

Dans cette suite d'articles, nous allons discuter de la mise en place d'une plate-forme Big Data utilisant l'orchestrateur Kubernetes.
Kubernetes étant en effet le sujet du moment, notamment en ce qui concerne l'utilisation de conteneurs avec des microservices.
Ce premier article n'est pas une présentation détaillée de Kubernetes, mais vous fournit tous les éléments nécessaires à la compréhension des notions évoquées.
De même que l'on n'insistera pas sur l'écosystème des orchestrateurs de conteneurs mais constaterons simplement que Kubernetes semble pour l'instant avoir gagné la bataille.
En 2018, Kubernetes représentait 51% du marché des orchestrateurs contre 11% pour Docker Swarm et 4% pour Mesos (Cf. Docker Usage Report 2018).
Introduction Kubernetes
Kubernetes est un système de gestion de conteneurs et plus particulièrement un orchestrateur. Il est, à l'origine, un projet Google disponible depuis juin 2014.
Il est le résultat de la réécriture en Go du système Borg (et d'Omega son successeur) que Google utilise en interne pour gérer son infrastructure.
Kubernetes a été versé à la Cloud Native Computing Foundation (CNCF) qui a pour vocation de s'assurer de la bonne exécution des applications dans des environnements cloud.
On retrouve dans cette fondation des produits tels que Prometheus, Fluentdb, Envoy, ...
Kubernetes n'est pas uniquement destiné au Cloud mais à tout type d'infrastructure. Un de ses points fort étant de permettre de faire de l'Infra As Code.
Depuis la version 1.10 (Mars 2018), Kubernetes prend plus de distance avec Docker et peut gérer un ensemble de technologies de conteneurs qui vont respecter la norme Container Runtime Interface (Docker, RKT, LXD, ...).
Principaux composants
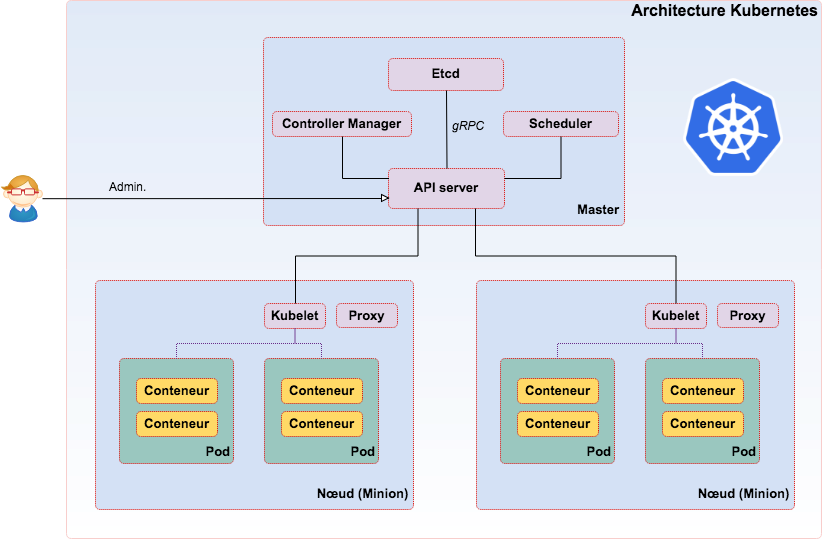
Dans un cluster Kubernetes, on distingue le nœud maître qui va piloter les nœuds esclaves (appelé « minions » ou « nodes »).
Master, serveur maître qui exécute les services suivants :
-
API Server : interface centrale qui permet d'exécuter les commandes sur le cluster.
-
Etcd : stocke les fichiers de configurations du cluster (stockage clé/valeur distribué).
-
Controller-manager : regroupe un ensemble de contrôleurs en charge de vérifier :
- l'état des nœuds,
- le bon nombre de réplicas de Pods dans le cluster,
- lier les services aux Pods,
- gérer les droits d'accès aux différents espaces de noms utilisés dans le cluster.
-
Scheduler : s'occupe d'assigner un nœud disponible à un Pod.
-
Service DNS : intégré à Kubernetes, les conteneurs utilisent ce service dès leur création pour la résolution de nom à l'intérieur du cluster.
Sur chaque nœud (minion) :
- Kubelet : en charge du bon fonctionnement des conteneurs sur le nœud (communique avec le serveur maître)
- Kube-proxy : gère le trafic réseau et les règles définies. Permet d'accéder aux autres conteneurs pouvant se trouver sur d'autres nœuds.
- Pods : unités éphémères d'exécution d'applications Stateless. Il est composé d'un ensemble de conteneurs et de volumes interconnectés.
- Fluentd : se charge de transférer les logs vers les serveurs maîtres.
Operators : Kubernetes 1.7 a ajouté la possibilité de personnaliser les contrôleurs. Cela permet aux développeurs d'étendre et d'ajouter de nouvelles fonctionnalités, de remplacer les fonctionnalités existantes et d'automatiser les tâches d'administration comme s'il s'agissait d'un composant natif de Kubernetes.
Les opérateurs Kubernetes permettent de customiser le comportement standard et de tenir compte des spécificités des solutions. Ce sont donc de vrais plus pour l'intégration d'une solution avec Kubernetes.
ReplicaSet
Service récent dans l'histoire de Kubernetes, il est en charge de la réplication des Pods dans Kubernetes (remplace le ReplicationController), il permet de créer plusieurs répliques d'un même Pod, et s'assure que le total soit conforme au nombre souhaité. Il redémarrera ou détruira des conteneurs afin qu'il y ait toujours n réplicas opérationnels du Pod.
StatefulSets
Apparus en bêta avec la version 1.5 de Kubernetes (décembre 2016) et stables depuis la version 1.9, ils permettent de rendre stateful les applications déployées dans des Pods.
Avec les StatefulSet, les Pods ont une identité réseau fixe et un stockage persistant.
Chaque Pod du StatefulSet est identifié par un nom d'hôte dont le pattern est déterministe et contenant le numéro d'ordre du Pod dans le Replica.
Cette fonctionnalité permet aussi d'attacher un volume persistant à un Pod et de maintenir sa connexion même si le Pod est redéployé sur une autre machine.
Depuis la version 1.10, Kubernetes permet d'étendre cette fonctionnalité aux disques locaux. Si un Pod utilisant un disque local se crashe, le même Pod sera reprogrammé sur la même machine afin de réutiliser les données s'y trouvant.
L'avantage est double :
- Apporter de l'optimisation en utilisant des disques locaux.
- Fournir une architecture adaptée aux solutions gérant elles-mêmes la réplication des données.
Ces évolutions sont essentielles pour le Big Data car elles permettent de garantir la non perte des données stockées et la continuité des connections réseaux suite à un arrêt/relance ou le démarrage d'une nouvelle instance.
NB : Étonnamment, les solutions que nous allons détailler utilisent encore peu cette fonctionnalité.
Headless services
Ce type de service est beaucoup utilisé dans les solutions Big Data que nous allons présenter.
C'est un service (une API) qui est en charge de la découverte (et uniquement cela) des Pods. Il sert à recenser les Pods composant le ReplicaSet Kubernetes et favorise leur déploiement sur différents nœuds en cas de crash.
Il n'y a généralement pas de load balancing ni d'IP fixe. Ce service n'est donc pas a priori joignable en dehors du cluster (en interne, le service DNS est utilisé).
Le marché des orchestrateurs
Il existe de nombreux orchestrateurs de ressources et on peut citer les produits suivants :
- Apache Mesos/Marathon,
- Apache YARN,
- Docker/Swarm,
- Rancher.
Par comparaison, Kubernetes a été testé avec des milliers de nœuds alors que Mesos a été testé avec des dizaines de milliers.
Pour compliquer encore plus la lecture du marché des orchestrateurs, DC/OS de Mesosphere, Rancher et Docker ont annoncé le support de Kubernetes.
On peut aussi citer OpenShift qui depuis la version 3 s'appuie sur Kubernetes.
Support Kubernetes dans le cloud
Petit à petit, tous les éditeurs se mettent à Kubernetes, Google ayant été le premier à fournir une offre dédiée, suivi par Microsoft. Concernant Amazon, même si AWS Elastic Container Service est compatible, le service dédié EKS n'a été officiellement lancé que le 5 juin 2018.
Voici la liste des principales offres Cloud :
- Microsoft Azure Container Service (ACS)
- Amazon Elastic Kubernetes Service (EKS)
- Google Kubernetes Engine (GKE)
- IBM Cloud Container Service (CCS)
- Alibaba Cloud Container Service
- ...
Kubernetes en résumé
Avant de se focaliser sur son application dans le mode du Big Data voici les principales caractéristiques de Kubernetes :
- Fourni un framework capable de définir l'infrastructure d'une application quel que soit le fournisseur.
- Repose sur etcd et des conteneurs.
- Possède une communauté très établie.
- Est très complet malgré son jeune âge car issu du savoir-faire de Google.
- Supporte des clusters bare-metal et dans le cloud.
- Est Open Source et écrit en Go.
Kubernetes et le Big Data
Si Kubernetes a montré tout son intérêt dans les architectures micro-services, les contraintes du Big Data sont différentes et demanderont des adaptations.
Voici d'abord les promesses de l'utilisation de Kubernetes dans le Big Data :
- Unification de la gestion des ressources quelle que soit la solution sous-jacente,
- Diminue les cycles de développement et de déploiement (en permettant la réutilisation des builds/code sur tous les environnements),
- Procédure native de Rolling Upgrade des Pods,
- Portabilité entre les différentes plateformes (Cloud/on-Premise),
- Optimiser l'utilisation des ressources de l'infrastructure IT avec une meilleure isolation entre les différents types de traitements,
- Gestion automatique du failover avec les ReplicaSets,
- Augmentation automatique du nombre de réplicas quand la charge devient trop importante pour le nombre de répliques existantes.
Un besoin d'unification
L'écosystème Big Data est très vaste et se pose régulièrement la question de l'unification de la gestion des différents composants.
Jusqu'ici, aucun système n'a permis d'uniformiser les besoins tels que :
- l'attribution des ressources,
- le monitoring,
- le déploiement,
- ...
Même si, avec la récente sortie de Hadoop 3.0, le gestionnaire de ressources YARN peut également contrôler les conteneurs Docker, YARN n'est pas compatible avec toutes les solutions.
Kubernetes gère tous les cycles de vie contrairement à Yarn/Mesos :
- Déploiement,
- Sécurité,
- Scalabilité,
- Scheduling des ressources.
Les challenges
Afin de devenir le standard de gestion des processus Big Data, Kubernetes devra résoudre les problématiques suivantes.
Utilisation des ressources
La gestion des ressources dans le Big Data est un processus rendu complexe à cause :
- des nombreuses ressources : CPU/RAM/Disque/Réseau/Carte graphique
- des types de charges : Batch, temps réel
- de la nature des solutions : Traitement, stockage, requêtage
En termes de ressources, Kubernetes gère les CPUs, la RAM et les GPUs.
Certaines fonctionnalités natives de Kubernetes permettent déjà de maximiser l'utilisation des ressources :
- bin packing : place automatiquement les conteneurs en fonction de leurs besoins en ressources.
- Scalabilité : possibilité d'automatiser l'ajout de répliques afin de répondre à une augmentation de la charge en fonction de l'utilisation du processeur ou de métriques personnalisées.
Kubernetes propose la fonctionnalité suivante pour faciliter le multi-tenant :
- Namespace : Méthode d'isolation logique, des applications Kubernetes. On peut appliquer des quotas de ressources à des Namespaces.
Enfin depuis la version 1.8 et supérieure il est possible de donner une priorité aux Pods.
Cette priorité permet de préciser à Kubernetes l'importance d'un Pod par rapport aux autres Pods. Ainsi lorsqu'un module ne peut pas être planifié faute de ressources disponibles, le planificateur tente d'évincer les modules de priorité inférieure.
Cette fonctionnalité permet aussi d'ordonner les modules en attente de planification.
Data locality
On appelle Data Locality la possibilité d'exécuter un traitement sur le nœud où les données sont stockées.
L'intérêt étant de minimiser le transport de données sur le réseau.
Ce paradigme est parfois remis en cause, car il ne permet pas la spécialisation des nœuds (certains optimisés pour le stockage/traitement) et parce que la multiplication des traitements entraîne de fortes contentions sur l'accès aux données.
Toutefois, cette possibilité est importante afin de garantir des temps de traitements optimisés.
Il existe une possibilité offerte par Kubernetes afin d'offrir cette fonctionnalité, l'affinité des PODs.
L'affinité des Pods permet de définir des affinités de déploiement entre plusieurs Pods et donc de placer un Pod de traitement sur le même nœud qu'un Pod de données.
La garantie est donc déportée sur le système de traitement qui doit déterminer que deux Pods sont sur un même nœud.
Malheureusement, la plupart des frameworks se basent sur le nom d'hôte (hostname) afin de localiser les données et avec Kubernetes chaque Pod en possède un, différent du nœud sur lequel il est abrité. Deux Pods sur un même nœud seront donc vus comme distants.
Une solution consiste donc à déployer solution de stockage et de traitement dans le même Pod.
Sécurité
La sécurité a été prévue dès le départ dans Kubernetes.
Chaque cluster a sa propre autorité de certification et tous les nœuds ont accès au certificat.
La communication entre les nœuds utilise HTTP/2 et est donc sécurisée par TLS.
Kubernetes supporte l'intégration avec LDAP, SAML, Kerberos...
Cette sécurité est interne à Kubernetes, elle n'est donc pas, faute d'intégration, disponible pour les solutions.
Il faudra un gros effort de standardisation des solutions Big Data pour qu'une seule solution de sécurité s'impose.
Performances
Kubernetes devra prouver qu'il peut être aussi performant que des solutions de conteneur et même pouvoir se comparer à des déploiements directs sur des machines.
Kubernetes profite pleinement des progrès des conteneurs en matière de performances :
Enhanced platform awareness in kubernetes performance benchmark report
Bare-metal performance for Big Data workloads on Docker containers
Aujourd'hui, il n'est donc plus impensable d'offrir des performances équivalentes avec des conteneurs.
Spécificités du Big Data
Il faut comprendre les spécificités de la solution afin d'en gérer le cycle de vie :
- Démarrage d'un cluster (ordre, configuration, …),
- Répartition des données,
- Les services accessibles à l'extérieur du cluster.
Contrairement au monde des microservices où les Pods d'un même service sont strictement identiques, ce qui n'est pas le cas dans le monde du Big Data.
Certaines valeurs de configuration sont spécifiques à un Pod (emplacement dans le Rack, le DataCenter, ...).
La gestion des rolling restart et des mises à jour qui demandent des précautions particulières :
- Atteindre un certain état avant de passer au nœud suivant.
- Comprendre que certaines valeurs sont statiques dans Kubernetes et que cela nécessite un redémarrage pour la prise en compte.
Dans le second article, nous présenterons l'intégration des principales solutions utilisées dans le Big Data avec Kubernetes.'
