

Après avoir travaillé plusieurs mois en utilisant Spark, je me suis lancé dans la préparation de la certification Spark, que j’ai obtenue récemment. Je souhaitais partager avec vous mes notes et conseils afin de préparer et de passer plus sereinement cette certification à votre tour !
Databricks étant fondé par les créateurs de Spark, c’est cet organisme qui délivre les certifications Spark. Autrefois, il était possible de passer la certification pour Spark 2.4 ou Spark 3.0, mais la certification pour Spark 2.4 étant à présent obsolète, le seul choix qu’il vous reste est de passer la nouvelle version de l’examen.
Lisez bien jusqu’à la fin, je vous partage une fiche récapitulative des éléments à connaître ainsi qu’un examen blanc fourni par Databricks pour vous entrainer en conditions réelles !
I - Présentation et contenu de l’examen
Il est tout d’abord important de noter qu’il ne s’agit plus d’un mélange de QCM et de coding challenges, aujourd’hui l’examen consiste en un QCM de 60 questions, pour lesquelles vous devez avoir au minimum 42 réponses justes (70%) pour passer. L’examen dure 2 heures et vous coûtera 240 USD (200 $ + 40 $ de taxes). Vous devrez payer à nouveau pour passer l’examen en cas d’échec. Cet examen existe pour Scala ou Python. Cet article se concentrera sur la version Scala de l’examen, car c’est cette version que j’ai passée.
Pour en savoir plus, tous les détails sur le contenu de la certification sont disponibles sur le site officiel de Databricks.
Une fois que vous serez prêts à sauter le pas, vous devrez vous créer un compte sur le site de la Databricks Academy depuis lequel vous pourrez accéder à la liste des certifications disponibles. L’inscription et le paiement se feront sur la plateforme Webassessor sur laquelle vous devrez créer un nouveau compte également.
Maintenant que vous savez comment vous inscrire, nous allons étudier en détail le contenu de l’examen. Pour rappel, il s’agit d’un QCM de 60 questions, pour chaque question une seule réponse est correcte. D’après la FAQ, l’examen couvre trois domaines :
- Spark Architecture - Conceptual understanding (~17%) : Comprendre l’architecture d’un cluster, la hiérarchie d’exécution d’un job Spark, comprendre des notions comme le shuffling, le partitioning, la “lazy evaluation”, les transformations narrow vs wide, la différence entre action et transformation etc…
- Spark Architecture - Applied understanding (11%) : Cette série de questions est un peu plus délicate et demandera au candidat de comprendre comment est exécuté un job, en passant du moment où il est soumis au cluster, jusqu’à la restitution du résultat.
- Spark dataFrame API Applications (~72%) : Le cœur de l’examen, c’est sur ce sujet que vous devrez concentrer vos efforts, nous le verrons dans la suite de cet article, mais savoir utiliser la documentation de Spark sera votre meilleur allié dans cette série de questions.
Il est possible que des nouveautés de Spark 3.0 (comme l’Adaptive Query Execution) soient incluses dans l’examen. Pas d’inquiétude, tout est inclus dans la “cheat sheet” de la partie III de cet article !
Vous savez donc à quoi vous attendre, nous allons maintenant voir comment vous pouvez vous préparer pour être prêts le jour J.
II - Révisions pour l’examen
Cette partie vous partage les ressources que vous pouvez utiliser pour apprendre Spark (que ce soit en partant de zéro ou non).
Commençons par les basiques, ce sont les ressources que vous retrouverez dans plus ou moins tous les guides pour passer cette certification et ce n’est pas sans raison !
- Lire les sections I, II et IV de Spark - The Definitive Guide ce livre, écrit par les créateurs de Spark permet de comprendre ce qui se passe quand vous exécutez du code Spark. C’est le point d’entrée indispensable pour apprendre ou vous perfectionner, je vous le recommande vivement !
- Si votre entreprise ou client est partenaire avec Databricks, vous pourrez effectuer les différents cours en ligne disponibles sur la Databricks Academy. Si ce n’est pas le cas, pas de panique, d’autres ressources sont disponibles et cet article vous fournira un récapitulatif des notions à comprendre pour réussir l’examen.
Je vous conseille ensuite de vous concentrer sur les points suivants :
- Apprendre à utiliser les documentations suivantes, a minima : Dataset, Column, Functions (si vous passez la version Python de l’examen, référez-vous aux versions Python de la documentation bien-sûr). Savoir si une fonction prend en argument un
Stringou uneColumnpar exemple vous sauvera la vie lors de l’examen. Essayez de bien retenir les signatures des fonctions et sur quoi elles s’appliquent. - Afin d’avoir un tour d’horizon de la certification et de l’architecture de Spark, je vous recommande cette excellente vidéo de Advancing Analytics.
Si vous ne vous sentez pas en confiance vous pouvez acheter un cours sur Udemy, mais n’en ayant pas fait je ne suis pas en mesure de vous en recommander un...
À ce stade, vous devriez maintenant être à l’aise sur les sujets suivants :
- Savoir comment une requête est exécutée
- Hiérarchie entre jobs, tasks, application et stages
- Architecture d’un cluster : nodes, driver, workers, executors, slots etc...
- Modes d’exécution de Spark
- Relation entre Driver et Executors
- Action set Transformations narrow vs wide
- Lazy evaluation, Shuffling, Repartitioning, Broadcasting
- etc...
La partie suivante vous partagera mes notes et ressources pour vous entraîner à l’examen.
III - Ressources
Cette partie peut être considérée comme une “cheat sheet” qui récapitule une grande partie des choses à savoir pour l’examen.
En plus de ces notions, je vous conseille de jeter un œil aux différents Storage Levels disponibles lorsque vous voulez mettre de la donnée en cache (et la manière dont la donnée sera stockée en les utilisants), ainsi qu’aux principales valeurs par défaut de la configuration de Spark comme par exemple spark.sql.shuffle.partitions, spark.sql.autoBroadcastJoinThreshold ou spark.sql.adaptive.skewJoin.enabled
Architecture de Spark
Architecture d’un Cluster et hiérarchie d’exécution
Un Job se divise en plusieurs Stages. Chaque Stage est une série d’opérations pouvant être effectuées sans devoir faire de shuffle (donc à chaque shuffle, un nouveau stage est créé). Chaque “portion” de données à traiter est une Task et elle ne peut être faite que par un CPU à la fois.
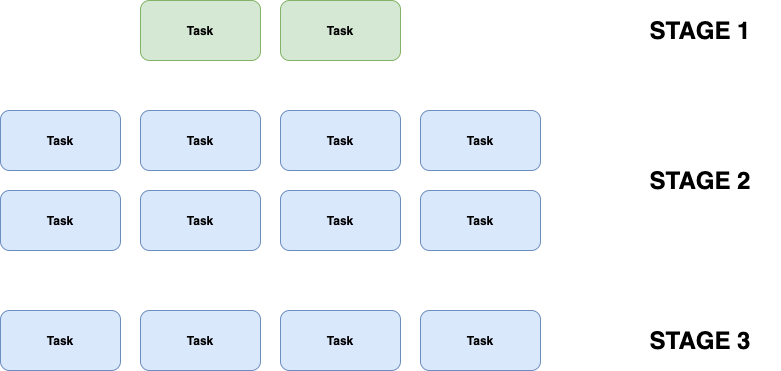
Pour résumer, les Tasks sont traitées par des Slots, qui sont un CPU en attente de travail. Le nombre de tâches que notre cluster peut faire en parallèle correspond donc au nombre de slots disponibles sur le cluster.
Un cluster est composé de plusieurs Nodes pouvant être soit un Driver Node soit un Worker Node.
Le Driver est l’endroit où est exécutée la méthode main() de votre application. Il est responsable d’assigner et de récupérer le résultat des Task assignées aux Executors.
Les Executors sont des processus exécutés sur les Workers et ont pour mission d’effectuer les traitements que le Driver leur assigne.
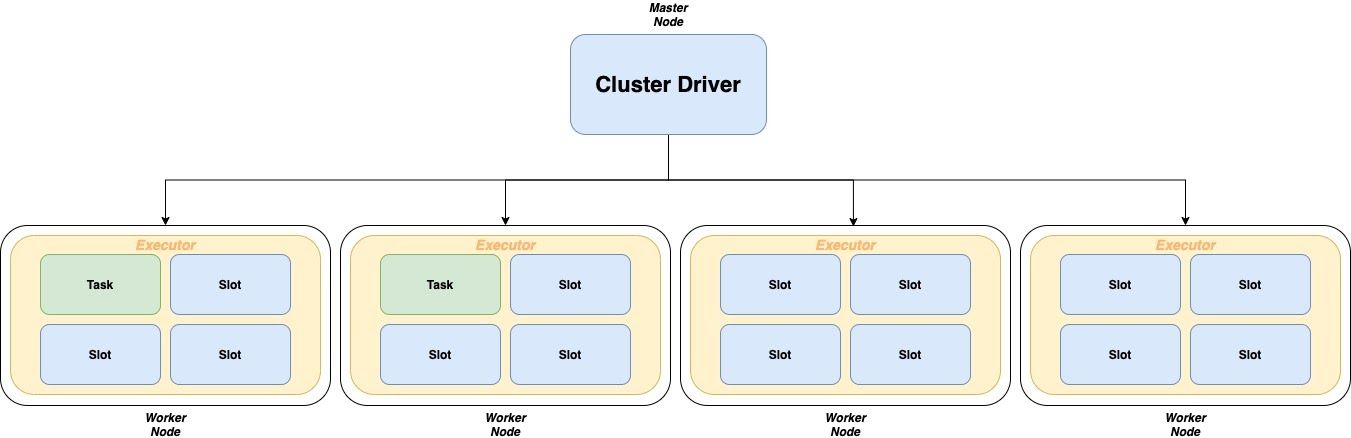
Si on se réfère au Stage n°1 du Job de l’illustration précédente, on peut assigner dans ce cluster uniquement 2 Tasks aux Workers, tous les autres Slot vont rester sans rien faire jusqu’à ce qu’on passe au Stage n° 2 dans lequel on pourra assigner les 8 Task à 8 Slots de notre Cluster (il ne sera donc utilisé qu’à 50 %, car on utiliserait que 8 Slots sur les 16 disponibles).
ℹ️ Un Worker, s’il a assez de CPU, pourrait contenir plusieurs Executors. En pratique, on n’a souvent qu’un Executor par Worker.
Shuffling
Un shuffle est le processus par lequel les données sont comparées entre les partitions. C'est ce qui se passe dans le cas des transformations wide car elles nécessitent l'ensemble des données pour être traitées.
Pendant un shuffle, les données sont écrites sur le disque et transférées sur le réseau.
Partitioning
Pour répartir le travail sur le Cluster et réduire les besoins en mémoire de chaque Node, Spark va diviser les données en parties plus petites appelées Partitions. Chacune de ces parties est ensuite envoyée à un Executor pour être traitée. Une seule partition est calculée par Executor Thread à la fois. Par conséquent, la taille et la quantité de partitions transmises à un exécuteur sont directement proportionnelles au temps qu'il faut pour les réaliser.
⚠️ Les partitions Spark sont à dissocier des partitions que vous pouvez avoir sur votre système de stockage. Ici, on parle bien de partitions Spark, c’est-à-dire les “morceaux” de votre donnée en entrée que vous allez fournir aux Workers (qu’on obtient avec les méthodes coalesce() et repartition() de la classe Dataframe), et non la manière dont votre donnée peut être partitionnée sur votre bucket S3 par exemple (en utilisant la méthode partitionBy() de la classe DataFrameWriter).
Lazy evaluation
L'exécution ne commencera pas avant qu'une action (write, collect, show, head, first...) ne soit déclenchée.
Pour les transformations, Spark les ajoute à un DAG (Directed Acyclic Graph, en français graphe orienté acyclique) et ce n'est que lorsque le Driver demande des données que ce DAG est réellement exécuté.
ℹ️ Il faut donc retenir que les transformations construisent un plan d’exécution et que les actions démarrent son exécution. Les opérations telles que printSchema() ne sont ni des actions ni des transformations et ne démarrent donc pas une exécution.
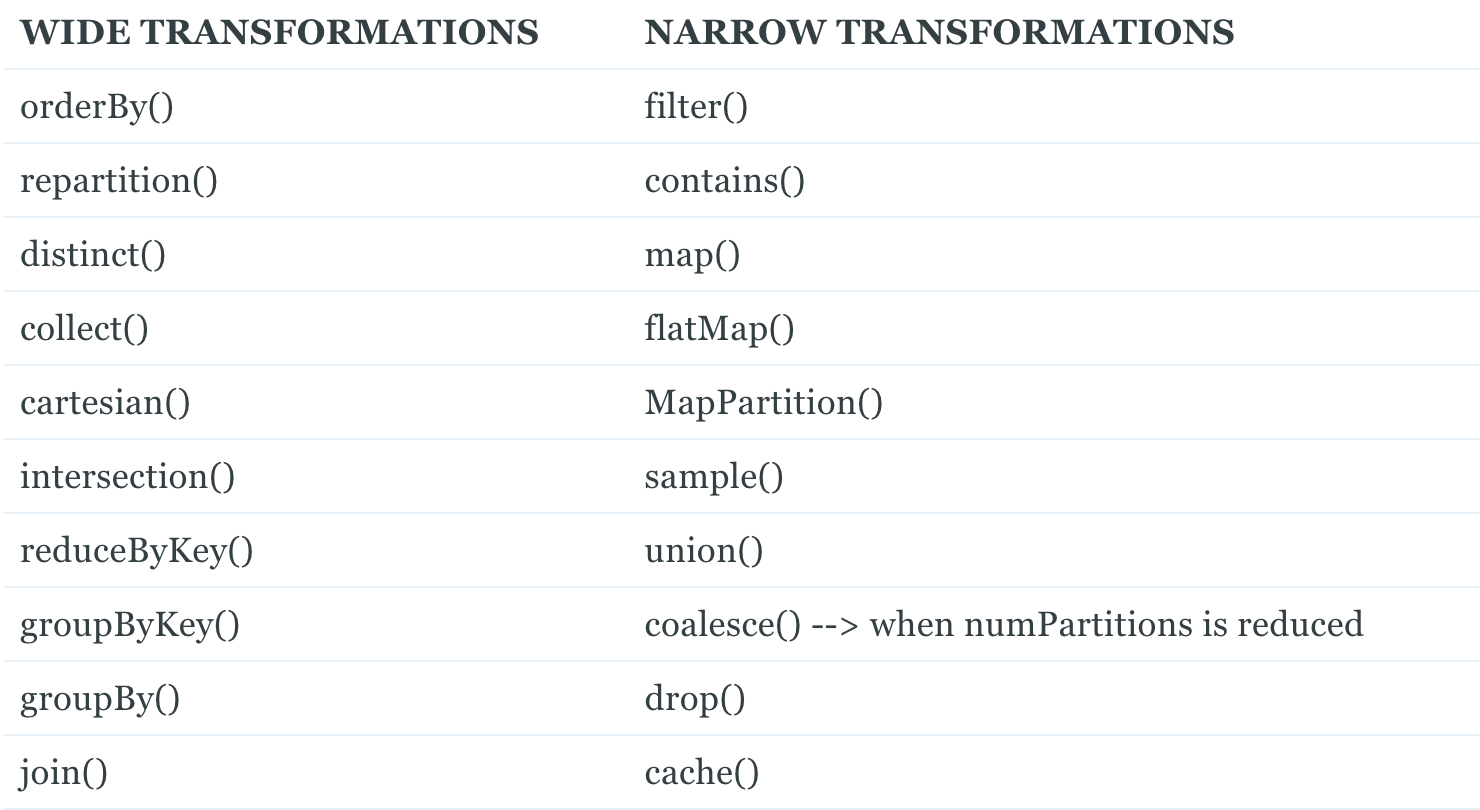
Narrow transformations vs Wide transformations
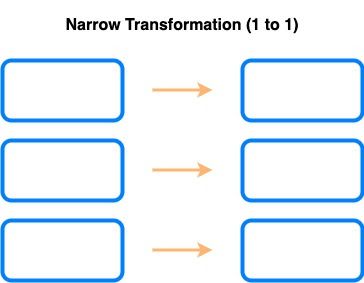
Une transformation dite Narrow est une transformation qui n’a pas besoin des autres partitions pour être effectuée (par exemple : filter, select, union…).
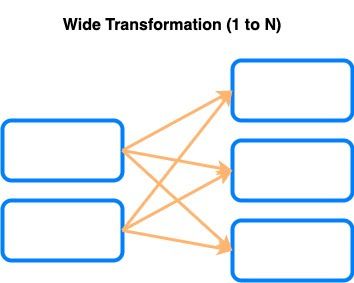
Une transformation dite Wide au contraire a besoin des autres partitions et produit donc un shuffle (par exemple : join, distinct, groupBy…)
Pour récapituler, voici une liste des principales transformations, classées par type :
Modes d’exécution
Spark peut fonctionner dans différents modes :
Cluster mode : le Cluster Manager lance le Driver sur un Worker Node à l'intérieur du Cluster, en plus des processus exécuteurs. Cela signifie que le Cluster Manager est responsable de la maintenance de tous les Worker Nodes Spark. Par conséquent, le Cluster Manager place le Driver sur un Worker Node et les Executors sur des Worker Nodes distincts.
Client Mode : le Cluster Manager lance le processus du Driver sur la machine à partir de laquelle le Job est soumis.
Repartitioning vs Coalescing
Repartition :
- Utilisé pour modifier le nombre de partitions d'un Dataframe.
- 📈 / 📉 Le nombre de partitions peut être augmenté ET diminué.
- ⚠️ Produit un shuffle.
Coalesce :
- Utilisé pour diminuer le nombre de partitions d'un Dataframe.
- 📉 Le nombre de partitions peut UNIQUEMENT être diminué.
- ✅ Minimiser le déplacement des données (pas de shuffle complet).
Broadcasting
Permet de répliquer des données sur tous les Workers pour les petits ensembles de données afin d'éviter le shuffle.
Variables partagées en lecture seule qui sont mises en cache et disponibles sur tous les nœuds d'un cluster afin d'être accessibles ou utilisées par les tâches. Au lieu d'envoyer ces données à chaque tâche, Spark distribue les broadcast variables à la machine en utilisant des algorithmes de diffusion efficaces pour réduire les coûts de communication.
Adaptive Query Execution
Introduit depuis Spark 3.0, cette option (désactivée par défaut, UPDATE: maintenant activé par défaut depuis Spark 3.2.0) permet trois choses :
- Coalescing dynamique des partitions de shuffle (combine de petites partitions adjacentes en partitions plus grandes au moment de l'exécution en examinant les statistiques du fichier de shuffle).
- Changement dynamique des stratégies de jointure.
- Optimisation dynamique des jointures “inégales” (en anglais skew join, une condition dans laquelle les données d'une table sont réparties de manière inégale entre les différentes partitions).
L’API Dataframe
Pour cette partie, je ne vais pas vous lister une à une les méthodes à savoir. Je ne pense pas que cela vous sera d’une grande utilité. Je vais simplement vous lister les manipulations requises par Databricks pour cet examen, à vous de naviguer dans la documentation pour trouver les méthodes associées et étudier leur signature et utilisation (N'oubliez pas que cette partie représente plus de 70% de l’examen, elle n’est donc pas à négliger) :
- Subsetting DataFrames (select, filter, etc.)
- Column manipulation (casting, creating columns, manipulating existing columns, complex column types)
- String manipulation (Splitting strings, regex)
- Performance-based operations (repartitioning, shuffle partitions, caching)
- Combining DataFrames (joins, broadcasting, unions, etc)
- Reading/writing DataFrames (schemas, overwriting)
- Working with dates (extraction, formatting, working with different data types etc)
- Aggregations
- Miscellaneous (sorting, missing values, typed UDFs, value extraction, sampling)
Une fois que vous aurez bien en tête les différents sujets, il est temps de vous lancer ! Le meilleur entraînement possible (et que je n’ai vu conseillé nulle part…) est de faire le QCM d’entraînement fourni par Databricks en utilisant uniquement la documentation de Webassessor que vous aurez le jour de l’examen. Vous serez donc en conditions réelles et cet exercice vous permettra de savoir si vous êtes prêts ou non à passer le vrai examen.
Merci de m’avoir lu, j’espère que vous êtes maintenant prêts pour passer cette épreuve, si néanmoins vous avez encore des questions, n’hésitez pas à me contacter sur LinkedIn !
