

Le temps de préparation des données dans un projet de Data Science/Machine Learning est souvent sous-estimé. Le data wrangling, aussi connu par le nom de data munging, est le processus de transformation des données d’une forme à une autre à des fins d'analyse et pour fournir des résultats unifiés.
Pourquoi a-t-on besoin de cette étape dans un projet de Data Science ? Comment la réaliser ? Je vais tout d'abord vous expliquer le problème. Ensuite on va se concentrer sur une nouvelle fonctionnalité annoncée par AWS lors du re:Invent 2020 qui est le service Data Wrangler dans SageMaker Studio. Je vous expliquerai comment on peut utiliser ce service et quelle est son utilité. C’est un service qui va rendre la vie des Data Scientists plus facile.
Le problème avec le data wrangling
Pourquoi fait-on du data wrangling ? Parce que nous devons unifier les informations provenant de sources disparates, qu'il s'agisse de bases de données, de feuilles de calcul, d'applications ou de systèmes de fichiers. Chacune de ces sources contient des informations sur les entités et les relations qui intéressent une entreprise, telles que les clients, les adresses, les transactions, les produits, les marques, etc. Il y a beaucoup de chevauchement dans les données, mais la structure des sources pour chacune a une forme et un étiquetage différents. Chaque source possède également des attributs spécifiques au contexte dont l'entreprise se soucie et souhaite les unifier, afin de pouvoir créer une vue unique d'une donnée quelconque.
Il faut savoir que 60 à 70% du temps des Data Scientists dans un projet Machine Learning est consacré à la préparation de données. Automatiser ces opérations devient un enjeu majeur afin de se concentrer sur la modélisation et les tests statistiques qui ont une réelle valeur métier.
Lors du dernier re:Invent d’AWS, un nouveau service intégré à SageMaker Studio a été annoncé : le Data Wrangler. Un moyen de faciliter, accélérer et maîtriser la préparation des données.
Dans ce qui suit, je vais vous présenter le service et son potentiel, puis on va utiliser le service sur un jeu de données de test : le dataset Titanic. C’est un problème connu (d’apprentissage) pour essayer de répondre à une question : quels types de passagers avaient le plus de chance de survivre ?
SageMaker Data Wrangler
Amazon SageMaker Data Wrangler réduit le temps nécessaire à l'agrégation et à la préparation des données pour l'apprentissage automatique (ML). Avec SageMaker Data Wrangler, vous pouvez simplifier le processus de préparation des données et de feature engineering, et faire chaque étape du flux de travail de préparation des données, y compris la sélection, le nettoyage, l'exploration et la visualisation des données, à partir d'une seule interface visuelle.
À l’aide de l’outil de sélection de données de SageMaker Data Wrangler, vous pouvez choisir les données (sans avoir à écrire de code) à partir de diverses sources et les importer en un seul clic. SageMaker Data Wrangler contient plus de 300 transformations de données intégrées afin que vous puissiez rapidement normaliser, transformer et combiner des fonctionnalités. Avec les modèles de visualisation de SageMaker Data Wrangler, vous pouvez rapidement prévisualiser et vérifier que ces transformations sont terminées comme vous l'aviez prévu en les visualisant dans Amazon SageMaker Studio. Vous pouvez sélectionner rapidement des données à partir de plusieurs sources de données, telles que S3, Athena, Redshift, AWS Lake Formation et SageMaker Feature Store, etc. Vous pouvez également écrire des requêtes sur des sources de données et importer des données directement dans SageMaker à partir de divers formats de fichiers, tels que des fichiers CSV, des fichiers Parquet et des tables de base de données.
SageMaker Data Wrangler propose une sélection de plus de 300 transformations de données préconfigurées. Nous pouvons citer, pour exemple :
- changement de type d’une colonne,
- one-hot-encoding,
- imputation des données manquantes avec la moyenne ou la médiane,
- redimensionnement des colonnes,
- manipulation de dates,
- création des transformations personnalisées dans PySpark, SQL et Pandas.
- etc.
Afin que vous puissiez transformer vos données en un format qui puisse être efficacement utilisé pour les modèles, sans écrire une seule ligne de code.
SageMaker Data Wrangler vous aide à comprendre vos données et à identifier les erreurs potentielles et les valeurs aberrantes (Outliers) grâce à un ensemble de modèles de visualisation préconfigurés robustes :
- histogrammes,
- nuages de points,
- graphiques en boîte à moustaches,
- graphiques linéaires et graphiques à barres.
SageMaker Data Wrangler vous permet d'identifier rapidement les incohérences dans votre flux de travail de préparation des données et de diagnostiquer les problèmes avant le déploiement des modèles en production. Vous pouvez identifier rapidement si vos données préparées aboutiront à un modèle précis afin de déterminer si feature engineering supplémentaire est nécessaire pour améliorer les performances. Tout cela est possible avec la fonctionnalité “Quick Model”.
Vous pouvez exporter votre flux de travail de préparation de données vers un bloc-notes ou un script de code en un seul clic pour le mettre en production. SageMaker Data Wrangler intègre de manière transparente votre flux de travail de préparation de données avec Amazon SageMaker Pipelines pour automatiser le déploiement et la gestion des modèles. Il publie également des fonctionnalités dans Amazon SageMaker Feature Store afin que vous puissiez partager des fonctionnalités au sein de votre équipe et que d'autres personnes puissent les réutiliser pour leurs propres modèles et analyses.
Prise en main
Comme mentionné auparavant, nous allons vous montrer comment utiliser SageMaker Data Wrangler en utilisant le dataset Titanic. Le but ici est de se familiariser avec l’outil.
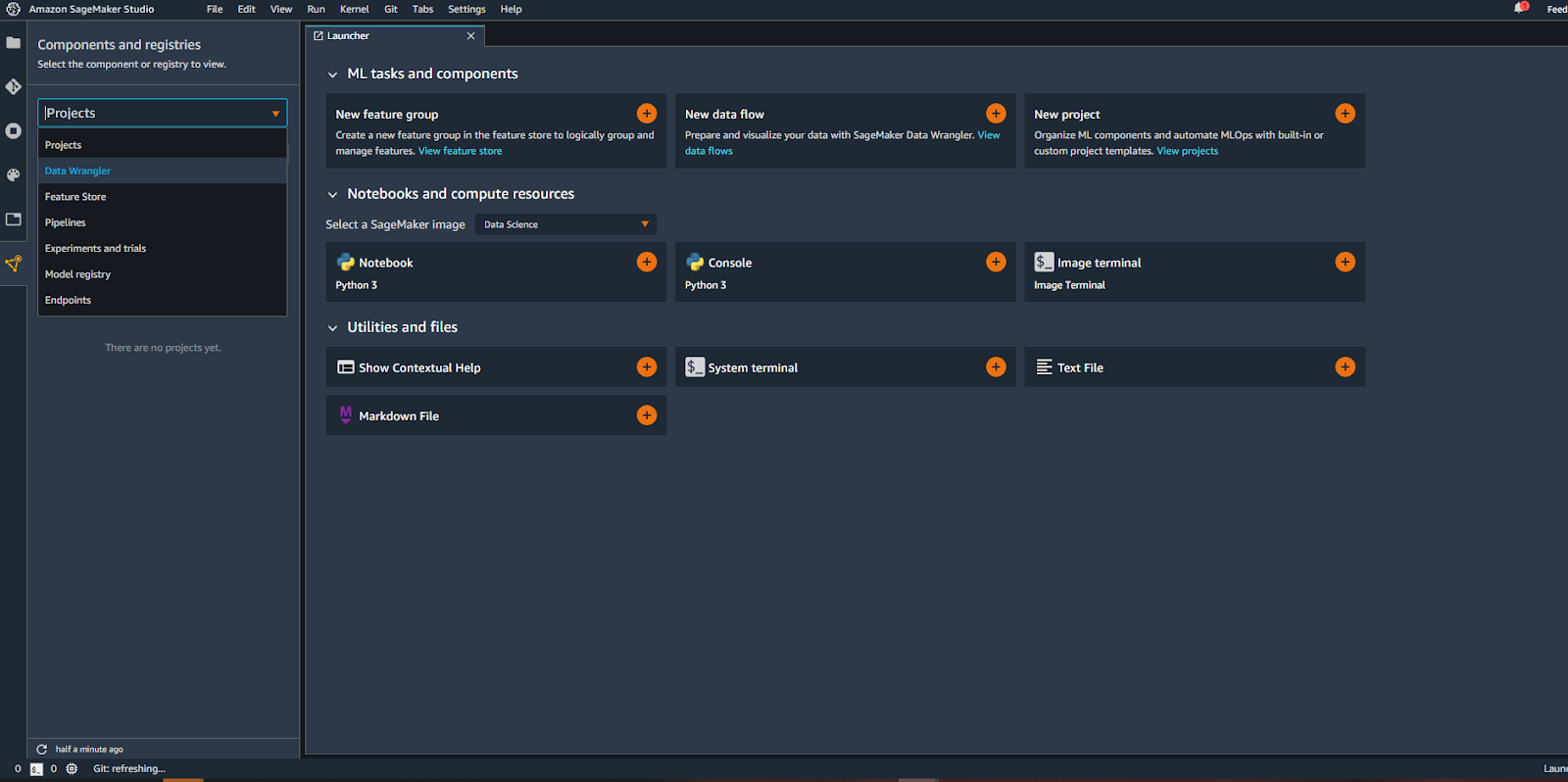
Pour commencer, il faut ouvrir votre IDE SageMaker Studio, et puis cliquez sur l’onglet “SageMaker Components and Registries” qui se trouve à gauche comme on peut le voir l’image ci-dessous.
Après, il faut choisir l’outil “Data Wrangler” pour passer à la prochaine étape qui est l’importation de données.
Sélection des données
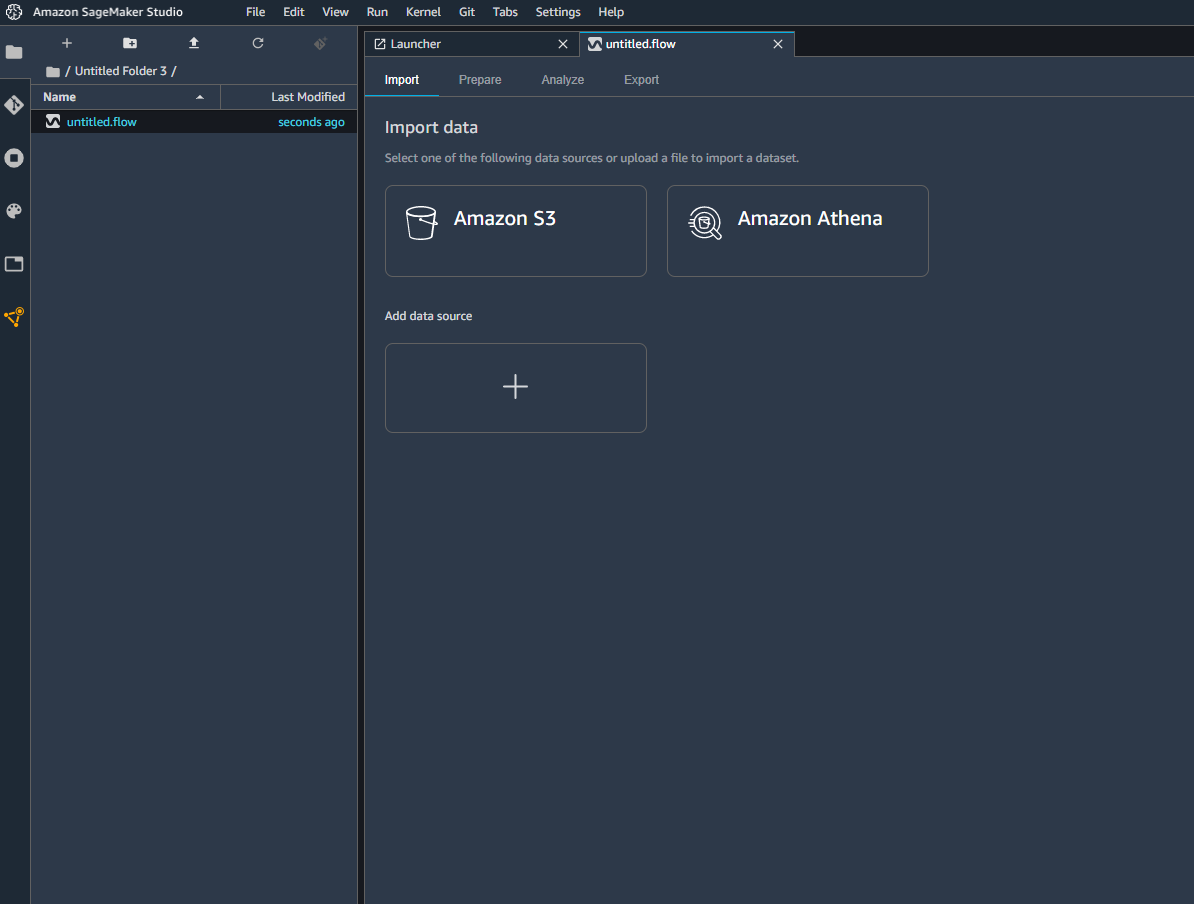
Comme vous pouvez le voir sur l’image ci-dessous, vous pouvez sélectionner rapidement des données à partir de plusieurs sources, telles que S3 ou Athena. Vous pouvez donc faire des requêtes directement sur une base de données pour récupérer les données, ou bien tout simplement rajouter une autre source de données.
Dans notre exemple, on va aller chercher le fichier CSV du dataset Titanic déjà stocké dans S3.
Directement depuis l’interface de sélection de votre source, vous aurez un aperçu des données contenues dans le fichier afin de le valider avant de l’importer.
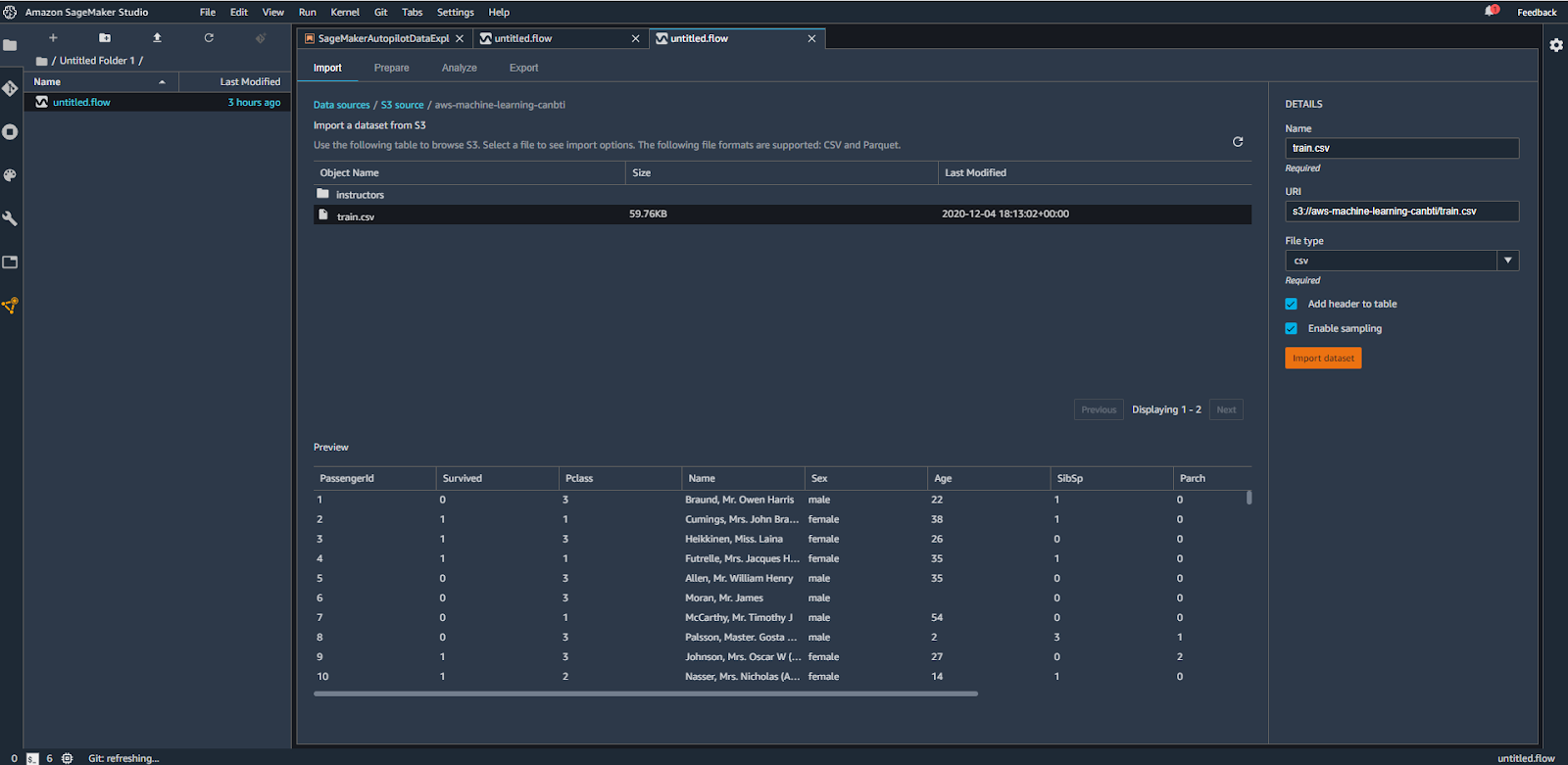
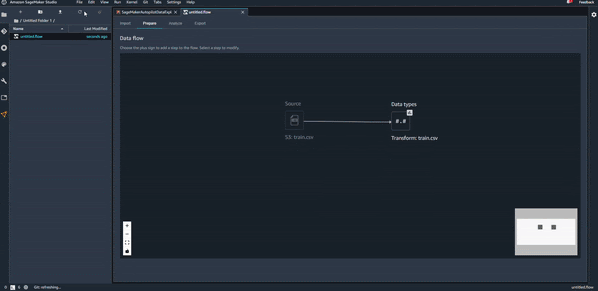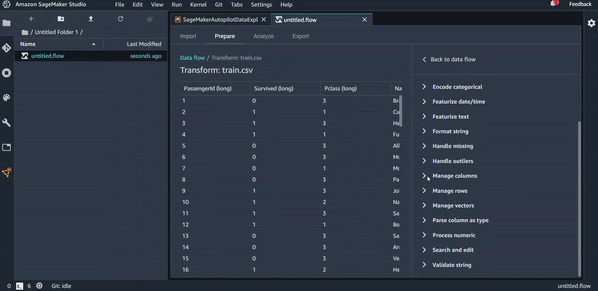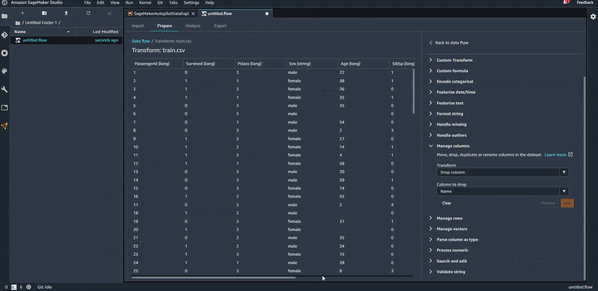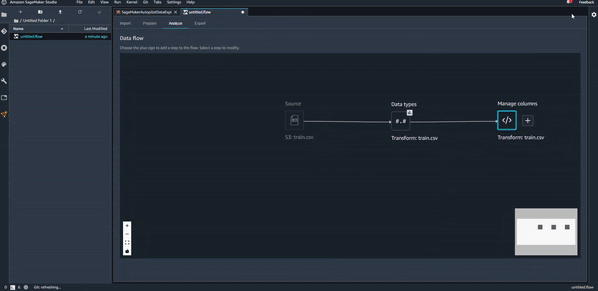
Une fois que le fichier est importé, on peut voir le premier flux de préparation de données avec les deux premiers composants (le fichier source et le début de transformation des données). Voir l’image ci-dessous.
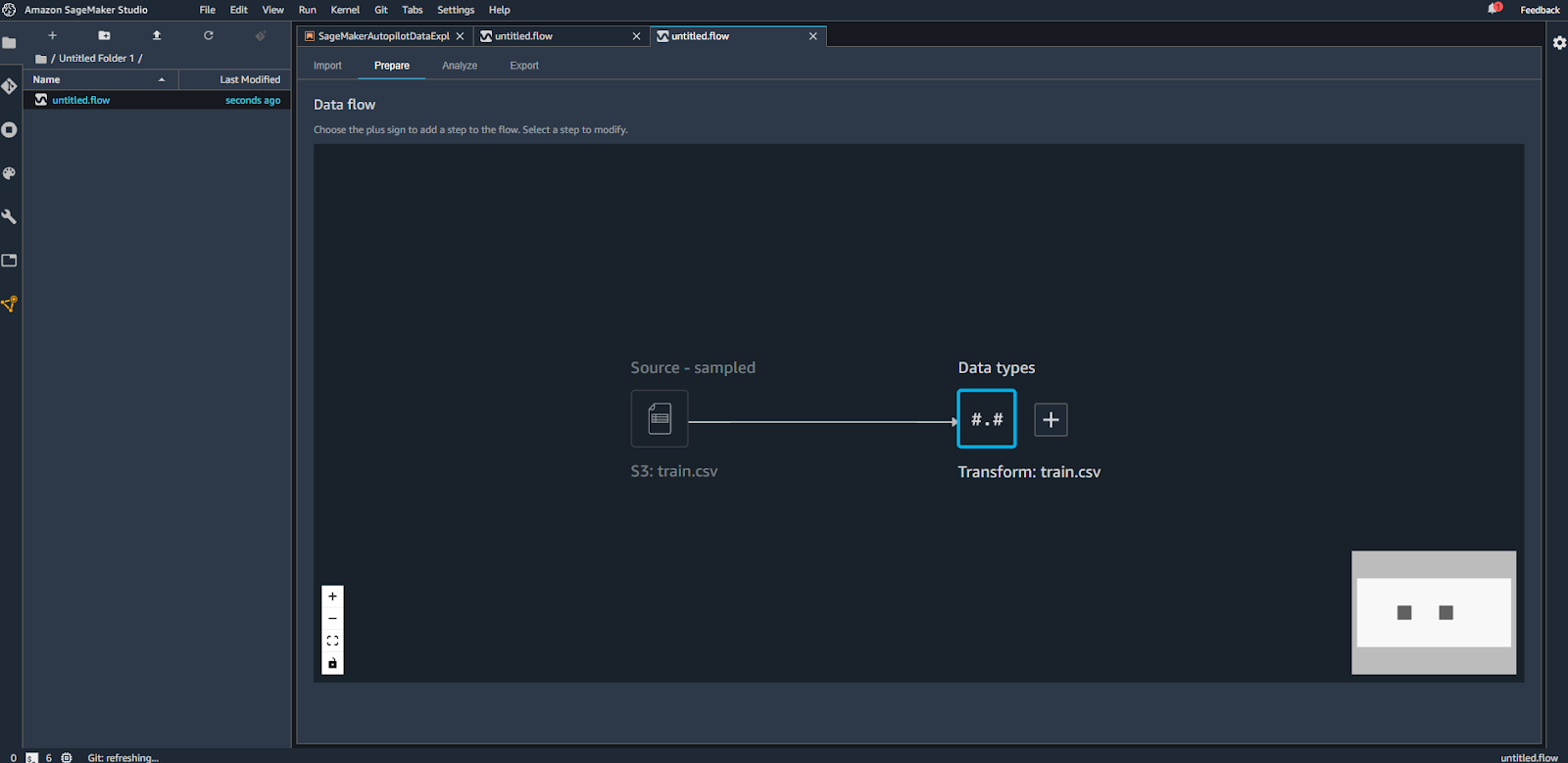
Data Types
Une première étape d’exploration de données qu’on peut imaginer serait de regarder le type des différentes variables du dataset, pour le changer si c’est nécessaire. Vous pouvez voir cela en action sur l’animation suivante :
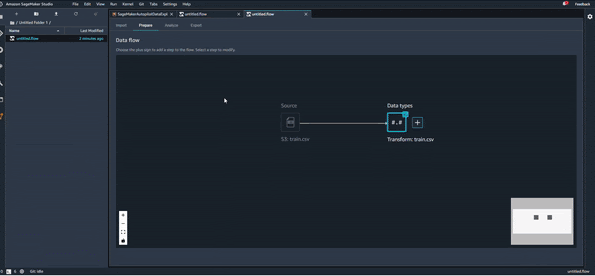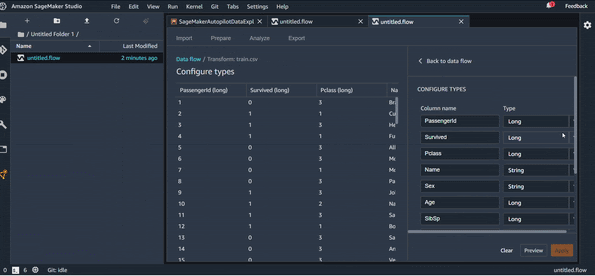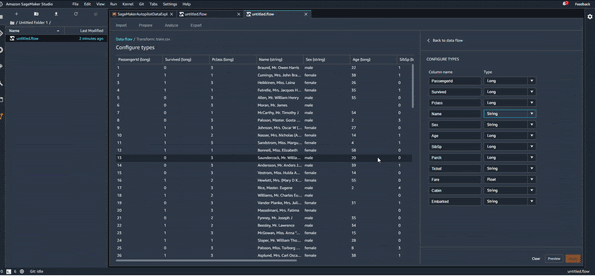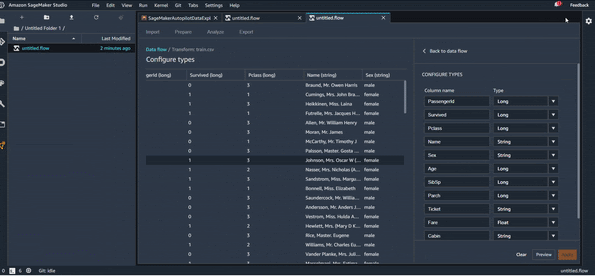
Cela nous permet donc de modifier les types et de consulter les résultats en temps réel. Une fois que tous les changements nécessaires sont faits, on clique sur “Apply” pour valider les changements.
Table Summary
Dans cette partie, nous allons commencer à faire des analyses sur nos données. Comme souvent dans un projet de Data Science, commençons par visualiser le résumé statistique de nos données. Si vous utilisez Python c’est l’équivalent d’un :
df.describe()
Cela va nous permettre de voir la moyenne statistique des variables numériques, l’écart type, etc. Ces informations sont utiles pour avoir une première information sur la distribution des données, même si ce n’est pas visuel.
On va donc donner ensuite un nom à cette visualisation et l’enregistrer dans la liste des analyses “All Analysis”.
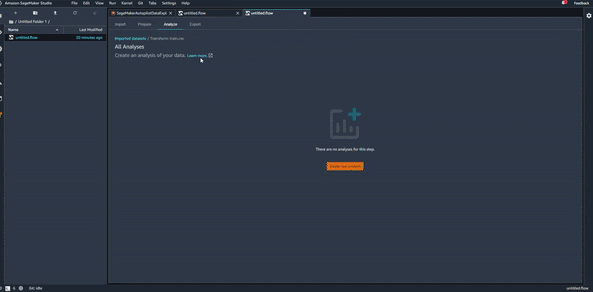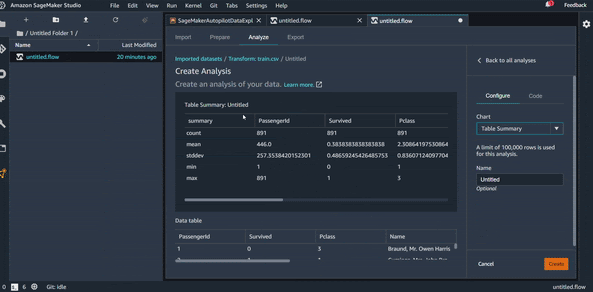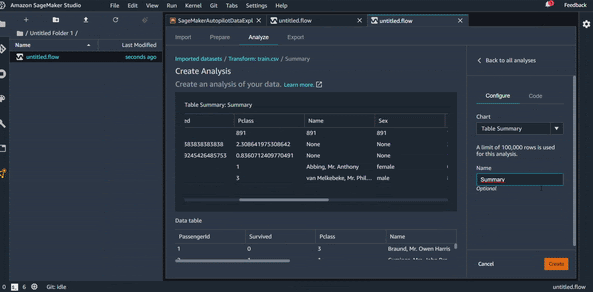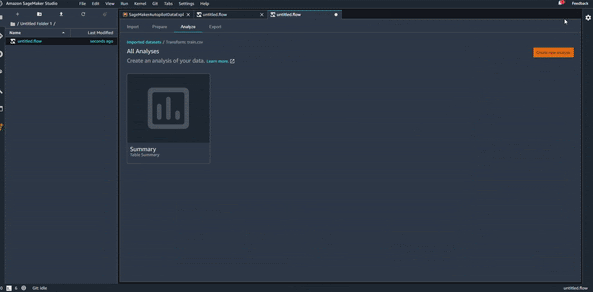
Visualisation
Si la première analyse c’était l’équivalent d’une seule ligne de code en Python, imaginez si vous voulez faire une visualisation complexe qui prend en compte plusieurs variables en même temps. Il faut que cela soit lisible et clair. Cela va sans doute vous prendre un peu de temps. On va donc essayer de faire une visualisation un peu complexe en quelques clics en ajoutant une nouvelle feuille d’analyse.
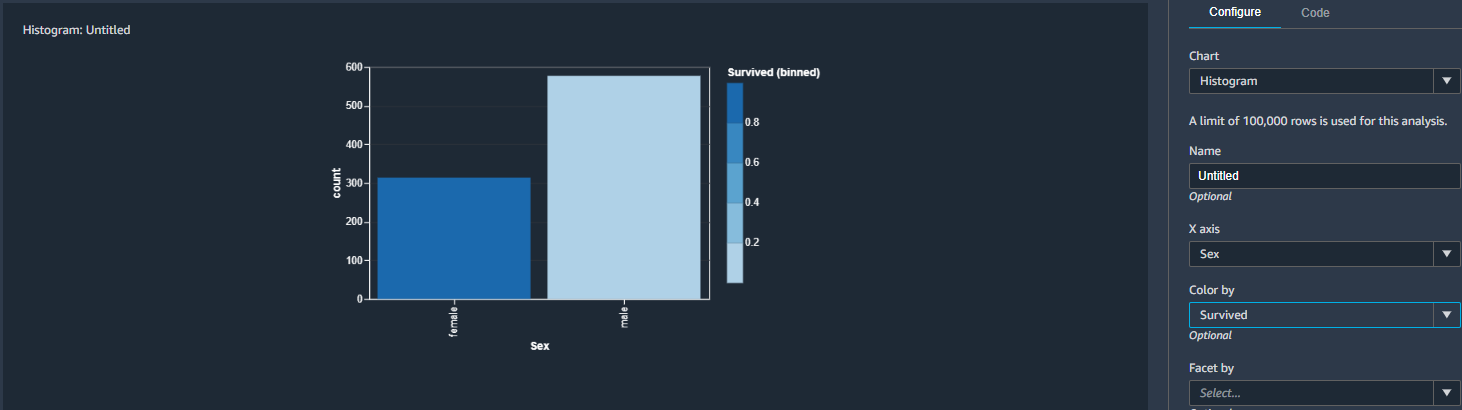
Pour l’exemple, on va essayer de voir à l’aide d’un histogramme la corrélation entre l'âge des passagers, la classe de leur cabine, et le fait qu’ils soient des survivants ou pas.
On vous montre cela sur l’animation suivante :
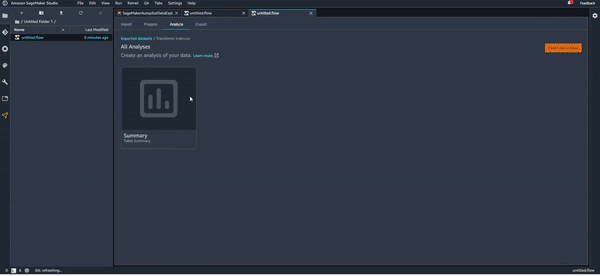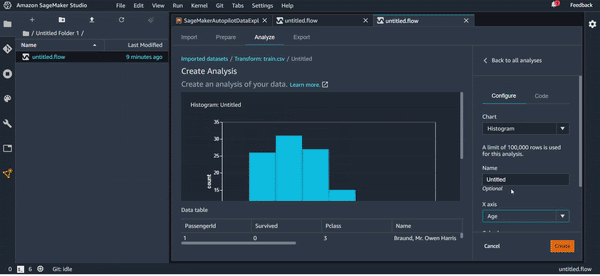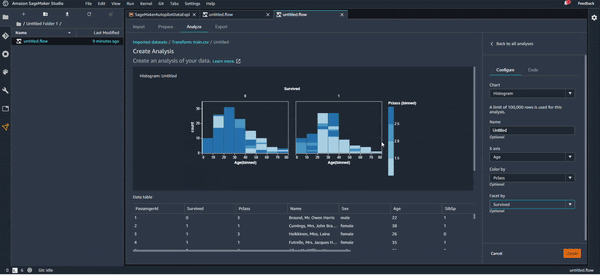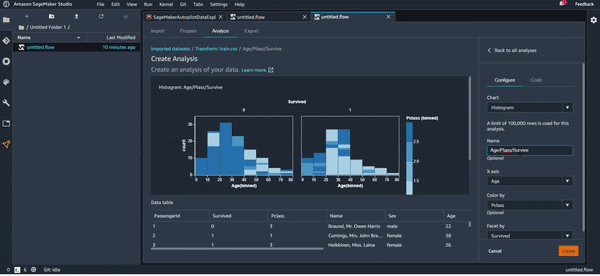
Apparemment, si vous avez entre 10 et 30 ans et si vous êtes dans la troisième classe, vos chances de survie ne sont pas très élevées.
On a pu faire en quelques clics les premières analyses exploratoires, enregistrer les analyses, et on peut passer à la prochaine étape : la préparation des données.
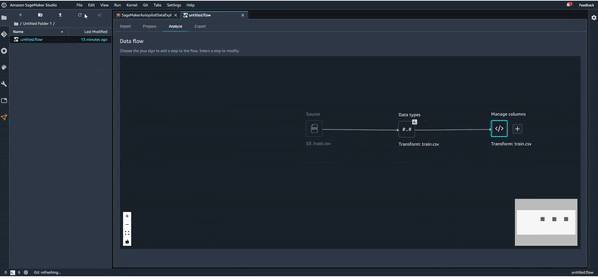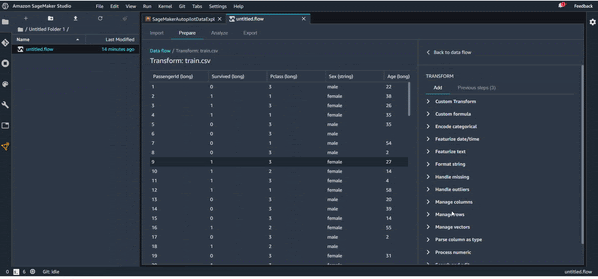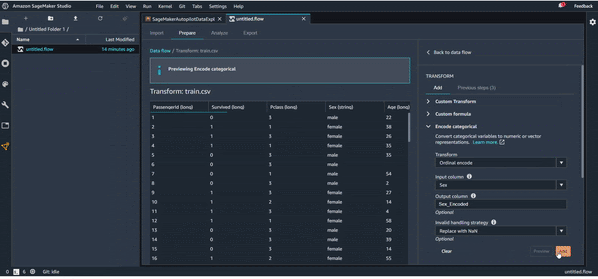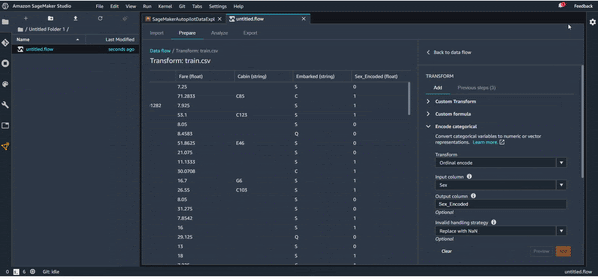
Transformation des données
Vous avez une grande liste de transformations possibles à faire.
Vous pouvez aussi bien sûr gérer les valeurs manquantes, les outliers et plein d’autres transformations possibles.
Pour commencer nos transformations et continuer l’étude de notre dataset Titanic, on va par exemple créer une première transformation pour supprimer la colonne “Name” qu’on juge non pertinente pour la prédiction. Voici la transformation en action :
Comme vous pouvez le voir, la transformation s’ajoute automatiquement à notre flux.
On va essayer maintenant, par exemple, d’encoder la variables “Sex”, qui est une variable catégorique. On va donc remplacer “Male” par 0 et “Female” par 1. Il suffit donc juste de rajouter une transformation et utiliser le bon composant :
Pour les valeurs manquantes, vous avez deux choix : imputation par moyenne ou par médiane. C’est vrai que ce n’est pas toujours les meilleures stratégies d’imputation, mais cela peut aider. Vu que l’outil vient d'être lancé, il va sans doute y avoir des mises à jour avec plusieurs possibilités d’imputation dans le futur.
Comme on va tester un algorithme de prédiction par la suite, il est nécessaire dans SageMaker que la variable target soit la première dans le dataset. On va donc rajouter une dernière manipulation pour déplacer la colonne target “Survived” à la première position :
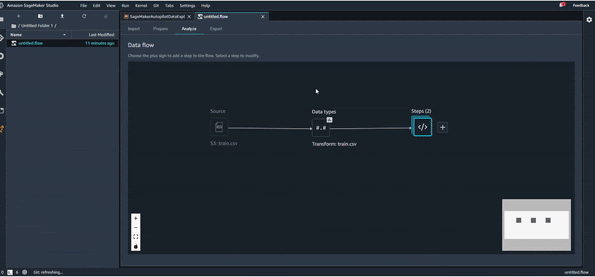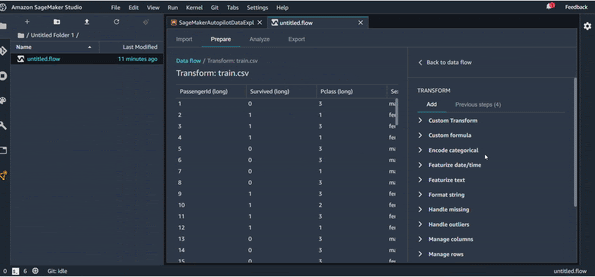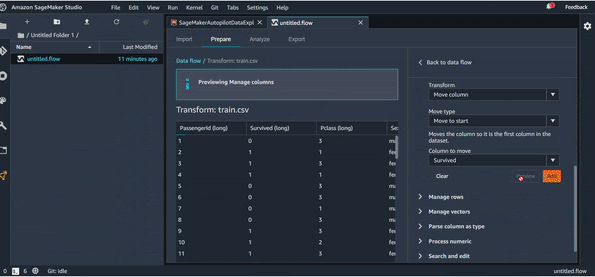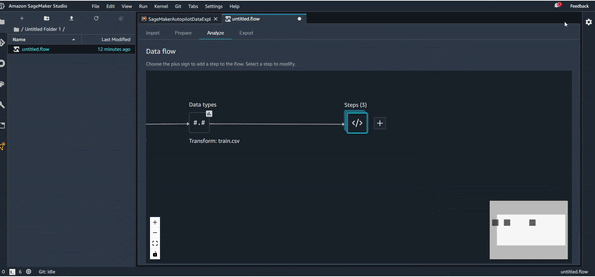
Une fois qu’on a terminé toutes les transformations nécessaires, et organisé notre pipeline de transformation comme on veut, on peut utiliser une dernière astuce très utile qui s’appelle QuickModel, dans l’onglet Analysis.
QuickModel
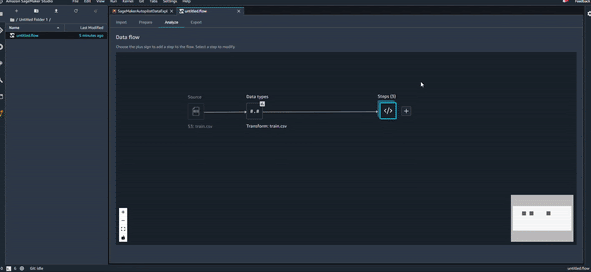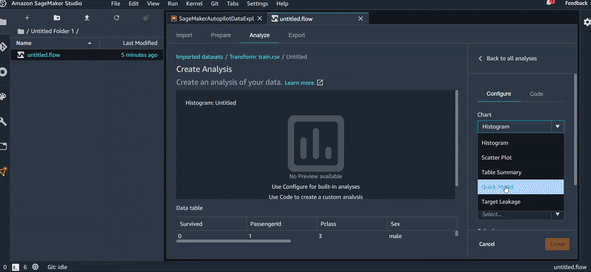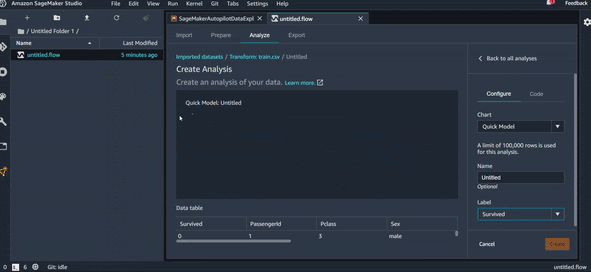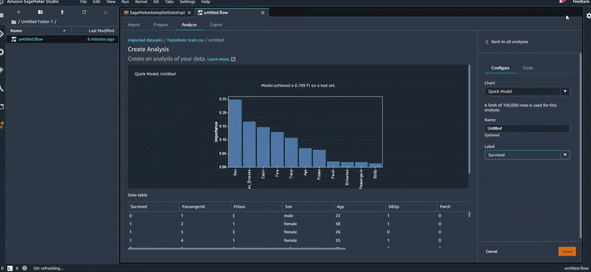
On arrive donc, en quelques secondes à avoir un premier modèle avec un résultat pas mal (F1 de 0.7) et un graphique qui montre les variables les plus importantes pour la prédiction. On peut voir par exemple que la variable “Sex” est la plus importante. Si on fait rapidement une analyse Sex/Survive, on obtient la visualisation dans la figure ci-dessous, qui montre qu’effectivement les femmes ont plus de chance de survie que les hommes. Logique, non !?
La prochaine question est : comment puis-je utiliser toutes ces modifications?
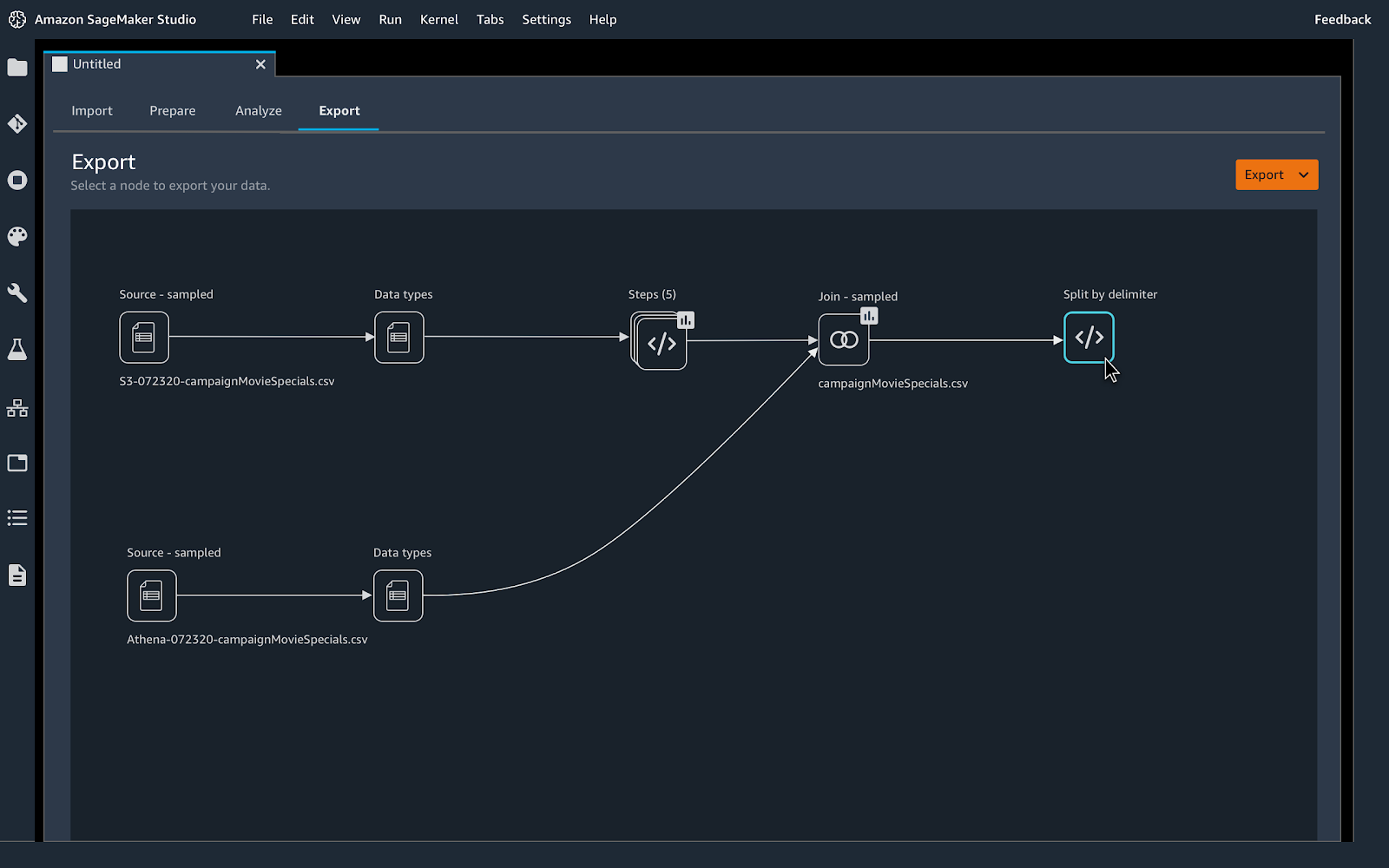
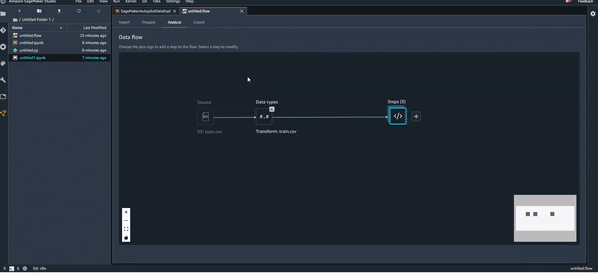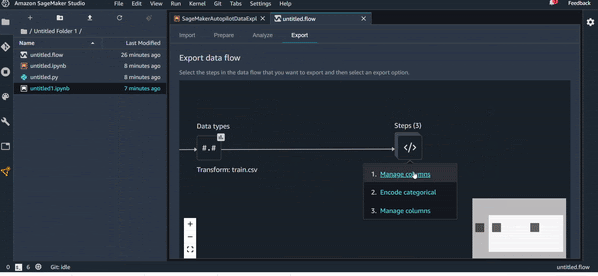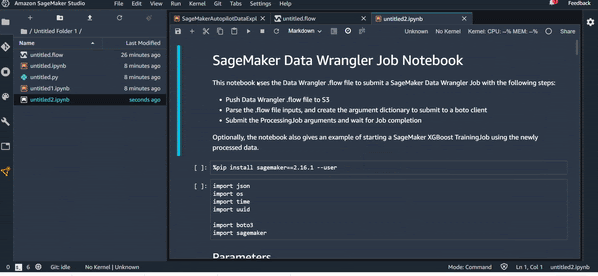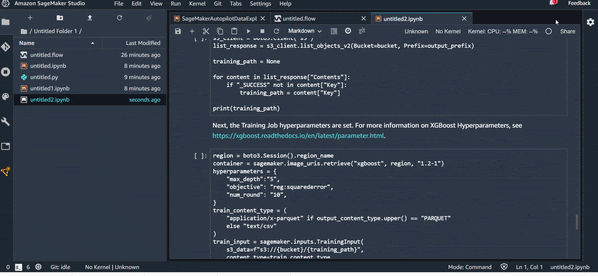
C’est assez simple, on va juste aller à l’onglet Export. Vous avez plusieurs choix pour exporter votre flux de transformation :
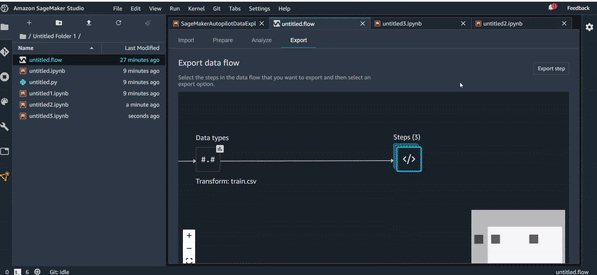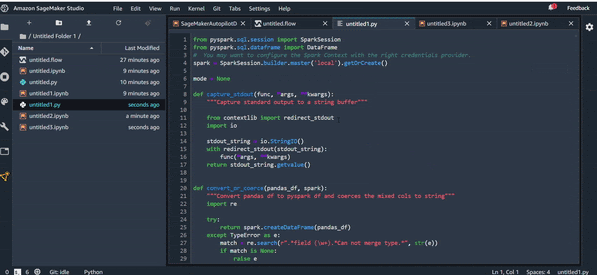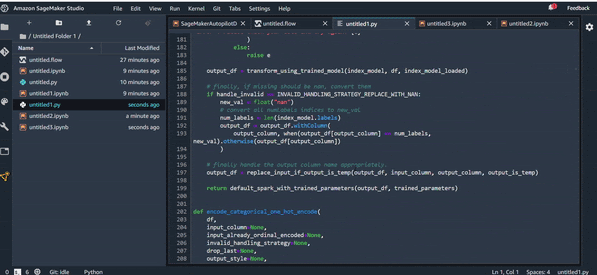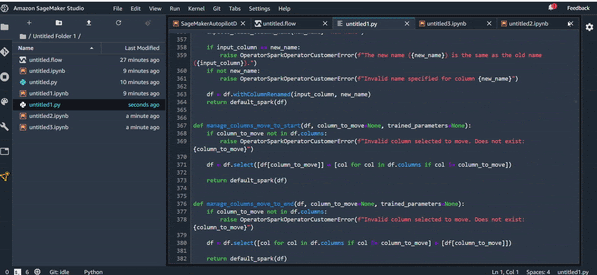
- Code Python : Un code python est généré avec toutes les transformations sélectionnées à la fin ;
- Data Wrangler Job : Un job de transformation que vous pouvez utiliser comme un batch transform job et l’appliquer sur vos datasets ;
- Un pipeline ML : Un notebook est généré pour vous, il stocke un fichier
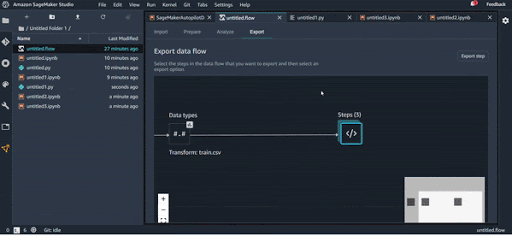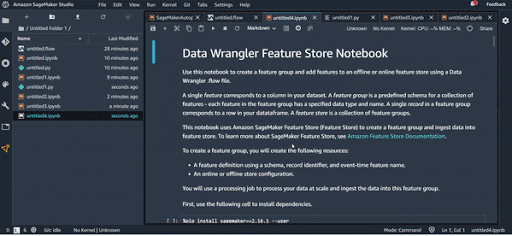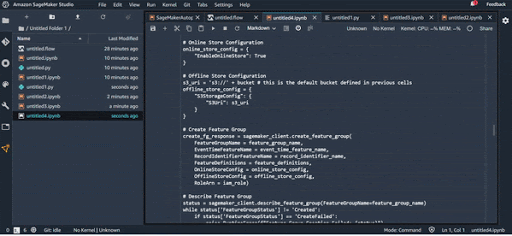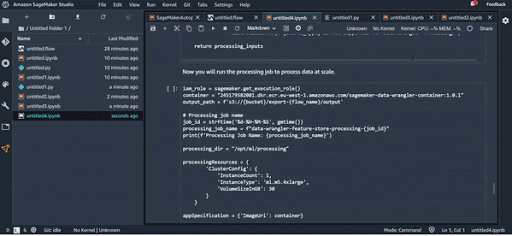
.fluxsur S3, créé un pipeline ML et y ajoute une étape de transformation avec le fichier.flux; - Ajouter au feature store : Créer un feature groupe et y ajouter le fichier Data Wrangler
.flow.
Si vous êtes intéressé par le nouveau service pipeline ML, n’hésitez pas à consulter mon deuxième article (SageMaker ML Pipeline) sur cette deuxième nouveauté sur SageMaker.
Je vous montre désormais comment exporter.
Export Data Wrangler Job :
Export Pipeline :
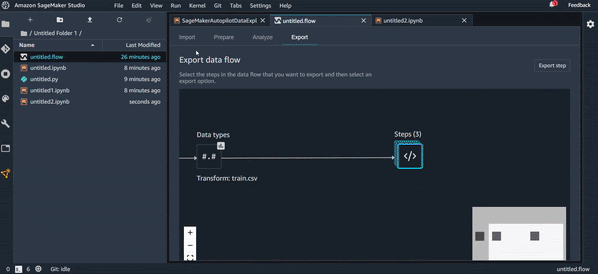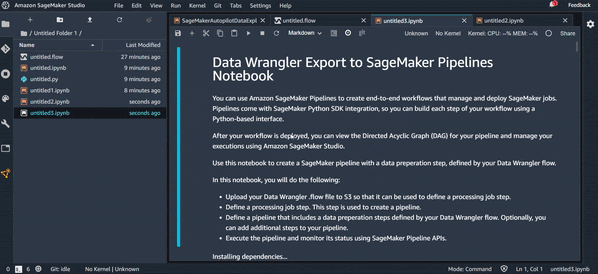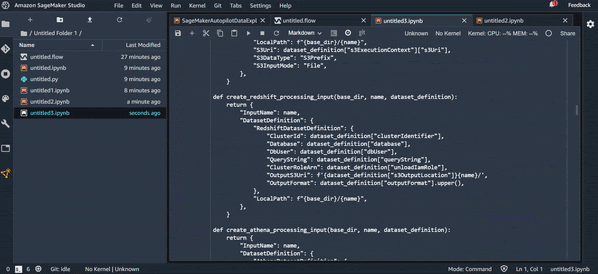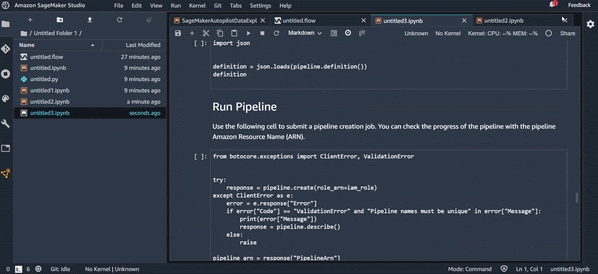
Export Python Code :
Export Feature Store :
Conclusion
Comme vous avez pu le voir, ce nouvel outil (SageMaker Data Wrangler) d’Amazon SageMaker, est vraiment puissant. Il va vous permettre d'accélérer sensiblement vos projets Data Science en toute flexibilité. L’outil vient d'être annoncé et promet pas mal de choses par la suite, comme l’ajout d’autres fonctionnalités de transformation de données et plus de visualisations possibles.
