

Ce mercredi 28 juin, j’ai eu la chance de participer au tout premier Paris Container Day, organisé par Xebia dans le magnifique restaurant Elyseum privatisé pour l’occasion. Durant cette journée, nous avons pu assister à différents talks ou hands-on autour des technologies de containerisation. Vous avez pensé « Docker » ? Oui, mais pas que !
À travers la keynote, animée par Pablo Lopez, directeur technique de Xebia, nous avons bien intégré que les containers étaient devenus un standard de facto au cours des 3 dernières années. Bien évidemment, le concept de « container » existe depuis longtemps, mais il a été largement démocratisé avec l’apparition de Docker. Au début de son existence, Docker a tout d’abord suscité la curiosité, entraînant les développeurs à faire des essais en local, parfois très exotiques, pour connaître les possibilités de ce nouvel outil. Il faudra compter une bonne année, avant de vraiment voir des containers en production et encore une année avant qu’il soit massivement adopté. Seulement, faire tourner une dizaine de containers sur 2 serveurs, ou plusieurs milliers de containers sur du cloud, ça ne demande pas les mêmes efforts pour le déploiement, la supervision ou encore le maintien en conditions opérationnelles.
La stratégie et les enjeux ne sont plus aujourd’hui de savoir quelle technologie de containers utiliser, mais plutôt de la manière dont ils vont être déployés, provisionnés, multipliés, mis à jour ou encore surveillés.
C’est ainsi que sont apparus les « orchestrateurs », magnifiques outils nous permettant de nous abstraire complètement de l’infrastructure — « J’ai besoin de faire tourner en permanence 10 instances de mon container : débrouille toi, mets les où tu veux, je ne veux pas le savoir ! » — ou de la perte de ressources — « Un serveur qui abritait des containers est mort ? Pas de problème, ils ont été créés ailleurs ». — Aujourd’hui, les 3 orchestrateurs principaux sont : Docker Swarm (Docker), Kubernetes (initialement développé par Google), Mesos/Marathon (Apache/Mesosphere).
La journée s’annonce bien, remise dans le contexte efficace et de nombreuses conférences sur tous ces sujets en perspective. Ne pouvant pas ici détailler l’intégralité des conférences auxquelles j’ai assisté, je vous propose un petit feedback par « produit » et plus particulièrement sur Kubernetes et Mesosphere.
Quoi de neuf chez Docker ?
La DockerCon 2016 à Seattle vient de se terminer. Jean-Laurent de Morlhon était donc là pour nous présenter les nouveautés de Docker et les faits marquants. En plus d’une remise dans le contexte de la stratégie de Docker, “qui n’est pas de changer le monde, mais de vous permettre de le faire”, puis de l’annonce d’un “Docker Store” permettant de rechercher des images officielles, voici les deux principaux sujets que j’ai retenu.
Docker Desktop
Travaillant sur Linux, j’avoue ne pas être directement impacté par cette annonce, mais elle me parait être de taille. Les versions Windows et Mac de Docker sont officiellement disponibles en version Beta. L’idée est d’uniformiser l’expérience utilisateur, quelle que soit la plateforme utilisée. Il ne sera donc plus nécessaire d’utiliser vagrant ou docker-machine pour lancer des containers sur vos machines.
Docker 1.12
Autre annonce de taille : la sortie de Docker 1.12. Pour la gestion des clusters, Docker proposait un outil externe appelé Swarm. Désormais, Swarm est directement intégré dans le deamon Docker. Avec lui viennent également les mécanismes de gestion et de découverte des services, ainsi que de la sécurité. Il n’est plus nécessaire de tout mettre en place manuellement (cluster Consul pour le stockage des informations, ajout d’un agent Swarm sur les serveurs, etc.), Docker s’en charge pour vous, fini les dépendances externes.

Merci à Jean-Laurent de Morlhon pour sa conférence : Retour de la DockerCon 2016, les faits marquants.
Les slides disponibles ici : https://speakerdeck.com/jeanlaurent/retour-sur-dockercon-2016
De Borg à Kubernetes
Un peu d’histoire
Google utilise des containers depuis de nombreuses années et aujourd’hui en démarre plusieurs milliers par semaine. Chez eux, tout est containerisé (Search, Maps, Gmail, etc.).
Pour gérer leur parc de containers, ils utilisent un outil interne appelé Borg. Schématiquement, un agent « borglet » est installé sur chacun des nœuds (physiques ou virtuels) et communique avec un « Borg master ». Ainsi, le master est informé en permanence par les agents de l’état des différents nœuds (CPU, RAM, disques, containers démarrés, etc.). Et inversement, il est capable d’envoyer des instructions aux agents pour qu’ils démarrent ou arrêtent des instances de container.

Leur outil étant trop lié à l’infrastructure et aux spécificités de Google, ils ont décidé de réécrire un nouvel orchestrateur open source conservant les concepts de base : Kubernetes. Afin d’éviter de trop diverger ou de le rendre spécifique, Google a cédé la propriété de Kubernetes à la CNCF (Cloud Native Computing Foundation) qui est désormais garante du respect des standards.
Merci à Alexis Moussine-Pouchkine pour sa conférence : Kubernetes, votre assurance-vie pour le Cloud.
Les concepts
Kubernetes utilise un ensemble de concepts et de mots clés, qu’il faut nécessairement comprendre avant de commencer.
- Node: serveur physique ou logique sur lequel est installé l’agent Kubelet,
- Pod: plus petite unité logique dans Kubernetes. Il peut être composé de 1 ou plusieurs containers,
- Labels: il est possible de définir un ensemble de clés/valeurs sur chacun des composants de Kubernetes (pod, service, …). Il sera possible de regrouper les éléments en fonction de leurs labels (Selector). Par exemple, on pourra labelliser les nodes « role:front », « role:bdd » ou les pods « version:v2 »
- Service: défini un ensemble de pods et leur assigne un nom par lequel y accéder (DNS)
- Replication Controller : assure que le nombre d’instances spécifié d’un pod correspond bien au nombre d’instances démarrées sur le cluster. Sinon, il arrêtera ou démarrera automatiquement des instances du pod concerné.
Ainsi, en jouant avec ces concepts, il est très facile d’augmenter ou de diminuer le nombre d’instances de chaque container, d’interroger un container d’un certain type sans savoir où il est ni même lequel est appelé, ou encore de mettre à jour les applications sans interruption de service.
Kubernetes est également capable de gérer l’auto-scalling ; c’est à dire qu’en fonction de seuils définis sur un pod (CPU > 90 %, RAM > 90 %, …), Kubernetes pourra démarrer automatiquement de nouvelles instances de ce pod afin de lisser la charge.
Merci à Cedric Hauber, Matthieu Parisot et Yann Lambret pour leur hands’on : Kubernetes par l’exemple avec une magnifique application sur l’euro 2016 (dois-je dire que l’Espagne a gagné pendant le hands-on ?).
Etcd
Pour la plupart des applications distribuées, il est nécessaire de mettre en place un espace de stockage de type clé/valeur afin de persister l’état du cluster. Kubernetes se base sur etcd pour stocker l’intégralité des informations du cluster (nodes, pods, etc.).
Durant sa conférence, Jonathan Boulle de chez CoreOs, nous a parlé, entre autres, des gros efforts de performance sur la v3 d’etcd par rapport à la v2. Il a également indiqué que malgré les améliorations, ils ne sont pas encore au niveau de Zookeeper qui obtient les meilleurs scores en terme de vitesse de lecture et d’écriture par rapport à consul, etcd2 et etcd3, si on considère que ces outils sont vraiment comparables.
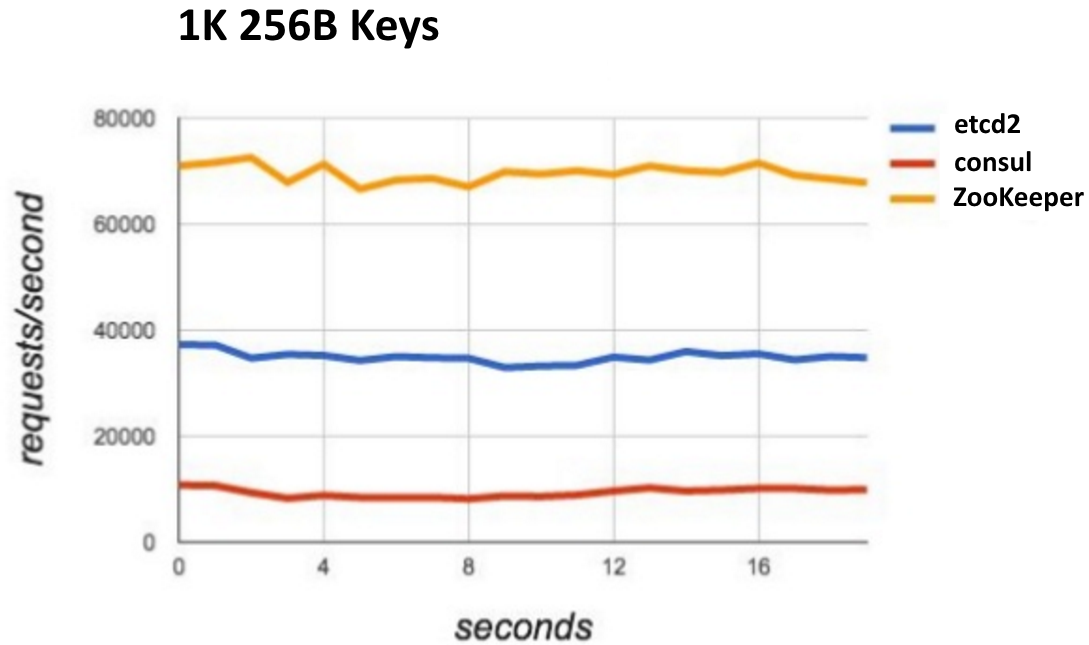
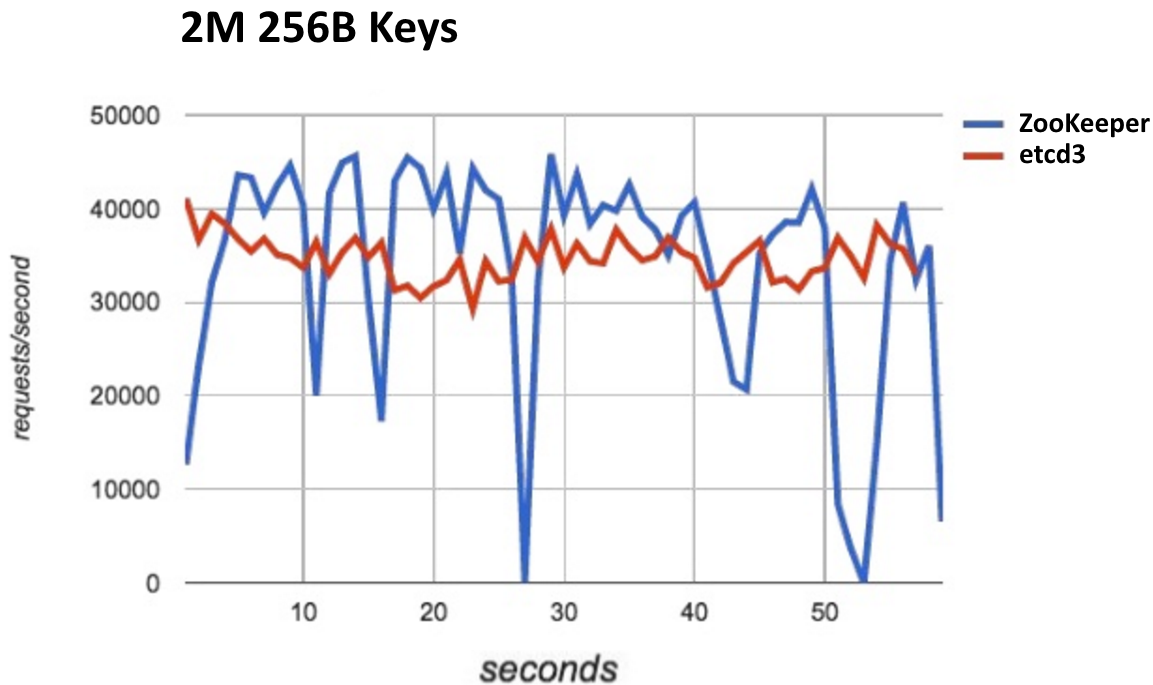
Merci à Jonathan Boulle pour sa conférence : How CoreOS sees the container industry.
Slides disponibles ici : http://fr.slideshare.net/CoreOS_Slides/etcd-mission-critical-keyvalue-store
Mesosphere : gérons des ressources plutôt que des nœuds
Contrairement à Kubernetes, la volonté de Apache Mesos est de gérer un ensemble de machines comme si elles ne constituaient qu’une seule et même machine. Cette application permet de créer une sur-couche aux différents OS installés sur les serveurs d’un cluster afin de s’abstraire de la notion de machine et de ne gérer qu’un ensemble de ressources comme s’il s’agissait d’un cloud privé. Il est ainsi possible de démarrer un service, lancer une commande, ou exécuter un script sur le cluster, sans avoir à connaître le serveur réellement utilisé.
Tout comme Kubernetes, Mesos fonctionne grâce à un agent déployé sur l’intégralité des nœuds du cluster (appelé Mesos-Slave) qui communique avec un agent (Mesos-Master) déployé sur des nœuds « Master ». Il est très largement conseillé de ne pas cumuler les fonctions “slave” et “master” sur le même noeud. Les serveurs masters devraient être exclusivement dédiés à la gestion du cluster. En revanche, c’est Zookeeper qui est utilisé pour le stockage des informations fournies par les agents Mesos, stockage distribué clé/valeur qui a largement fait ses preuves. Afin de diminuer les risques d’erreur (arrêt d’une machine par exemple), il est recommandé de monter un cluster d’au moins 3 masters. Mesos recense donc au travers de ses agents l’intégralité des ressources disponibles. Si vous voulez commencer à déployer des containers Docker, Mesos n’est pas suffisant, vous aurez besoin de l’application Marathon.
Marathon
Marathon est le véritable « orchestrateur » de services tournant sur un cluster Mesos. Sur l’interface de Marathon, il est donc possible de créer des « applications » avec tout un tas de paramètres tels que les limites de CPU et de RAM, le container Docker à utiliser ou le service à démarrer, comment vérifier qu’il est en bonne santé, ou encore le nombre d’instances que l’on souhaite faire tourner. Marathon va communiquer avec les masters du cluster Mesos, afin que ces derniers gèrent toutes les opérations. Mesos se chargera de répartir la charge sur les différents slaves, alors que Marathon surveillera l’état du cluster au travers des APIs de Mesos et demandera l’arrêt ou le démarrage d’applications en fonction des paramètres de scalabilité saisis.
À la différence de Mesos, sous licence Apache et entièrement maintenu par la communauté, Marathon est une application open source poussée par la société Mesosphere. Cette dernière propose une solution open source complète de gestion de plateforme évolutive (cloud privé) basée sur Mesos : baptisée DC/OS. Plus qu’un outil, DC/OS est un système d’exploitation distribué sur un cluster. En plus des fonctionnalités des Mesos, DC/OS permet de faciliter les déploiements et l’isolation de services stateless ou de containers, gérer la communication entre les services ou encore permettre du load balancing.
Minimesos
Développer un système d’exploitation distribué c’est une chose, mais ça demande un peu plus de configuration que simplement l’ajout d’un agent sur une machine. Comment faire pour tester sur un environnement local les possibilités de DC/OS. Pour ce faire, Mesosphere a mis à disposition “Minimesos” qui permet d’installer et d’auto-configurer les différents outils de la stack en une fois, sur son poste de développement.
Merci à Alex Rukletsov pour sa conférence : How cluster managers affect the landscape of modern distributed computing—why we decided to open source DC/OS
Merci à Philip Norman et Franck Scholten pour leur conférence : Deep dive into one of the application of DCOS : Velocity
Continuous Delivery avec Jenkins 2
Je ne pouvais terminer cet article sans évoquer la brillante intervention de Nicolas De Loof qui est venu nous parler de déploiement continu avec Jenkins 2.
D’apparence, rien de révolutionnaire avec cette nouvelle version. Et pourtant… Fini le clickodrome, place aux scripts Groovy et aux pipelines ! Vous pouvez désormais définir les différentes étapes de votre build dans un seul fichier de configuration, sans avoir besoin de créer plusieurs jobs s’enchaînant les uns les autres. Pour ceux qui ne l’auraient pas déjà fait, je vous invite à regarder sa conférence au Devoxx France 2016 (disponible ici : https://www.youtube.com/watch?v=ij1-MNcRBSQ).
“Mais c’est le container day, quel est le rapport avec Jenkins ?” “Facile, il y a un plugin pour tout !”. Nous avons donc pu découvrir que Jenkins possède également des plugins Docker, permettant de générer une image, ou bien de construire son projet directement dans un container (afin par exemple de s’assurer que les composants nécessaires au build soient dans des versions maîtrisées). Et grâce à Philip Norman, nous savons également qu’il existe un plugin pour Marathon, qui permet de déployer le container généré directement sur le cluster Mesos.
Merci à Nicolas De Loof pour sa conférence : Évolution du Continuous Integration/Continuous Delivery avec l’émergence des conteneurs et leurs évolutions.
Pour finir, je souhaiterais remercier tous les speakers que je n’ai pas cité, qui sont venus partager leurs connaissances, leurs compétences et leurs expériences sur les containers.
Félicitations à tout le monde !
