
L’écosystème Hadoop
En 2004, Google a publié un article présentant son algorithme de calcul à grande échelle, MapReduce, ainsi que son système de fichier en cluster, GoogleFS. Rapidement (2005) une version open source voyait le jour sous l’impulsion de Yahoo.
Aujourd’hui il est difficile de se retrouver dans la jungle d’Hadoop pour les raisons suivantes :
- Ce sont des technologies jeunes.
- Beaucoup de buzz et de communication de sociétés qui veulent prendre le train Big Data en marche.
- Des raccourcis sont souvent employés (non MapReduce ou un équivalent n’est pas suffisant pour parler d’Hadoop).
- Beaucoup d’acteurs différents (des mastodontes, des spécialistes du web, des start-up, …).
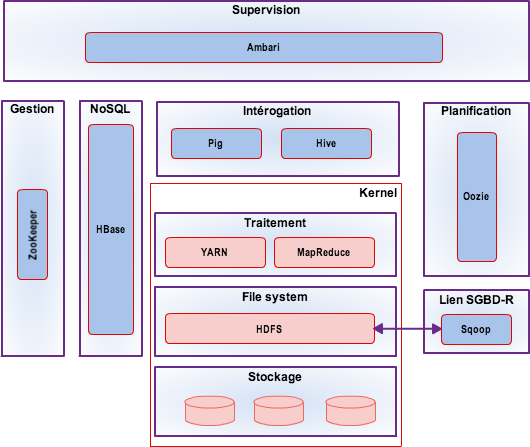
Dans une distribution Hadoop on va retrouver les éléments suivants (ou leur équivalence) HDFS, MapReduce, ZooKeeper, HBase, Hive, HCatalog, Oozie, Pig, Sqoop, …
Ces solutions sont des projets Apache et donc disponibles mais l’intérêt d’un package complet est évident : compatibilité entre les composants, simplicité d’installation, support, …
Dans cet article on évoquera les trois distributions majeures que sont Cloudera, HortonWorks et MapR, toutes les trois se basant sur Apache Hadoop.
On peut toutefois les distinguer en fonction de la distance qu’elles prennent avec cette base :
- MapR : noyau Hadoop mais repackagé et enrichi de solutions propriétaires.
- Cloudera : fidèle en grande partie sauf pour les outils d’administration.
- HortonWorks : fidèle à la distribution Apache et donc 100% open source.
Il existe d’autres distributions, voire des offres cloud, mais qui n’offrent pas l’ensemble des fonctionnalités d’une plate forme Hadoop ou ne sont pas open source (ou a minima gratuites) comme Intel Distribution for Hadoop ou bien Greenplum (Pivotal HD).
Le cœur : Hadoop kernel
Hadoop est le framework le plus utilisé actuellement pour manipuler et faire du Big Data.
Apache Hadoop est un framework qui va permettre le traitement de données massives sur un cluster allant de une à plusieurs centaines de machines, c’est un projet open source (Apache v2 licence).
Hadoop est écrit en Java et a été créé par Doug Cutting et Michael Cafarella en 2005 (Doug, travaillait alors pour Yahoo sur son projet de crawler web Nutch).
C’est lui qui va gérer la distribution des données au cœur des machines du cluster, leurs éventuelles défaillances mais aussi l’agrégation du traitement final.
L’architecture est de type « Share nothing » : aucune donnée n’est traitée par deux noeuds différents même si les données sont réparties sur plusieurs noeuds (principe d’un noeud primaire et de noeuds secondaires).
HDFS (Hadoop Distributed File System)
HDFS est un système de fichiers Java utilisé pour stocker des données structurées ou non sur un ensemble de serveurs distribués.
HDFS s’appuie sur le système de fichier natif de l’OS pour présenter un système de stockage unifié reposant sur un ensemble de disques et de systèmes de fichiers hétérogènes.
La consistance des données est basée sur la redondance. Une donnée est stockée sur au moins n volumes différents.
Éléments importants :
Node (Master/slave) : Dans une architecture Hadoop chaque membre pouvant traiter des données est appelé node (Noeud). Un seul d’entre eux peut être master même s’il peut changer au cours de la vie du cluster.
Il est responsable de la localisation des données dans le cluster (il est appelé Name Node). Les autres sont des slaves appelés Data Nodes.
Bien qu’il puisse y avoir plusieurs Name Nodes, la “promotion” doit se faire manuellement (Hadoop 2.0, actuellement en version alpha, introduit un failover automatisé).
Le Name Node est donc un Single Point Of Failure (SPOF) dans un cluster Hadoop.
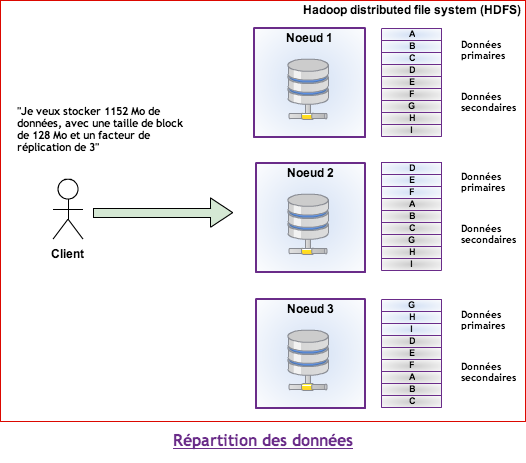
Au sein du cluster, les données sont découpées et distribuées en blocks selon les deux paramètres suivants :
- Blocksize : Taille unitaire de stockage (généralement 64 Mo ou 128 Mo). C’est à dire qu’un fichier de 1 Go (et une taille de block de 128 Mo) sera divisé en 8 blocks.
- Replication factor : C’est le nombre de copies d’une données devant être réparties sur les différents noeuds du cluster (souvent 3, c’est à dire une primaire et deux secondaires).
Enfin, un principe important d’HDFS est que les fichiers sont de type “write-once” car dans des opérations analytiques on lit la donnée beaucoup plus qu’on l’écrit. C’est donc sur la lecture que les efforts ont été portés.
Ce qui signifie que l’on ne modifie pas les données déjà présentes.
Un principe lié est qu’à partir du moment ou un fichier HDFS est ouvert en écriture, il est verrouillé pendant toute la durée du traitement.
Il est donc impossible d’accéder à des données ou à un résultat tant que le job n’est pas terminé et n’a pas fermé le fichier (et un fichier peut être très volumineux avec Hadoop).
Alternatives
MapR
En mai 2011, MapR a annoncé une alternative au système HDFS. Ce système permet d’éviter le SPOF qu’est le Name Node. Ce système n’est pas inconnu car il s’agit de HBase, dont elle propose une version propriétaire.
HBase (Apache)
HBase est un sous-projet d’Hadoop, c’est un système de gestion de base de données non relationnelles distribué, écrit en Java, disposant d’un stockage structuré pour les grandes tables.
HBase est inspirée des publications de Google sur BigTable. Comme BigTable, c’est une base de données orientée colonnes.
HBase est souvent utilisé conjointement au système de fichiers HDFS, ce dernier facilitant la distribution des données de HBase sur plusieurs noeuds.
Contrairement à HDFS, HBase permet de gérer les accès aléatoires read/write pour des applications de type temps réel.
Cassandra (Facebook)
Cassandra est une base de données orientée colonnes développée sous l’impulsion de Facebook.
Cassandra supporte l’exécution de jobs MapReduce qui peuvent y puiser les données en entrée et y stocker les résultats en retour (ou bien dans un système de fichiers).
Cassandra comparativement à HBase est meilleur pour les écritures alors que ce dernier est plus performant pour les lectures.
Offre Cloud
Le cloud est un complément idéal au monde Hadoop, en offrant des possibilités de stockage et de traitement extensibles.
Il est donc possible d’utiliser un système de fichiers situé dans le cloud pour le stockage des données et l’exécution des traitements.
Solutions supportées :
- Amazon S3.
- Kosmix’s CloudStore.
- IBM GPFS (General Parallel File System).
MapReduce
A l’origine crée par Google pour son outil de recherche web.
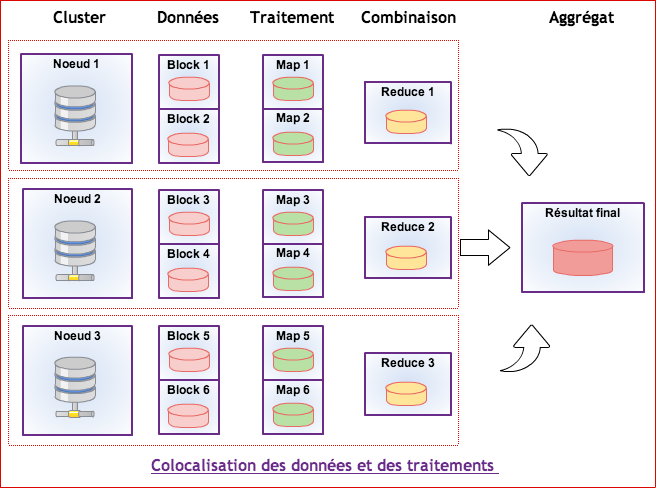
C’est un framework qui permet le décomposition d’une requête importante en un ensemble de requêtes plus petites qui vont produire chacune un sous ensemble du résultat final : c’est la fonction Map.
L’ensemble des résultats est traité (agrégation, filtre) : c’est la fonction Reduce.
Alternatives
YARN (HortonWorks)
YARN (Yet-Another-Resource-Negotiator) est aussi appelé MapReduce 2.0, ce n’est pas une refonte mais une évolution du framework MapReduce.
YARN apporte une séparation claire entre les problématiques suivantes :
- Gestion de l’état du cluster et des ressources.
- Gestion de l’exécution des jobs.
YARN est compatible avec les anciennes versions de MapReduce (il faut simplement recompiler le code).
Les extensions
Requêtage des données : Hive (Facebook)
Hive est à l’origine un projet Facebook qui permet de faire le lien entre le monde SQL et Hadoop.
Il permet l’exécution de requêtes SQL sur un cluster Hadoop en vue d’analyser et d’agréger les données.
Le langage SQL est nommé HiveQL. C’est un langage de visualisation uniquement, c’est pourquoi seules les instructions de type “Select” sont supportées pour la manipulation des données.
Dans certains cas, les développeurs doivent faire le mapping entre les structures de données et Hive.
Hive utilise un connecteur jdbc/odbc.
Scripting sur les données : Pig (Yahoo)
Pig est à l’origine un projet Yahoo qui permet le requêtage des données Hadoop à partir d’un langage de script.
Contrairement à Hive, Pig est basé sur un langage de haut niveau PigLatin qui permet de créer des programmes de type MapReduce.
Contrairement à Hive, Pig ne dispose pas d’interface web.
Intégration SGBD-R : Sqoop (Cloudera)
Sqoop permet le transfert des données entre un cluster Hadoop et des bases de données relationnelles.
C’est un produit développé par Cloudera.
Il permet d’importer/exporter des données depuis/vers Hadoop et Hive.
Pour la manipulation des données Sqoop utilise MapReduce et des drivers JDBC.
Ordonnanceur : Apache Oozie (Yahoo)
Oozie est une solution de workflow (au sens scheduler d’exploitation) utilisée pour gérer et coordonner les tâches de traitement de données à destination de Hadoop.
Oozie s’intègre parfaitement avec l’écosystème Hadoop puisqu’il supporte les types de jobs suivant :
- MapReduce (Java et Streaming).
- Pig.
- Hive.
- Sqoop.
- Autres tels que programmes Java ou scripts de type Shell.
Gestion des clusters Hadoop
Clustering
Apache ZooKeeper
ZooKeeper est un service de coordination des services d’un cluster Hadoop.
En particulier, le rôle de ZooKeeper est de fournir aux composants Hadoop les fonctionnalités de distribution.
Pour cela il centralise les éléments de configuration du cluster Hadoop, propose des services de clusterisation et gère la synchronisation des différents éléments (événements).
ZooKeeper est un élément indispensable au bon fonctionnement de HBase.
Supervision
Apache Ambari (HortonWorks)
Ambari est un projet d’incubation Apache initié par HortonWorks et destiné à la supervision et à l’administration de clusters Hadoop.
C’est un outil web qui propose un tableau de bord. Cela permet de visualiser rapidement l’état d’un cluster.
Ambari dispose d’un tableau de bord dont le rôle est de fournir une représentation :
- De l’état des services.
- De la configuration du cluster et des services.
- Des informations issues de Ganglia et de Nagios.
- De l’exécution des jobs.
- Des métriques de chaque machine et du cluster.
De plus Ambari inclue un système de gestion de configuration permettant de déployer des services d’Hadoop ou de son écosystème sur des clusters de machines.
Ambari se positionne en alternative à Chef, Puppet pour les solutions génériques ou encore à Cloudera Manager pour le monde Hadoop.
Ambari ne se limite pas à Hadoop mais permet de gérer également tous les outils de l’écosystème.
Les outils annoncés sont :
- Hadoop
- HDFS
- MapReduce
- Hive, HCatalog
- Oozie
- HBase
- Ganglia, Nagios
Autres
Apache Flume (Cloudera)
Flume est une solution de collecte et d’agrégation de fichiers logs, destinés à être stockés et traités par Hadoop.
Il a été conçu pour s’interfacer directement avec HDFS au travers d’une API native.
Flume est à l’origine un projet Cloudera, reversé depuis à la fondation Apache.
Alternatives : Apache Chukwa.
Apache Mahout
Apache Mahout est un projet de la fondation Apache visant à créer des implémentations d’algorithmes d’apprentissage automatique et de datamining.
Même si les principaux algorithmes d’apprentissage se basent sur MapReduce, il n’y a pas d’obligation à utiliser Hadoop. Apache Mahout ayant été conçu pour pouvoir fonctionner sans cette dépendance.
Apache Drill (MapR)
Initié par MapR, Drill est un système distribué permettant d’effectuer des requêtes sur de larges données. Il implémente les concepts exposés par le projet Google Dremel.
Drill permet d’adresser le besoin temps réel d’un projet Hadoop. MapReduce étant plutôt conçu pour traiter de larges volumes de données en batch sans objectif de rapidité et sans possibilité de redéfinir la requête à la volée.
Drill est donc un système distribué qui permet l’analyse interactive des données, ce n’est pas un remplacement de MapReduce mais un complément qui est plus adapté pour certains besoins.
Apache HCatalog (HortonWorks)
HCatalog permet l’interopérabilité d’un cluster de données Hadoop avec des systèmes externes.
HCatalog est un service de management de tables et de schéma des données Hadoop :
- Permet d’attaquer les données HDFS via des schémas de type tables de données en lecture/écriture.
- Permet d’opérer sur des données issues de MapReduce, Pig ou Hive.
Apache Tez (HortonWorks)
Tez est un nouveau framework en incubation chez Apache.
Utilisant YARN il remplace MapReduce afin de fournir des requêtes dites “temps réel”. La faible latence est en effet un pré requis à l’exploration interactive des données stockées sur un cluster Hadoop.
C’est un concurrent d’Apache Drill (MapR) ou de Cloudera Impala.
Vue d’ensemble de la plate forme Hadoop
Les distributions
HortonWorks
Présentation
HortonWorks a été formé en juin 2011 par des membres de l’équipe Yahoo en charge du projet Hadoop.
Leur but est de faciliter l’adoption de la plate forme Hadoop d’Apache, c’est pourquoi tous les composants sont open source et sous licence Apache.
Le modèle économique d’HortonWorks est de ne pas vendre de licence mais uniquement du support et des formations.
Cette distribution est la plus conforme à la plate forme Hadoop d’Apache et HortonWorks est un gros contributeur Hadoop.
Parmi les projets reversés il y a :
- YARN,
- HCatalog,
- Ambari,
- …
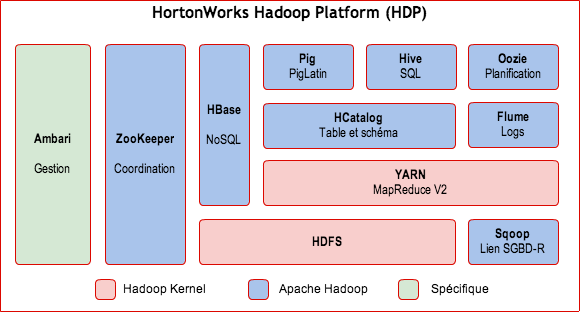
Composants de la plate forme HDP
Les éléments suivants composent la plate forme HortonWorks :
- Cœur Hadoop (HDFS/MapReduce).
- NoSQL (Apache HBase).
- Méta-données (Apache HCatalog).
- Plate forme de script (Apache Pig).
- Requêtage (Apache Hive).
- Planification(Apache Oozie).
- Coordination (Apache Zookeeper).
- Gestion et supervision (Apache Ambari).
- Services d’intégration (HCatalog APIs, WebHDFS, Talend Open Studio for Big Data, Apache Sqoop).
- Gestion distribuée des logs (Apache Flume).
- Apprentissage (Apache Mahout).
Vision d’ensemble de la distribution
Déploiement de la plate forme
Machine Virtuelle prête à l’emploi
HortonWorks met à disposition une machine virtuelle ou sont pré installés les composants de la plate forme Hadoop.
C’est l’idéal pour l’apprentissage de la plate forme mais incompatible avec les exigences de production ou même celles d’un POC.
Installation automatique avec Ambari
En plus de la gestion du cluster, Ambari permet le déploiement de l’ensemble des composants Hadoop de manière centralisée.
Installation manuelle avec Linux RPM
HortonWorks met à disposition des packages RPM.
En utilisant le principe des RPM Linux il est possible d’installer les composants HDP manuellement.
Cloudera
Présentation
Cloudera se veut comme la compagnie commerciale Hadoop.
Fondée par des experts Hadoop en provenance de Facebook, Google, Oracle et Yahoo.
Si leur plate forme est en grande partie basée sur Hadoop d’Apache, elle est complétée avec des composants maison essentiellement pour la gestion du cluster.
A noter aussi que la version d’Apache Hadoop distribuée est la dernière version stable complétée de patchs critiques ainsi que de quelques fonctionnalités de la version de développement.
Le modèle économique de Cloudera est la vente de licences mais aussi du support et des formations.
Cloudera propose une version entièrement open source de leur plate forme (Licence Apache 2.0).
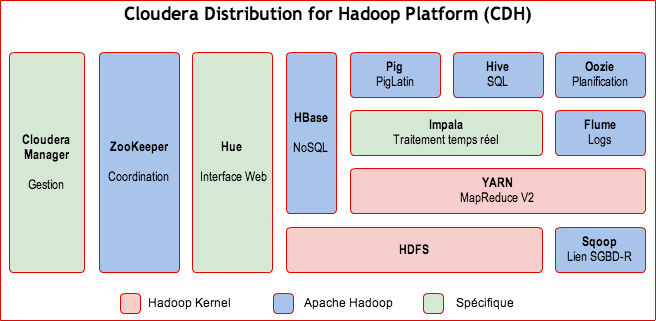
Composants de la plate forme CDH (Cloudera’s Distribution including Apache Hadoop)
Composants Apache :
- HDFS : File System distribué.
- MapReduce : Framework de traitement parallélisé.
- HBase : Base de données NoSQL (accès read/write aléatoires).
- Hive : Requêtage de type SQL.
- Pig : Scripting et requêtage Hadoop.
- Oozie : Workflow et planification de jobs Hadoop.
- Sqoop : Intégration de bases SQL.
- Flume : Exploitation de fichiers (log) dans Hadoop.
- ZooKeeper : Service de coordination pour les applications distribuées.
- Mahout : Framework d’apprentissage et de datamining pour Hadoop.
Composants d’origine Cloudera :
- Hadoop Common: Un ensemble d’utilitaires.
- Hue : SDK permettant de développer des interfaces utilisateur pour les applications Hadoop.
- Whirr : Librairies et scripts pour l’exécution d’Hadoop et de services liés dans le cloud.
Composants non Apache Hadoop :
-
Cloudera Impala : Moteur temps réel de requêtage SQL parallélisé de données stockées dans HDFS ou HBase. Contrairement à Hive de Hadoop, Impala n’utilise pas le framework MapReduce qui exige que les résultats de recherche soient écrits sur le disque, ce qui lui permet d’exécuter les requêtes plus rapidement. La consultation des données peut être interactive. Licence : ASLv2.
-
Cloudera Manager : Déploiement et gestion des composants Hadoop.
A noter que Cloudera Manager n’est pas entièrement Open Source mais dispose d’une version gratuite avec quelques restrictions :
- La version gratuite est limitée à 50 noeuds.
- Certaines fonctionnalités sont uniquement disponibles sur la version commerciale (comme le monitoring, les sauvegardes et les mises à jour automatiques).
- Support uniquement pour la version payante.
Vision d’ensemble de la distribution
Déploiement de la plate forme
Automatique avec Cloudera Manager
Cloudera Manager permet l’installation des composants de la plate forme sur une machine (y compris distante).
Cloudera Manager permet la configuration centralisée des composants du cluster.
Enfin Cloudera Manager permet de finaliser l’installation en vérifiant le bon fonctionnement de chacun des composants.
Manuel avec les packages
Récupération des archives tarball (tgz) contenant la distribution.
Configuration et installation à l’aide des scripts fournis.
MapR
Présentation
MapR a été fondée en 2009 par d’anciens membres de Google.
Bien que son approche soit commerciale, MapR contribue à des projets Apache Hadoop comme HBase, Pig, Hive, ZooKeeper et surtout Drill.
MapR se distingue surtout de la version d’Apache Hadoop par sa prise de distance avec le cœur de la plate-forme. Ils proposent ainsi leur propre système de fichier distribué ainsi que leur propre version de MapReduce : MapR FS et MapR MR.
Trois versions de leur solution sont disponibles :
- M3 : version open source.
- M5 : Ajoute des fonctions de haute disponibilité et du support.
- M7 : Environnement HBase optimisé.
MapR a remporté de beaux succès commerciaux depuis sa création.
- Un partenariat avec EMC pour une la création et le support d’une version spécifique à la plate forme Hadoop d’EMC.
- MapR est à l’origine de la version cloud de MapReduce d’Amazon : Elastic Map Reduce (EMR).
- Enfin ils ont été retenu par Google pour l’offre Big Data de Google Compute Engine (GCE).
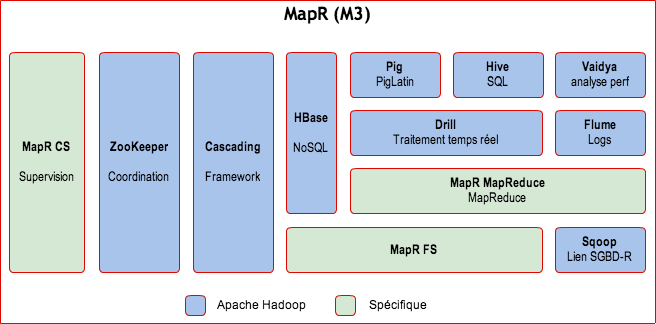
Contenu de la distribution MapR M3
Composants Apache :
- HBase,
- Pig,
- Hive,
- Mahout,
- Cascading,
- Sqoop,
- Flume
MapR propose son propre système en remplacement de HDFS :
- Une version maison de HBase (performance et fiabilité améliorées).
Avantages :
- Système plus adapté au mode read/write que HDFS.
- MapR intègre un serveur NFS (Network File System) pour l’intégration au SI de l’entreprise.
- Simplification de mise en oeuvre (surcouche du File System de l’OS et non remplacement comme HDFS).
- Plus de Single Point Of Failure.
MapR FS reste compatible avec les API MapReduce/HDFS et HBase.
MapR propose son propre système en remplacement de MapReduce d’Apache.
Avantages :
- MapR annonce de meilleures performances.
- Entièrement optimisé pour HBase.
MapR Control System (MCS)
MCS permet la gestion et la supervision du cluster Hadoop. C’est un outil web permettant à la fois les ressources du cluster (CPU, Ram, Disque) que les services et les jobs.
MCS permet de définir des alarmes sur des seuils ou des quotas …
La visualisation des informations est assurée par le composant HeatMap.
Autres spécificités :
Apache Cascading
Cascading est un framework Java dédié à Hadoop. Il permet à un développeur Java de retrouver ses marques (JUnit, Spring, etc…) et de manipuler les concepts d’Hadoop avec un langage de haut niveau sans en connaître les API.
Apache Vaidya
Hadoop Vaidya est un outil d’analyse des performances des jobs MapReduce.
Son principe de fonctionnement est basé sur des règles qu’il confronte aux statistiques d’exécution des jobs et aux fichiers de configuration.
Le rapport est produit au format XML.
Apache Drill
MapReduce a la réputation d’être puissant mais complexe à manipuler (il faut en maîtriser l’API).
De plus, il est impossible de redéfinir les requêtes à la volée.
Drill vient compléter MapReduce et se présente sous la forme d’une API permettant de créer plus rapidement des requêtes en se basant sur le modèle SQL.
SQL plutôt qu’une nouvelle API, c’est donc le choix de la capitalisation fait par Drill.
Vision d’ensemble de la distribution
Déploiement de la plate forme
Machine virtuelle
MapR fourni une machine virtuelle avec un seul noeud et l’ensemble des composants installés.
C’est l’idéal pour une prise en main de la plate-forme mais incompatible avec les exigences de production.
Manuelle avec les packages
MapR ne fournit pas de système de déploiement Hadoop.
L’installation est donc essentiellement manuelle avec des automatisations possibles.
Tout d’abord il faut récupérer les composants à installer :
- Depuis le repository internet
- Depuis un repository local
- Avec des packages Debian/Linux
Après édition de la configuration il faut ensuite exécuter les scripts fourni pour installer les composants MapR sur chaque machine.
A noter que la distribution ne contient pas les composants Apache et qu’il faut les installer manuellement.
Conclusion
Les trois distributions ont une approche et un positionnement différent en ce qui concerne la vision d’une plate forme Hadoop (open source, modèle économique…).
Le choix se portera sur l’une ou l’autre solution en fonction des exigences :
- Solution open source.
- Maturité de la solution.
- Partenariats et compatibilité avec les produits satellites.
Le choix d’une distribution est d’autant plus difficile que l’avenir d’Hadoop est loin d’être tout tracé.
En effet des virages technologiques importants sont d’ores et déjà annoncés :
- Hadoop est né afin de répondre à la problématique suivante : comment traiter des téra-octets de données simplement ?
- La réponse proposée alors, un système de fichier distribué, est arrivée à un moment où il était impossible de traiter de tels volumes de données en mémoire. Maintenant le coût de la RAM a fortement baissé et avec la généralisation des architecture 64 bits ce n’est plus tout à fait exact.
- La sécurité : elle est encore balbutiante malgré quelques initiatives comme Apache Knox.
- L’intégration avec le SI, une plate forme Hadoop isolée et non intégrée au système d’information ne sera plus possible dans le futur (en tout cas certains besoins exigeront une interaction plus grande).
- Un support direct des transactions ce qui a toujours été un challenge très important dans le monde des données distribuées.
Cloudera
Le vétéran ce qu’il lui donne une légitimité et un nombre de clients supérieur à ces concurrents.
Un autre avantage est de disposer dans ses rangs de Doug Cutting le créateur d’Hadoop.
Cloudera est très prompt à sortir les dernières versions d’Hadoop (les premiers à sortir une distribution compatible Hadoop 2.0).
Les principaux partenaires sont IBM, HP, Oracle.
MapR
La plus éloignée d’Apache Hadoop car elle intègre leur propre vision de MapReduce et HDFS. Après Cloudera c’est la solution la plus mature.
C’est aussi la solution la plus simple à installer grâce à leur utilisation du file system natif.
Beaucoup de partenariats de haut niveau et très stratégiques sur le cloud (Amazon Elastic MapReduce et Google Compute Engine).
HortonWorks
C’est la seule plate forme 100 % Apache Hadoop.
La stratégie assumée d’HortonWorks est de se baser sur les versions stables et testées d’Apache Hadoop plutôt que sur les dernières versions.
Leur solution de gestion du cluster, Ambari, n’est pas aussi mature que la concurrence : Cloudera Manager et HeatMap.
Malgré sa relative jeunesse, HortonWorks a signé des partenariats importants avec IBM, Microsoft, Teradata et Talend. Ils ont notamment signé avec Microsoft un accord pour le déploiement de leur plate forme sur Azure.
