
Par Steve HOUËL, Solution Architect chez Ippon Technologies
Nous le savons tous, le monde informatique est en constant changement. Que ce soit les évolutions matérielles, l’avènement de l’IoT ou encore les services proposés par les Cloud Providers. Le monde du développement logiciel n’échappe pas à cette tendance. Outre les nouveaux frameworks Web qui sortent plus vite que notre courbe d’apprentissage, les architectures applicatives elles aussi se voient repensées, remaniées. Il y a encore peu de temps, nous pensions tous qu’un bon vieux monolithe était “LA” solution simple, efficace et pas chère.
Hors avec l’émergence de la conteneurisation et du DevOps, un nouveau panel d’architectures a vu le jour. Nous avons ainsi hérité des architectures Microservices. Simples, scalables et rapides à développer lorsque l’on se base sur des générateurs tel que JHipster, elles ont ouvertes de nouvelles voies dans le développement d’applications Web. Mais comme toute nouvelle architecture, celle-ci venait avec son lot de contraintes. L’une d’entre elles est la gestion de l’infrastructure. Même si le DevOps et la conteneurisation ont apporté beaucoup dans cette problématique, ils ne l’ont pas résolue pour autant.
Aujourd’hui, une nouvelle architecture fait parler d’elle dans le monde de l’IT, c’est le Serverless. Pour vous expliquer cette nouvelle notion, je me suis basé sur un très bon article de Mike Roberts que je vous recommande.
Alors qu’est-ce que le Serverless exactement ?
Définition
Les architectures sans serveur se réfèrent à des applications qui dépendent de manière significative de services tiers (connue sous le nom de Backend en tant que service ou «BaaS») ou sur un code personnalisé exécuté dans des conteneurs éphémères (Function as a Service ou «FaaS»), le fournisseur de ce service le plus connu est actuellement AWS Lambda.
De nos jours la migration de nombreuses fonctionnalités côté FrontEnd nous a permis de supprimer nos besoins de serveurs “Always On”. Selon les circonstances, de tels systèmes peuvent réduire considérablement le coût et la complexité opérationnels et ainsi se résumer à payer uniquement les frais d’utilisations (bande passante, volume de stockage). Ainsi on ne paie ainsi que ce que l’on consomme, connu aussi comme le pay-as-you-go.
Comme de nombreuses tendances dans le logiciel, il n’y a aucune vision claire de ce qu’est ‘Serverless’, et cela n’a pas été aidé par le fait qu’il s’agisse vraiment de deux domaines différents, mais qui se chevauchent:
- Serverless a d’abord été utilisé pour décrire des applications qui dépendent de manière significative ou totale à des applications / services tiers (‘dans le cloud’) pour gérer la logique et l’état du serveur. Ce sont généralement des applications «client riches» (pensez à des applications Web en une seule page ou à des applications mobiles) qui utilisent le vaste écosystème de bases de données accessibles sur le cloud (comme Parse, Firebase, AWS DynamoDB, …), les services d’authentification (Auth0, AWS Cognito), etc. Ces types de services ont été précédemment décrits comme Backend as a service (j’utiliserai le terme BaaS comme abréviation dans le reste de cet article).
- Serverless peut également symboliser des applications où une certaine quantité de logique serveur est toujours écrite par le développeur, mais contrairement aux architectures traditionnelles (exemple: Monolith), elle est exécuté dans des conteneurs stateless qui sont déclenchés par le biais d’événements, éphémère (uniquement une invocation) et entièrement géré par une 3rd party. Une façon de penser à ceci est le terme Function as a service ou Faas. AWS Lambda est l’une des implémentations les plus populaires de FaaS à l’heure actuelle, mais il y en a d’autres (Google Functions).
Nous parlerons principalement de la deuxième définition du fait qu’elle soit plus récente et qu’elle possède le plus de différence avec la vision que l’on a d’une architecture technique traditionnelle (elle est tout simplement plus hype !!)
Attention à l’étymologie
Le terme «Serverless» est source de confusion car, dans de telles applications, il existe à la fois du matériel et des processus serveur. La différence avec les approches basiques est que l’entreprise créant et prenant en charge une application dite Serverless ne s’occupe pas du matériel ou des processus, ils externalisent cela à un fournisseur (AWS, Google, …) et ainsi se concentrent uniquement sur la partie fonctionnelle de l’application.
Quelques exemples
Afin d’illustrer le fonctionnement et l’approche Serverless, voici des exemples de Use Cases.
Application Web
Prenons l’exemple d’un site e-commerce. Il s’agit d’une application Web 3-tiers avec la logique côté serveur.

Avec cette architecture, le client ne contient pratiquement aucune logique comparé au serveur (authentification, navigation de page, recherche, transactions).
Avec une architecture Serverless, cela pourrait finir par ressembler davantage à ceci:
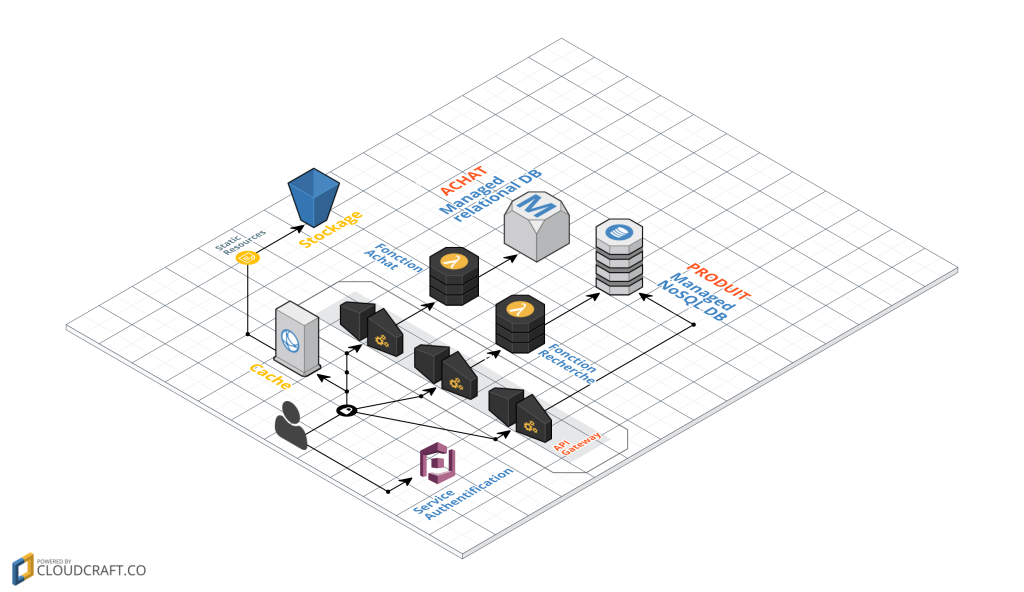
Il s’agit d’un exemple de transposition de l’architecture précédente en Serverless. Il y a un certain nombre de changements importants qui se sont produits ici. S’il vous plaît notez que ce n’est pas une recommandation d’une migration architecturale, je l’utilise simplement comme un outil pour exposer certains concepts sans serveur.
- Plus besoin d’héberger nos fichiers Web sur un serveur, un simple bucket et un outil de gestion du cache peuvent suffir.
- Nous avons supprimé la logique d’authentification et l’avons remplacée par un service tiers BaaS (Auth0, AWS Cognito, …).
- En utilisant un autre exemple de BaaS, nous avons permis à un client d’accéder directement aux données (listes de produits), hébergées par un tiers (AWS Dynamo, Firebase). Nous pouvons aussi établi des règles de sécurité strictes liées aux profils utilisateurs et ainsi gérer les restrictions d’accès aux données.
- Les deux points précédents impliquent un changement important des rôles des tiers : la logique est passée du serveur au client (exemple : suivi d’une session utilisateur, UX, lecture de données et affichage dans une vue utilisable.
- Certaines fonctionnalités sont à garder côté serveur, par exemple, si elles impliquent des calculs intensifs ou nécessitent l’accès à des quantités importantes de données (recherche de produits). Pour cette fonctionnalité, au lieu d’avoir un serveur toujours en cours d’exécution, nous pouvons implémenter une fonction FaaS qui répond aux requêtes HTTP via une API Gateway.
- Finalement, nous pouvons remplacer la fonctionnalité “Achat” par une autre fonction FaaS, en choisissant de la garder sur le côté serveur pour des raisons de sécurité.
Avec ce changement d’architectures, nous avons un nouveau panel d’outils à notre disposition comme l’API Gateway. Pour faire simple, cet outil permet de définir des endpoints sécurisés accessible de l’extérieur et de rediriger l’appel vers un service de traitement (génération d’un événement, lancement d’une fonction) qui une fois fini pourra retourner des données selon les besoins.
Application basée sur les événements (Event-driven)
Un autre Use Case d’architecture Serverless est l’analyse et le traitement de données asynchrones. Prenons un cas que nous connaissons tous, le tracking d’activités des utilisateurs d’une application. Le besoin est d’arriver à connaître les activités précises d’un utilisateur sans impacter les performances de l’application. Nous pourrons ainsi déporter la logique permettant l’envoi/réception d’un événement de navigation et son enregistrement au sein d’une base de données de type BaaS.
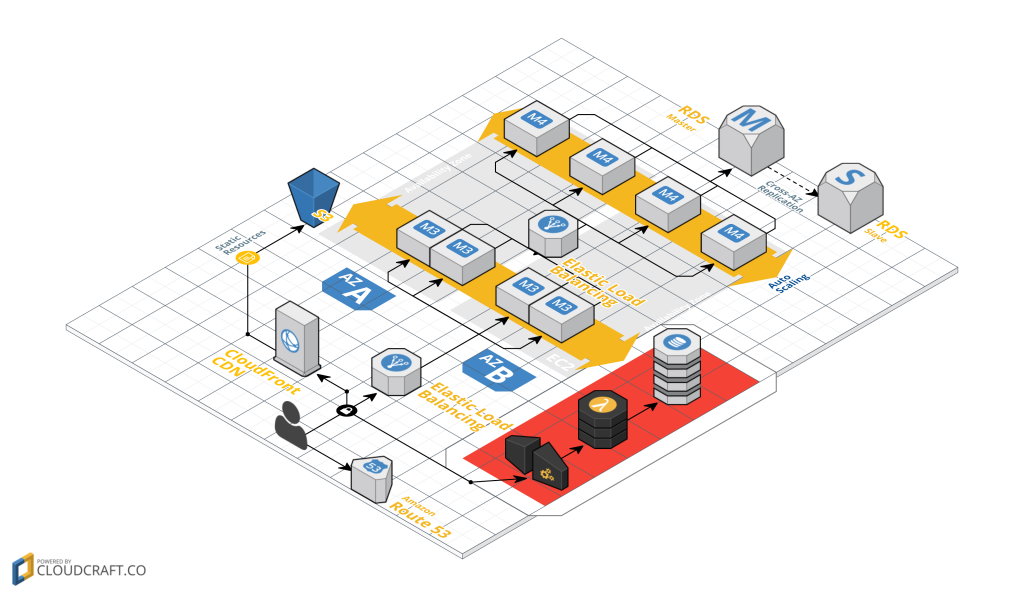
Voici l’exemple d’une architecture d’application Web basique possédant une fonction de tracking Serverless (zone rouge)
Ce service est assuré à l’aide d’une API Gateway, fonction permettant la déclaration d’endpoint et son mapping vers un service de traitement, ici une fonction de type FaaS. Elle-même est en charge de l’enregistrement des données auprès d’une base de données de type BaaS.
Un autre exemple très en vogue de nos jours concerne l’IoT et son envoi d’informations effectué par des milliers de capteurs. Nous n’avons aucun besoin d’une communication synchrone entre la partie serveur et les capteurs, en revanche l’objectif est la récupération des informations, son stockage et son analyse. Un exemple de ce Use Case est la maintenance prédictive. Après la récupération des données brutes issues des capteurs, des algorithmes vont les analyser et pouvoir conjecturer et “prédire” une panne ou un besoin de maintenance d’un équipement.
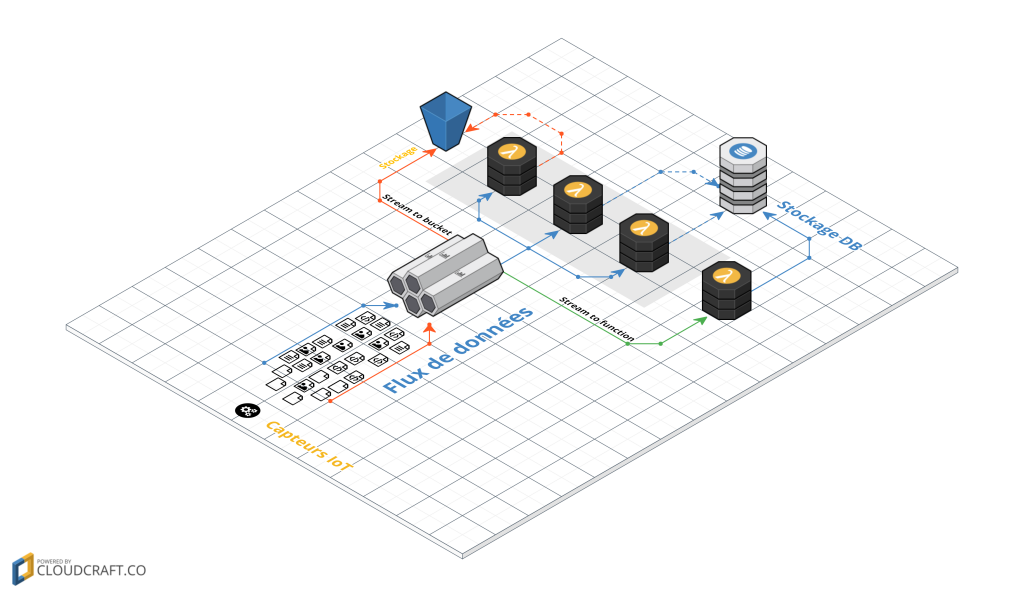
Dans cette architecture nous utilisons des systèmes BaaS pour la gestion des flux de données (exemple : AWS Kinesis ou Google Cloud Pub/Sub) puis des systèmes FaaS pour le prétraitement, le pré-calcul ainsi que l’enregistrement de celles-ci dans une base de données fournis par un système BaaS.
Vous pourrez voir de nombreux exemples d’architectures Serverless édité par Werner Vogels, CTO chez amazon.com sur le lien suivant:
http://www.allthingsdistributed.com/2016/06/aws-lambda-serverless-reference-architectures.html
Qu’est-ce qui ne fonctionne pas en Serverless ?
Jusqu’à présent, j’ai défini le terme Serverless pour signifier l’union de 2 principes – «Backend as a Service» et «Functions as a Service».
Avant de commencer à examiner la promesse que peut offrir ce nouveau type d’architecture, j’aimerais d’abord expliquer ce qui n’est pas Serverless. Actuellement lorsque l’on recherche ce terme, nous pouvons trouver de nombreuses définitions ou assimilations erronées.
#PaaS (Platform as a Service)
On peut en effet trouver des similitudes entre certains services PaaS comme Heroku et les services FaaS, certaines pensent même que FaaS est une extension de PaaS. Mais comme dit Mike Roberts, co-fondateur de l’entreprise Symphonia.
La plupart des applications PaaS ne sont pas destinées à ramener des applications complètes vers le haut et vers le bas pour chaque demande, alors que les plates-formes FaaS font exactement cela. …
La différence opérationnelle clé entre FaaS et PaaS est la mise à l’échelle . Avec la plupart des PaaS, vous avez encore besoin de réfléchir à l’échelle, par exemple avec Heroku combien de Dynos vous souhaitez exécuter. Avec une application FaaS, cela est complètement transparent. Même si vous configurez votre application PaaS à l’échelle automatique, vous ne le feriez pas au niveau des demandes individuelles (sauf si vous avez un profil de trafic très précisément façonné), et donc une application FaaS est beaucoup plus efficace en matière de coûts .
#Container
La conteneurisation subit une popularité croissante de nos jours, surtout depuis l’arrivée de Docker. Nous pouvons en effet trouver certaines similarités entre FaaS et la conteneurisation. Mais rappelons le, FaaS offre une couche d’abstraction telle que nous n’avons plus la notion de processus système au contraire de Docker qui est basé sur du la notion de processus unique.
Parmis ces similitudes, nous retrouvons l’argument de la mise à l’échelle. Fonctionnalité disponible niveau conteneur grâce aux systèmes tels que Kubernetes, Rancher ou Mesos. Dans ce cas nous pouvons nous poser la question du pourquoi faire du FaaS alors que nous pouvons faire du conteneur ?
Il faut savoir que malgré le buzz autour de cette technologie, elle reste toujours immature et de nombreuses entreprises ont encore du mal à basculer leur infrastructure de conteneur en production. De plus les systèmes de mise à l’échelle niveau conteneur est encore loin d’arriver au niveau de celle des FaaS même si cette écart tend à se réduire avec l’arrivée de nouvelles fonctions telles que Horizontal Pod Autoscaling pour Kubernetes.
Finalement, le choix de la technologie se fera selon les cas d’utilisations.
#NoOps
Il ne faut pas confondre Serverless et NoOps. Si on prend le mot Ops (Opérations) cela ne signifie pas uniquement des opérations d’admin systèmes. Cela signifie également au moins le suivi, le déploiement, la sécurité, le réseautage et aussi souvent une certaine quantité de débogage de production et de mise à l’échelle du système. Ces problèmes existent toujours avec des applications Serverless, je dirais même qu’elles sont plus compliquées étant donné la jeunesse de la technologie et les nouvelles fonctions et paramètres à prendre en compte.
Je vous conseille de lire la conversation faite par Charity Majors sur le sujet ici.
La promesse d’une architecture Serverless
Nous verrons dans cette partie la promesse que peut offrir une architecture Serverless. Pour cela nous listerons les avantages et les inconvénients inhérents à celle-ci.
Avantages
Coût opérationnel réduit
Serverless est de nature une solution simple d’externalisation. Il vous permet de payer quelqu’un pour gérer les serveurs, les bases de données et même la logique des applications. Etant donné que votre service fait parti d’un ensemble de services similaires, la notion d’économie d’échelle va alors s’appliquer – vous payez moins cher vos coûts de gestion vu que le même service est utilisé par de nombreux autres ce qui permet de réduire les coûts.
Les coûts réduits apparaissent comme le total de deux notions:
- le coût d’infrastructure
- le coût des employés (opérations / développement).
Alors que certains des gains de coûts peuvent venir uniquement de l’infrastructure de partage (matériel, réseau) avec d’autres utilisateurs, l’attente derrière peut aussi se traduire dans une réduction des coûts liés à l’utilisation du personnel d’exploitation du fait de l’utilisation de technologies managées.
Cet avantage, cependant, n’est pas trop différent de ce que vous obtiendrez en utilisant des technologies de type Infrastructure as a Service (IaaS) ou Platform as a Service (PaaS).
BaaS – Coût de développement réduit
Afin d’illustrer ce point, prenons en exemple le cas de l’authentification. De nombreuses applications codent leur propre service d’authentification et de gestion des utilisateurs, implémentant par la même occasion leur propre niveau de sécurité. Parmis les fonctionnalités implémentées, nous pouvons retrouver :
- L’enregistrement et la validation d’un utilisateur (Enregistrement Suppression)
- La récupération d’un mot de passe
- La connexion et l’accès aux services
Dans l’ensemble nous retrouvons à peu de choses près ces fonctionnalités dans la plupart des applications actuelles. Même si des solutions de type générateurs d’application comme JHipster existent et permettent de générer rapidement plusieurs types d’authentification, il n’en reste pas moins à la charge de l’entreprise de maintenir ce code et de les faire évoluer. A ce jour, nous voyons l’émergence de services tels que Auth0 qui fournissent des fonctionnalités d’authentification “prête à l’emploi”. L’application peut ainsi se décharger de ces fonctionnalités et laisser le fournisseur du service être responsable de leurs maintien.
Un autre exemple qui se prête bien au jeu est l’utilisation de services de base de données tels que Firebase. On retrouve principalement ces cas d’utilisations au sein des architectures mobiles qui préfèrent créer une communication directe entre le client (mobile) et la base de données et ainsi supprimer tous les tiers, et par ce fait l’administration de la base de données et son optimisation. Ce système apporte aussi une nouvelle couche de sécurité et permet ainsi une gestion plus fine des données accessibles en fonction des différents profils utilisateur.
FaaS – Coût de mise à l’échelle
Pour ma part l’un des avantages les plus importants du Serverless est la mise à l’échelle horizontale automatique, élastique et surtout gérée par le fournisseur. Cela peut se traduire par plusieurs avantages, principalement au niveau infrastructure, mais surtout cela permet d’avoir une facturation très fine et de ne payer que la charge dont vous avez besoin, que ce soit en temps de calcul utilisé (à partir de 100 ms pour AWS Lambda) ou en quantité de données récupérées ou analysées. Selon votre architecture et vos Use Cases cela peut engendrer une énorme économie pour vous.
Un des cas d’exemple d’économie est l’utilisation occasionnelle d’une fonction. Par exemple, disons que vous exécutez une application serveur qui ne traite que 1 demande chaque minute, qu’il faut 50 ms pour traiter chaque requête et que votre utilisation moyenne de CPU pendant une heure est de 0,1%. D’un point de vue charge de travail serveur, cela est extrêmement inefficace.
La technologie FaaS capte cette inefficacité et vous permet ainsi de ne payer que ce que vous consommez, c’est-à-dire 100ms (valeur minimum) de calcul par minute, soit moins de 0,5% du temps global.
Pensons optimisations
Même si cette nouvelle architecture propose des nouvelles fonctionnalités telles que la mise à l’échelle, elle n’en subit pas moins les contraintes inhérentes au développement d’applications. Ainsi la phase d’optimisation des fonction prends encore plus de valeurs vu qu’elle permettra, en plus d’améliorer le temps de réponse aux utilisateurs, d’économiser de l’argent sur la facturation. Par exemple pour une opération qui initialement prend 1 seconde et qui après optimisation prend 200ms, nous aurons une réduction immédiate de notre facture de 80% du coût de calculs.
Une informatique plus “verte”
Etant donné que l’écologie est un sujet phare du moment, je ferai un paragraphe dédié à cette partie.
De nos jours, nous avons vu le nombre de datacenters augmenter de plus en plus au fil des années. La consommation en énergie de ceux-ci est énorme et de plus en plus de Cloud providers se sensibilisent à l’écologie et aux énergies renouvelables. Ainsi Google, Apple, … parlent de construire et d’héberger certains de leurs datacenters dans des zones à fort potentiel en énergies renouvelables afin de réduire l’impact sur l’environnement de ces sites.
L’une des causes de cette hausse du nombre de serveurs est due au maintien et à la consommation des serveurs dits “inactifs” face à une demande toujours croissante des entreprises.
Comme le stipule le magazine Forbes
Typical servers in business and enterprise data centers deliver between 5 and 15 percent of their maximum computing output on average over the course of the year.
Ces charges non utilisées viennent principalement de décisions faites par les entreprises sur les capacités nécessaires au fonctionnement d’une application et des “marges de sécurité” faites afin de palier aux fluctuations de charges. Avec une approche Serverless, nous ne prenons plus de décision sur la capacité nécessaire à l’exécution d’une fonctionnalité, cette charge revient désormais aux fournisseurs du service. Il se doit de fournir une capacité de calcul suffisante pour nos besoins en temps réel. Il pourra ainsi avoir une vision globale des capacités nécessaires pour l’ensemble de ces clients. Ils pourront par ce biais optimiser la gestion des ressources et permettre une réduction du nombre de serveurs et en conséquence l’impact environnemental des datacenters.Cela représente un fonctionnement extrêmement inefficace et surtout un impact environnemental non négligeable.
Les inconvénients
Et oui nous ne sommes pas là que pour vanter les mérites de cette nouvelle technologie et dire qu’elle peut résoudre tous nos problèmes (on compare d’ailleurs souvent celle-ci par un arc-en-ciel et une licorne). Comme toute technologie, elle vient aussi avec son lot d’inconvénients qui ne sont pas à prendre à la légère car ceux-ci pourrait devenir votre pire cauchemar selon vos Use Cases.
Il faudra toutefois séparer ces inconvénients en 2 types, ceux inhérents à ces nouvelles architectures et cette technologie et ceux qui ont pour origine sa jeunesse et son manque d’outillages et de solutions.
Verrouillage des Cloud Providers
Le premier et pas des moindres pour moi est la dépendance forte que l’on crée avec le fournisseur de service. A ce jour aucune spécification n’est sortie afin d’adopter un langage commun entre les fournisseurs. Même si certains frameworks (Serverless.io) essaient de briser ces limitations, lors de la conception de votre solution et du choix des fonctionnalités, vous devrez faire le choix d’un fournisseur unique afin de garantir une certaines homogénéité de communication entre les différentes couches et pour palier au vérouillage que les fournisseur font de leurs services. Par exemple pour la liaison API Gateway > AWS Lambda, vous êtes contraint d’utiliser les 2 technologies AWS pour garantir son fonctionnement. Vous pourrez toujours trouver des passerelles afin d’utiliser plusieurs fournisseurs de services différents (Authentification via Auth0, DB via Firebase et API + Lambda via AWS) mais dans ce cas, cela compliquera fortement l’administration et la facturation de votre solution.
Il en va de même pour le code utilisé au sein des fonctions, il est propre à chaque fournisseur et il vous faudra donc prévoir un coût de réécriture lors de son changement.
Optimisations des serveurs
A partir du moment où vous décidez d’utiliser des technologies Serverless, vous abandonnez par ce fait le contrôle de certains systèmes tiers et de leur configuration. Même si cette gestion par le fournisseur vous conviendra dans 99% des cas, il reste 1% des cas ou votre solution nécessitera d’avoir une configuration spécifique du service afin d’améliorer ses performances ou une meilleure qualité de services.
Sécurité
Je ne pouvais pas écrire un article sur le Serverless sans parler de la sécurité de cette technologie. De nombreuses entreprises se sensibilisent de plus en plus aujourd’hui à la sécurité de leurs applications et à l’accès à leurs données. Les services Serverless ne vont pas échapper à la règle et vont apporter leur lot de questions. Je vais tenter d’en expliquer 3 mais de nombreuses autres sont à considérer.
- En sécurité, on parle souvent de périmètre ou de surface d’action d’une solution. Cela correspond à l’empreinte que celle-ci à sur Internet. Plus l’empreinte est grande, plus la surface d’attaque est importante. Or l’utilisation de plusieurs services Serverless va augmenter votre empreinte et créer une certaine hétérogénéité dans vos politiques de sécurité. Par ce fait vous augmenterez votre probabilité d’intention malveillante à l’encontre de votre solution et la probabilité qu’une de ces attaques soit réussie.
- Si vous utilisez le service de base de données de type BaaS et permettez l’accès direct à vos données via une API cliente, vous perdrez la barrière de protection qu’une application serveur traditionnelle peut fournir de part sa configuration réseau ou ses restrictions d’accès au serveur. Cependant, même si ce problème n’est pas une fin en soi, il est à prendre en compte lors de la conception de votre application.
- De part le fait que les services que vous utilisez sont mutualisés, vous héritez des problématiques de sécurité inhérente au service multi tenant. Par exemple l’accès aux données d’autres clients du fait du partage des processus.
Problèmes à l’utilisation
Passons maintenant aux inconvénients inhérents aux solutions actuellement disponibles. Ceux-ci pourront en effet être corrigés avec l’évolution de la technologie et de l’écosystème qui l’entourent.
Durée d’exécution
Un problème actuel concerne la limitation faite sur la durée d’exécution des fonctions. Actuellement nous avons une durée limite de 5min pour AWS et 9min pour Google Cloud. Cette contrainte restreint le périmètre d’actions des fonctions et ainsi empêche leur utilisation pour un grand nombre de Use Cases comme le traitement vidéo par exemple.
Latence de démarrage
Un autre inconvénient que certaines implémentations de FaaS provoquent est la latence au démarrage. En plus du temps d’exécution de la fonction, vient s’ajouter une latence pouvant aller jusqu’à 10 secondes selon les cas de figure (exemple lors de l’utilisation d’une JVM ou lors d’un premier lancement). C’est pourquoi certains fournisseurs comme Google contraignent le langage de développement de leurs fonctions et ainsi permettent uniquement l’utilisation du Javascript (ce qui se comprend vu les performances de leur moteur).
De même nous pouvons observer des latences réseaux lorsque l’on met en série plusieurs fonctions lambda.
Tests
Vu que l’on parle beaucoup de développement il en est de même pour les tests. Même si certains pensent que “Tester c’est douter”, nous nous devons de traiter ce point, d’autant plus qu’il s’agit d’un lourd inconvénient lors de l’utilisation de ce type de services.
Certains peuvent penser qu’en raison de l’isolation de chacune des fonctions, il peut être relativement facile de les tester. Ceux-là ont raison pour le périmètre des tests unitaires vu qu’il s’agit simplement d’un bout de code, cependant lorsque l’on aborde le sujet des tests d’intégration c’est une autre paire de manches. De nouvelles notions et questions vont alors apparaître venant principalement du fait que vous dépendez de services externes (base de données, authentification). Nous pouvons nous interroger sur leur périmètre et sur la pertinence d’effectuer ces tests bout en bout. Si tel est le cas, est ce-que ces services sont compatibles avec vos scénarios de tests comme la gestion des états avant et après ? De plus, est-ce qu’une grille de coûts spécifique est prévu par les fournisseurs lors de tests de charge par exemple ?
Si votre volonté est au contraire de vous soustraire à ces services temporairement, il vous faudra alors des systèmes de stub local qui ne sont pas forcément fournis par le fournisseur. Sur ce point, Google se différencie des autres par le fait que ses solutions sont généralement basées sur des systèmes Open Source, de ce fait l’écosystème qui gravite autour fournit assez rapidement des moyens de stub ces services. D’autres questions apparaissent alors sur le niveau de confiance que l’on peut avoir dans ces stubs et s’ils ne sont pas fournis, comment faire pour les implémenter.
Il en va de même pour l’intégration des services FaaS. Il est encore difficile de trouver une implémentation locale de la structure qui embarque les fonctions. Il va donc falloir utiliser directement l’environnement final. Même si des notions de staging permettent de séparer l’utilisation en test de l’utilisation en production, celles-ci ne s’appliquent pas à tous les services.
Déploiement et versionning
Actuellement aucun pattern probant n’est sorti sur la phase de packaging et déploiement. C’est pourquoi nous avons rapidement des contraintes sur le déploiement atomique des fonctions. Prenons le cas d’une série de fonctions qui s’exécutent, afin de garantir un déploiement uniforme, il va falloir arrêter votre service à l’origine des événements de déclenchement, puis livrer l’ensemble de vos fonctions pour ensuite activer de nouveau le service. Cela peut représenter un problème important pour les applications nécessitant de la haute disponibilité. Il en va de même pour le versionning “applicatif” et la phase de rollback.
Supervision
A ce jour les seuls solutions possibles pour effectuer la supervision et le débogage de vos fonctions sont celles fournies par votre fournisseur et il faut se le dire, elles ne sont pas encore au niveau attendu. Même si des efforts énormes sont faits comme avec la sortie en preview de AWS X-Ray, il reste encore du chemin à parcourir afin d’avoir une solution complète et spécifique FaaS.
Conclusion
Nous avons vu dans cet article que l’approche Serverless peut en effet apporter beaucoup de simplification et d’avantages mais ce n’est pas la solution miracle à tous les problèmes. Il faut bien étudier au préalable ses Use Cases et ses contraintes afin de pouvoir peser le pour et contre de cette nouvelle technologie.
Il faut aussi retenir qu’à ce jour la technologie Serverless est relativement jeune. A titre d’information, la technologie AWS Lambda existe uniquement depuis 2 ans et les Google Functions viennent tout juste de sortir de la phase Bêta. Nous avons donc peu de REX réels sur des architectures Serverless massives c’est pourquoi nous avons simplement exposé les promesses qu’elle a à nous offrir. Mais nous pouvons supposer un avenir radieux à cette technologie vu l’effervescence des acteurs autour de celle-ci et l’émergence chaque jour de nouveaux systèmes ou frameworks qui nous permettrons une utilisation et une supervision simplifiée.
Dans un prochain article nous détaillerons plus précisément Comment faire du Serverless et nous expérimentons certaines de ces technologies et frameworks avec des cas concrets d’utilisation.
