise ces fameux mécanismes donne de meilleures performances.
Qu’est-ce qu’un carnet d’ordre ?
Que se cache-t-il derrière le prix que nous voyons affiché ? Prenons l'exemple d'Apple : l'action coûte aujourd'hui 100 dollars. En fait, 100 dollars signifie que la meilleure offre de vente est à 100 dollars. En effet, certaines personnes souhaitent vendre cette action par exemple à 101 dollars. Toutes ces offres sont répertoriées dans un carnet d'ordre. Toutes les demandes - c'est-à-dire les propositions d’achat - sont également répertoriées dans le carnet.
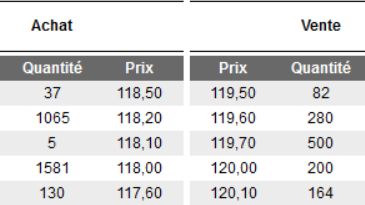
Dans le carnet ci-dessus, nous voyons qu'il y a 37 actions proposées à 118,50 dollars. Si quelqu'un souhaite proposer l'action à 118,70, alors il passera devant tous ceux qui la proposent à 118,50 dollars. Le meilleur prix d’achat affiché s’appelle le bid et le meilleur prix de vente s’appelle l’ask.
La question que nous pouvons nous poser maintenant est : en ayant connaissance de l'historique de ce carnet, pouvons-nous prédire la direction haussière, baissière ou neutre du cours ?
Rappels sur les réseaux de neurones récurrents
Lorsque nous traduisons une phrase dans une autre langue, il ne suffit pas de faire une traduction mot à mot. En effet, il est essentiel que le contexte soit pris en compte.
Les réseaux de neurones récurrents sont une première solution pour une telle traduction car ils permettent la prise en compte des premiers mots de la phrase et donc, d'une partie du contexte. Le schéma ci-dessous illustre ce mécanisme : pour prédire le reste des mots de la phrase, nous utilisons des premiers mots.
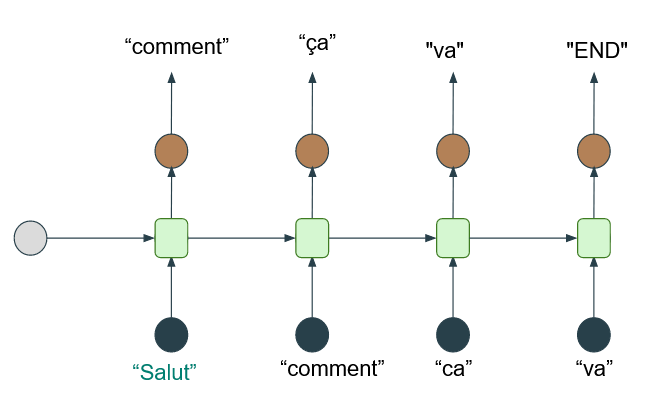
Sur le schéma, les cercles noirs et marrons correspondent à une représentation des mots en vecteur, appelée l'embedding du mot.
La limite de cette architecture est que, si nous l'utilisons pour traduire une phrase, alors nous n'avons pas connaissance de l'ensemble de celle-ci et donc, de son contexte général. Pour pallier ce problème, une des alternatives serait de d'abord lire la phrase entière, puis de la traduire - tout comme le ferait un traducteur humain. Voyons maintenant l'architecture Encoder-Decoder.
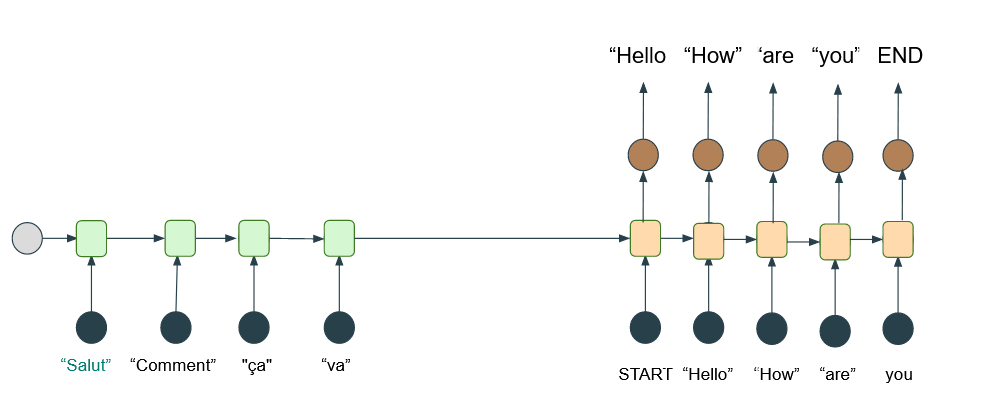
Les cellules vertes du schéma ci-dessus capturent de l’information au fur et à mesure que la phrase est lue. Ces cellules sont appelées des cellules LSTM. Vous remarquerez que la seconde cellule verte ne récupère pas seulement l'embedding du mot « Comment » mais prend aussi en compte l'information de la cellule précédente. À la fin, la dernière cellule envoie un vecteur de « contexte » à la première cellule beige pour commencer la traduction de la phrase.
Cependant, pour traduire le premier mot, il serait préférable de se concentrer sur le début de la phrase plutôt que sur la fin. Le fait d'avoir une représentation de l'entièreté de la phrase est moins efficace que d'avoir une représentation de cette même phrase mais avec une pondération plus forte pour les premiers mots. Nous en arrivons au mécanisme d'attention.
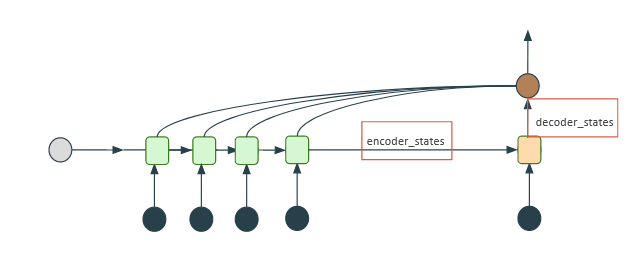
L'idée est de brancher des connexions sur chaque cellule verte - contrairement à ce qui était montré plus haut, où il n'y avait qu'une connexion sur la dernière cellule. Durant la phase d'entraînement, le réseau va ainsi comprendre de lui-même qu’il faut attribuer un poids plus important aux premières cellules vertes lorsqu'il s'agit de traduire le premier mot.
Pour les curieux, voici la formule précise représentant ce mécanisme. Nous aurons l'occasion d'aborder, dans un prochain article, les mécanismes d’attention plus en détail.
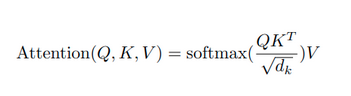
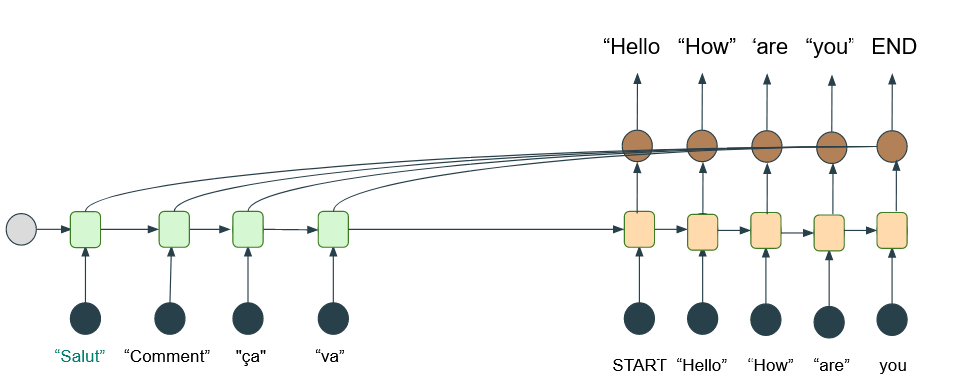
Et voici à quoi ressemble le branchement final, sur notre exemple précédent :
Nos datasets
Nous avons, dans l'article, deux jeux de données. Ceux-ci servent à entraîner notre modèle pour prédire le cours boursier. Le premier, FI-2010, est un jeu de données de référence pour que les algorithmes créés par la communauté puissent se comparer les uns aux autres en termes de performance. Il représente le carnet d'ordre de cinq actions du Nasdaq sur dix jours de cotation. Le second jeu de données est le LSE qui représente une année du carnet d'ordre de la bourse londonienne.
Nous allons tester notre modèle sur ce premier jeu de données. Bien entendu, il est évident que sa taille est insuffisante : lorsque nous utilisons du deep learning, une très grande quantité de données est requise pour entraîner nos modèles. C’est pourquoi nous utiliserons, dans un second temps, une année entière de cotation pour l'entraînement du modèle sur ces cinq actions du Nasdaq. Du transfert learning sera ensuite utilisé pour évaluer le modèle sur cinq nouvelles actions. En revanche, nous ne pourrons pas comparer les résultats avec d’autres algorithmes puisqu’il ne s’agit pas du jeu de données de référence mentionné ci-dessus.
Données d’entrées & Labellisation
Dans cette partie, nous allons créer nos données qui serviront à entraîner notre réseau de neurones. Il nous faut donc un jeu de données d'entrée ainsi que des labels associés.
Définition : On appelle « profondeur » du carnet d’ordre le nombre de lignes du carnet.
Nous allons prendre comme données d'entrée les cent derniers états du carnet d'ordre. Tout changement d'information du carnet entraîne un nouvel état. Pour chaque état, nous nous limiterons à une profondeur de 10 car plus l’on va en profondeur dans le carnet, moins l’information est importante. Enfin, pour chaque ligne du carnet, nous nous intéresserons aux quatre données suivantes : le bid, l’ask, la quantité au bid et la quantité à l'ask (la quantité s’appelle aussi le volume). Notre vecteur d'entrée sera donc de taille 100x10x4. Le label que nous allons associer correspondra donc au fait que le marché a monté, baissé ou stagné.
Pour construire cela, nous allons regarder les k états suivants du carnet et faire la moyenne des prix (on regarde cette fois uniquement la moyenne bid-ask avec une profondeur de 1), puis nous comparons cette valeur au prix actuel du marché (cela nous donne un rendement, par exemple 0.01% de hausse sur les k périodes qui ont suivi).
Architecture du réseau de neurones (sans mécanisme d’attention)
Dans la partie précédente, nous avons vu que, pour chacun de nos 100 derniers états du carnet d'ordre, nous avons un tableau de 10x4 nombres. Ce tableau peut être vu comme une image sur laquelle nous allons brancher un réseau de convolution.
Il est intéressant de résumer le bid price et l'ask price avec leur quantité pour avoir une représentation « moyennée » de ce qu’il se passe au bid et à l’ask. Il faudra sauter des « pixels » pour ne pas avoir le volume du bid avec le prix de l’ask. Nous utiliserons donc un noyau de 1x2 et un stride de 1x2 - le stride consiste à «sauter» volontairement certains pixel. Nous obtenons ainsi comme sortie un tableau de 2x10. Nous calculons également la moyenne des deux résultats à l'aide d'un noyau de 1x2. Nous obtenons donc un tableau de 1x10. Enfin, nous fusionnons les 10 nombres à l'aide d'un noyau de 10x1. Nous obtenons donc un nombre représentatif de tout notre carnet.
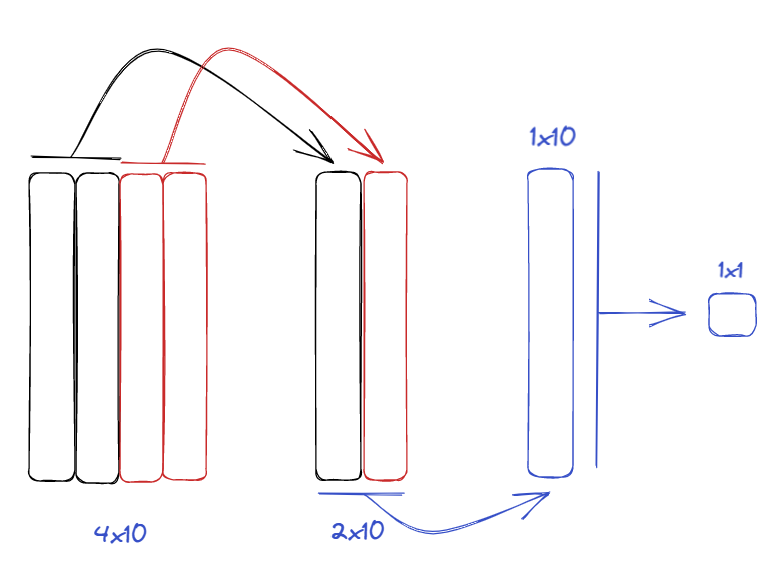
Finalement, nous avons ceci pour les 100 derniers états du carnet, ce qui nous donne un vecteur de 100x1.
Afin de capturer la relation temporelle et dans le but d’avoir un nombre de paramètres réduit, nous utiliserons des cellules LSTM. Nous avons donc finalement la probabilité estimée par le modèle pour que le mouvement monte, baisse et stagne.
Quelques détails techniques :
- La dernière couche de sortie utilise une fonction d'activation softmax ;
- La fonction de perte utilisée sera celle de l'entropie croisée catégorielle ;
- ADAM est également utilisé (avec epsilon de 1 et learning rate de 0.01) ;
- L'apprentissage est arrêté lorsque la précision de la validation ne s'améliore pas durant les epochs suivantes ;
- Nous allons prendre un batch size de 32.
Résultats (sans mécanisme d'attention)
Définition : le mean accuracy, le rappel, la précision et le score F1 sont métriques de performance. Elles nous permettrons d'évaluer notre modèle. Le but étant d’avoir la plus grande valeur possible sur ces quatre métriques.
Le deep learning nécessite souvent une grande quantité de données pour calibrer les poids. Les 7 premiers jours du jeu de données FI-2010 sont utilisés comme données de train et les 3 derniers jours sont utilisés comme données de test. Les performances sont mesurées en calculant le mean accuracy, le rappel, la précision et le score F1. Comme l'ensemble de données FI-2010 n'est pas bien équilibré, il est préférable de se concentrer sur les performances des scores F1. Le modèle est comparé à tous les résultats expérimentaux existants dans la littérature scientifique :
- Ridge Regression (RR)
- Single-Layer-Feedforward Network (SLFN)
- Linear Discriminant Analysis (LDA)
- Multilinear Discriminant Analysis (MDA )
- Multilinear Time-series Regression (MTR)
- Weighted Multilinear Time-series Regression (WMTR)
- Multilinear Class-specific Discriminant Analysis (MCSDA)
- Bag-of Feature (BoF) [24], Neural Bag-of-Feature (N-BoF)
- Attention-augmented-Bilinear-Network avec une couche cachée (B(TABL))
- Attention-augmented-Bilinear-Network avec deux couches cachées (C(TABL))
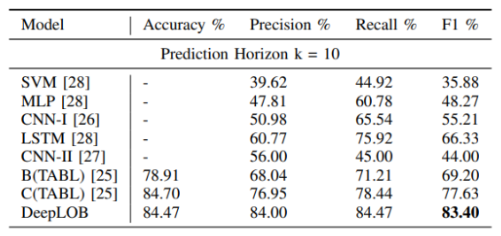
Nous pouvons voir de belles améliorations sur les performances. Dans le tableau ci-dessous, le nombre de paramètres est mis en comparaison entre les algorithmes de CNN. Notre modèle (DeepLOB) possède beaucoup plus de couches, pourtant il a beaucoup moins de paramètres en raison de l'utilisation de cellules LSTM au lieu de couches entièrement connectées.
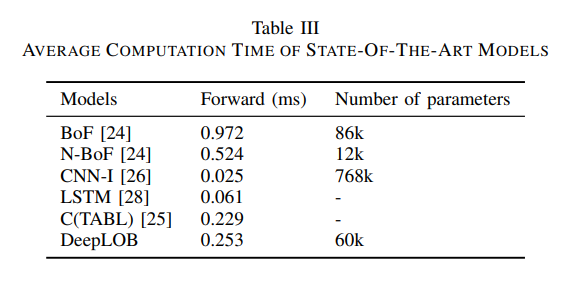
L’apprentissage est également satisfaisant : on observe un validation loss - qui correspond aux données de test, le but étant qu’elle soit le plus faible possible - qui stagne dès la 5ème epoch :
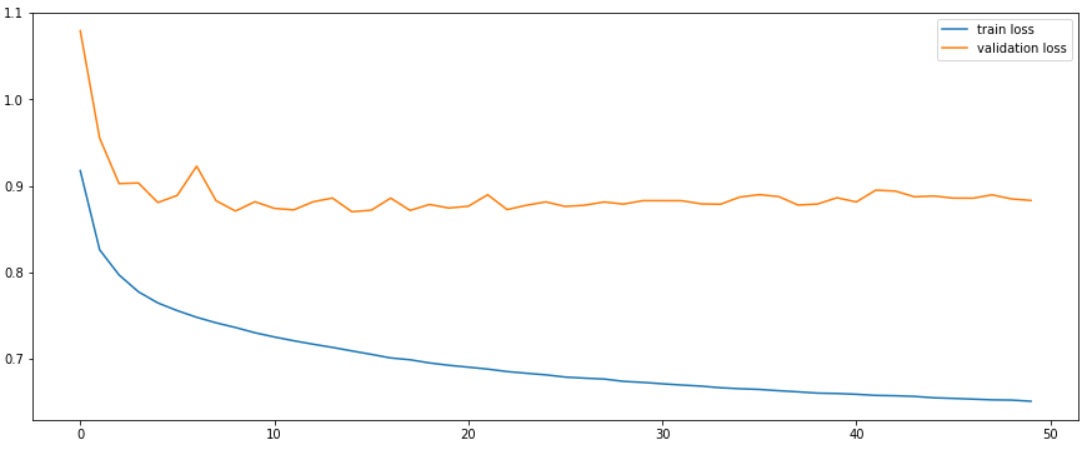
LSE
Comme nous l’avons dit plus haut, l'ensemble de données FI-2010 n'est pas suffisant. En effet, l'échantillon de données est trop faible et tiré d'un marché moins liquide. Pour effectuer une évaluation significative, le modèle est testé sur des actions du London Stock Exchange (LSE) d'une durée d'un an avec une période de test de trois mois. L'entraînement du modèle se fait sur cinq actions : Lloyds Bank (LLOY), Barclays (BARC), Tesco (TSCO), British Telecom (BT) et Vodafone (VOD). Les travaux récents suggèrent que les techniques de deep learning peuvent extraire des caractéristiques universelles sur les carnets d'ordres. Pour tester cette universalité, nous appliquons directement notre modèle à cinq actions supplémentaires non utilisées durant l'apprentissage (transfer learning). Celles-ci sont HSBC, Glencore (GLEN), Centrica (CNA), BP et ITV. Elles figurent aussi parmi les actions les plus liquides du LSE. La période de test est la même de trois mois et les classes sont à peu près équilibrées. Le tableau ci-dessous présente les résultats de notre modèle pour toutes les actions sur différents horizons de prédiction.
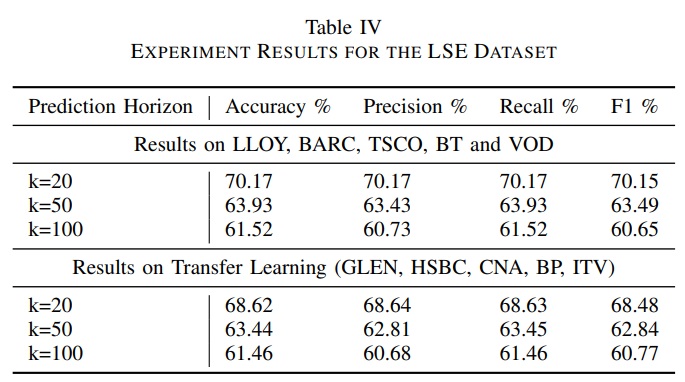
Résultats (avec mécansime d'attention)
Nous observons, sur le tableau ci-dessous, que DeepLOB-Attention fournit des résultats similaires à DeepLOB pour de courts horizons de temps. Cependant, le modèle au mécanisme d’attention fait mieux lorsque l'on considère des horizons de temps plus longs comme pour k=100.
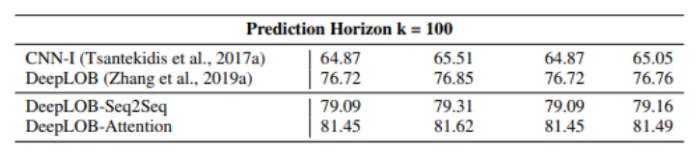
Finalement, les trois modèles obtiennent de solides résultats prédictifs avec DeepLOB-Attention en tête de classe.
Références
[1] Zhang Z., Zohren S. & Roberts S. (Janvier 2020). DeepLOB: Deep Convolutional Neural Networks for Limit Order Books [...]
[2] Zhang Z. & Zohren S. (Août 2021). Multi-Horizon Forecasting for Limit Order Books: Novel Deep Learning Approaches [...]
[3] Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, Polosukhin (Décembre 2017). Attention Is All You Need [...]