
Le Big Data est à la mode et je commencerai cet article par lister les freins qui empêchent encore les entreprises de franchir le pas, malgré les avantages que le Big Data peut apporter. Pour terminer ce mois du temps fort du Big Data chez Ippon, je voulais surtout faire un panorama des architectures types du Big Data. Ce retour est d’autant plus intéressant que les solutions ont maintenant quelques années d’exploitation en production.
Nous voyons donc arriver les premiers retours d’expérience sur les architectures mises en place.
Constats et opportunités du Big Data
Plusieurs sondages sur le Big Data permettent d’en savoir un peu plus sur les éléments qui empêchent certaines entreprises de franchir le pas (cf. http://www.zdnet.fr/actualites/big-data-qu-est-ce-qui-bloque-encore-les-entreprises-39821966.htm).
Parmi les points cités, on trouve :
- Coût.
- Manque de compétences.
- Manque de visualisation des opportunités.
- Les entreprises n’ont pas cherché à quantifier le ROI des investissements Big Data (les investissements ne sont pas pondérés par les gains attendus).
- La collecte de la donnée est limitée aux canaux traditionnels.
- Les données sont non structurées (et on ne sait pas les traiter).
À l’inverse, voici les gains potentiels pour les entreprises qui utilisent le Big Data.
Les plus matures en matière d’exploitation des données (clients, métiers, externes, etc.) se distinguent par les critères suivants :
- Anticipation des enjeux stratégiques liés à une meilleure utilisation des données internes et externes.
- Diversité des données collectées et des canaux de collecte.
- Constitution d’équipes de data scientists et autres experts data.
- Adoption de nouvelles technologies d’exploitation de la data.
- Meilleure prise en compte des enjeux de protection de la vie privée et des données à caractère personnel dans l’exploitation des données clients.
L’étude suivante montre les gains constatés par les entreprises ayant mis en œuvre le Big Data
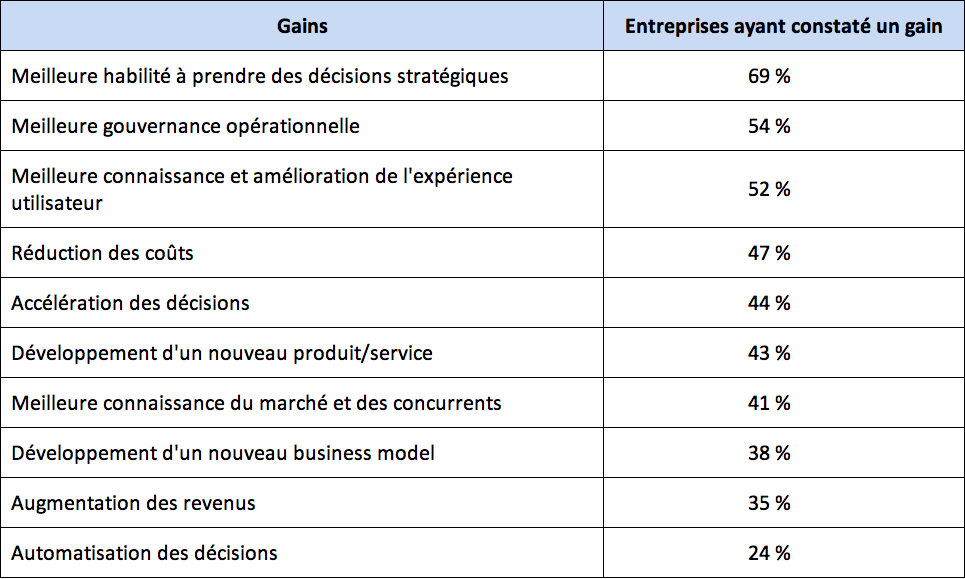
Source : http://barc-research.com/research/big-data-use-cases-2015/
Mise en œuvre
Le Big Data a vocation à traiter des problématiques métiers complexes. Il déplace le centre d’intérêt des entreprises vers les données et la valeur qu’elles peuvent apporter à l’entreprise.
L’exploitation de la donnée est tout d’abord une dette :
- Coût de l’acquisition de données.
- Coût matériel et logiciel.
- Coût humain (recrutement, montée en compétences).
Ce n’est qu’une fois ce cap franchi que le retour sur investissement devient possible. C’est pourquoi il faut commencer par de petits projets, (et donc limiter les investissements) pour ensuite réfléchir à des problématiques de généralisation (offre de service) à tout un système d’information. Plus globalement, il faut passer d’une entreprise pilotée par les projets à une entreprise pilotée par les données.
Traitements
Il y a trois grandes familles de traitement dans le Big Data :
- Batch,
- Micro-batch,
- Temps réel (streaming).
Batchs
Les traitements vont analyser l’ensemble des données disponibles à un instant T.
Données en entrée : fichiers, résultat d’une requête (HDFS, Sqoop, etc.).
Résultats : les résultats ne seront disponibles qu’à la fin des traitements.
Latence : souvent de l’ordre de la minute, voire dans certains cas de l’heure.
Exemple d’implémentation : MapReduce.
Micro-batchs
Les traitements vont analyser l’ensemble des données disponibles toutes les n secondes.
Données en entrée : petits fichiers, données Web, etc.
Résultats : les résultats ne seront disponibles qu’à la fin des traitements d’un micro-batch.
Latence : souvent de l’ordre de la seconde.
Exemple d’implémentation : Spark streaming.
Temps réel
Les traitements vont analyser les données au fur et à mesure de leur disponibilité.
Données en entrée : stream Web, messages provenant d’un bus, flux de logs, etc.
Résultats : les résultats sont disponibles au fur et à mesure.
Latence : parfois inférieur à la seconde.
Exemple d’implémentation : Flink, Tez, Storm.
Catégories
Catégories des solutions Big Data :
- Ingestion/Extraction de données,
- Traitement de données,
- Analyse/Apprentissage,
- Data visualisation,
- Requête/Interrogation,
- Workflow,
- Stockage,
- Ordonnancement,
- Sécurité,
- Gouvernance,
- Messages.
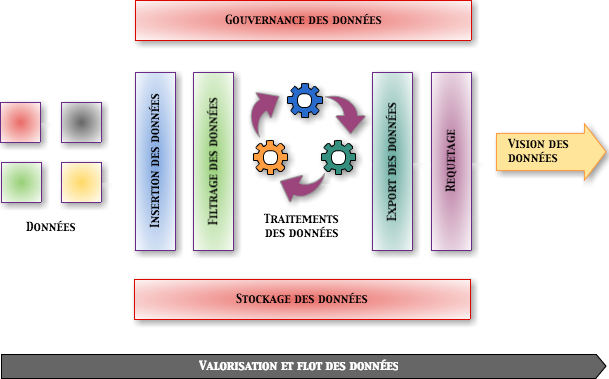
Architecture Big Data 2016
Aucune technologie ne permet de résoudre tous les types de problèmes posés. Hadoop a posé les bases du Big Data (surtout en terme de traitement). La plateforme est capable de traiter des volumes importants de données, mais avec une latence importante. C’est pourquoi sont apparus des systèmes (quasi) temps réels tels que Spark, Storm, Flink, Druid, ou encore Tez.
L’enjeu étant de conserver les points forts de la plateforme Hadoop :
- Capacité à traiter des quantités énormes de données.
- Sécurité.
- Distribution.
- Tolérance à la panne.
Ceci tout en augmentant les possibilités d’interactions grâce à des traitements temps réels. Non seulement ces nouveaux frameworks améliorent les performances grâce à une meilleure utilisation de la mémoire, mais ils offrent aussi (et surtout) la possibilité de définir des fenêtres de traitements (micro batch, windowing) ainsi que des traitements itératifs.
Coté stockage, ces dernières années ont vu l’émergence des solutions NoSQL en remplacement des solutions traditionnelles de type SGBD. Même si certaines solutions dominent le marché (MongoDB, Cassandra, Neo4j, etc.), le besoin est trop diversifié pour qu’une seule solution puisse répondre à l’ensemble des besoins.
Du coté des interrogations d’une plateforme de Big Data, le (pseudo-)SQL tente de s’imposer comme standard avec des solutions comme Hive, Drill ou bien Spark SQL.
Au final, le but est de permettre une exploration interactive des données et d’ouvrir la plateforme à une population plus large que celle des programmeurs. Certaines architectures et solutions permettent de résoudre des problèmes complexes mais cela a évidemment un coût qui peut être rédhibitoire pour des problématiques plus simples.
En résumé il faut choisir une architecture évolutive que l’on adaptera en fonction des nouveaux besoins plutôt qu’une architecture complexe dès le départ.
Hadoop
Définition
Hadoop est un framework qui va permettre le traitement de données massives sur un cluster, allant de une à plusieurs centaines de machines. Hadoop est écrit en Java et a été créé par Doug Cutting et Michael Cafarella en 2005 (après avoir créé le moteur de recherche Lucene, Doug travaillait alors pour Yahoo sur son projet de crawler web Nutch). Hadoop va gérer la distribution des données au cœur des machines du cluster, leurs éventuelles défaillances, mais aussi l’agrégation du traitement final. L’architecture est de type « Share nothing » : aucune donnée n’est traitée par deux nœuds différents, même si les données sont réparties sur plusieurs noeuds (principe d’un noeud primaire et de noeuds secondaires).
Hadoop est composé de quatre éléments :
- Hadoop Common : ensemble d’utilitaires utilisés par les autres briques Hadoop.
- Hadoop Distributed File System (HDFS) : un système de fichiers distribué pour le stockage persistant des données.
- Hadoop YARN : un framework de gestion des ressources et de planification des traitements.
- Hadoop MapReduce v2 : Un framework de traitements distribués basé sur YARN.
HDFS est un système de fichiers utilisé pour stocker des données structurées ou pas sur un ensemble de serveurs. C’est un système distribué, extensible et portable développé par le créateur d’Hadoop et inspiré du système développé par Google (GoogleFS). Écrit en Java, il a été conçu pour stocker de très gros volumes de données sur un grand nombre de machines équipées de disques durs standard. HDFS s’appuie sur le système de fichier natif de l’OS pour présenter un système de stockage unifié reposant sur un ensemble de disques et de systèmes de fichiers hétérogènes.
MapReduce est un framework de traitements parallélisés, créé par Google pour son moteur de recherche Web. Ce framework permet de décomposer des requêtes importantes en un ensemble de requêtes plus petites qui vont produire chacune un sous-ensemble du résultat final. C’est la fonction Map. L’ensemble des résultats est traité (par agrégation et/ou filtrage) : c’est la fonction Reduce. MapReduce est idéal pour les traitements batchs, mais il n’est pas itératif par défaut.
Un cas d’utilisation très répandu d’Hadoop actuellement est le “Data Lake”.
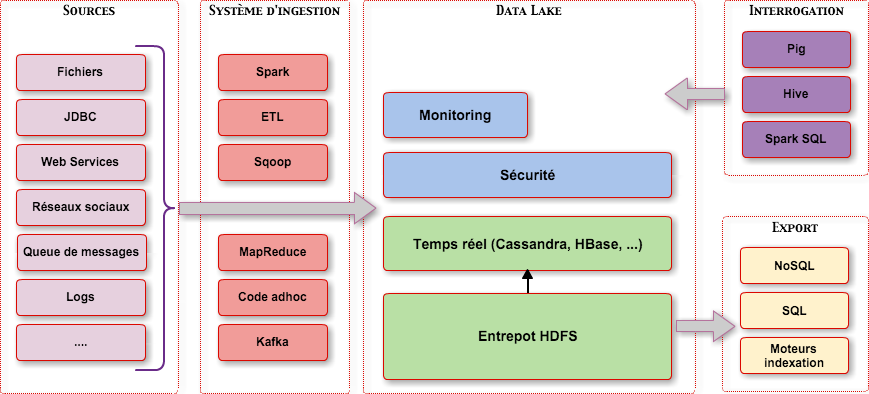
Synthèse
Les points forts d’Hadoop sont :
- Distribution des traitements au plus près de la donnée (parallélisation).
- Reprise automatique sur erreur.
- Coût de stockage très concurrentiel.
- Écosystème très important.
Ses inconvénients sont :
- Performance (par rapport à des bases NoSQL, à des grilles de données, etc.).
- Fait principalement pour traiter de très gros volume de données.
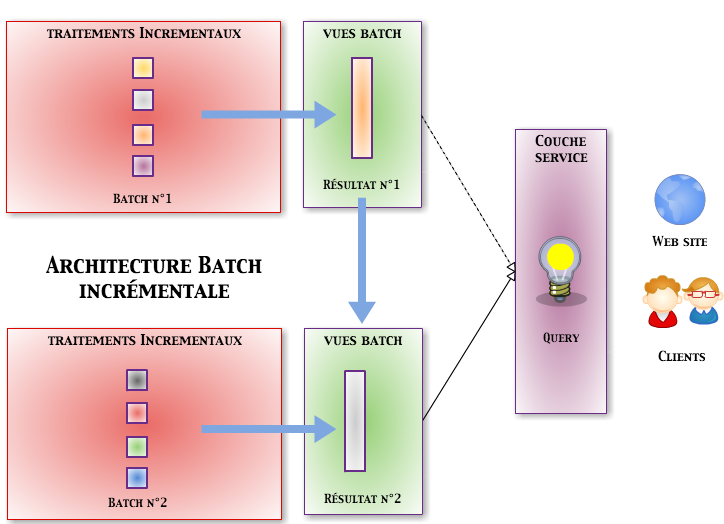
Traitements de type Batch (incrémentaux)
Définition
Une architecture de type batch permet de traiter un ensemble de données en entrée jusqu’à épuisement de la source. Tant que des données seront présentes, les traitements vont se poursuivre et l’on aura un résultat cohérent et accessible uniquement à la fin des traitements. Afin d’éviter cet effet tunnel, il est possible de découper les données en entrée. C’est là que la notion incrémentale est importante. Elle va permettre de prendre en compte les nouvelles données sans la nécessité de retraiter l’ensemble des données déjà traitées.
Un parfait exemple de traitement Big Data de type Batch est MapReduce dans sa version Hadoop. D’autres frameworks peuvent aussi implémenter des traitements de type Batch :
- Apache Flink.
- Apache Spark.
- Apache Tez.
Les données sont d’abord sélectionnées par un traitement principal et souvent unique. Elles sont par la suite distribuées entre différents nœuds, afin d’être traitées. Une fois les données traitées par l’ensemble des nœuds, un traitement réalise les opérations globales :
- Tri.
- Agrégation.
Synthèse
Les points forts de cette approche sont :
- Simplicité de mise en œuvre.
- L’agrégation des traitements incrémentaux est pris en charge par le framework.
Ses inconvénients sont :
- Temps de traitement.
- Les données arrivées en cours de traitement ne sont pas prises en compte.
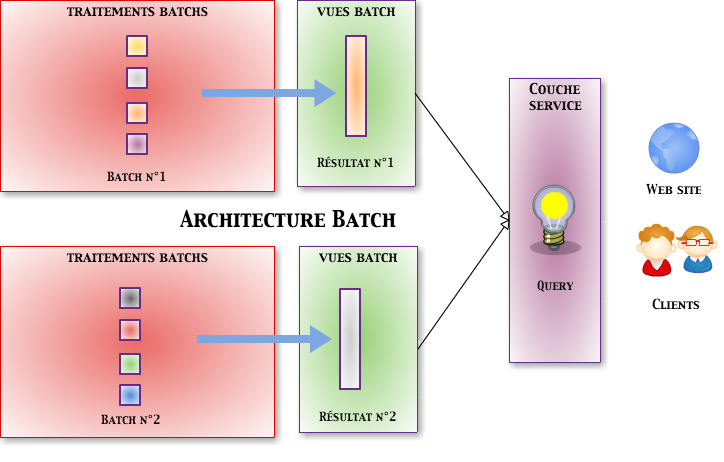
Les traitements incrémentaux vont différer des traitements batchs « simples » par la possibilité de ne traiter que les nouvelles entrées tout en proposant un résultat qui tienne compte de l’ensemble des données.
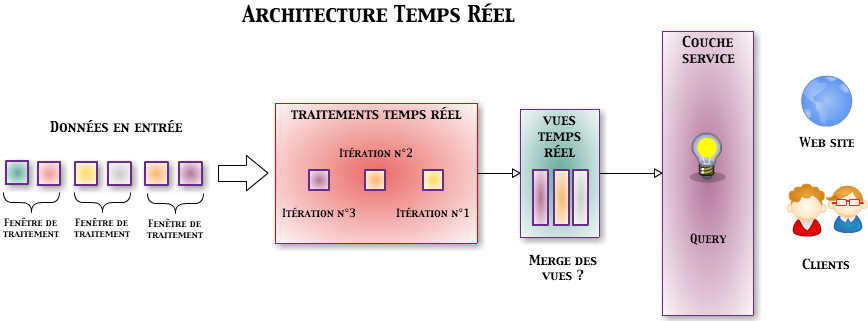
Traitements temps réel
Définition
On parle d’architecture temps réel ou streaming par opposition aux architectures de type batch. Il n’est pas nécessaire d’attendre la fin des données en entrée pour émettre un résultat. La notion de temps réel est toute relative et dépend du contexte : milli-secondes, secondes ou encore minutes.
On distingue les solutions de type micro-batch des solutions de streaming :
- Micro-batch : un résultat est produit toutes les n secondes.
- Streaming : chaque entrée est traitée immédiatement et produit un résultat.
Apache Spark est par exemple une solution de micro-batch, alors que Storm et Flink sont des solutions de streaming.
Synthèse
Les points forts de l’approche temps réel sont :
- Temps de traitement modulable.
- Performances (améliore les temps de traitements).
- Simplicité de mise en œuvre.
- Peut être la base de solutions évolutives.
Ses inconvénients sont :
- Fusion des vues pour produire un résultat plus complet.
- Ne concerne que le traitement et doit donc être complété d’autres solutions (stockage, interrogation, etc.).
Architecture Lambda
Définition
L’architecture Lambda a été imaginée par Nathan Marz et James Warren, afin de résoudre des problématiques complexes mélangeant temps réel et batchs. L’architecture Lambda permet de stocker et de traiter de larges volumes de données (batch) tout en intégrant dans les résultats des batchs les données les plus récentes. Cette approche permet de conserver les principes du Big Data, tels que la scalabilité, la tolérance aux pannes, etc.
Une architecture Lambda est composée de trois couches: :
-
Couche batch (Batch Layer) :- Stockage de l’ensemble des données.
-
Traitements massifs et réguliers afin de produire des vues consultables par les utilisateurs.
-
La fréquence des traitements ne doit pas être trop importante afin de minimiser les tâches de fusion des résultats et de constituer les vues.
-
Couche temps réel (Speed Layer) :- Ne traite que les données récentes (flux).
-
Calcul des vues incrémentales qui vont compléter les vues batch afin de fournir des résultats plus récents.
-
Suppression des vues temps réel obsolètes (postérieures à un traitement batch)
-
Couche de service (Serving Layer) :- Permet de stocker et d’exposer aux clients les vues créées par les couches batch et temps réel.
-
Aussi capable de calculer dynamiquement ces vues.
-
N’importe quelle base NoSQL peut convenir.
L’architecture Lambda est générique mais complexe dans le nombre de composants mis en œuvre.
Il n’y a pas de solutions dédiées à cette architecture, mais une multitude :
- Stockage : NoSQL surtout mais aussi JMS, Kafka, HDFS.
- Couche Batch : Hadoop MapReduce, Spark, Flink, etc.
- Couche Temps réel : Storm, Spark, Flink, Samza, Tez, etc.
- Couche de service : Druid, Cassandra, Hive, HBase, ElasticSearch, etc.
Il existe toutefois des projets complets implémentant une architecture Lambda :
- Générique : Twitter Summingbird (https://github.com/twitter/summingbird).
- Dédiée au machine learning : Cloudera Oryx 2 (http://oryx.io/).

Synthèse
Les points forts de l’architecture Lambda sont :
- On conserve les données brutes afin de pouvoir les retraiter au besoin.
- La vision fournie aux clients est la plus fraîche possible.
- Solution à tout faire.
- Indépendant des technologies.
Ses inconvénients sont :
- La logique métier est implémentée deux fois (dans la filière temps réel et dans la filière batch).
- Plus de frameworks à maîtriser.
- Il faut deux sources différentes des mêmes données (fichiers, web services).
- Il existe des solutions plus simples lorsque le besoin est moins complexe. L’évolutivité des solutions Big Data permettra dans la plupart des cas de migrer vers une architecture Lambda lorsque le besoin l’exigera.
L’architecture Lambda est utilisée par des entreprises comme Metamarkets ou Yahoo.
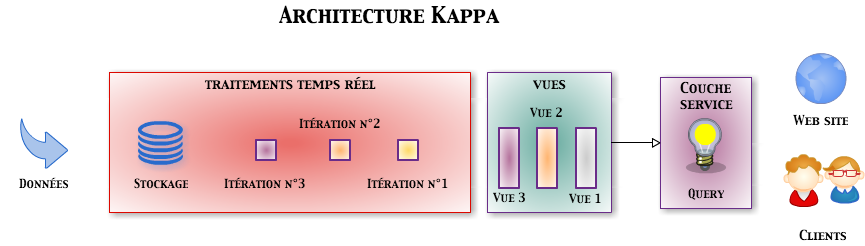
Architecture Kappa
L’idée de l’architecture Kappa a été formulée par Jay Kreps (LinkedIn) dans cet article. L’architecture Kappa est née en réaction à l’architecture Lambda et à sa complexité. Elle est née d’un constat simple : la plupart des solutions de traitement sont capables de traiter à la fois des batchs et des flux.
L’architecture Kappa permet donc de simplifier l’architecture Lambda en fusionnant les couches temps réel et batch. Elle apporte une autre évolution par rapport à l’architecture Lambda : le système de stockage des données est plus restreint et doit être un système de fichiers de type log et non modifiable (tel que Kafka).
Kafka ou un autre système permet de conserver les messages pendant un certain temps afin de pouvoir les retraiter. De fait, et encore plus que l’architecture Lambda, l’architecture Kappa ne permet pas le stockage permanent des données. Elle est plus dédiée à leur traitement.
Quoique plus restreinte, l’architecture Kappa laisse une certaine liberté dans le choix des composants mis en œuvre :
- Stockage : Kafka, etc.
- Traitements : Storm, Spark, Flink, Samza, Tez, etc.
- Couche de service : Druid, Cassandra, Hive, HBase, ElasticSearch, etc.
Synthèse
Les points forts de l’architecture Kappa sont :
- Solution à tout faire.
- Indépendant des technologies.
- Plus simple que l’architecture Lambda.
Les inconvénients de cette architecture sont :
- Pas de séparation entre les besoins
- …
L’architecture Kappa est utilisé par des entreprises comme Linkedin.
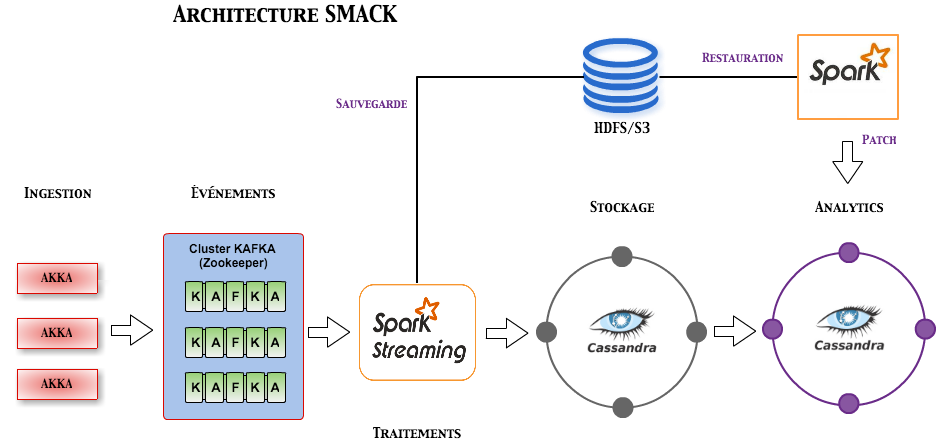
Architecture SMACK
L’architecture SMACK (pour Spark-Mesos-Akka-Cassandra-Kafka) est assez différente des architectures Lambda ou Kappa, puisqu’elle est composée d’une liste de solutions plutôt que sur des principes et pattern. Toutefois chacune des solutions est dédié à une tâche particulière. Il est tout à fait possible d’implémenter une architecture Lambda ou Kappa avec ces solutions, mais aussi d’adopter une architecture plus simple.
Choix de solutions matures, répondant aux exigences du Big Data :
- Spark : Framework de traitement des données (batch et streaming).
- Mesos : Gestion des ressources du cluster (CPU/RAM), haute disponibilité grâce à Zookeeper.
- Akka : Implémentation du paradigme acteurs pour la JVM (ingestion des données dans Kafka).
- Cassandra : Solution NoSQL (Stockage des données brutes, mais aussi pour l’analyse des données).
- Kafka : Stockage des événements (les événements de mise à jour sont stockés dans Kafka afin d’assurer leur persistance).
Kafka est parfois remplacé par Kinesis sur le cloud (Amazon AWS). Certaines de ces solutions sont officiellement supportées par Mesos (Spark, Kafka). Par contre l’intégration de Cassandra nécessite de s’appuyer sur des projets tiers comme ceux de Mesosphere (http://mesosphere.github.io/cassandra-mesos/)
Exemple d’implémentation de l’architecture SMACK.
Synthèse
Les points forts de l’architecture SMACK sont :
- Un minimum de solutions capable de traiter un très grand nombre de problématiques.
- Basée sur des solutions matures du Big Data.
- Scalabilité des solutions.
- Solution de gestion unique (Mesos).
- Compatible batchs, temps réel, Lambda, etc.
Ses inconvénients sont :
- Intégration de nouveaux besoins et donc de nouveaux frameworks.
- Architecture complexe.
L’architecture SMACK est utilisé par des entreprises comme TupleJump ou ING.
En conclusion
Les architectures Big Data se multiplient. Même si elles se veulent génériques et évolutives, toutes ne seront pas adaptées à vos besoins.
Parmi les retours d’expériences que l’on peut observer, on trouve des entreprises qui ont cru trouver la solution définitive à leur besoin et se retrouve actuellement dépassées par les opérations de maintien en conditions opérationnelles d’architectures trop complexes par rapport à leur besoin.
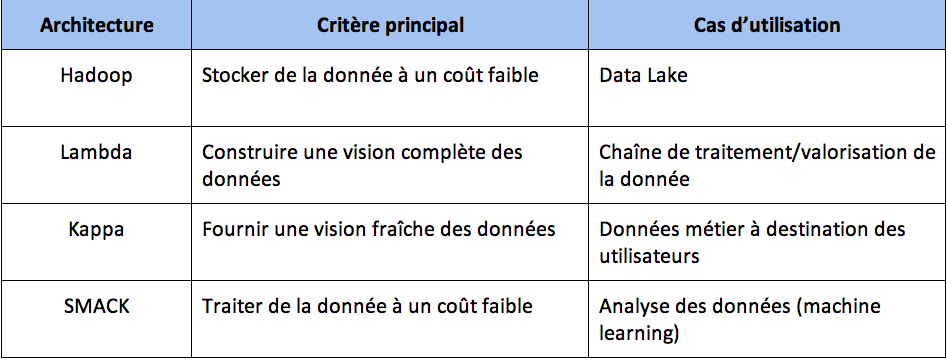
Voici les critères de choix des architectures présentées :
Références
Gartner status of Big Data : https://www.gartner.com/doc/3115022/demise-big-data-lessons-state
Gartner Big Data Industry Insights : http://www.gartner.com/webinar/2931518
Big Data : Principles and best practices of scalable realtime data systems
(Nathan Marz et James Warren) https://www.manning.com/books/big-data
Vous souhaitez tout savoir du Big Data (architectures, solutions, freins et opportunités…) ? Découvrez notre livre blanc Big Data !
