
Cet article de blog présente une solution de Data Lineage nommé Spline qui permet de tracer les différentes actions et transformations dans un traitement avec Apache Spark.
Qu’est-ce que le data lineage et pourquoi l’utiliser ?
Le data lineage est une problématique qui existe depuis que l’on s’intéresse au traitement de la donnée. En effet, dans les organisations quelles qu’elles soient, on cherche à conserver la provenance des données et à pouvoir tracer les différentes transformations au cours du cycle de vie de la donnée (lors d’un traitement ETL par exemple).
Cette traçabilité est nécessaire lorsque l’on veut auditer les différents traitements qui sont faits dans un système d’information (dans un Data Lake par exemple) ce qui est un besoin fréquent chez les grands comptes (par exemple dans le milieu bancaire où les entreprises doivent fournir des reporting réglementaires fréquents). De plus, les données étant un asset particulièrement stratégique et précieux, un lineage efficace permet de garder le contrôle sur les traitements qui sont réalisés.
Idéalement, les outils de lineage de données doivent permettre de tracer les versions des datasets utilisés. En effet dans un contexte de Data Lake, les sources de données changent fréquemment (nouvelles données qui arrivent tous les jours par batch ou au fil de l’eau en streaming, référentiel qui évolue et croît au cours du temps etc..) et il est important de pouvoir tracer quelle version du dataset d’entrée a été utilisée pour produire tel dataset de sortie.
Quels sont les outils existants ?
Il existe différents outils pour effectuer ce lineage, certains étant plus ou moins spécifiques, plus ou moins globaux, liés aux écosystèmes Big Data ou non.
-
De nombreux outils existent pour faire du lineage dans les systèmes de type Data Warehouse où toutes les données sont structurées (donc le lineage est relativement facile). On pourrait citer par exemple QueryFlow.
-
Il existe également des outils beaucoup plus macro qui permettent de faire le lineage d’un SI entier, de cartographier les données, d’assurer la gouvernance de la donnée etc. On peut penser à Collibra ou Zeenea, spécialisé dans la cartographie des données et le data catalog.
-
Dans le monde Big Data, certaines plateformes d’analytics intègrent nativement du lineage. On peut penser à Dremio par exemple ou des plateformes plus orienté data science comme Pachyderm.
-
Dans le monde Hadoop, il existe deux outils à ma connaissance qui permettent de faire du lineage de la donnée : Apache Atlas ou Cloudera Navigator. Ces outils sont assez récents et offrent une granularité de lineage relativement haute avec un versionnage des datasets inexistant. De plus ces outils s'interfacent assez mal avec Apache Spark qui est devenu le framework de processing de la donnée le plus populaire et ont tendance à le voir comme une boîte noire. Apache Atlas offre cependant une API de lineage qu'il est possible d'appeler directement depuis un traitement Spark sous la forme d’un logger.
-
Apache Nifi qui permet d’ingérer des données au sein d’un cluster Hadoop propose une fonction de “Provenance Repository” pour faire du lineage sur les données ingérées.
-
Enfin il existe des outils spécifiques à Spark, ceux qui nous intéressent aujourd’hui, qui permettent de faire le lineage automatiquement sans Logger particulier avec une granularité plus fine. L’outil qui va nous intéresser s’appelle Spline. Spline vient de Spark Lineage et est composé de deux éléments : un noyau permettant de déduire les différentes transformations, et une web UI pour visualiser le résultat des jobs. C’est un outil relativement jeune développé par la banque sud africaine Absa.
Démo avec Spline
Spline est un outil développé par une banque sud africaine pour répondre à la norme bancaire BCBS 239 (norme comptable réglementaire sur la gestion et le reporting autour du risque financier). Pour effectuer le lineage, Spline se base sur le plan d’exécution Spark généré automatiquement par le framework.
Le plan d'exécution est constitué de l’ensemble des opérations à effectuer dans un job Spark (enchaînement d’actions ou de transformations comme filter, join, group by, etc.). On distingue deux plans d'exécution : le plan logique qui est composé des instructions dans l’ordre où elles apparaissent dans le code, et le plan physique qui optimise l'ordre des différentes instructions (ex : filtre en premier pour avoir moins de données).
Spline se base sur le plan logique car c’est l’enchainement des actions au niveau du software et non du hardware qui nous intéresse.
Spline s’appuie sur différents back-end pour le stockage des données : MongoDB, HDFS ou bien Apache Atlas. Pour la démo de cet outil, nous utiliserons MongoDB.
Installation de MongoDB
Pour commencer, nous allons lancer un container Docker (installation) contenant la base MongoDB. Pour cela, rien de plus simple, lancer la commande suivante :
docker run -it -p 27017:27017 -d mongo:3.4
On utilise la version 3.4 de Mongo car il y a des incompatibilités avec la version la plus récente au moment où j’écris ces lignes (la 3.6) https://github.com/AbsaOSS/spline/issues/12
Si l’image Docker n’a jamais été récupérée, cela devrait prendre 5 bonnes minutes pour l’installer. Nous allons maintenant vérifier que l’on peut bien accéder au container. Pour cela, plusieurs solutions existent, comme mongo-express, robot 3T ou bien le client mongoDb en ligne de commande.
Installer un des 3 outils. Pour ce tutoriel, j’utilise le client MongoDB.
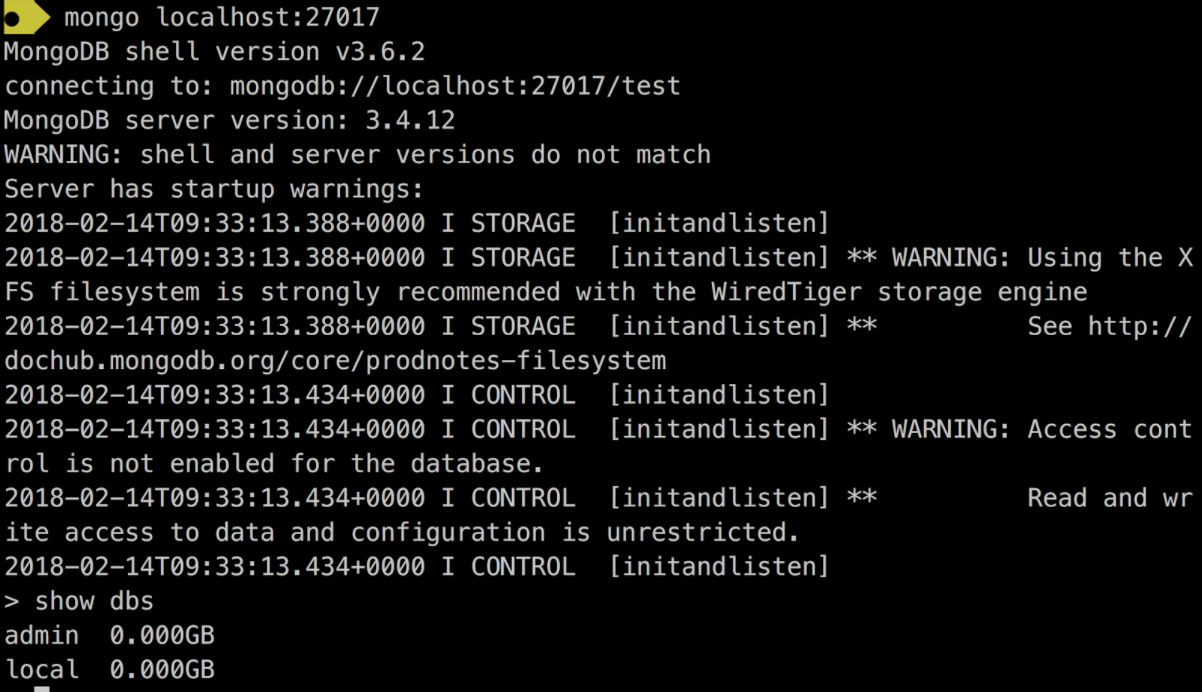
Si le shell se lance sans erreur et que l’instruction show dbs liste les bases par défaut, la base est bien installée !
Installation de Spline
Pour installer Spline, un exécutable .WAR est fourni dans la documentation. C’est grâce à lui que Spline va pouvoir fonctionner. À noter qu’il est aussi possible de packager nous-mêmes un exécutable à partir de Spline Core. Télécharger le WAR
Lancement de Spline
Pour lancer la Web UI de Spline qui va nous permettre de visualiser notre lineage, commencer par cloner le projet depuis GitHub. Ensuite, copier le WAR précédemment téléchargé à la racine du répertoire.
On peut maintenant lancer le serveur web avec la commande suivante en précisant bien l’URL de la base MongoDB (localhost dans notre cas) et le nom de la database mongo où l’on veut enregistrer les informations (local par défaut).
java -jar spline-web-0.2.5-exec-war.jar -Dspline.mongodb.url=mongodb://localhost -Dspline.mongodb.name=local
Si tout se passe bien, la web UI devrait être accessible sur http://localhost:8080 de votre navigateur.
Lancement d’un Job Spark
Spline nous fournit des jobs Spark d’exemple pour visualiser notre lineage mais il est bien évidemment possible d’associer Spline avec vos Jobs déjà existants (en spécifiant bien la dépendance vers MongoDB, Spark et Scala dans le gestionnaire de dépendances) en ajoutant le WAR contenant Spline au Classpath et en rajoutant les deux lignes suivantes :
import za.co.absa.spline.core.SparkLineageInitializer._ sparkSession.enableLineageTracking()
Pour plus d’informations voir cette section du site Spline.
Pour ce tutoriel, nous allons utiliser les Jobs d’exemple fournis par Spline. Se déplacer dans le dossier sample et lancer un des jobs avec l’URL suivante :
mvn test -Psamples -Dspline.mongodb.url=mongodb://localhost -Dspline.mongodb.name=local -DsampleClass=za.co.absa.spline.sample.SampleJob1
Une fois exécuté, se rendre sur http://localhost:8080 pour visualiser les résultats du Job en sélectionnant le résultat sur la gauche et en cliquant sur “show lineage graph” sur la droite.
Cela nous donne une vision macroscopique des traitements :
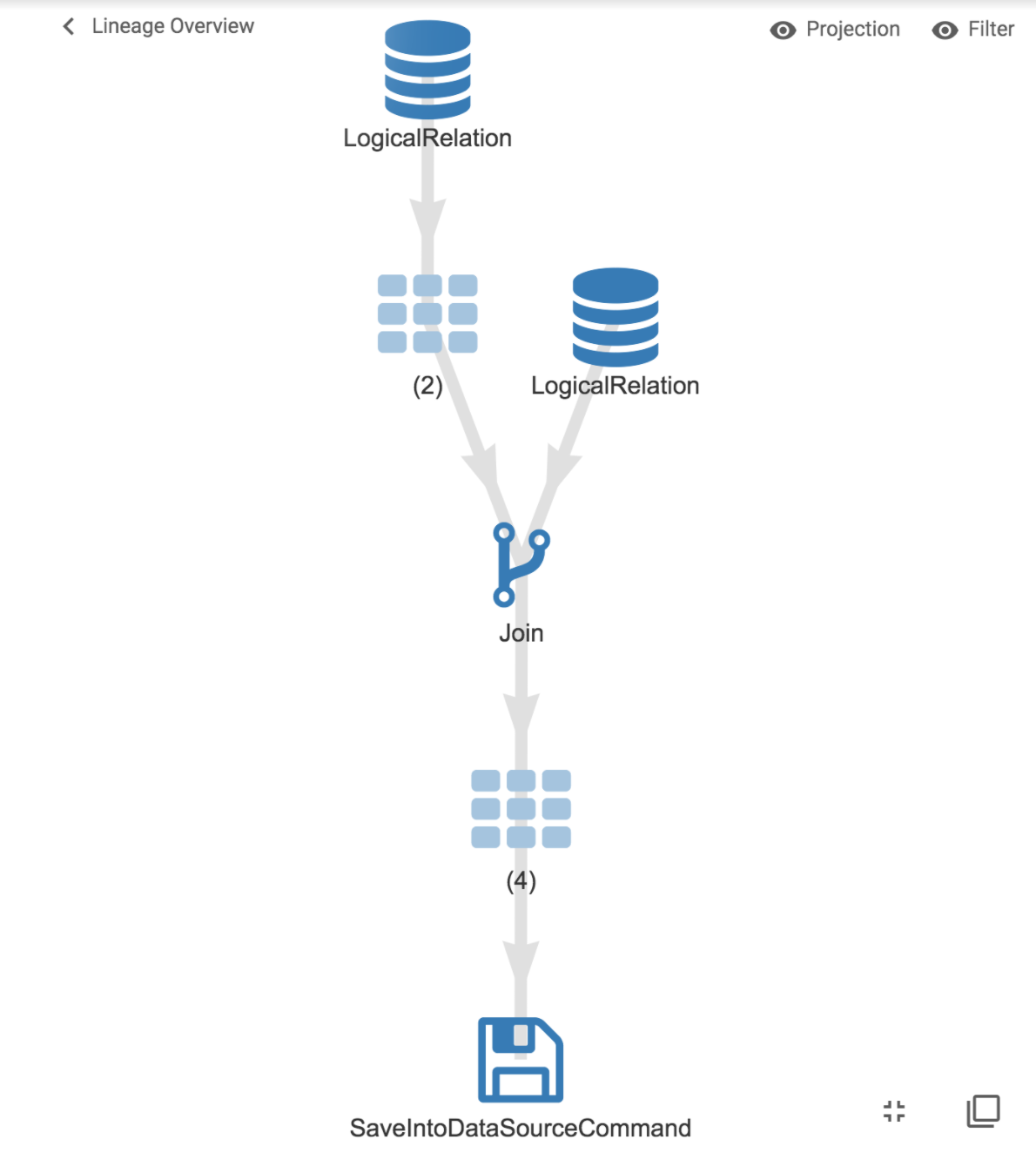
Il est possible de cliquer là où les traitements sont rassemblés pour avoir des détails sur les opérations :
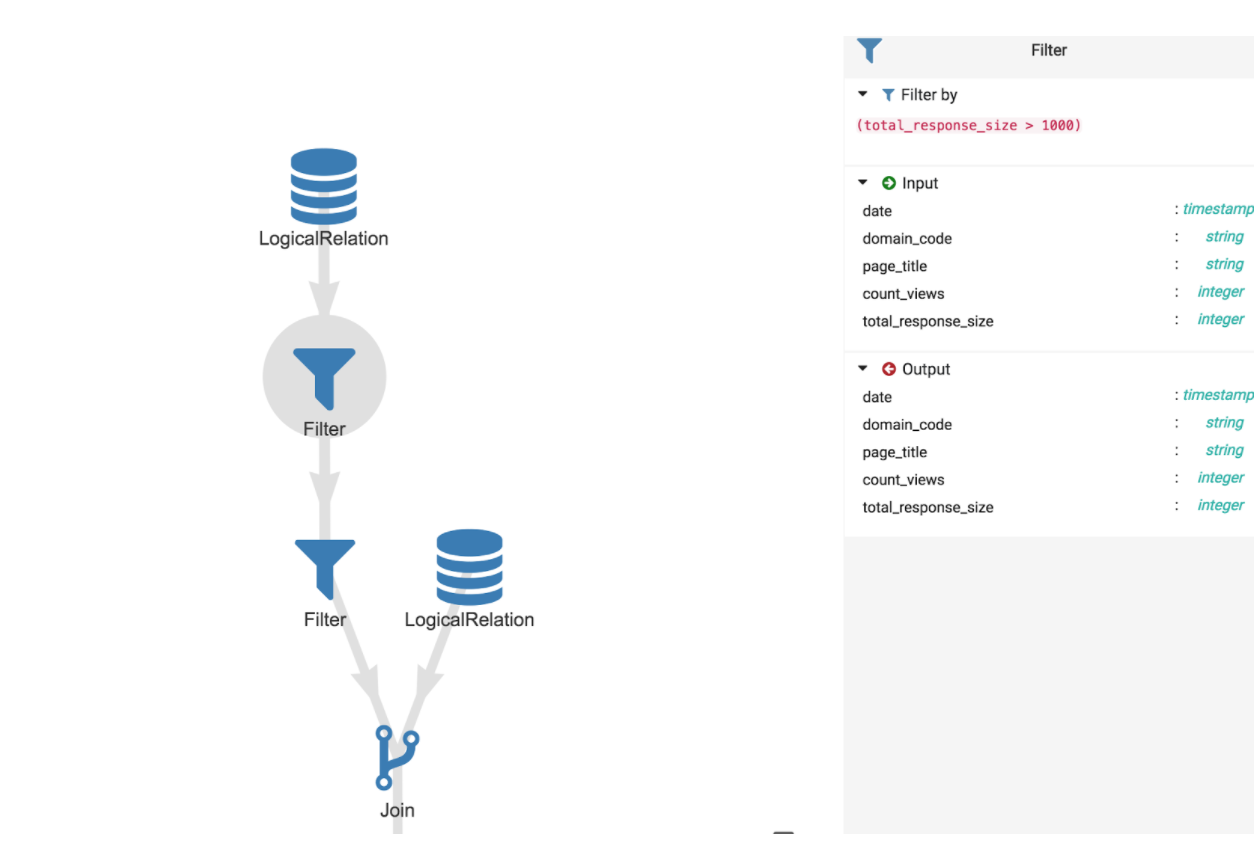
On peut voir par exemple le détail du filtre qui a été effectué avec les données en entrée et en sortie et la condition de filtrage qui a été appliquée.
Limites / Conclusion
Comme on l’a vu, Spline est très simple d’utilisation et permet de facilement commencer à faire du lineage sur des traitements Spark. Entre autre, il permet de documenter de la logique métier et peut servir d’aide à la supervision des performances des traitements en identifiant les durées de chaque étape.
Néanmoins, l'inconvénient de Spline (et de tous les outils de lineage sur Spark en général), c’est qu’il marche très bien tant qu’on reste dans l’API des DataFrames et Spark SQL (car un plan d’exécution détaillé est généré), mais quand on sort de cette API pour des développements plus spécifiques (utilisation des map sur les DataFrames et passage vers l’api Dataset), Spline n’est plus capable de savoir ce qui se passe à l’intérieur de ce map qui est interprété comme une boîte noire.
Or, dans des “conditions réelles”, on est obligé de fréquemment sortir des DataFrames pour faire des développements spécifiques en repassant par les Datasets.
Enfin, un autre point négatif est qu’il n’est pas possible d’utiliser Spline sur du Spark Streaming pour le moment, même si après avoir posé la question à l’équipe de dev c’est prévu pour la version 0.3.0.
Hormis cela, Spline est un outil facile à prendre en main et avec une UI de qualité qui permet aux développeurs et aux métiers d’échanger et d'interagir sur une base commune. À surveiller car Spline est un outil encore jeune qui va s’améliorer et s’enrichir de nouvelle fonctionnalités au cours du temps (Spark Streaming, versionning plus fin des dataset IO, gestion des utilisateurs qui lance les jobs...).
Twitter : @lulufrego
