

Nous avons vu dans mes précédents articles Les architectures Serverless et Comment faire du Serverless une description de ce qu’est le Serverless, les avantages et les contraintes de ces services ainsi que les différents cas d’usages. Mais qu’en est-il d’une utilisation dans le monde professionnel ou même de sa capacité d’industrialisation et de son intégration dans des pratiques comme l’agilité ?
Dans la série d’articles qui va suivre je vous parlerai de concepts d’architectures, de choix techniques et de bonnes pratiques qui vous aideront à construire votre kit de survie lors du démarrage d’un nouveau projet d’application REST Serverless.
Mais avant de rentrer dans le vif du sujet, un petit mot d’avertissement. Malgré les nombreux avantages que les technologies Serverless ont à offrir, certains services comme le FaaS ne possèdent pas encore la maturité ou le niveau de performance nécessaire pour ce cas d’utilisation et peuvent impacter l’expérience de vos utilisateurs.
Un monolithe en Serverless ?
Et si on faisait des Monolithes en Serverless ?
Nombreux d’entre vous seront probablement pris de spasme et voudront oublier à jamais la lecture de ces quelques mots si lourds de sens. Mais laissez-moi vous expliquer.
Prenons l’exemple d’un projet Web standard et étudions sa structure :
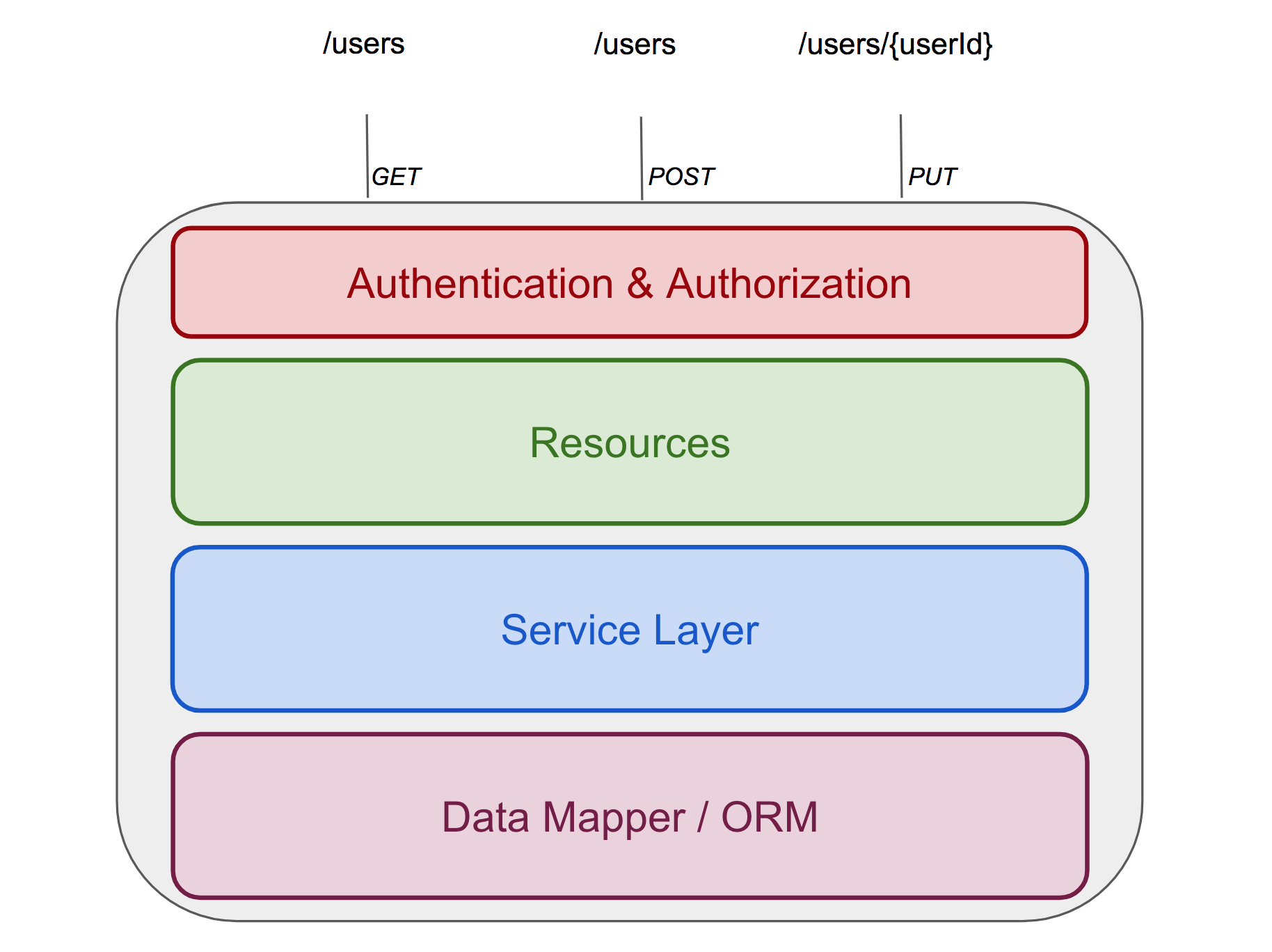
Nous retrouvons tous les ingrédients d’une architecture Monolithique avec les différentes couches qui la constituent :
- Accès aux données
- Services métier
- Endpoints REST
- Sécurité
Maintenant intéressons-nous à l’impact de l’utilisation d’une technologie de type Function as a service (FaaS). Nombreux penseront, de par leur définition, que les fonctions doivent être isolées les unes des autres et posséder leur propre cycle de vie.
Ainsi nous aurions la représentation suivante :
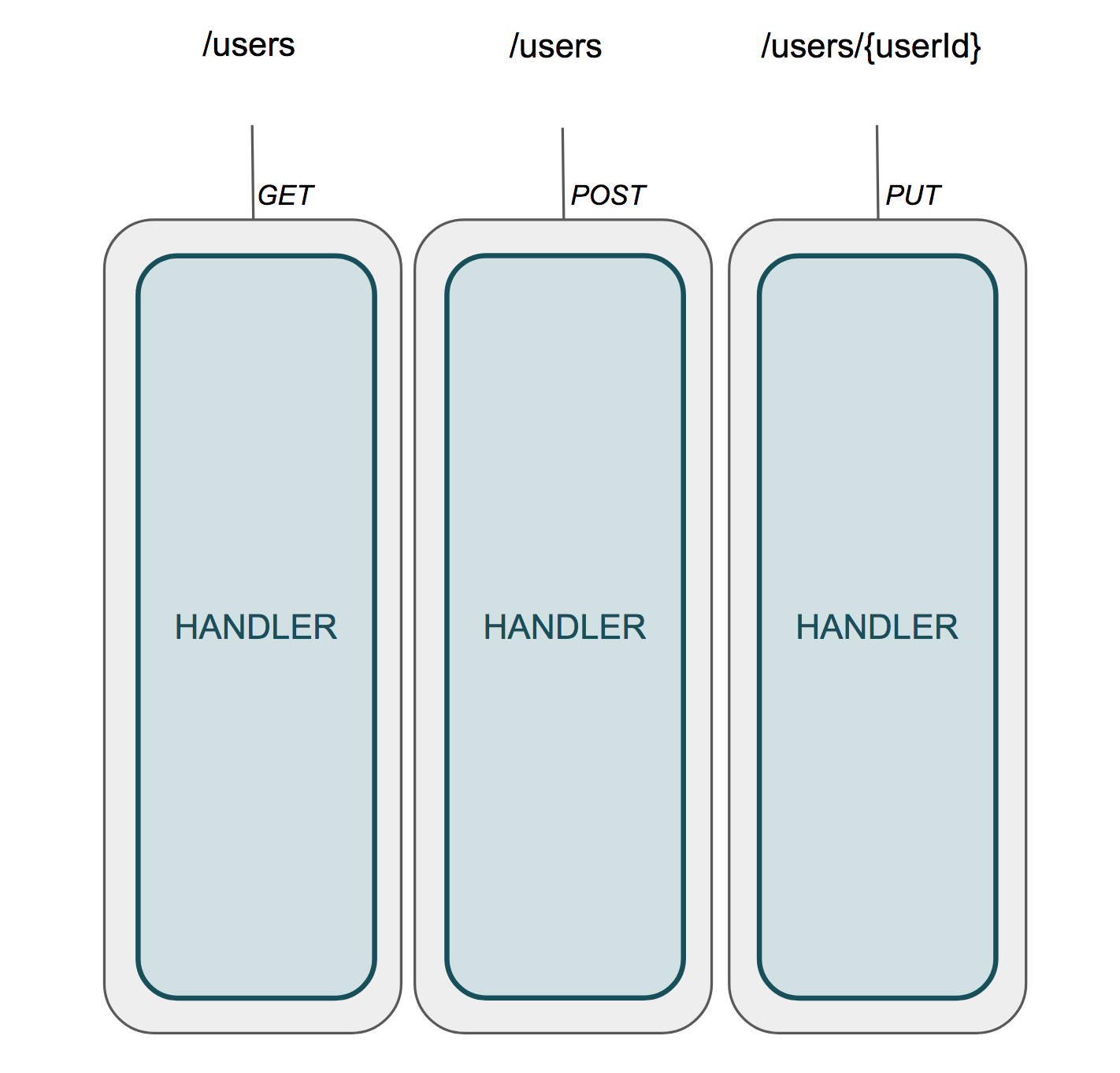
Cette structure pourrait tout à fait convenir pour certains cas d’utilisation qui auraient une dizaine de fonctions. Mais dans les proportions d’un projet d’entreprise avec plus de 80 fonctions c’est une autre paire de manches. Certains y verront du “microservice à l’extrême”, d’autre un enfer dans la gestion du produit.
Mais dans ce cas, qu’en est-il de :
- La qualité du code
- La duplication du code
- La complexité
- La couverture de tests
- La gestion des dépendances
- La gestion du versionning
Maintenant, prenons un peu de recul et reprenons la définition du FaaS que nous donne Wikipedia :
Function as a service (FaaS) is a category of cloud computing services that provides a platform allowing customers to develop, run, and manage application functionalities without the complexity of building and maintaining the infrastructure typically associated with developing and launching an app
Le point important dans ce texte est la notion de services d’infrastructure. Le FaaS n’est rien d’autre qu’une catégorie de services managés qui vous permettent de mettre à l’échelle automatiquement vos fonctions et d’avoir une facturation adaptée à ce mode de fonctionnement. Nombreux sont ceux qui veulent y voir des impacts sur l’organisation du projet, de l’équipe de développement ou de l’architecture technique. Ce n’est pas parce que nous utilisons ce type de technologie que nous ne pouvons pas avoir une structure simple de type Monolith ou une séparation en services métier (bounded context), une gestion des sources (Git flow) ou même l’utilisation de méthodologie Agile ou de processus d’intégration et de déploiement continu. Une fonction a uniquement besoin d’un point d’entrée (Handler) pour exécuter son code et rien ne nous empêche d’avoir un package disposant du même code propagé sur plusieurs fonctions avec des points d’entrée différents.
Une fois ces principes pris en compte, nous pouvons nous permettre d’avoir la représentation suivante :
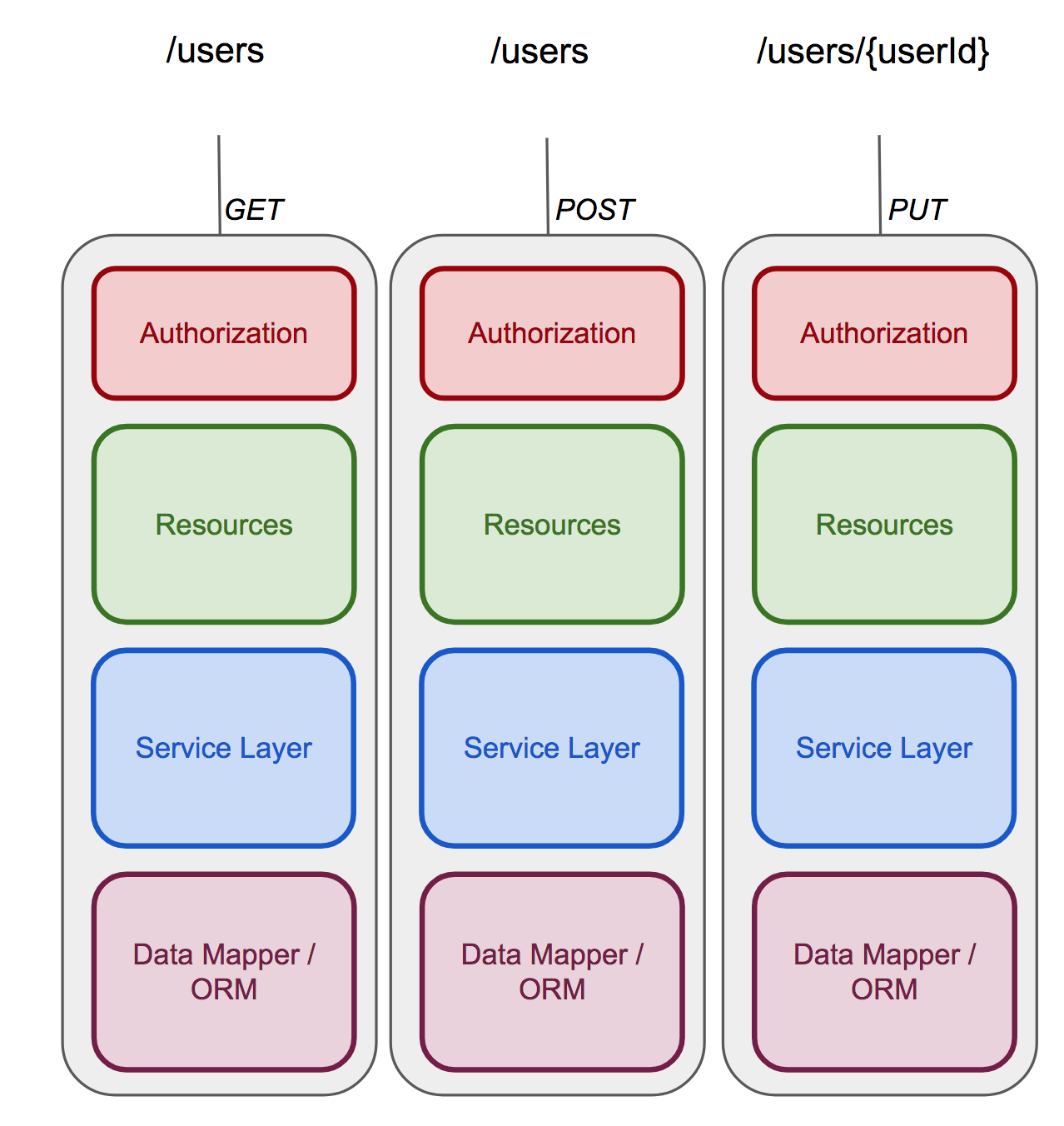
La partie visible de l’Iceberg : Les APIs
Petit rappel de mes précédents articles : le FaaS est un service asynchrone basé sur des événements. Cela signifie que n’importe quelle exécution de fonctions est liée à un événement source. Dans le cas d’une application Web l’événement vient des ressources REST que nous exposons.
Nous avons de ce fait 2 niveaux au sein de notre architecture :
- Un service en charge de définir notre contrat REST
- Nos fonctions en charge de l’aspect métier de notre application
D’un point de vue utilisateur, l’unique point d’entrée de l’application se trouve dans les ressources REST mises à sa disposition. Il est donc important de mettre un effort particulier à la définition de notre contrat d’interface.
Nous utiliserons pour cela un service dédié : API Gateway.
API Gateway
Pour faire simple, ce service fait office d’un serveur HTTP où les contrats / endpoints sont définis au travers d’une configuration. Ceux-ci vont alors générer un événement qui pourra être utilisé au travers d’une fonction FaaS. En règle générale, il permet le mapping des paramètres d’une requête HTTP aux arguments d’entrée d’une fonction FaaS puis en retour, il transformera le résultat de l’appel à la fonction en une réponse HTTP et la renverra à l’appelant d’origine. Au-delà des demandes de routage simple, ce service permet aussi d’avoir des notions d’authentification, une gestion du cache ou même de validation des paramètres.
Notre contrat
Précédemment je parlais de définitions de notre contrat au travers d’une configuration. Vous l’aurez bien compris,cette phase représente la pierre angulaire de notre application étant donné qu’elle constitue la partie visible de notre métier.
Peu de Cloud Service Providers proposent des solutions efficaces à cette problématique. À ce jour APIGateway d’AWS ou Azure API Management ont clairement un train d’avance sur les autres, que ce soit en termes de maturité ou même de fonctionnalités, mais nous reviendrons dessus plus tard.
Intéressons-nous maintenant à la définition de notre contrat de façon homogène et compréhensible pour toute l’équipe. Quoi de mieux qu’une spécification connue de tous et qui possède déjà son écosystème open source : Swagger.
Un point important à savoir est que les service d’AWS ou Azure permettent d’intégrer directement cette définition pour configurer l’ensemble de nos contrats. De nouvelles fonctions Swagger ont même été ajoutées afin de coller au plus près aux fonctionnalités disponibles sur ce service (ex: x-amazon-apigateway-integration).
Voici un exemple de ce à quoi pourrait ressembler cette définition :
/users:
get:
tags:
- users
description: |
Get all users
responses:
200:
description: A list of all users
schema:
type: array
items:
$ref: '#/definitions/user'
headers:
Access-Control-Allow-Origin:
type: "string"
400:
description: Error
schema:
$ref: '#/definitions/message'
headers:
Access-Control-Allow-Origin:
type: "string"
x-sample-input:
method: GET
query: "/users"
x-sample-output:
200:
- id: "1"
firstName: "Steve"
lastName: "HOUEL"
email: "shouel@ippon.fr"
company: "Ippon Technologies"
400:
code: 400
message: Error
x-amazon-apigateway-integration:
uri:
Fn::Sub: arn:aws:apigateway:${AWS::Region}:lambda:path/2015-03-31/functions/${GetAllUsersFunction.Outputs.Arn}:prod/invocations
passthroughBehavior: "when_no_match"
httpMethod: "POST"
responses:
default:
statusCode: "200"
responseParameters:
method.response.header.Access-Control-Allow-Origin: "'*'"
type: "aws_proxy"
security:
- sigv4: []
Pour ceux qui se posent des questions sur ce contenu et les différentes configurations, il fera l’objet d’une partie dédiée dans un prochain chapitre de notre Kit de survie d’une application Serverless.
Avant de clore ce chapitre, il faut savoir que AWS et Azure ne sont pas les seuls providers présent sur ce marché et qu’un service du nom de APIGee vient de faire son entrée chez Google Cloud Platform et semble tout aussi prometteur. Stay in touch !!
Le choix du langage
Intéressons-nous maintenant à une autre facette primordiale et structurante de notre projet : le choix du langage.
En plus des considérations humaines (ô combien essentielles pour ce genre de décisions), il est essentiel de prendre en compte les problématiques liées au cycle de vie des fonctions et de comprendre les impacts que ce choix peut avoir aussi bien d’un point de vue organisationnel qu’en terme de facturation.
Cycle de vie d’une fonction
À la différence d’une application traditionnelle, où le code est présent en mémoire sur le serveur et attend des requêtes, dans le monde serverless, le code est dormant et n’est, la majorité du temps, pas provisionné.
Nous aurons ainsi 2 principales phases lors de l’exécution de notre fonction :
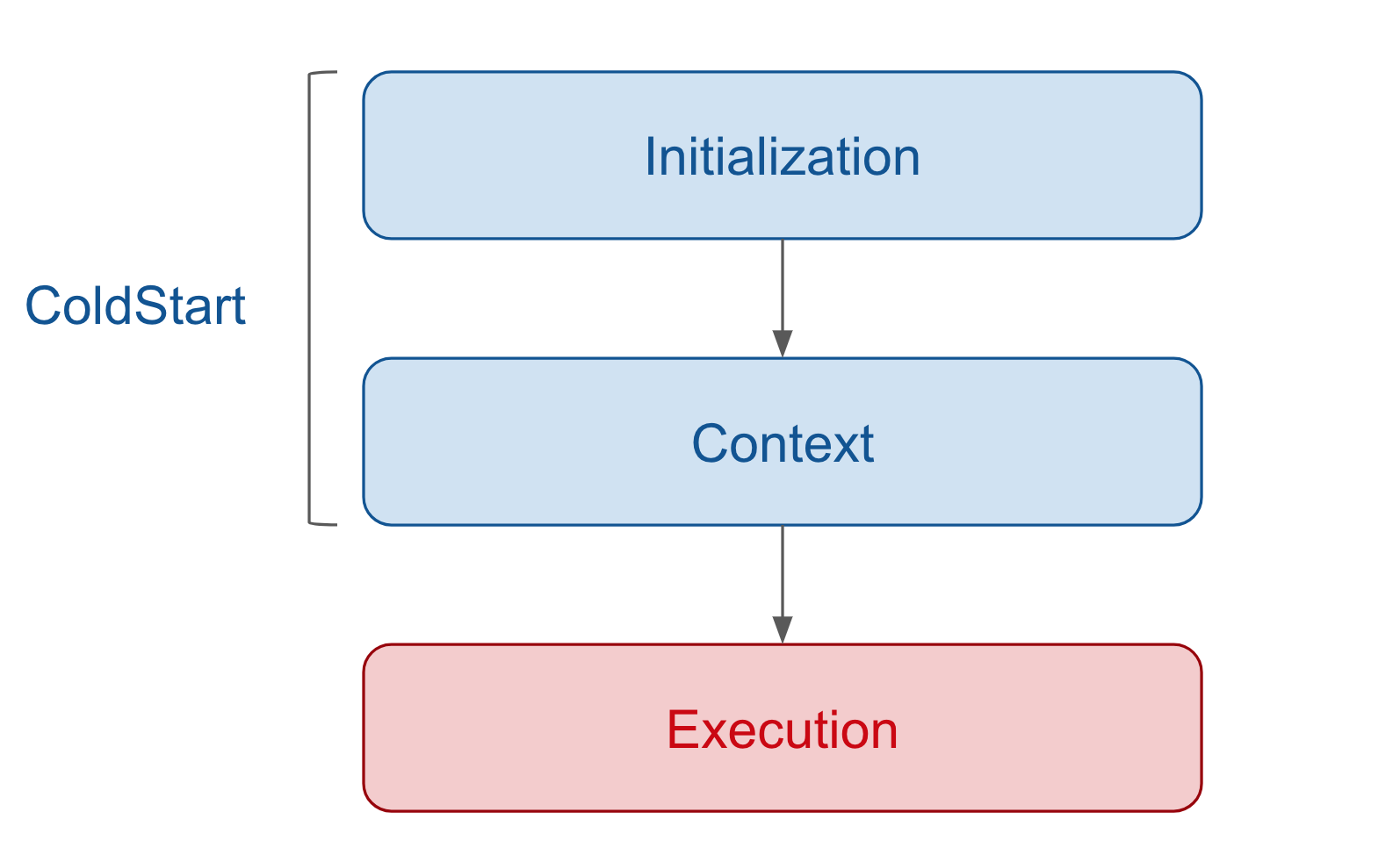
ColdStart
Cette étape a un impact non négligeable sur le temps de réponse de votre fonction à une demande, il peut s’étaler de 10 ms à 2 minutes. Soyons un peu plus précis, en utilisant AWS Lambda comme exemple.
Si votre fonction est implémentée en JavaScript ou Python qui sont des langages interprétés avec un contenu simple (moins d'un millier de lignes de code), la durée de chargement devrait se situer entre 10 et 100 ms. Des fonctions plus importantes peuvent occasionnellement voir ce temps augmenter.
Si votre fonction Lambda est en revanche exécutée dans une JVM par exemple (Java, Scala, Kotlin, …), vous pourrez avoir un temps de démarrage drastiquement plus long (> 10 secondes).
Nous pouvons distinguer 2 étapes lors de ce ColdStart :
- Téléchargement du code, chargement en mémoire et démarrage du runner, phase que je nomme Initialization
- Exécution du contexte de la fonction (et non de la fonction elle même), phase que je nomme Context.
Voici quelques points importants à savoir :
- La phase d'initialisation n’est pas facturée
- En revanche, la phase d’exécution du contexte ne doit pas dépasser les 10 secondes sous peine d’être prise en compte dans la facturation.
- Ce temps ne fait pas parti du délai de timeout d’une fonction
Une bonne pratique consiste à initialiser le maximum de code au sein durant cette phase (initialisation des ORM, pools de connexion, …). Cela ne réduira pas le temps de démarrage, mais accéléra le temps des prochaines exécutions de vos fonctions.
Exécution
Il est temps maintenant de prendre en compte le temps d’exécution propre à chacun des langages. Pour ce faire rien de mieux qu’un benchmark. Vous trouverez ci-dessous un benchmark réalisé sur des fonctions de différents langages:
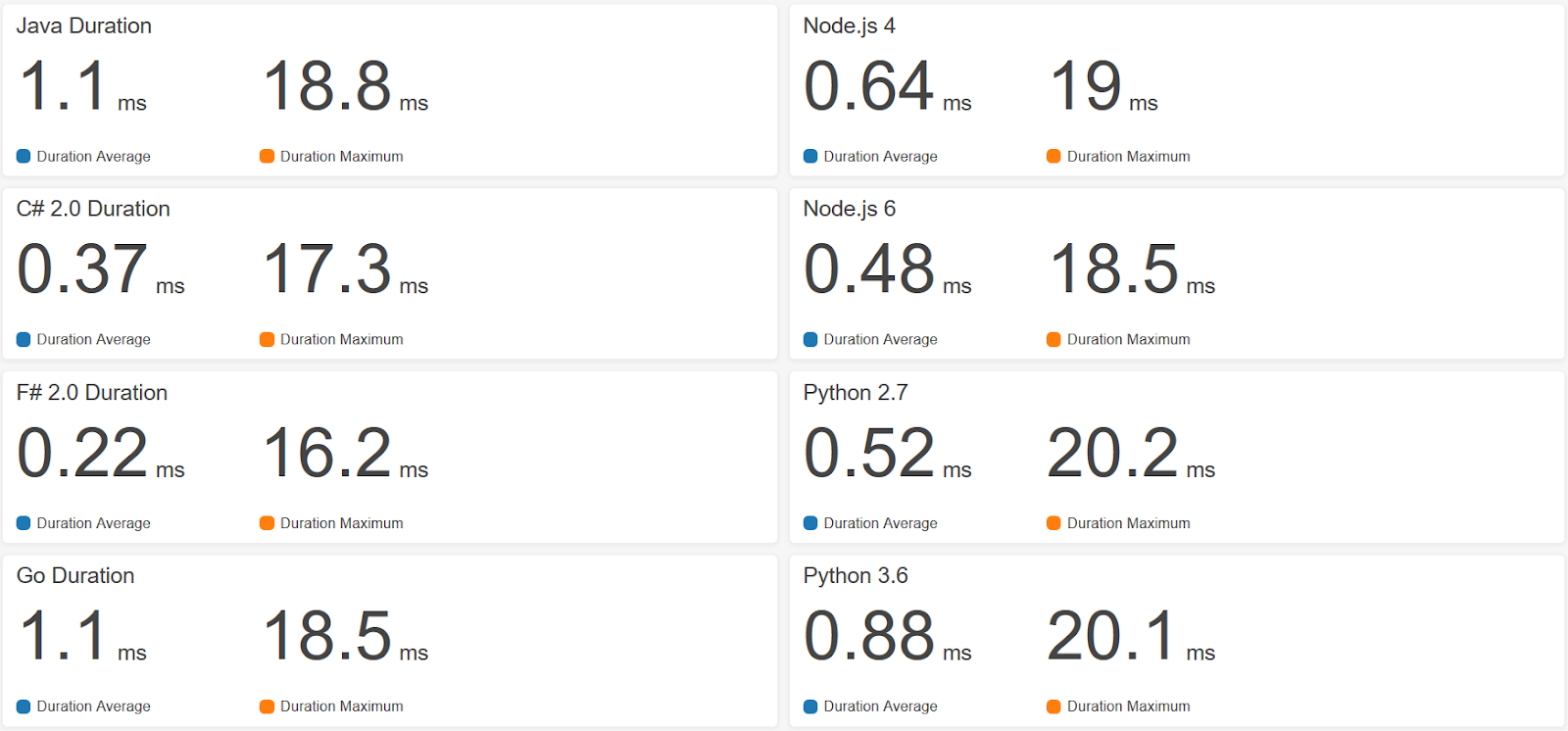
On voit clairement que certains langages ont de meilleures performances que d’autres. Ces différences doivent cependant être nuancées avec les temps liés au ColdStart.
Le choix fatidique
Intéressons-nous maintenant à l’aspect conception et organisationnel. L’objectif n’est pas de lancer un débat sur les avantages et les inconvénients de chacun des langages mais de mettre l’accent sur :
- L’impact d’un tel choix sur vos équipes de développement : montée en compétence, formation, recrutement
- La conception de votre projet
- La gestion des dépendances
- Vos coûts d’exécution
Rappelons-le, l’optimisation a un impact direct sur votre facture, prenons l’exemple d’une fonction qui s’exécute en 1 seconde. Après optimisation du code, que ce soit par l’utilisation d’une librairie plus performante ou par la réduction de sa complexité, nous arrivons à atteindre les 200ms. Cette modification impactera directement votre facture en fin de mois et la réduira de 80%, ce qui dans des volumétries d’un projet d’entreprise peut représenter une somme non négligeable.
Conclusion
L’objectif de cet article a été de présenter dans les grandes lignes certains concepts liés au Serverless. Le but n’était pas de rentrer dans le détail technique, travail que je ferai dans les prochains articles, mais de vous faire prendre conscience de certaines notions structurantes avant le démarrage d’un projet.
Voici un récapitulatif :
- Le FaaS est une technologie d’infrastructure et n’impacte en rien votre phase de conception et de design de votre projet. Une architecture monolithique ou une séparation en services peuvent tout à fait être utilisées.
- La pierre angulaire de votre application Web se trouve sur les ressources REST que vous exposez. Il faut mettre un effort particulier sur sa définition.
- Le choix du langage a un impact direct sur les performances de votre application et de ce fait sur les coûts associés.
Stay tuned !!
