
Depuis quelques mois, la suite Elastic s’est enrichie d’un outil de Machine Learning non supervisé, c’est-à-dire qu’on travaille avec des données non étiquetées.
Nous allons voir sur deux articles, dont voici le premier, quels sont les principes, les usages et les avantages de cette solution.
Introduction
Grâce au rachat puis à l’intégration de Prelert, Elastic.co a enrichi sa suite Elastic Stack avec un outil de Machine Learning non supervisé. Ce nouvel outil, qui est distribué avec le package X-Pack, est disponible en bêta depuis la version 5.4 parue le 4 mai 2017 (annonce ici).
Pour l’utiliser en production, il faudra néanmoins souscrire aux packages Platinum ou Enterprise qui sont respectivement en prix public à environ 6 k€ et 8 k€ / nœud master ou data. Mais je vous donne ça juste pour information car le pricing se fait au cas par cas. Une licence d'évaluation de X-Pack d’une durée de 30 jours permet de découvrir les fonctionnalités supplémentaires offertes.
Les deux articles sont basés sur la formation en ligne X-Pack-Machine-Learning que je vous recommande.
Principes
La détection d’anomalies est un domaine à part entière du Machine Learning comme cela est expliqué dans cet article de Wikipédia.
Avec X-Pack Machine Learning, le principe est de créer des jobs qui analysent les données temporelles présentes dans Elasticsearch pour en déduire une tendance. Les valeurs qui s’éloignent de cette tendance seront identifiées et mises en évidence. Il sera même possible d’utiliser le composant Alerting présent dans la suite X-Pack pour configurer des notifications au fur et à mesure que ces valeurs aberrantes sont détectées.
Voici un exemple :
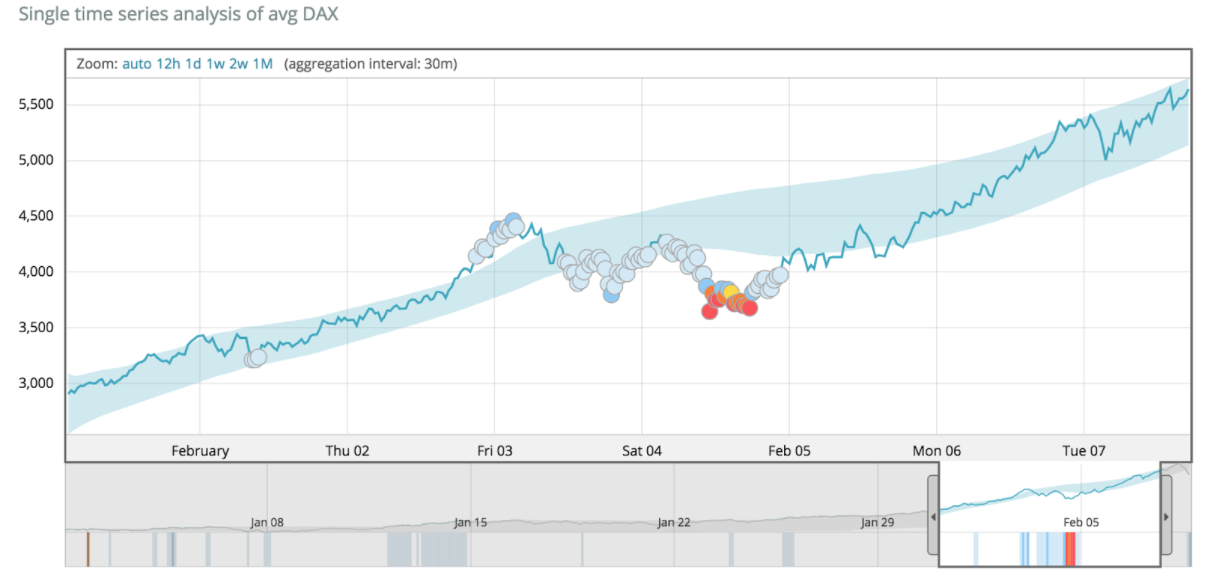
Plusieurs choses sont à observer sur cette copie d’écran :
- Les données temporelles sont représentées par la courbe en bleu foncé.
- La surface bleu clair qui englobe la courbe représente la tendance qui a été déduite suite à l’analyse des données.
- Les points représentent les valeurs aberrantes.
- Les points rouges étant les valeurs les plus extrêmes.
Use Cases
Voyons à quels besoins peut répondre cette nouvelle fonctionnalité de la suite Elastic.
- Automatiser la surveillance d’un site web par exemple en détectant les pics ou les creux de fréquentation par rapport à la normale.
- On peut aussi détecter le crawling d’un site web quand le nombre de visiteurs uniques devient anormalement faible. Vous trouverez plus d’exemples dans cet article.
- Faciliter l’Application Performance Management (APM) en détectant automatiquement les événements inhabituels (consommations de ressources systèmes, trafic réseau, occurrence de codes erreurs).
- On pourrait utiliser cet outil pour analyser des métriques collectées sur une application, construite par exemple avec JHipster, qui intègre le framework Metrics auquel il est possible d’associer un reporter Elasticsearch.
- Dans le contexte de l’IoT, on peut aussi par exemple analyser automatiquement des événements issus de capteurs pour émettre une alerte si la communication est interrompue.
- En Data Exploration, on peut utiliser la fonction de Machine Learning pour détecter manuellement des tendances et avoir ainsi un aperçu rapide des données.
Vous l’aurez compris, toutes les données temporelles peuvent faire l’objet d’une analyse automatique grâce à cet outil.
Concepts
Pour analyser les données, il faut créer un Job qui peut être de 3 types :
- Dans un Single Metric Job on ne peut analyser qu’un champ à la fois.
- Dans un Multi Metric Job, on peut analyser plusieurs champs, soit avec la même fonction, soit avec des fonctions différentes.
On peut aussi séparer les données selon un champ (par exemple le hostname). - Dans un Advanced Job, on peut analyser plusieurs index et donc plusieurs champs et configurer manuellement les éléments clefs du job que nous allons voir tout de suite.
Quand on crée un job, on choisit quel index ou quelle requête sauvegardée on veut analyser. Pour un advanced job, on peut choisir plusieurs index.
Le choix du Bucket Span est très important quand on crée un job. Il s’agit de l’intervalle de temps sur lequel les données seront agrégées, par exemple pour calculer une moyenne. L’outil propose lui-même un bucket span à la création du job mais il est parfois nécessaire de le choisir soi-même pour des résultats plus fiables.
Il faut savoir comment les données sont distribuées pour choisir un bucket span pertinent.
Ensuite on choisit la fonction d’analyse, appelée Detector, qui sera appliquée sur le champ analysé. Si on analyse plusieurs champs, on aura plusieurs detectors.
La source de données, nommée Datafeed, peut être un index complet, des données sur un intervalle de temps ou même des données live (les trentes dernières minutes en continu).
Enfin, le dernier concept à connaître concernant les jobs sont les Influencers. Ce sont les variables qui ont la plus grande influence sur les anomalies détectées. Par exemple, la région géographique du serveur peut avoir une influence sur la latence réseau.
Exemple de Single Metric Job
Nous allons créer un Single Metric Job à partir de l’index “stocks”.
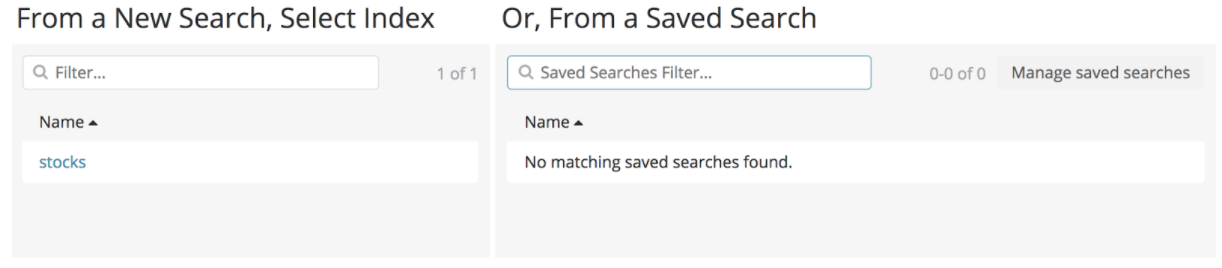
Comme agrégation nous choisirons une moyenne sur le champ DAX avec un bucket span de 30 min. Puis nous rentrons un titre et nous allons pouvoir créer le job.
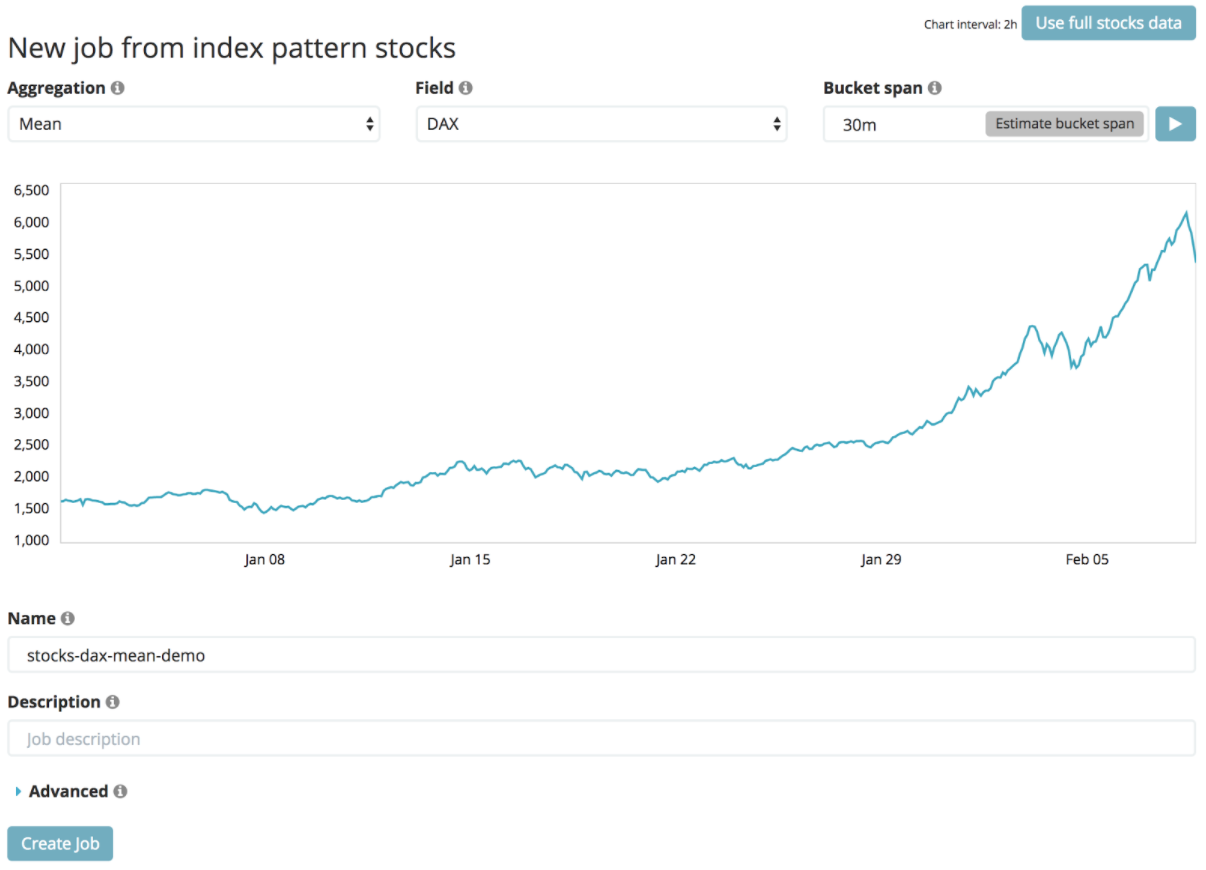
L’analyse démarre et les données sont analysées pour identifier la tendance et les valeurs aberrantes.
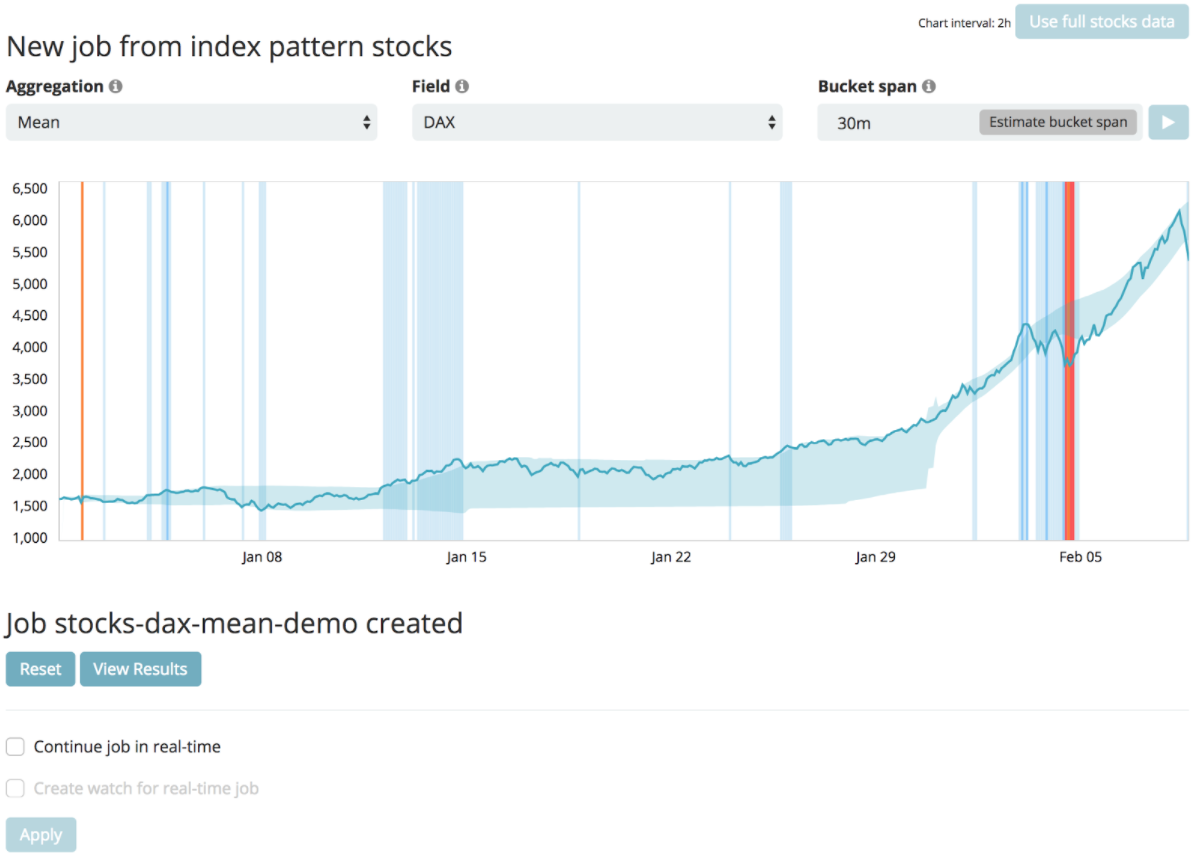
Ensuite on peut visualiser les résultats et faire apparaître les anomalies sur la courbe.
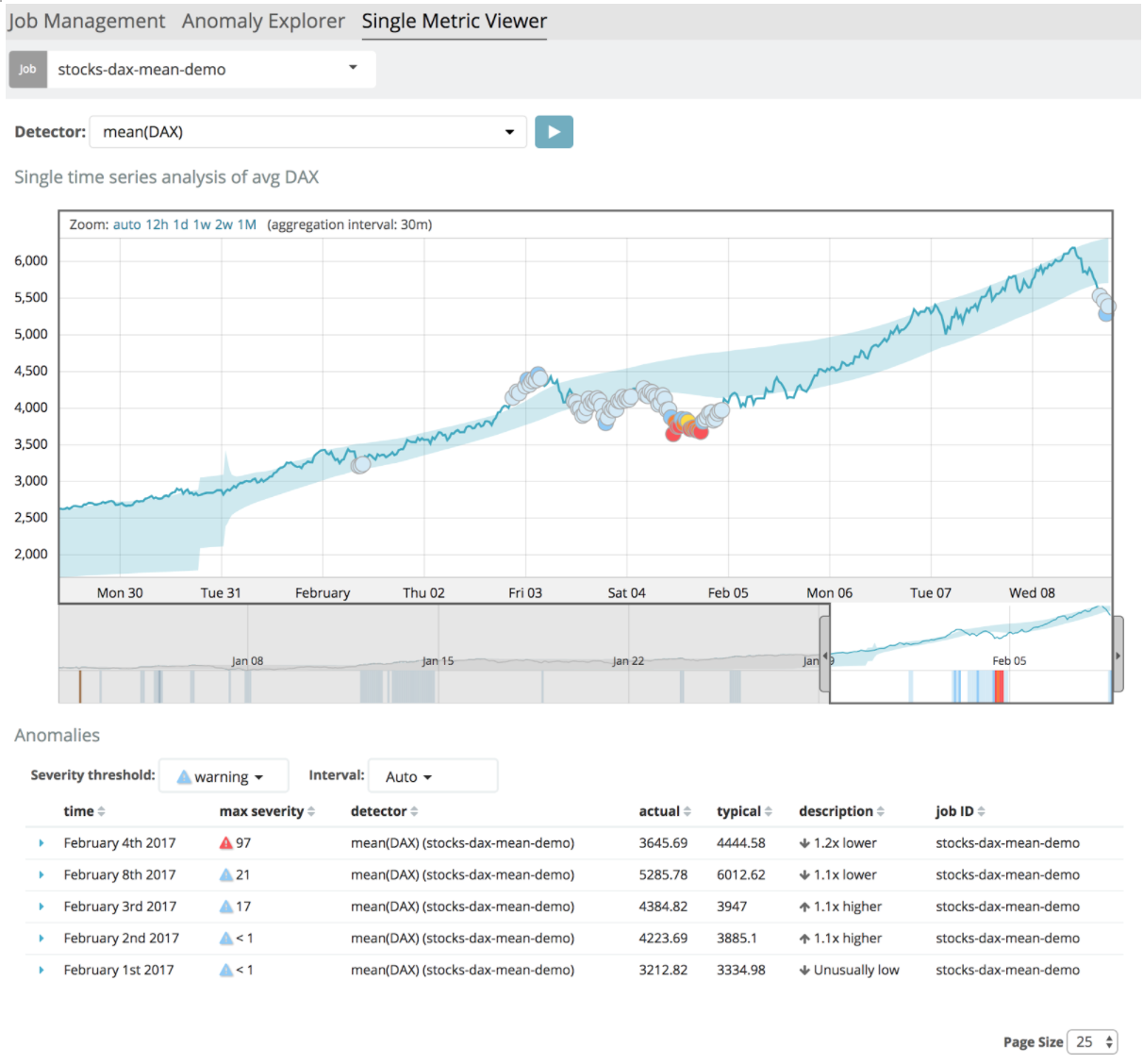
On peut jouer sur l’intervalle de temps et la criticité des anomalies pour les explorer.
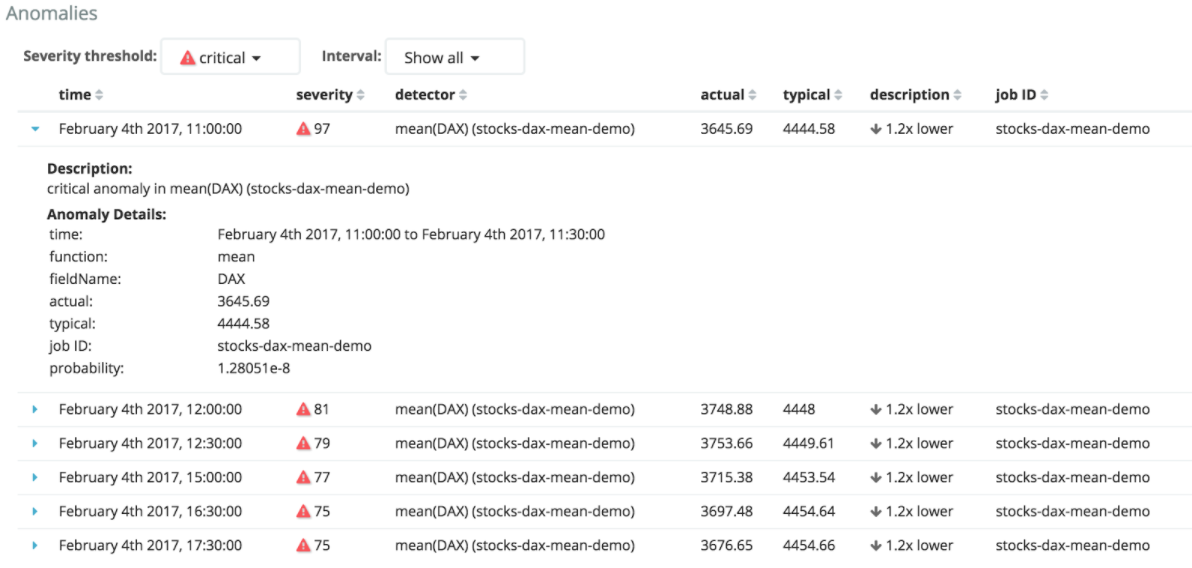
Analysis tools
Plusieurs notions sont à connaître pour configurer l’analyse des données.
Quand on fait une Individual Anomaly Detection, on veut en fait comparer le comportement d’une donnée par rapport à elle-même dans le temps, c’est-à-dire à ses valeurs sur l’échelle de temps du bucket span.
Le champ sur lequel va se faire la comparaison s’appelle le By Field dans le jargon de l’outil.
Ce type d’analyse n’est pas adapté pour les champs qui ont une forte cardinalité, c’est-à-dire qui ont trop de valeurs distinctes.
Population analysis
Avec une Population Anomaly Detection, on veut comparer les comportements de plusieurs populations les uns avec les autres.
On va alors définir un Over Field qui est le champ sur lequel les populations seront comparées.
Exemple Multi Metrics Job
Dans un Multi Metrics Job, on va comparer côte à côte des séries temporelles sur lesquelles on va faire varier un paramètre. Par exemple si on compare du trafic réseau, on peut faire varier le datacenter ou la région.
Les deux premières étapes sont les mêmes que pour un Single Metric Job.
Par contre quand on arrive à la page de configuration du job, on a beaucoup plus d’options qu’avec un Single Metric Job.
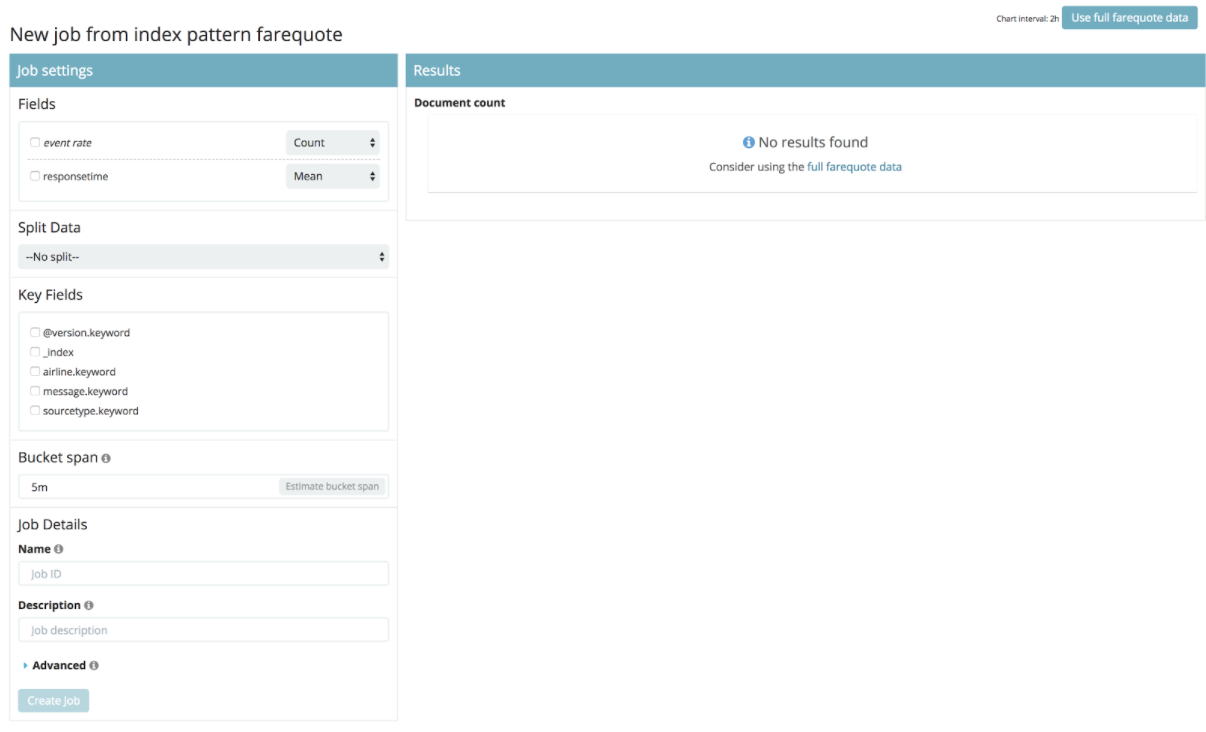
Ici on va choisir d’analyser le temps de réponse moyen en fonction du code de la compagnie aérienne.
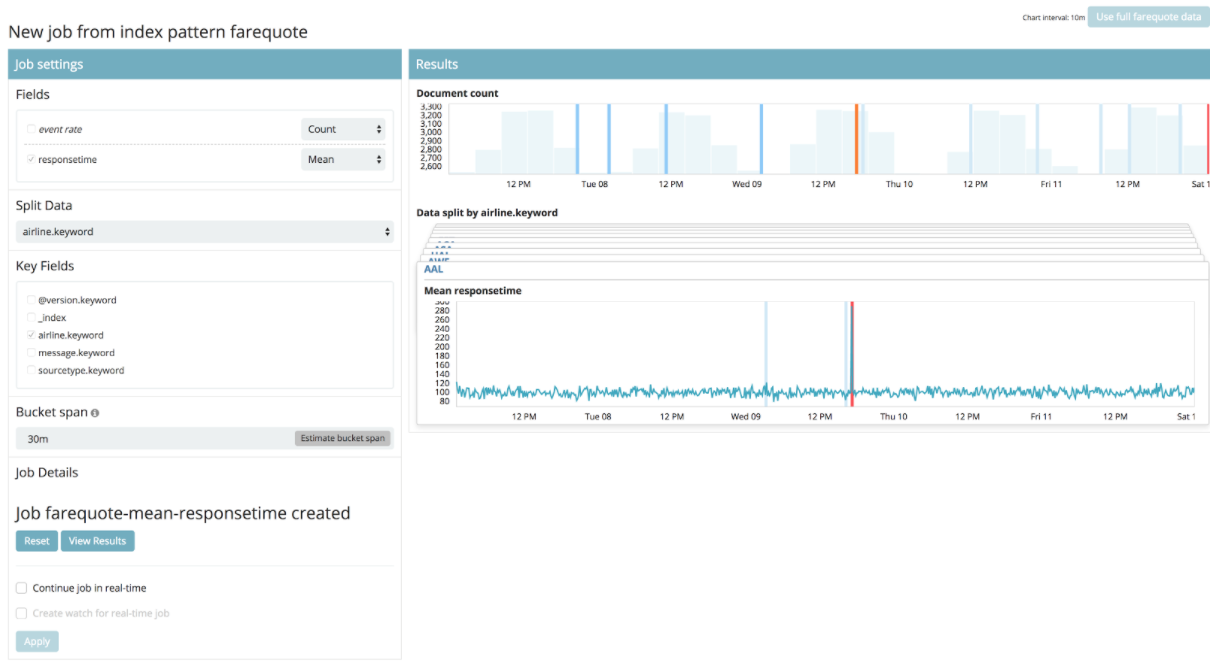
On observe un “split” de données par compagnie aérienne. Mais le plus intéressant est de cliquer sur le bouton “view results” qui permettra de comparer les résultats dans l’écran appelé Anomaly Explorer.
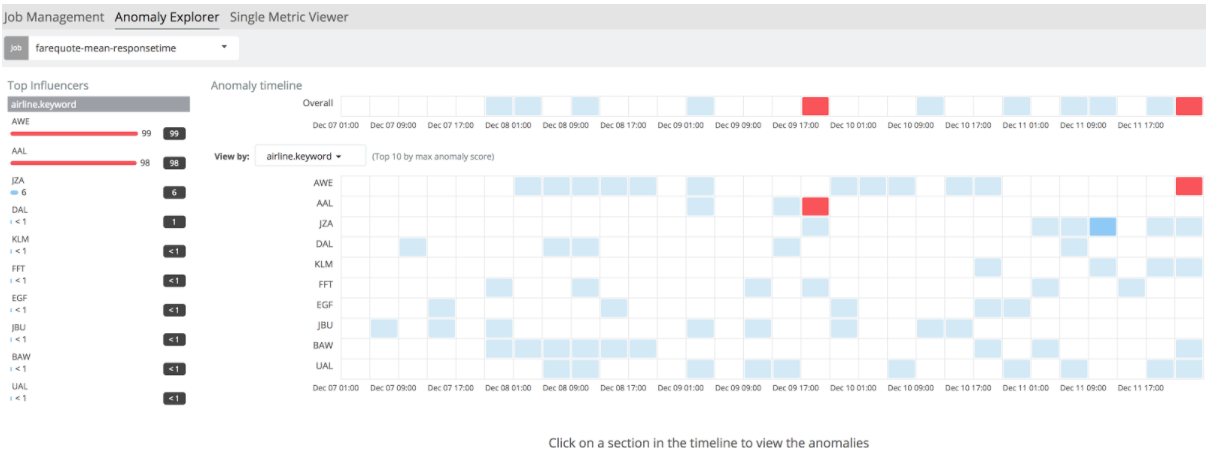
On voit d’un seul coup d’oeil que les 2 compagnies à l’origine du plus grand nombre d’erreurs, autrement appelées Top Influencers, sont AWE et AAL. Si on clique sur une case du tableau, on peut visualiser les erreurs correspondantes.
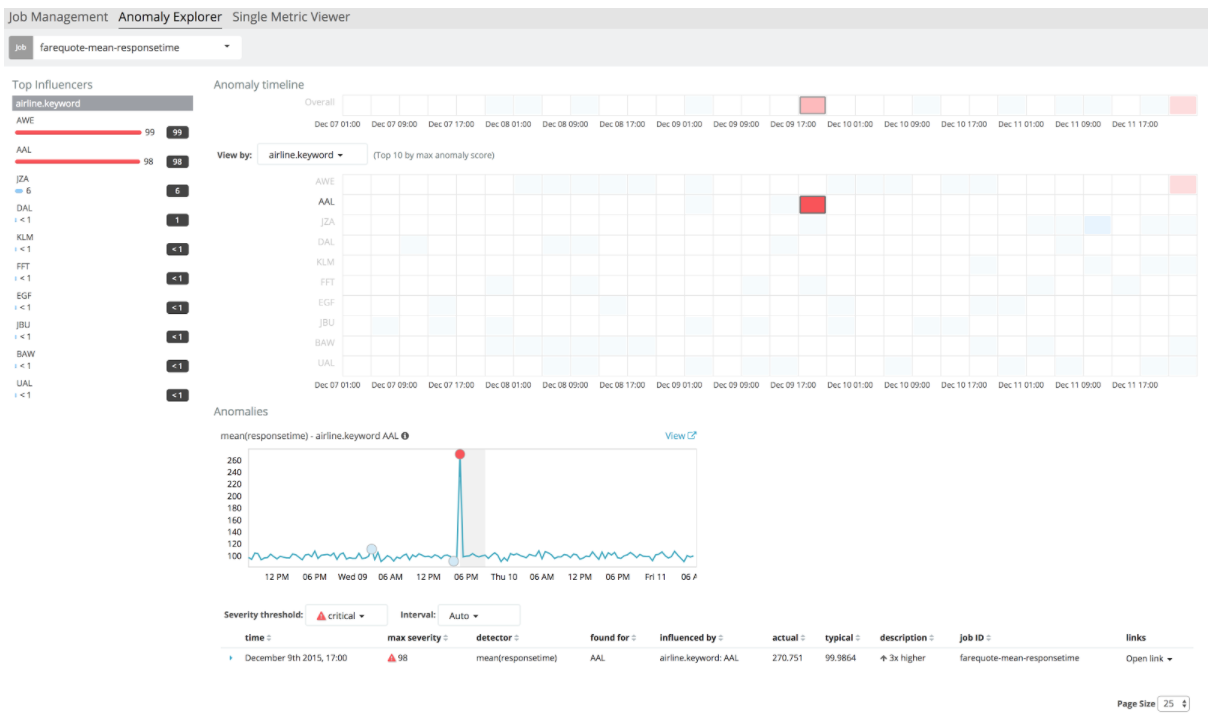
Aurait-on pu trouver cette valeur en faisant des requêtes Elasticsearch ? Oui, mais il faut faire autant de requêtes que de compagnies aériennes puis analyser les résultats des buckets dans un second temps.
Par exemple voici la requête pour la compagnie AAL :
GET farequote/_search
{
"size": 0,
"query": {
"term": {
"airline.keyword": "AAL"
}
},
"aggs": {
"group_by_date": {
"date_histogram": {
"field": "@timestamp",
"interval": "30m",
"order": {
"meantime": "desc"
}
},
"aggs": {
"meantime": {
"avg": {
"field": "responsetime"
}
}
}
},
"typical": {
"avg_bucket": {
"buckets_path": "group_by_date>meantime"
}
}
}
}
J’en profite pour préciser qu’on peut bien sûr lancer ce genre de requête en Curl. Mais on peut aussi utiliser l’outil Console fourni avec Kibana :
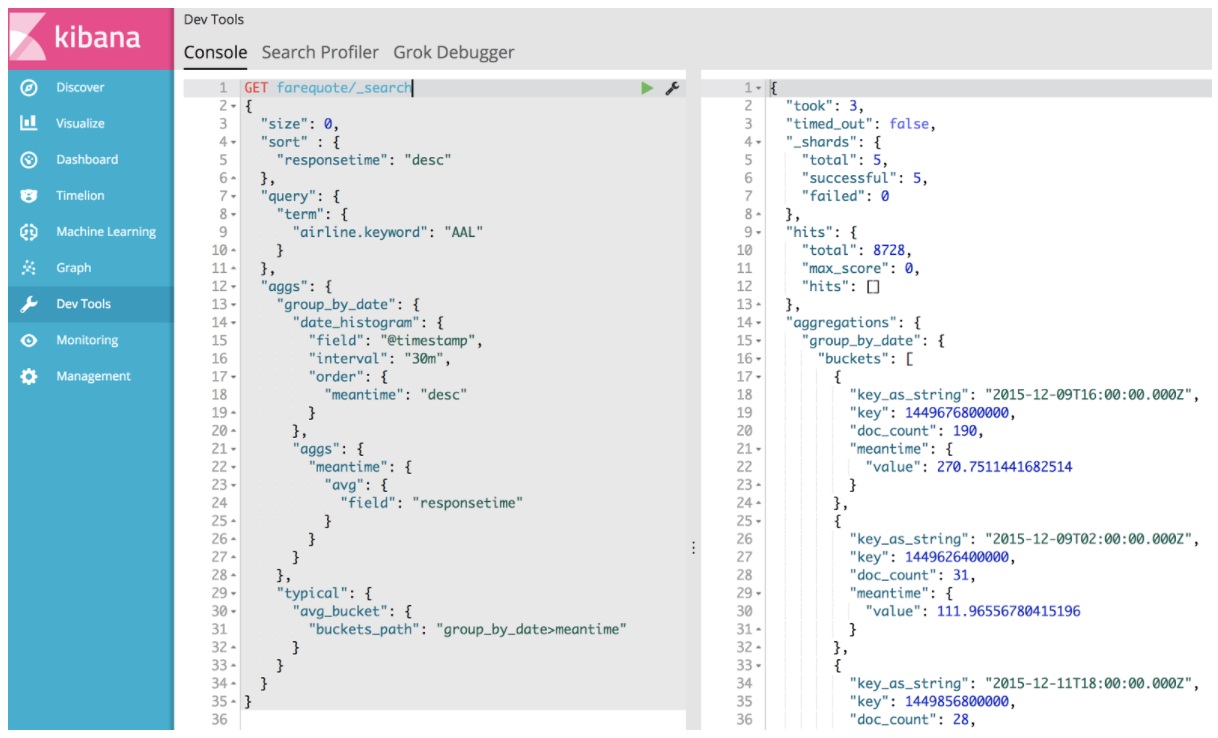
La requête nous ramène donc les résultats suivants :
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 8728,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_date": {
"buckets": [
{
"key_as_string": "2015-12-09T16:00:00.000Z",
"key": 1449676800000,
"doc_count": 190,
"meantime": {
"value": 270.7511441682514
}
},
{
"key_as_string": "2015-12-09T02:00:00.000Z",
"key": 1449626400000,
"doc_count": 31,
"meantime": {
"value": 111.96556780415196
}
},
…
{
"key_as_string": "2015-12-07T19:30:00.000Z",
"key": 1449516600000,
"doc_count": 29,
"meantime": {
"value": 87.2219133048222
}
}
]
},
"typical": {
"value": 101.03547596909824
}
}
}
On retrouve nos buckets triés par valeur moyenne décroissante du champ responsetime et la valeur moyenne globale, appelée ici typical. Par contre, les données concernent une seule compagnie. Il faudra faire autant de requêtes que de compagnies et agréger les résultats.
On comprend rapidement l’intérêt de l’outil de Machine Learning qui propose de l’assistance pour analyser et surtout pour visualiser les données.
A suivre
Dans le second article, nous parlerons d'architecture, nous verrons un exemple d'Advance Job et nous terminerons avec les points forts et faibles.
