
Dans cet article nous allons étudier la possibilité d’exécuter des tâches MapReduce en dehors d’Hadoop.
En particulier nous allons étudier les possibilités offertes par les grilles de données open source Java.
Introduction
L’impression actuelle est que tous les éditeurs veulent prendre le train Hadoop en route et se positionnent sur ce marché quitte à brouiller l’image de leur produit et la nôtre par la même occasion :
- ETL, bases de données, caches, BI, la liste est longue.
Parmi ces initiatives il y a donc les grilles de données mémoire qui proposent des API MapReduce.
Les solutions étudiées :
- Hazelcast qui propose une API MapReduce depuis la version 3.2
- Infinispan qui propose une API MapReduce depuis la version 5.2
D’autres solutions de type NoSQL ou grilles de données mémoire font un rapprochement avec Hadoop mais elles sont hors contexte car elles ne visent pas à remplacer complètement Hadoop mais à le compléter :
C’est le cas des produits suivants :
- Cassandra, Coherence, Terracotta…
Par exemple avec Cassandra il est possible d’exécuter des jobs MapReduce avec en entrée des données Cassandra et de stocker les résultats dans Cassandra (ou dans un File System).
Cette solution exige toutefois la mise en place d’un cluster Hadoop (dans ce cas Cassandra remplace HBase comme solution NoSQL).
A l’opposé avec Terracotta les données sont extraites d’Hadoop (HDFS) pour traitement et le résultat final est stocké dans Hadoop (mais peut être consulté dans Terracotta).
De plus d’autres solutions comme MongoDB proposent aussi une API MapReduce mais ce ne sont pas des solutions Java (MongoDB est écrit en C++ et on code les fonctions MapReduce en JavaScript).
Enfin il existe depuis peu Apache Spark qui est une grille de calcul mémoire qui peut fonctionner avec ou sans Hadoop.
Mais Spark est encore un peu jeune et mériterait un article à lui tout seul : c’est pourquoi il n’est pas étudié ici.
Présentation Hazelcast et Infinispan
Hazelcast et Infinispan sont des grilles de données mémoire (In Memory Data Grid) open source (Licence Apache) qui permettent le stockage et le traitement de données réparties dans un cluster.
Fonctionnalités communes :
- Écrit en Java,
- Caches locaux et distribués,
- Clients natifs pour les langages Java, C#, …
- API Rest, memcache,
- Découverte automatique des membres,
- Failover automatique (un crash d’un nœud ne met pas en péril les données),
- Support des transactions et des locks,
- …
Liste des cas d’utilisations :
- Cache de service,
- Cache L2,
- Cache de sessions HTTP,
- …
Licence : Open source, LGPL.
Les dernières versions :
- Infinispan 6.0 (novembre 2013)
- Hazelcast 3.2 RC1 (février 2014)
Infinispan est plus ancien et bénéficie du support de RedHat mais Hazelcast compte dans ses rangs des noms prestigieux dans l’écosystème Java :
- Rod Johnson, créateur de Spring, au comité exécutif.
- Greg Luck créateur d’Ehcache en tant que CTO.
Les grilles de données mémoire proposent déjà des traitements distribués sous des dénominations parfois différentes : EntryProcessor, ExecutorService, Distributed task, …
Mais offrant toutes la même fonctionnalité : faire exécuter les traitements à l’endroit même où sont stockées les données plutôt que de rapatrier les données pour les traiter.
Un traitement est en charge de la bonne exécution et de l’agrégation des résultats.
Nous allons donc étudier l’intérêt de l’implémentation MapReduce des grilles de données vis à vis d’Hadoop mais aussi par rapport aux traitements distribués déjà offerts par ces solutions.
Implémentations MapReduce
Rappel de l’implémentation Map Reduce d’Hadoop
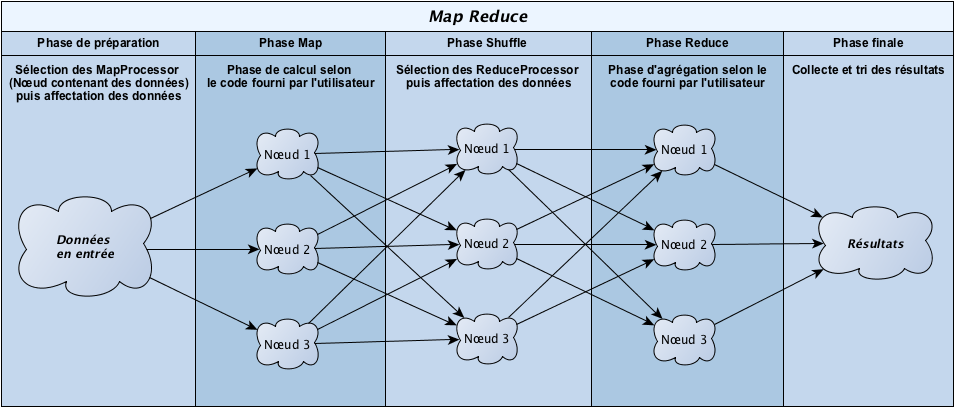
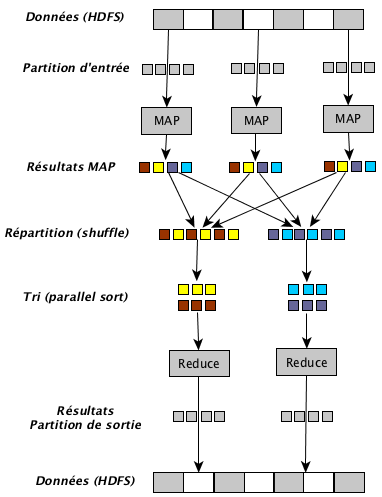
Cinq phases distinctes constituent l’algorithme MapReduce (pour rappel les données sont stockées dans le système de fichiers HDFS sous la forme clé/valeur).
- Phase de préparation : Les nœuds contenant les données concernées sont identifiées (stockage HDFS).
- Phase Map (calcul) : Pour chaque ensemble le traitement Map est appliqué.
- Phase Shuffle : Les données sont triées et les données liées sont regroupées pour être traitées par un même nœud.
- Phase Reduce (agrégation) : Les données sont éventuellement agrégées.
- Phase finale : Les résultats de chacun des nœuds sont regroupés et triés pour stockage et/ou restitution.
NB : La phase « combiner » qui est sommairement une phase de Reduce en mémoire a été volontairement omise pour simplifier la compréhension.
Ces cinq phases ne sont pas obligatoirement strictement séquentielles dans la mesure ou une phase peut démarrer avant la fin complète de la phase précédente (sous réserve de la disponibilité des données et de l’absence d’impact sur le résultat final).
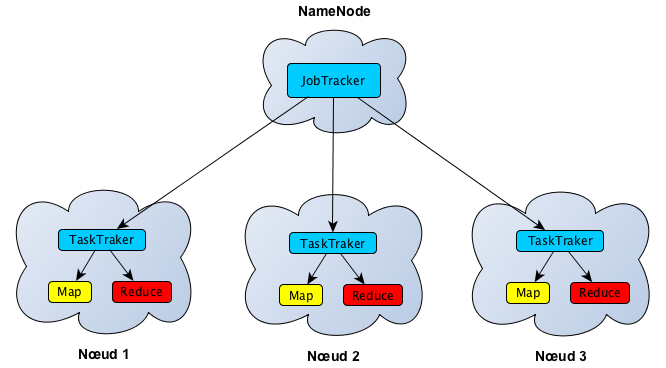
Ensuite un jobTracker est en charge de la supervision de l’ensemble des traitements confiés aux différents nœuds (taskTracker).
Il serait toutefois injuste de ne pas aborder la dernière évolution, à savoir YARN.
YARN est une refonte complète de MapReduce afin de répondre aux limitations majeures de la première version :
- Améliorer la scalabilité et la disponibilité.
- Étendre MapReduce (et faciliter l’introduction de traitements temps réel).
Scalabilité : Une partie de la gestion des tâches est maintenant gérée par les nœuds de data (nœuds secondaires).
De plus il n’y a plus d’affectation de rôle aux slots de calculs (un nœud devait être configuré pour utiliser n slots dédiés aux taches Map et m slots dédiés aux tâches Reduce).
Disponibilité : Suppression des SPOF (Single Point Of Failure) que pouvaient être le NameNode et le jobTracker (ce dernier est séparé en deux).
Temps réel : La réponse au besoin temps réel n’est pas directement adressée par YARN.
Mais ce dernier offre la possibilité d’aller au delà du framework MapReduce et donc d’intégrer des paradigmes moins axés batch.
Par exemple :
- Traitement de flux de données massif comme Storm ou Apache S4 (streaming),
- Traitement in-memory comme Apache Spark (qui peut aussi faire du streaming).
YARN permet l’intégration entre Hadoop et ces solutions qui bénéficieront des avantages de la plateforme comme la scalabilité.
Infinispan
Pour son implémentation MapReduce, Infinispan s’est basé sur la publication originale de Google.
Quatre composants permettent de définir une tache MapReduce :
- Mapper,
- Reducer,
- Collator,
- MapReduceTask.
Mapper : Comme son nom l’indique il s’agit de l’équivalent de la phase Map d’Hadoop
Reducer : Comme son nom l’indique il s’agit de l’équivalent de la phase Reduce d’Hadoop
Collator : C’est une étape supplémentaire par rapport à Hadoop dans la mesure où elle permet à l’utilisateur de définir une fonction qui va traiter les résultats des tâches MapReduce
MapReduceTask : il s’agit du composant en charge de l’ordonnancement des traitements.
Un développeur Hadoop reconnaîtra un système très familier dans l’implémentation d’Infinispan. Même si il y a une phase supplémentaire dans l’implémentation Infinispan (en tout cas une étape sur laquelle l’utilisateur peut intervenir contrairement à Hadoop).
Particularités propres à Infinispan :
- Timeout sur la durée des taches.
- Le locking est automatiquement géré.
- Les données en entrées et en sorties sont des caches.
- Tout comme Infinispan, MapReduce est compatible avec CDI.
- Avec Infinispan il est possible d’indiquer que l’on souhaiterait distribuer les tâches de type Reduce au sein du cluster (attribut distributeReducePhase lors de la création d’une tâche MapReduce).
- Il est aussi possible d’indiquer à Infinispan d’utiliser un cache pour le stockage des résultats intermédiaires (useIntermediateSharedCache), cette option est plus lente mais utile pour le débogage (le cache utilisé s’appelle alors __tmpMapReduce).
A noter qu’une évolution importante est annoncée avec la version 7 d’Infinispan, les étapes Map et Reduce ne sont plus mono-thread mais basées sur un pool de threads consommant les tâches à accomplir. De grandes améliorations sont attendues au niveau de la performance.
Hazelcast
La première implémentation MapReduce dans Hazelcast était basée sur CastMapR, elle a été récemment entièrement revue et intégrée de manière officielle.
La nouvelle implémentation s’inspire de celle d’Infinispan et comme cette dernière toutes les taches sont parallèles et s’inspire donc plutôt de YARN que de MapReduce.
Quatre composants permettent de définir une tâche MapReduce :
- Mapper,
- Reducer,
- Collator,
- JobTracker.
Mapper : Comme son nom l’indique il s’agit de l’équivalent de la phase Map d’Hadoop
Reducer : Comme son nom l’indique il s’agit de l’équivalent de la phase Reduce d’Hadoop
Collator : C’est une étape d’agrégation des résultats avec éventuellement un traitement global du résultat produit par MapReduce
JobTracker : il s’agit du composant en charge de l’ordonnancement des traitements.
Particularités propres à Hazelcast :
- La clé et la valeur des entrées du cache peuvent être de n’importe quel type.
- Le locking est automatiquement géré.
- Les données en entrée et en sortie sont des caches.
- L’interface JobProcessInformation permet d’obtenir des statistiques sur les traitements MapReduce (état des partitions, nombre d’enregistrements traités, …).
- Possibilité de définir une stratégie en cas de changement de la topologie (perte de nœuds pouvant entraîner la perte de données).
A noter qu’une évolution importante est annoncée : Continuous MapReduce.
Il s’agit en fait de l’intégration des « continuous Query » avec MapReduce.
Les Continuous Query sont des fonctionnalités classiques des grilles de données mémoire, elles permettent à un client d’effectuer une requête sur la grille de données et de recevoir automatiquement les nouvelles données qui pourraient avoir été insérées.
Cette fonctionnalité est un pas de plus vers le streaming MapReduce.
Schéma de synthèse

Avantages de l’implémentation MapReduce des Grilles de données
Le principal avantage est évidemment la mémoire. Toutes les données sont traitées en mémoire ce qui garantit des performances accrues par rapport à HDFS (on annonce des performances jusqu’à 100 fois plus rapides).
L’autre avantage est que les tâches Map et Reduce peuvent être exécutées en parallèle ce qui est rarement le cas avec Hadoop. C’est pourquoi une étape supplémentaire existe dans les implémentations des IMDG.
Enfin un des apports des grilles de données est la scalabilité (découverte automatique des nœuds) : même si Hadoop est par définition scalable, il est loin d’atteindre le coté “plug and play” de ces solutions.
On pourra ajouter ou supprimer un nœud qui sera automatiquement pris en compte (sans la phase de déclaration d’Hadoop) pour les traitements.
Il est même possible de modifier la topologie du cluster pendant un traitement.
Les grilles de données sont plus simple à mettre en oeuvre du fait de leur architecture réduite.
En effet, a minima, une plateforme Hadoop va intégrer :
- MapReduce : Framework de traitement des données
- HBase : Ajoute du NoSQL et des transaction à Hadoop
- Zookeeper : Gestion centralisée de la configuration et coordination des services
- HDFS : Système de stockage des données (Système de fichiers distribués)
- Un outil d’interrogation :
- Hive (Interrogation de type SQL)
- Pig (Langage de haut niveau)
- Un outil de monitoring :
- Cloudera manager.
- Apache Ambari.
Une autre différence importante entre Hadoop et les grilles de données est le cycle de vie des données.
Avec les grilles, les données sont stockées en mémoire et peuvent changer, avec Hadoop (HDFS) les données sont figées (les blocks de données peuvent être amendés mais pas mis à jour).
De plus les grilles supportent le versioning des données (les données ont alors un historique) alors que MapReduce, Storm, Spark ne gèrent pas le modèle de données.
Toutefois signalons que le streaming est une vraie valeur ajoutée des grilles de données mémoire mais il n’est pas encore mis en oeuvre.
Enfin les implémentations sont très proches d’Hadoop ce qui facilite la montée en compétence pour des développeurs déjà formés à Hadoop.
Inversement une pratique des mécanismes MapReduce des grilles de données peut être vue comme une première étape vers une future adoption d’Hadoop au sein du SI.
Il est donc possible de capitaliser malgré les différences d’implémentation.
CONCLUSION
Critères de choix traitements distribués vs MapReduce
Quels sont les avantages, les différences avec les traitements distribués ?
MapReduce est préférable :
- Si plusieurs sources de données sont concernées ou bien la source est des données est différente du cache.
- Si justement le traitement ne consiste pas uniquement à effectuer des calculs mais à agréger/trier les résultats (le fameux Word Count en est l’exemple typique).
Traitements distribués préférables :
- Traitements simples et unitaires fortement liés à la donnée.
L’algorithme MapReduce offre une nouvelle possibilité de traitement distribué aux grilles de calculs mémoire.
Critères de choix traitements MapReduce (Grilles de données vs Hadoop)
Quelles sont les avantages, les différences avec l’implémentation Hadoop ?
Cas d’utilisation MapReduce (Hadoop) :
- Volumétrie (péta-octets).
- Persistance des données.
- Besoin d’analyse des données poussée (Mahout, …).
Cas d’utilisation MapReduce (grilles de données) :
- Volumétrie (relativement) faible : jusqu’à 1 To.
- Expériences grilles de données et envie de capitaliser sur cette technologie.
- Besoin de performances (calcul) et de latence faible (disponibilité des résultats).
L’implémentation MapReduce des grilles de données apporte une possibilité supplémentaire, ce n’est évidemment pas un remplacement d’Hadoop.
Il est évident que la capacité d’une grille de données mémoire ne peut rivaliser avec celle d’un cluster Hadoop, car la capacité mémoire d’une machine ne peut concurrencer les capacités disques.
Une capacité d’un téra-octet est déjà une limite haute pour une grille de données mémoire (soit un cluster de 15 serveurs).
Un cluster Hadoop est tout à fait capable de traiter des péta-octet.
Mais dans certains cas il apporte une plus value car la montée en compétence et la conduite du changement est moins forte que pour Hadoop (déploiement et administration simplifiée).
Exemple complet (Infinispan) :
Voici un exemple avec le fameux “word count” :
Dans cet exemple nous allons comptabiliser le nombre d’occurrences de chacun des mots dans un texte et afficher le mot apparaissant le plus souvent.
Ici seul un nœud Infinispan est démarré, vous pouvez évidemment en lancer d’autres pour un exemple plus réaliste.
La librairie “LoremIpsum” est utilisée pour la génération du texte.
import java.io.IOException;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import java.util.StringTokenizer;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.infinispan.Cache;
import org.infinispan.configuration.cache.CacheMode;
import org.infinispan.configuration.cache.ConfigurationBuilder;
import org.infinispan.configuration.global.GlobalConfiguration;
import org.infinispan.configuration.global.GlobalConfigurationBuilder;
import org.infinispan.distexec.mapreduce.Collator;
import org.infinispan.distexec.mapreduce.Collector;
import org.infinispan.distexec.mapreduce.MapReduceTask;
import org.infinispan.distexec.mapreduce.Mapper;
import org.infinispan.distexec.mapreduce.Reducer;
import org.infinispan.eviction.EvictionStrategy;
import org.infinispan.manager.DefaultCacheManager;
import de.svenjacobs.loremipsum.LoremIpsum;
public class WordCountExample {
private static int MAX_ENTRIES = 1000;
private static String CACHE_NAME = "WordsList";
private static final Log log = LogFactory.getLog(WordCountExample.class);
private static Cache<Integer, String> wordsListCache = null;
public static void main(String[] args) throws IOException {
/** Configure ISPN */
GlobalConfiguration globalConfig = new GlobalConfigurationBuilder()
.transport().clusterName("ISPN-MR").transport()
.defaultTransport()
.addProperty("configurationFile", "jgroups-tcp.xml").build();
DefaultCacheManager manager = new DefaultCacheManager(globalConfig);
/** Define custom cache */
manager.defineConfiguration(
CACHE_NAME,
new ConfigurationBuilder().eviction()
.strategy(EvictionStrategy.LIRS)
.maxEntries(MAX_ENTRIES).clustering()
.cacheMode(CacheMode.DIST_SYNC).build());
manager.start();
wordsListCache = manager.getCache(CACHE_NAME);
wordsListCache.start();
/** Put words to count into the cache */
feedCache(MAX_ENTRIES / 10);
/** Create Map Reduce Task masterCacheNode, distributeReducePhase, useIntermediateSharedCache */
MapReduceTask<Integer, String, String, Integer> t = new MapReduceTask<Integer, String, String, Integer>(
wordsListCache, true, true);
/** Define Mapper and Reducer */
t.mappedWith(new WordCountMapper()).reducedWith(new WordCountReducer());
/** Define Collator */
String[] mostFrequentWord = t
.execute(new Collator<String, Integer, String[]>() {
@Override
public String[] collate(Map<String, Integer> reducedResults) {
String mostFrequent = "";
Integer maxCount = 0;
for (Entry<String, Integer> e : reducedResults
.entrySet()) {
Integer count = e.getValue();
if (count > maxCount) {
maxCount = count;
mostFrequent = e.getKey();
}
}
return new String[] { mostFrequent, maxCount.toString() };
}
});
log.info("The most frequent word is '" + mostFrequentWord[0]
+ "' which appears " + mostFrequentWord[1] + " times.");
manager.stop();
}
static class WordCountMapper implements
Mapper<Integer, String, String, Integer> {
private static final long serialVersionUID = -5943370243108735560L;
@Override
public void map(Integer key, String value, Collector<String, Integer> c) {
StringTokenizer tokens = new StringTokenizer(value);
log.debug("Key : " + key + ", Value : " + value);
while (tokens.hasMoreElements()) {
String s = (String) tokens.nextElement();
c.emit(s, 1);
}
}
}
static class WordCountReducer implements Reducer<String, Integer> {
private static final long serialVersionUID = 1901016598354633256L;
@Override
public Integer reduce(String key, Iterator<Integer> iter) {
int sum = 0;
while (iter.hasNext()) {
Integer i = (Integer) iter.next();
log.debug("Key : " + key + ", Value : " + i);
sum += i;
}
return sum;
}
}
public static String[] generateIpsum(int wordsToGenerate) {
LoremIpsum loremIpsum = new LoremIpsum();
String phrase = loremIpsum.getWords(wordsToGenerate);
log.debug("Phrase : " + phrase);
phrase = phrase.replaceAll(", ", " ");
return phrase.split(" ");
}
public static void feedCache(int length) {
String[] wordsArray = generateIpsum(length);
for (Integer i = 1; i < wordsArray.length; i++) {
wordsListCache.put(i, wordsArray[i]);
}
}
}
