
À l’occasion du temps fort Data Ippon Technologies, nous vous proposons de découvrir la technologie de base de données Couchbase au travers d’une série de quatre articles.
- Découvrir Couchbase Server
- Couchbase Server : les outils du développeur Java
- La vie d’un cluster Couchbase
- Création d'une application offline avec Couchbase Mobile
Couchbase Server est une base de données NoSQL orientée documents que nous avons utilisée pour le développement d’une application déconnectée (offline).
Pour ce projet nous avions besoin :
- D’un stockage de données schemaless (le formalisme JSON nous convenait parfaitement) ;
- D’une réplication de données inter-sites facile à mettre en place ;
- De haute disponibilité et de sécurité.
Tout au long du projet, Couchbase s’est avéré être le bon choix pour la synchronisation des données. En outre, nous avons pu apprécier beaucoup d’autres aspects de Couchbase Server.
- Couchbase est fortement centré sur la cohérence des donnés ;
- La mise en cluster est particulièrement simple (comme nous vous le montrerons dans un prochain article) ;
- Le développement avec Couchbase est facilité (API RESTful, SDK, Support de Spring Data) ;
- Architecture et administration simples ;
- Bonne documentation.
Dans la suite de ce premier article, nous vous proposons de découvrir concrètement Couchbase Server à l’aide d’un petit guide de prise en main rapide.
Hands On !
Couchbase met à disposition une image Docker nommée sandbox qui fournit un serveur Couchbase prêt à l’emploi et contenant des données d’exemple (https://developer.couchbase.com/documentation/server/5.0/getting-started/do-a-quick-install.html)
À noter : l’image sandbox sert uniquement à jouer avec le serveur de données. Par ailleurs elle n’est pas à jour (et c’est bien dommage) car la dernière version de Couchbase est la 5.1. Pour une installation en production on considèrera les images Couchbase officielles.
Bien qu’OpenSource sous licence Apache 2, Couchbase n’est pas une solution gratuite, même s’il existe une édition Community. Si vous envisagez de l’utiliser sur un projet il faut prendre le temps d’étudier l’édition Enterprise.
https://www.couchbase.com/products/editions
Pour démarrer le serveur, on entre la commande :
docker run -t --name db -p 8091-8094:8091-8094 -p 11210:11210 couchbase/sandbox:5.0.0-beta
A noter : Les ports utilisés par le serveur sont documentés ici : https://developer.couchbase.com/documentation/server/5.0/architecture/connectivity-architecture.html
Notre serveur Couchbase est opérationnel et on peut accéder à l’interface d’administration : http://localhost:8091 [Administrator/password].
L’interface d’administration nous présente un tableau de bord général.
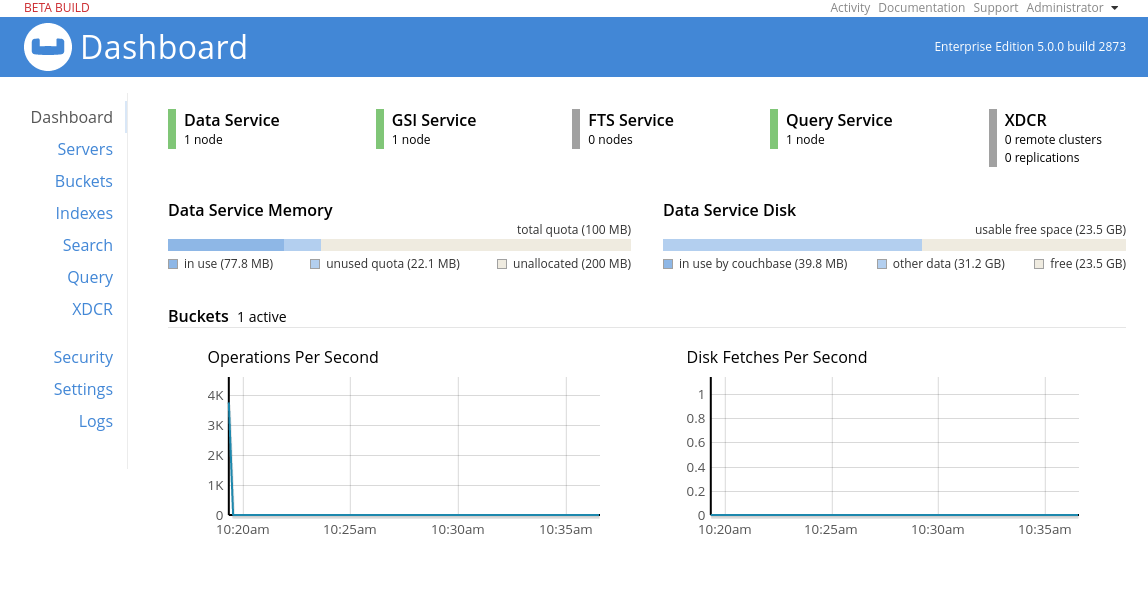
Si nous cliquons sur Servers dans le menu de gauche, nous arrivons sur une nouvelle page contenant l’avertissement "Fail Over Warning: At least two servers with the data service are required to provide replication!".

Que signifie cet avertissement ?
Couchbase est un système de base de données distribué. Cela signifie que Couchbase permet de répartir les données sur un cluster de serveurs (les nœuds) ceci afin d’assurer la disponibilité des données.
Dans notre cas, nous n’avons démarré qu’un nœud. Cela n’empêche pas d’utiliser le serveur mais Couchbase nous avertit qu’en cas de panne, la disponibilité des données n’est pas assurée (concept de Fail Over).
La mise en cluster d’une base de données Couchbase fera l’objet du second article. Pour le moment, nous nous contenterons d’utiliser un seul nœud.
Découverte des données
Dans Couchbase, les données sont portées par des documents exprimés en JSON ; Couchbase est donc un système de base de données NoSQL orienté documents. Ces documents sont rangés dans des Buckets.
Pour faire simple, un Bucket s’apparente à la notion de base de données au sein de votre serveur Couchbase.
Dans le menu de gauche, on choisit l’option Buckets
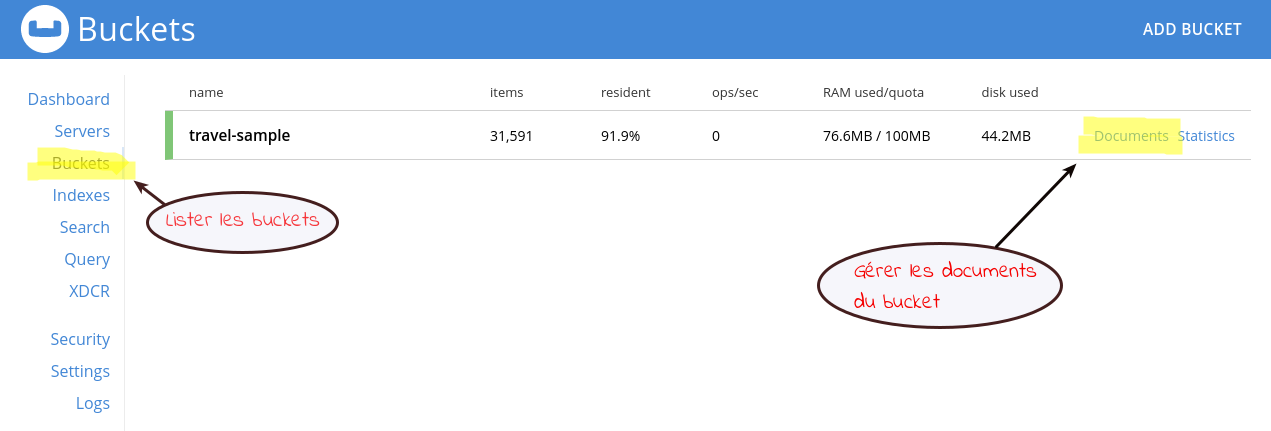
Sur notre serveur, on voit qu’il existe déjà un Bucket nommé travel-sample. Ce bucket contient des documents qui, comme le nom l’indique, modélisent l’activité d’une agence de voyage.
En cliquant sur le lien Documents à droite de l’écran, on accède à une application très complète permettant de gérer les documents du bucket.
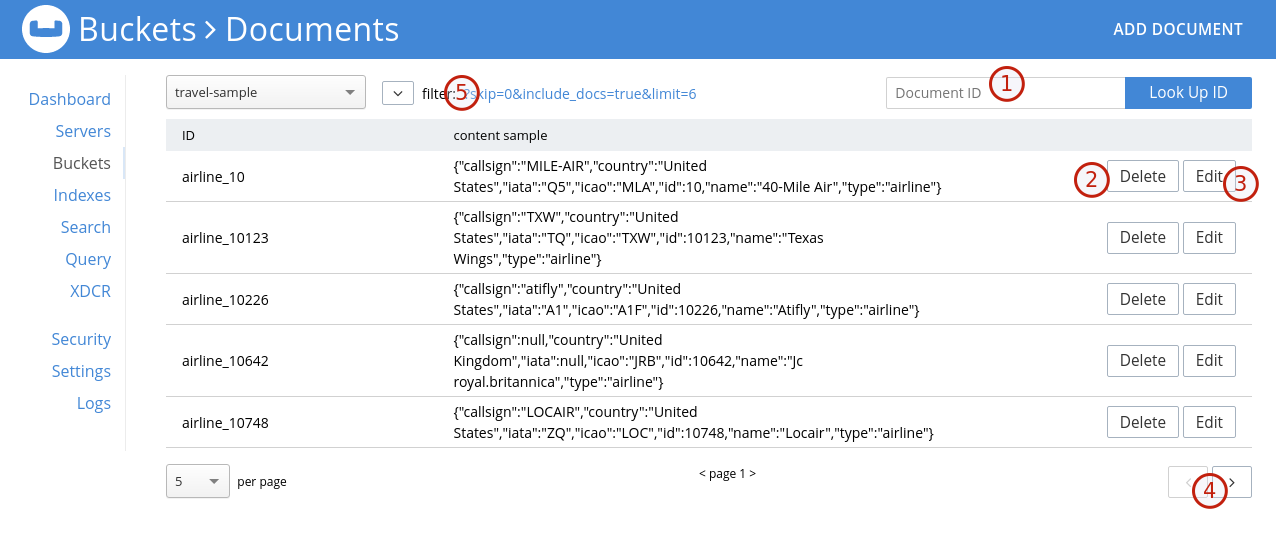
Depuis cette application, on peut administrer les documents, ce qui fait de Couchbase une solution de gestion de données très agréable à utiliser.
-
Rechercher un document à l’aide de son identifiant
-
Supprimer un document
-
Editer un document (c’est-à-dire modifier son contenu)
-
Naviguer dans les documents
-
Filtrer les documents trouvés
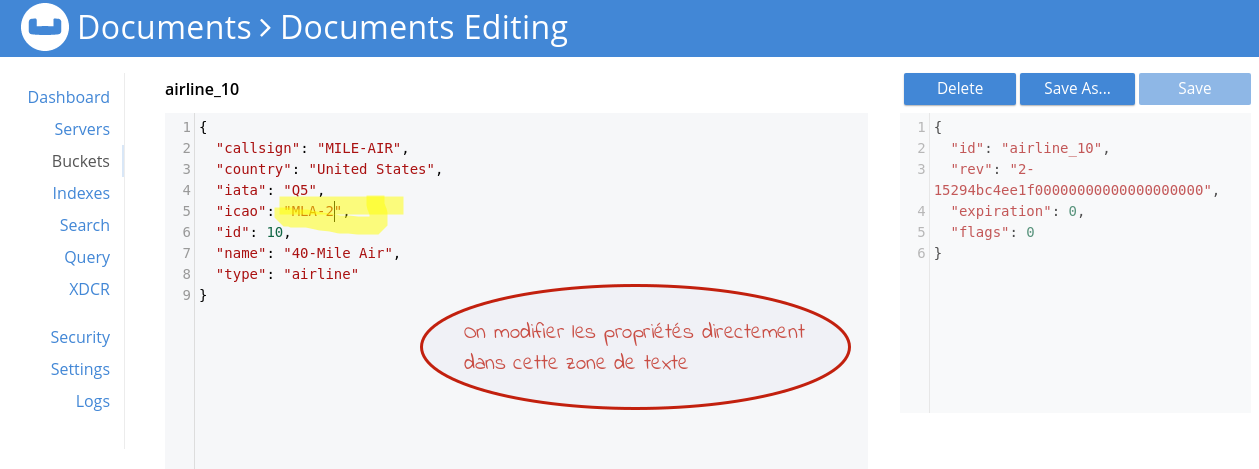
En cliquant sur le bouton  on peut modifier le contenu d’un document.
on peut modifier le contenu d’un document.
Requêtes à l’aide du langage N1QL
Couchbase dispose d’un langage de requête inspiré de SQL: le N1QL.
N1QL est très riche en fonctionnalités. Il permet de rechercher des documents JSON en les filtrant selon les valeurs des champs, d’utiliser des fonctions de calcul, de groupage et même de combiner plusieurs documents à l’aide de jointures.
Voici un exemple de requête avec un filtrage mettant en oeuvre une sous requête.
SELECT DISTINCT t1.city
FROM `travel-sample` t1
WHERE t1.type = "landmark"
AND t1.city IN (SELECT RAW city
FROM `travel-sample`
WHERE type = "airport")
LIMIT 3;
Et voici un exemple combinant deux types de documents à l’aide d’une jointure.
SELECT DISTINCT airline.name, route.schedule
FROM `travel-sample` route
JOIN `travel-sample` airline
ON KEYS route.airlineid
WHERE route.type = "route"
AND airline.type = "airline"
AND route.sourceairport = "BOS"
AND route.destinationairport = "SFO"
AND airline.callsign = "JETBLUE";
On peut exécuter des requêtes N1QL depuis différents environnements :
En outre, l’application d’administration Couchbase dispose d’un écran qui permet d’exécuter facilement des requêtes N1QL.
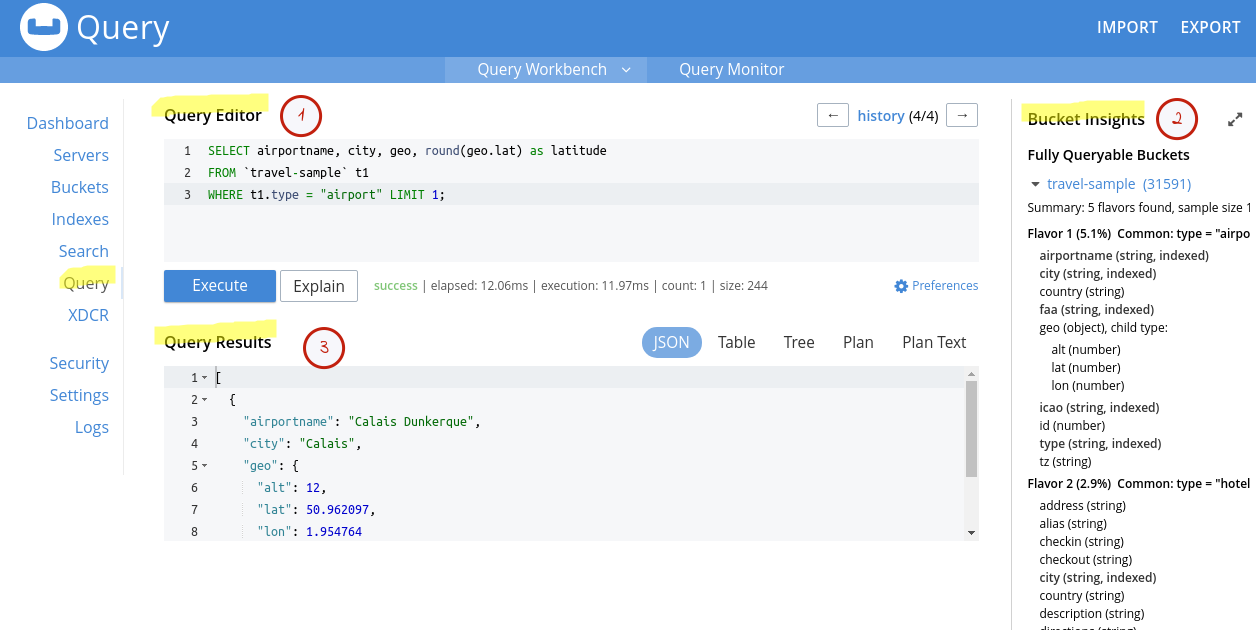
Dans la zone (1) Query Editor on saisit une requête. Dans la copie d’écran ci-dessus, j’ai repris la requête qui est donnée en exemple dans la documentation de référence N1QL.
Les résultats retournés par l’exécution de la requête sont affichés dans la zone (3) Query Results. On dispose de plusieurs options de présentation des résultats, ce qui est très agréable.
Présentation JSON :
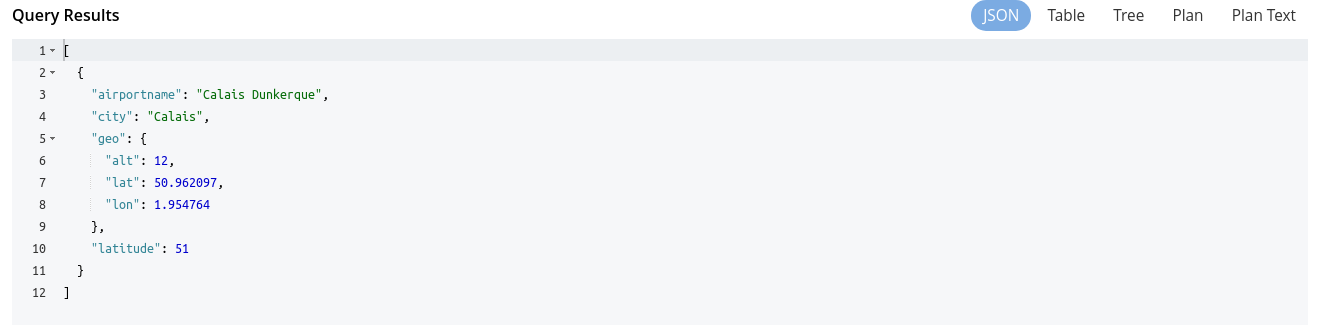
Présentation tableau classique :

Enfin la zone (2) Bucket Insights donne une vue des types de documents présents dans la base.
Cette fonctionnalité est très utile ; en effet, dans une base de données NoSQL orientée documents, le schéma de données n’est pas figé, il peut exister au sein d’un bucket toute sorte de documents ayant des formats très divers.
Ainsi lorsque l’on doit exécuter une requête pour rechercher des documents, il faut connaître à priori le format des documents que l’on cherche.
Ici, Couchbase nous aide à nous repérer dans la base en effectuant des statistiques sur des types de documents similaires (Flavor).
Par exemple, selon l’extrait d’écran ci-dessous, Couchbase nous indique que la base est constituée d’environ 6,2% de documents "similaires" ayant le type airport.

Notons ici que Couchbase se base sur le champ type pour inférer des types de documents. Le champ type n’est pas obligatoire mais c’est une bonne pratique d’en prévoir un.
En effet, dans un même bucket, on peut faire cohabiter des documents de différentes formes. Dans une base de données relationnelle, ce sont les tables qui nous permettent de ranger les données. Mais dans une base de données orientée documents, nous n’avons pas de table donc le classement des données par type ne peut se faire que par les propriétés des documents.
Notons que le champ servant à "typer" les documents peut porter n’importe quel nom ; c’est ce que nous allons voir dans la suite de l’article.
Créer un bucket (conteneur de données)
Pour créer un conteneur de données il suffit de créer un Bucket. Pour cela, il suffit de cliquer sur le bouton (1) ADD BUCKET dans le tableau de bord des buckets.
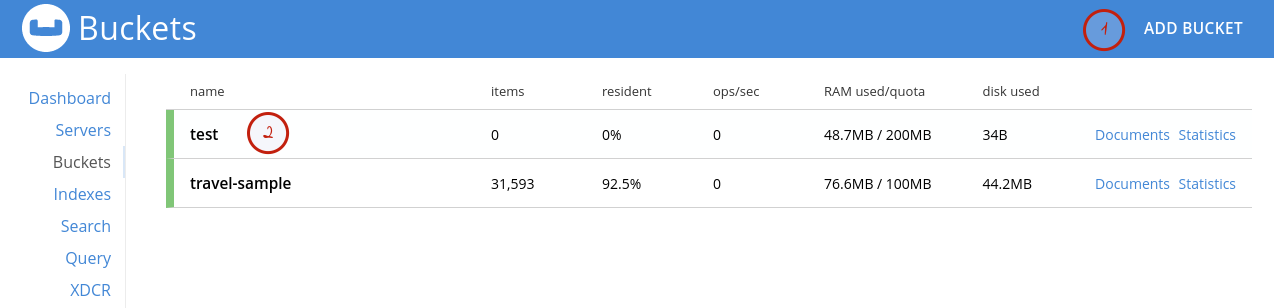
La copie d’écran ci-dessus montre que j’ai créé un bucket nommé test (2).
On commence ensuite à ajouter des documents dans le bucket.
La structure des documents est libre.
Depuis le bucket, on clique sur Documents, puis ADD DOCUMENT. Dans une popup, on saisit l’identifiant unique du document. Là encore on est libre sur le format de l’id.
On saisit ensuite le contenu du document en JSON.

Et on sauvegarde.
On remarque qu’il n’y a pas de champ type dans le document. En revanche, j’ai nommé un champ categorie qui jouera le rôle de type de document.
Pour pouvoir exécuter des requêtes N1QL sur le bucket test il faut lui ajouter un index primaire. Cela se fait en exécutant l’ordre N1QL suivant :
CREATE PRIMARY INDEX on test
A partir de ce moment, si on regarde la vue Bucket Insights on remarque que Couchbase a détecté (inféré) des types de documents.
Et dans notre cas, c’est le champ categorie qui sert à classer les documents.

Comment continuer ?
Documentation Couchbase 5.0 : https://developer.couchbase.com/documentation/server/5.0/introduction/intro.html
Découvrir l’API REST : https://developer.couchbase.com/documentation/server/5.0/rest-api/rest-intro.html
Tout comprendre sur Couchbase : https://developer.couchbase.com/documentation/server/5.0/concepts/concepts-intro.html
Découvir le SDK : https://developer.couchbase.com/documentation/server/5.0/sdk/nodejs/start-using-sdk.html
Se former en ligne :
https://training.couchbase.com/online
Le blog Couchbase contient publie des articles souvent très intéressants : https://blog.couchbase.com/
Articles recommandés :
https://blog.couchbase.com/moving-from-mongodb-to-couchbase-server/
https://blog.couchbase.com/10-things-developers-should-know-about-couchbase/
