

Kafka Streams est un terme que l’on entend de plus en plus souvent dans l’écosystème des applications de stream-processing. Nous allons voir dans cet article quels sont les avantages que présente cette librairie. Puis nous allons illustrer ces avantages dans un cas d’utilisation simple.
Kafka Streams, mais encore ?
Il s’agit d’une librairie Java dont le but est de traiter ou d’analyser les données présentes dans Kafka, puis de les faire ressortir dans un nouveau topic Kafka ou dans un service externe (une base de données, par exemple).
Disponible depuis la version 0.10 de Kafka, cette librairie fait de plus en plus parler d’elle grâce à ses nombreux avantages :
- Aucune dépendance externe autre que Kafka
- Librairie simple et légère
- Fault-tolerant et scalable
- Traitement de la donnée event-time (contrairement aux approches micro-batch)
- Ajout de ressources à chaud
- Mécanisme de reprise en cas de panne
Fonctionnement et avantages
Tout comme la librairie Producer et Consumer de Kafka, Kafka Streams est une simple dépendance Maven à placer dans un code Java et n’a besoin d’aucune installation supplémentaire autre qu’un cluster Kafka.
Simplicité
Poussée par Confluent depuis mars 2016, cette librairie se veut simple et performante à la fois, tout en proposant une API haut niveau permettant de manipuler les flux avec des fonctions telles que map, filter, count proposées depuis Java 8 et une API bas niveau permettant d’obtenir une plus grande flexibilité. Les développeurs familiers avec Java 8 n’auront aucun mal à se plonger dans la librairie et à développer leur première application rapidement.
L’API se veut simple au niveau de l’installation et du déploiement. Au niveau de l’installation, une simple dépendance Maven suffit pour pouvoir utiliser l’API dans un IDE. Au niveau du déploiement, les applications Kafka Streams se connectent au cluster Kafka défini dans les propriétés de l’application et se lancent via une ligne de commande Java , contrairement aux frameworks de stream processing (Spark, Storm, Flink, etc.) qui doivent tous être déployés d’une façon particulière dans leur cluster dédié.
Performance
En plus de proposer une installation simple et rapide, l’API proposée par Confluent offre de très grandes performances car elle utilise les mécanismes de Kafka et son système de partitionnement pour consommer les évènements; ceci garantit une grande performance des applications, une scalabilité ainsi que l’ordre d’arrivée des données.
De plus, la particularité clé de cette librairie réside dans son architecture. La plupart des applications de stream processing classiques nécessitent l’installation d’un cluster dédié au traitement de la donnée en plus de Kafka (Kafka + Spark streaming par exemple), comme les applications Kafka se lancent via une ligne de commande, les ops et les développeurs n’auront plus à monter, maintenir et tuner un cluster supplémentaire en plus de Kafka.
De même, toutes les améliorations faites dans un cluster Kafka se feront ressentir au niveau de Kafka Streams. Enfin, l’emploi du traitement de la donnée event-time au lieu de micro-batches assure un temps de latence du traitement de la donnée extrêmement faible.
Et la panne ?
La librairie est basée sur la tolérance à la panne embarquée dans Kafka, les partitions se veulent hautement disponibles et répliquées. Cette réplication permet, en cas de panne, de redémarrer une tâche à partir de son “point-of-failure” dans une instance déjà existante.
Sous le capot, Kafka Streams écrit ses données dans un changelog, il s’agit d’un fichier persisté sur le disque écrit de façon séquentielle au fur et à mesure que la donnée arrive et utilise un mécanisme de compactage basé sur la dualité entre les flux et les tables.
Kafka Streams introduit ainsi trois notions dans son API haut-niveau, les KStreams, les KTables et les GlobalKTables. Sans nous plonger dans les détails, nous allons prendre un cas d’utilisation simple basé sur l’open data de Meetup, afin d’illustrer les principes de base de l’API.
Mise en œuvre
Dans cette section, nous allons créer une application permettant de suivre en temps réel l’évolution du nombre de personnes inscrites à un Meetup dans une ville. Nous allons partir du flux JSON envoyé par l’open data de meetup, où chaque entrée représente une inscription à un Meetup. Puis nous allons faire une agrégation sur la ville afin d’obtenir, en sortie du flux, un schéma clé / valeur constamment mis-à-jour de cette forme :
(ville -> nombre d’inscrits à un Meetup)
Avant toute chose, commencez par installer une instance Kafka sur votre machine en suivant les deux premiers steps décrits dans la documentation Kafka officielle.
Ensuite, créez un topic meetup
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic meetup
Afin de pouvoir traiter le flux de données que nous allons recevoir, nous devons créer un producer permettant de “faire rentrer” le flux dans le topic ainsi créé. Pour ce faire, ouvrez un nouveau terminal. Clonez ensuite le répertoire Git contenant le producer à l’aide de la commande :
git clone https://github.com/Wconti/kafka-meetup-producer
Placez-vous dans le répertoire cloné, puis lancez le producer :
java -cp target/meetup-producer-1.0-SNAPSHOT.jar com.wconti.app.Producer localhost:9092
Vous allez ensuite pouvoir observer le flux de données dans la console consumer de Kafka en lançant la commande suivante dans le répertoire de votre installation Kafka :
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic meetup
Vous devrez obtenir l’affichage suivant :
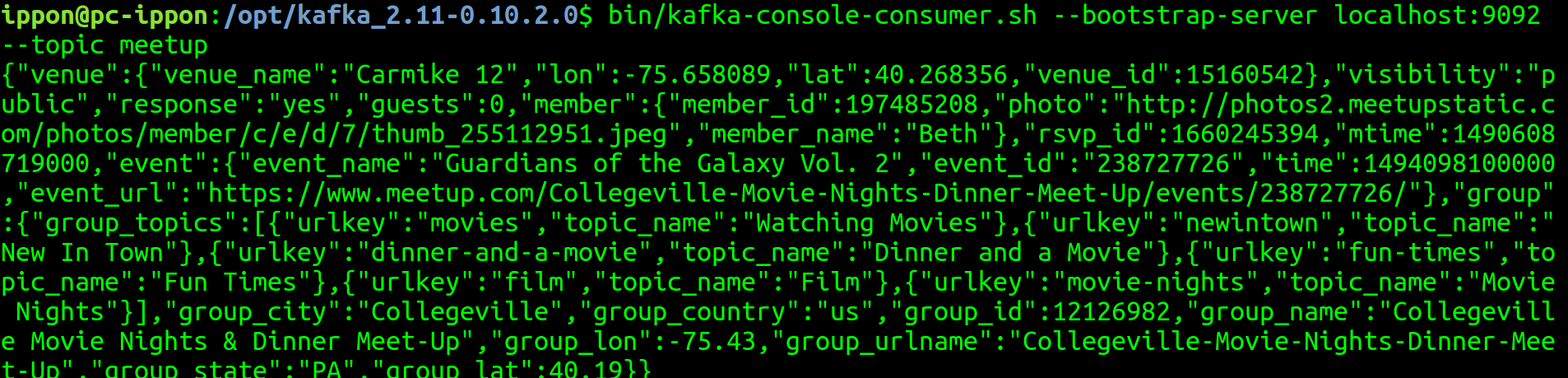
Maintenant que nous avons configuré le producer, nous allons pouvoir rentrer dans le vif du sujet. Le code suivant va vous permettre de récupérer le topic meetup-out. Puis il va faire une petite transformation afin de récupérer uniquement le champ group_city correspondant à la ville d’une entrée. Enfin, il exécute une agrégation et envoie le tout dans un topic testout.
Voici tous les éléments nécessaires à la création de notre application.
Tout d’abord, nous devons définir un objet StreamsConfig. Cet objet va contenir toute la configuration nécessaire au bon fonctionnement de notre application.
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "my-first-stream-application");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
StreamsConfig streamingConfig = new StreamsConfig(props);
Nous allons ensuite instancier un objet KStreamBuilder qui va nous permettre de définir la logique de notre application. Puis nous allons récupérer le contenu du topic meetup.
KStreamBuilder builder = new KStreamBuilder();
KStream<String,String> stream = builder.stream("meetup");
Notre objet stream contient tout le contenu du topic meetup qui est un flux Json. Nous allons maintenant appliquer la transformation nécessaire afin d’arriver au résultat souhaité.
stream
.map((key,value) -> {
JsonObject meetup = jsonParser.parse(value.toString()).getAsJsonObject();
String city =meetup.get("group").getAsJsonObject().get("group_city").getAsString();
return KeyValue.pair(city,city);
})
.countByKey("table")
.to(stringSerde,longSerde,"meetup-out");
Pour chaque message que nous recevons dans notre stream, nous allons récupérer le champ group_city et le mapper à la fois en tant que clé et valeur. Une fois cette transformation effectuée, nous pouvons utiliser la méthode countByKey, qui va compter le nombre d’occurrences de chacune des villes et convertir le résultat en tant qu’une KTable<String,Long> // (ville -> nombre). Nous pouvons ainsi utiliser la méthode to, en faisant attention à appliquer un serializer identique à celui de notre message (String,Long). Nous diffusons ensuite le résultat dans le topic meetup-out.
Nous devons enfin déclarer notre application, puis la lancer.
KafkaStreams streams = new KafkaStreams(builder, streamingConfig);
streams.start();
Il suffit simplement d’instancier un objet KafkaStreams, qui prend dans son constructeur le builder que nous avons codé plus tôt, puis la configuration du stream. Un appel à la méthode start permet d’envoyer le tout !
Simple non ?
Il ne manque plus qu’à packager notre application et à la lancer via une commande Java.
Voici ce que donne la sortie de ce programme en faisant pointer la console consumer de Kafka dans le topic meetup-out.
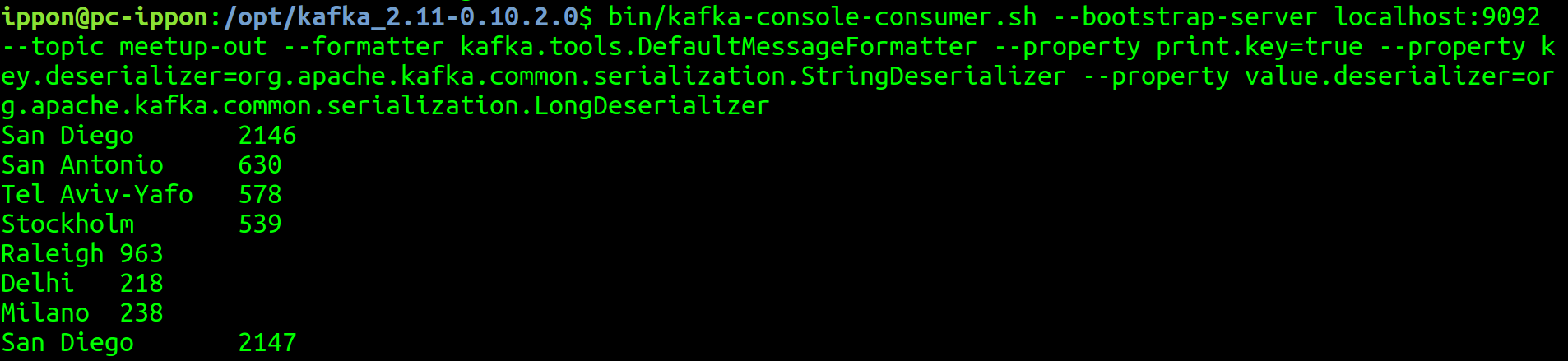 Nous pouvons observer en temps réel l’évolution du nombre d’inscrits à un meetup par ville
Nous pouvons observer en temps réel l’évolution du nombre d’inscrits à un meetup par ville
Remarque : les doublons présents pour San Diego sont une démonstration du flux continu d’updates qu’est notre application ainsi que l’évolution de l’état de la KTable définie plus tôt pour la clé San Diego.
Vous pouvez retrouver cet exemple sur ce github et suivre les instructions pour son lancement.
Pour conclure
Les nombreux avantages de Kafka Streams lui permettent de rapidement faire sa place dans l’écosystème du stream-processing. Sa facilité de mise en place va ravir de nombreux développeurs réticents à l’idée de devoir installer un cluster Kafka ainsi qu’un autre cluster dédié au traitement de données. De plus, la possibilité de déployer une application Kafka Streams via Puppet, de la packager via Docker ou encore de la scaler via Kubernetes redonnera le sourire à de nombreux ops 🙂
Cependant, notons que la légèreté de l’API ne lui permet pas de répondre à des besoins bien plus complexes comme de l’apprentissage pour des modèles de machine learning.
