
MongoDB v3 : Les benchmarks

Dans un premier article, nous avons passé en revue la liste des nouveautés de la version 3 de MongoDB. Cette version est sortie officiellement le 4 mars 2015.
Cette version 3 de MongoDB est très attendue, notamment pour les améliorations des performances et du volume de stockage nécessaire.
Pour rappel, MongoDB v3 est livré avec deux moteurs de stockage :
- Une évolution du moteur de stockage historique : MMAPv1,
- WiredTiger : issu du rachat de l’entreprise éponyme.
Contrairement aux précédentes versions, le fonctionnement des verrous a évolué :
- MMAPv1 : lock au niveau collections,
- WiredTiger : lock au niveau document.
Dans cet article, nous allons effectuer plusieurs benchmarks afin de mesurer, sur des cas précis, les gains réels en termes de performances.
Nous allons utiliser :
- MongoDB v2.6.7 comme base de référence.
- MongoDB v3 MMAPv1.
- MongoDB v3 WiredTiger.
Voici, sur le papier, ce à quoi nous pouvons nous attendre au niveau des performances.
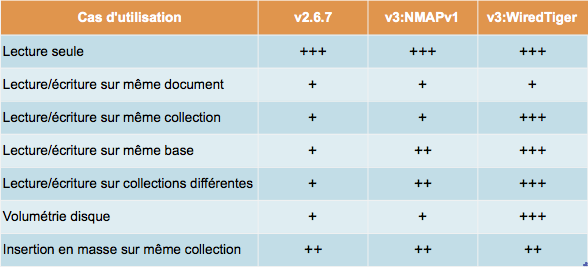
Versions logicielles
Tous les tests se baseront sur les versions suivantes :
- MongoDB v2.6.7
- MongoDB 3.0 rc8
- Driver java 2.13.0
NB : depuis les tests, la dernière version Release Candidate était la RC10 et la version officielle (v3 GA) est sortie le 4 mars. Enfin MongoDB v2.6.8 est la dernière version de la branche v2.
Le benchmark 1 : YCSB
Ce benchmark (Yahoo! Cloud Serving Benchmark) a été développé par les équipes de Yahoo afin de mesurer les performances des solutions de stockage diverses telles que :
- SGBD : toutes (celles disponibles avec driver JDBC)
- NoSQL : MongoDB, Redis, Cassandra, HBase, …
- Grille de données mémoire : Infinispan, GemFire.
La liste des tests est au nombre de 6.
Workload A : mises à jour de masse
- 50% lectures
- 50% écritures
Cas typique d’utilisation : stockage d’un panier d’une application e-commerce.
Workload B : majoritairement lecture
- 95% lectures
- 5% écritures
Cas typique d’utilisation : affichage avec parfois mise à jour d’une information d’un dossier client.
Workload C : lectures seules
- 100% lectures
Cas typique d’utilisation : affichage de données provenant d’un autre système.
Workload D : read latest workload
- Insertion de nouvelles données
- Ces données sont lues massivement
Cas typique d’utilisation : mise à jour de données affichées (lues) en temps réel.
Workload E : short ranges
Dans ce test, chaque thread requête un ensemble de données (par une query) et non plus individuellement.
Cas typique d’utilisation : affichage d’une multitude de données (type “tableau de bord”).
Workload F : read-modify-write
Dans ce test l’enchaînement est le suivant :
- le client lit un document,
- le client modifie le document,
- le client sauvegarde le document.
Cas typique d’utilisation : formulaire d’affichage et de modification d’une donnée.
Configuration du benchmark
- YCSB utilise une seule collection pour les tests.
- Nombre de threads : 8
- Nombre de documents : 1 million
- Nombre d’opérations : 1 million
- Taille des documents : 1 ko (paramètre inchangé)
- Chaque document est constitué de 10 champs binaires (100 octets) et d’une clé constituée d’un champ fixe (user) et d’une séquence
- Write_concern MongoDB : Safe
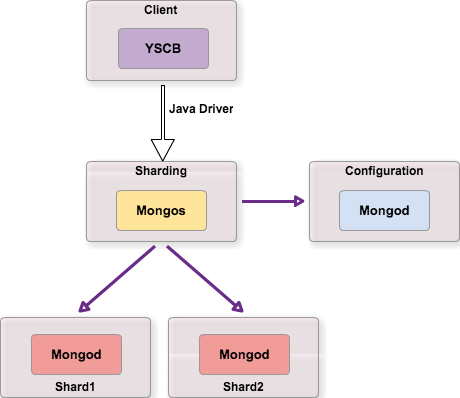
Architecture de test
Pour ce premier test nous avons choisi une architecture de type sharding, typique des architectures à forte sollicitation, mais sans ReplicaSet afin de faciliter la mise en œuvre des tests et parce que l’aspect disponibilité ne nous intéresse pas ici.
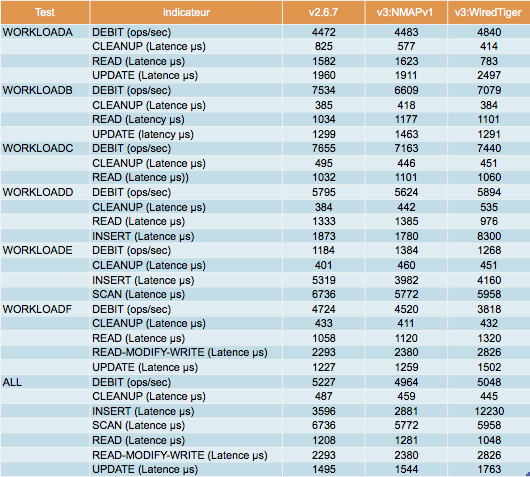
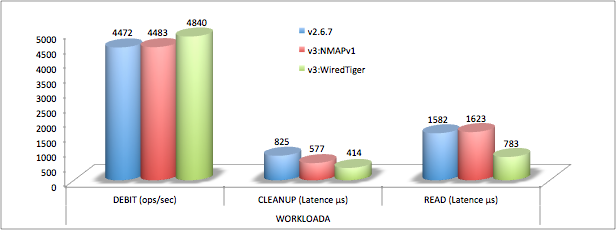
Résultats
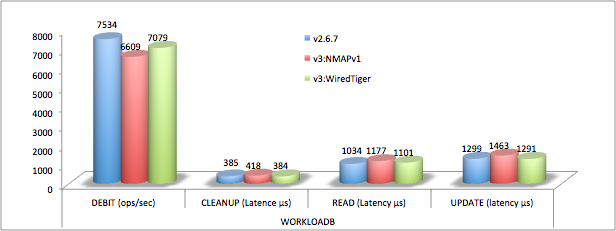
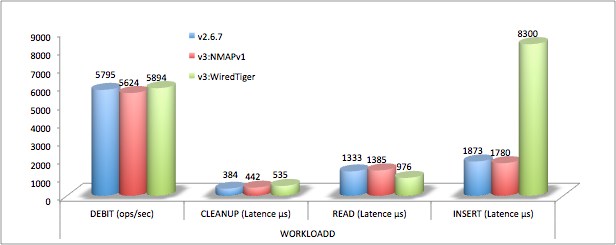
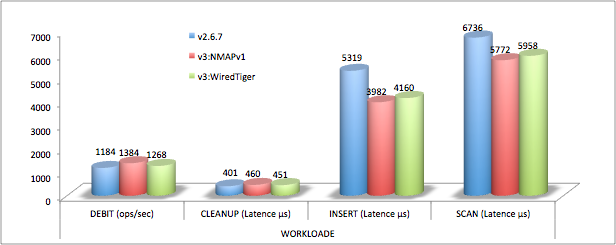

Volumétrie stockage

WiredTiger divise par deux les tailles sur disque par défaut (avec snappy, un peu moins sans compression et un peu plus avec le mode zlib).
Analyse du résultat
Les résultats sont décevants en ce qui concerne les performances de la v3. En tenant compte de l’erreur de mesure, ils sont globalement équivalents à la version précédente.
J’ai essayé de comprendre quelle pouvait en être la cause (CPU, mémoire, cas de test, architecture MongoDB, …).
Même si la consommation CPU et mémoire est plus élevée avec WiredTiger, ce ne semble pas être la cause des contentions qui est en réalité le routeur “mongos”.
C’est pourquoi les modifications suivantes impactent peu les résultats :
- Augmentation du cache WiredTiger
- Désactivation de la compression.
- Clé de sharding de type “hashed”.
Seule l’augmentation du nombre de chunks (en diminuant leur taille maximum) permet d’améliorer les performances. En effet le nombre de chunks avec WiredTiger est beaucoup plus faible qu’avec un autre moteur de stockage.
Ma conclusion est que le benchmark YCSB (avec cette configuration) n’est pas un cas d’usage pour du sharding et que l’aspect mono-collection ne permet pas la mise en valeur de la dernière version de MongoDB.
C’est pourquoi j’ai choisi d’effectuer une autre série de tests sur une architecture différente et mettant en avant le multi-threading.
Le benchmark 2 : SysBench
SysBench est à l’origine un test de charge d’un système d’exploitation hébergeant une base de données.
Il est destiné à mettre en valeur, grâce à deux types de tests, l’aptitude d’un serveur à monter en charge lors de fortes sollicitations.
Ce test a été adapté par l’équipe de TokuMX afin de pouvoir benchmarker MongoDB.
Le test se déroule en deux phases :
- Phase 1 – Chargement des collections dans des threads séparés et en utilisant le bulk insert.
- Phase 2 – Tests de charge : ordres de type “select”, “aggregate”, “insert”, “update” et “remove” le tout dans des threads séparés.
Configurations du benchmark
- Nombre de collections : 16
- Nombre de documents par collection : 1 million
- Nombre de documents par batch : 1000
- Nombre de threads pour le chargement : 8
- Nombre de threads pour les tests de charge : 64
- Durée du test : 10 minutes
- Write_concern MongoDB : Safe
Architecture de test
L’architecture retenue est volontairement plus simple.
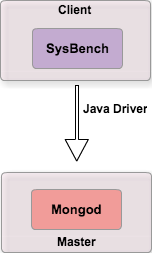
Résultats
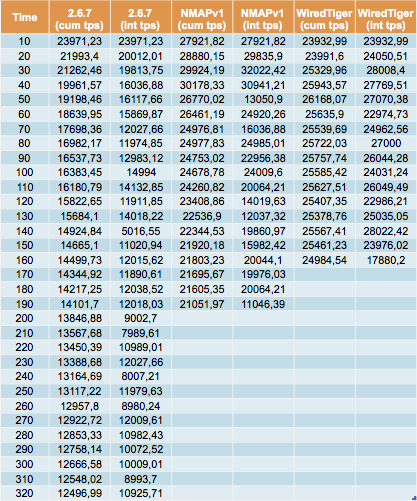
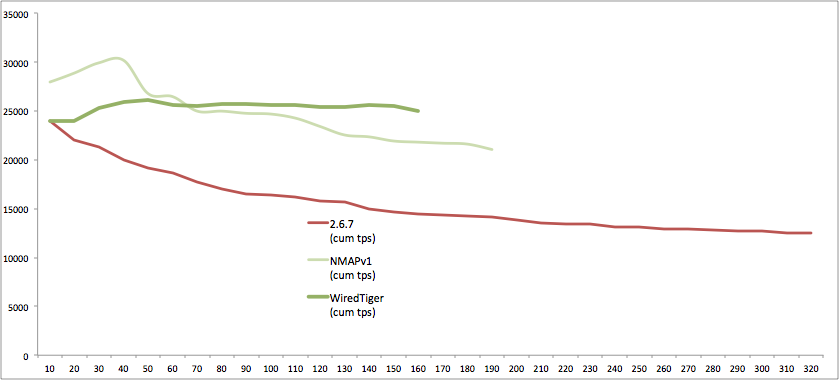
Dans ce tests on mesure le débit (en nombre de transactions par seconde), pendant l’intervalle (10 secondes) et le débit global (cumulé).
Import des données
Tests de charge
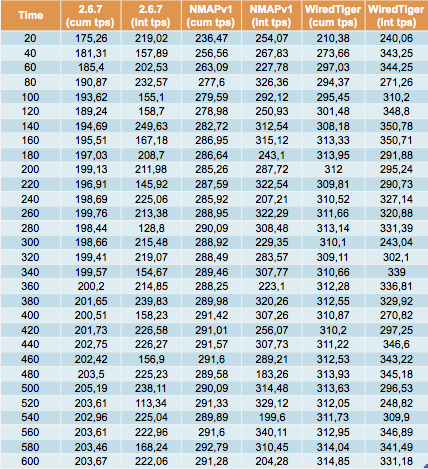
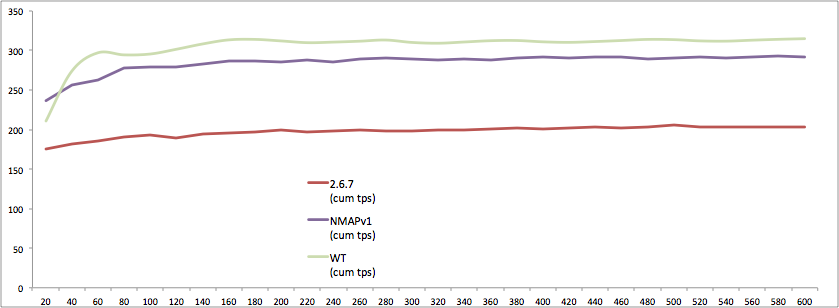
Analyse des résultats
On obtient enfin des résultats plus conformes aux attentes même si la différence entre MMAPv1 et WiredTiger est faible.
Insertion
Dans ce test d’insertion en masse et par lots (1000), les différences de performances entre la v2.6.7 et la v3 sont importantes.
WiredTiger est en effet deux fois plus rapide par rapport à la version 2.6.7 et presque autant pour MMAPv1.
Par rapport aux tests YCSB, la différence s’explique par la multiplication du nombre de collections mais aussi sans doute par l’architecture mise en œuvre (pas de sharding).
Tests de charge
Là encore, on observe un avantage de la version 3 par rapport à la version 2.6.7 :
- +43% MMAPv1 par rapport à 2.6.7
- +54% pour WiredTiger
Par rapport aux tests YCSB, la différence s’explique par la multiplication des collections mais aussi par le ratio lecture/modification (ici mise à jour et suppression) qui est plus important.
Conclusion
En ce qui concerne les gains en performance, il faut prendre les chiffres annoncés par MongoDB avec du recul et ne pas les considérer comme acquis.
Cette version est juste un commencement pour MongoDB qui va dans les prochaines versions parfaire l’intégration du moteur WiredTiger.
Le moteur historique MMAPv1 n’est pas en reste puisqu’il permettra à certaines applications existantes un gain en performances.
Mais au vu des résultats des benchmarks, on comprend mieux les mises en garde de la part de MongoDB (et sa réticence à publier des benchmarks officiels). MMAPv1 et WiredTiger vont continuer d’exister ensemble dans les prochaines versions.
WiredTiger ne rend pas obsolète MMAPv1 puisqu’il y a des cas ou les performances seront équivalentes, sans avoir à réécrire le code de l’application.
Et donc, pourquoi ne pas migrer vers WiredTiger ?
- Nécessite la réécriture du code (un thread client par collection).
- Moins de recul sur le comportement de WiredTiger.
- Quelle est la volumétrie minimum (et le nombre d’accès) pour envisager la mise en œuvre du sharding ?
- Le bulk insert à t’il encore sa place ?
- Quelles sont les tâches de maintenance, les indicateurs à superviser ?
C’est un plus d’avoir le choix mais il faudra du temps afin de déterminer tous les critères de choix et les avantages et inconvénients de chacun des moteurs de stockage.
En conclusion l’arrivée de WiredTiger (et d’un changement de moteur de stockage dans MongoDB) a des impacts sur la modélisation, le développement, l’exploitation, …
Enfin les outils devront se mettre à jour (en dehors de MMS qui est évidement déjà compatible).
Par exemple seul uMongo est pour l’instant fonctionnel avec cette version (et encore grâce à une mise à jour sauvage du driver dans le package).
