
1. Présentation du contexte
1. Présentation du métier
Notre client est un des premiers sites de e-commerce en France. Il possède un SI de taille conséquente adapté aux fortes contraintes de trafic et un volume toujours croissant de données. Notre équipe, composée pour une grande part de collaborateurs Ippon, est responsable du moteur de recherche du site.
2. Existant technique
Historiquement notre client est très lié aux technologies Microsoft. La plupart des composants du SI sont développés sur le framework .Net en C#. Néanmoins, un certain nombre de programmes étaient développés en Java mais étaient livrés à la main et non versionnés. Ils ne bénéficiaient pas de l’intégration continue ni des outils de livraisons développés pour la plate-forme .Net.
Les développements .Net sont intégrés à l’aide de l’outil propriétaire Microsoft, Team Fondation Server et un outil de livraison en masse a été développé en interne.
La livraison hebdomadaire de l’ensemble du code est effectuée depuis une branche de production construite à l’aide de merges manuels.
3. Besoin d’évoluer ? Comment et pourquoi ?
Depuis quelques années, l’architecture du site a atteint ses limites du fait de l’augmentation conjointe du trafic et du volume de données à traiter. Il a fallu trouver de nouvelles solutions de stockage, de traitement et de transfert de données. Il est difficile de trouver un éditeur pouvant s’engager avec ce type de contraintes, qui concernent trop peu de sites. Ce sont souvent des solutions open source qui permettent de trouver une réponse.
C’est ainsi que nous avons entamé le chantier de migration du moteur de recherche vers la solution Solr Cloud, utilisée par de grands sites comme Rakuten, Etsy, Apple ou encore Netflix.
Notre ancien moteur de recherche embarquait des outils de surveillance et de pilotage plus complets que Solr.
De plus, la librairie .Net d’accès à Solr (Solr.Net) n’a pas évolué depuis l’arrivée de SolrCloud et ne permet pas de profiter de l’ensemble des fonctionnalités du moteur de recherche.
Nous avons donc du développer un ensemble de services pour réaliser des opérations de surveillance, d’interrogation et d’alimentation du moteur.
Ces services devaient être développés en Java, car la librairie solrj est le seul composant évoluant au rythme de Solr, garantissant ainsi la compatibilité du client avec le moteur.
2. Une architecture de microservices
1. Agilité et DevOps
Le mouvement agile qui irrigue nos pratiques depuis plus d’une dizaine d’années a été rejoint plus récemment par la démarche DevOps. Ces mouvements tentent d’apporter une réponse à la demande de réactivité toujours plus grande dans la réduction du “Time to Market”. L’objectif est clairement de minimiser l’intervalle de temps entre une idée de départ et son implémentation concrète visible par le client.
L’aboutissement logique de ces mouvements est une transformation de l’organisation de l’entreprise et donc de la DSI en équipes pluri-compétentes orientées autour d’un objectif métier (feature team) ou d’un composant technique (component team). Ces équipes (teams) comportent des experts métiers, des développeurs, architecte(s) et des ingénieurs systèmes. Certains de ces rôles peuvent être cumulés mais l’essentiel est d’avoir une équipe autonome sur son sujet.
Le but de cette organisation est d’assurer l’autonomie des équipes qui doivent, dans un cadre donné, pouvoir décider du contenu de leurs livraisons et de leur disponibilité en production. La fréquence de mise en production est alors accélérée pour se calquer sur le modèle de l’intégration continue, on parle alors de déploiement en continu.
Il est difficile de coordonner les développements d’un nombre conséquent d’équipes si un seul livrable est construit chaque semaine. Il va forcément y avoir des difficultés d’intégration et une fois que le “train” de livraison est raté c’est une à deux semaines de perdues sur la mise à disposition du développement.
C’est ainsi que l’architecture du système d’information a dû faire face à ce besoin de souplesse et est née l’architecture dite de “microservices”. Cette mise en place ne se fait bien sûr pas sans précaution ni sans raison. Nous allons voir par la suite quels outils nous avons mis en place et comment nous pouvons livrer nos services en continu en production.
2. Spring Boot
Il est aujourd’hui difficile d’étudier une architecture de microservices en Java sans parler de Spring Boot. Certes il existe d’autres frameworks (Dropwizard, SparkJava) mais la souplesse d’utilisation de Spring Boot et son intégration à l’écosystème Spring font de son utilisation une évidence.
Par exemple, nous utilisons le serveur web Undertow alors que c’est impossible avec DropWizard qui force à utiliser Jetty.
Spring Boot offre également un ensemble de “starter projects” permettant d’intégrer l’ensemble des librairies nécessaires à la construction par exemple d’un connecteur vers une technologie donnée.
Tous nos microservices sont accessibles via HTTP et utilisent spring boot actuator qui expose un ensemble d’APIs de surveillance et d’analyse permettant de brancher des outils de gestion d’alertes comme Zabbix, Nagios, etc…
3. Gestion de la concurrence
Outre les avantages liés à la maintenabilité ou à la maîtrise des impacts de chaque évolution, les microservices apportent une souplesse quant à la scalabilité horizontale des applications. Cette capacité de montée en charge, alignée sur les systèmes distribués comme SolrCloud, Cassandra, Kafka, entraîne une complexité liée à la programmation distribuée.
Il nous faut trouver des solutions de partage de ressources (mutex), d’élection de leaders ou encore de notifications instantanées entre ces services.
Pour coordonner l’ensemble de nos services nous utilisons le système de coordination Apache Zookeeper. Ce système, d’abord conçu pour coordonner les noeuds de la plate-forme Hadoop, a ensuite été utilisé par de nombreux projets open source comme SolrCloud ou Kafka.
Accédé au travers d’un autre projet open source, Apache Curator, il permet de gérer l’ensemble de ces problématiques de façon assez simple à l’aide de différentes recettes techniques (appelées Recipes dans le framework Curator).
Zookeeper est un système CP au regard du théorème CAP. Ceci implique qu’il sacrifie la disponibilité de façon à assurer la consistance et la résistance à la partition. En d’autres termes, s’il ne peut garantir un fonctionnement correct, il ne répondra plus aux requêtes.
Il offre donc une grande garantie de véracité et de fiabilité des informations partagées. Il conviendra par contre de bien surveiller son fonctionnement pour éviter tout risque d’arrêt de ce rôle crucial de coordination.
4. Découverte des services
Tous nos microservices ont été développés de manière à ce que plusieurs instances puissent fonctionner parallèlement, que ce soit de manière éparpillée sur tout un datacenter, ou sur un même serveur. C’est ce dernier point qui nous a apporté la plus grande partie des challenges à relever.
Port d’écoute dynamique
Pour que plusieurs instances d’un même service puissent être démarrées sur une même machine (et c’est vrai aussi pour des services différents), elle doivent écouter sur des ports différents de la machine hôte ou utiliser des IP différentes avec les mêmes ports.
Cette dernière solution étant plus complexe à mettre en place, nous avons privilégié l’utilisation de ports dynamiques.
Le port d’écoute d’un microservice n’est pas spécifié dans ses fichiers de configuration, ni même en tant que paramètre de démarrage de la JVM. Nous avons inclus dans nos microservices un mécanisme leur permettant de réserver dynamiquement, au démarrage, un port libre de l’hôte (parmi une plage de ports définie).
Registry / Discovery avec Zookeeper
Nous pouvons désormais lancer tous les services que nous voulons, sur les serveurs que nous voulons, sans craindre de conflit de ports ou de gestion des ressources. Il est donc impossible de garantir qu’un service tournera toujours sur la même machine, et encore moins sur le même port. Comment accéder depuis l’extérieur à nos services, ou encore gérer leur intercommunication ?
Une multitude de solutions de découverte de services existent, les plus connues étant: Etcd, Consul, Eureka, ou encore Zookeeper. Il existe également des services permettant de proxifier Zookeeper, comme l’à fait AirBnB par exemple.
Afin de connaître en temps réel l’état de notre cluster de services, nous avons mis en place un mécanisme d’”enregistrement”, embarqué dans nos services, à l’aide de Zookeeper. Lors de son démarrage, une fois le port réservé, chaque microservice va s’enregistrer sur Zookeeper en spécifiant un minimum d’information : Qui suis-je ? Quelle version ? Sur quel serveur suis-je déployé ? Sur quel port peut on m’interroger ?
Ainsi, n’importe qui ayant accès à Zookeeper peut connaître la liste de tous les microservices démarrés, avec l’adresse et le port permettant de les contacter.
Nous avons tout d’abord mis en place un système s’appuyant sur l’une des recettes de Apache Curator, Service Discovery. Ceci nous a permis de lier les microservices en leur permettant de s’appeler mutuellement.
Depuis, nous avons suivi la montée en puissance du projet spring-cloud et en particulier son implémentation spring-cloud-zookeeper, dont la première version 1.0.0 est sortie en avril 2016. Nous avons donc décidé de basculer notre système sur ce nouveau projet, nous permettant ainsi de simplifier le code en utilisant le mécanisme d’auto configuration basé sur le même principe que Spring Boot.
Création d’une Gateway
Le nouveau challenge de notre architecture était donc de proposer une interface unique d’accès à l’ensemble de nos services : un “edge server” ou “gateway”.
Pour ce faire, nous avons utilisé le proxy “Zuul” développé par Netflix.
Zuul est la porte d’entrée pour l’ensemble des requêtes venant de l’ensemble des appareils et sites internet vers le backend de Netflix. En tant que service proxy de l’ensemble des services, il propose principalement un routage dynamique, une surveillance et un système de sécurité d’accès.
L’utilisation de Zuul est complétée par deux autres projets Netflix: le composant Ribbon, permettant le load balancing entre les instances d’un même service et Feign, qui permet d’effectuer les appels vers les APIs REST distantes au travers de Ribbon.
Gestion et monitoring des erreurs
Dans un environnement distribué comme le notre, tôt ou tard, certains des services vont tomber en erreur, que ce soit pour un problème matériel, réseau ou encore logiciel. L’enjeu est donc de pouvoir gérer efficacement la tolérance aux pannes et aux latences. Hystrix est une librairie développée par Netflix permettant d’isoler les interactions entre les services et d’éviter les cascades d’erreurs en proposant des mécanismes de “fallback”.
Hystrix permet notamment d’implémenter le pattern “circuit breaker”. Comme son nom l’indique, lorsqu’une erreur est détectée lors de l’appel à un microservice, Hystrix “ouvre” le circuit, c’est à dire qu’il considère ce microservice non-opérationnel. Régulièrement, des tentatives d’interrogations seront faites pour savoir quand il sera rétabli. En attendant qu’il soit à nouveau opérationnel, Hystrix va gérer la redirection des appels vers un autre microservice ou alors va proposer une réponse par défaut si aucun n’est capable de répondre aux sollicitations.
Afin de connaître l’état des coupes circuits, Hystrix met à disposition un dashboard temps réel, permettant également d’afficher certaines métriques telles que les temps de réponse ou le nombre d’instances d’un même service. 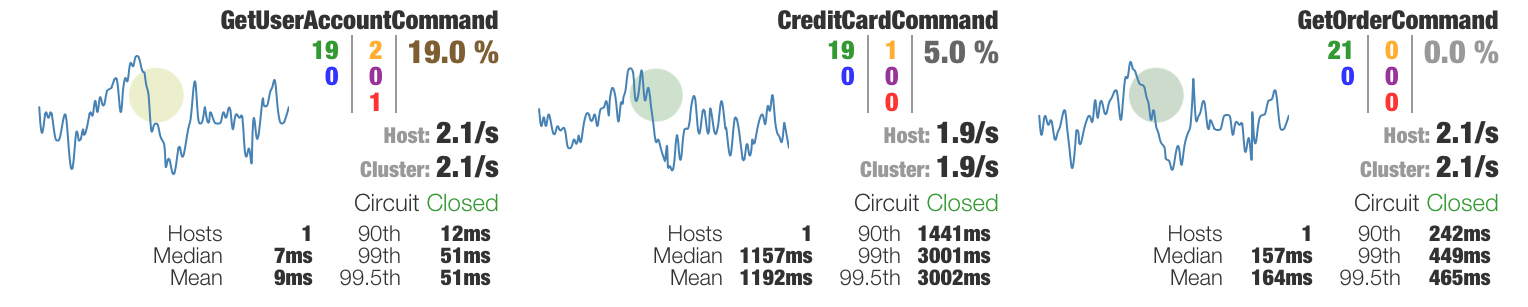
3. Une première intégration continue
1. Compilation et livraison avec Jenkins
Nous l’avons dit en préambule, tout est prévu pour les composants .Net mais rien n’existe pour les autres langages. Nous avons donc du monter dès le début du projet une plate-forme d’intégration continue pour nos microservices.
Nous avons choisi d’installer Jenkins, le standard de facto pour la compilation et la construction de livrables. Le gestionnaire d’artefacts et proxy de ressources choisi est l’outil de JFrog, Artifactory. Nous avons complété cette usine logicielle par l’outil de surveillance de la qualité logicielle SonarQube.
Aujourd’hui, chacun de nos microservices possède au moins 2 jobs Jenkins : un job de “build” et un job de “release”. A chaque modification du code source sur le dépôt partagé Git, le job de build se lance automatiquement. Ce job est chargé de compiler le code, exécuter des tests unitaires puis, si les résultats de tests sont bons, de déployer cette nouvelle version “Snapshot” sur la plate-forme de développement. Un autre job est parfois utilisé pour jouer des tests d’intégration sur cette plate-forme.
Le job de release est utilisé pour générer un livrable et figer les sources en “taguant” le dépôt Git. Une fois ce livrable généré, il est mis à disposition dans Artifactory et rendu disponible pour les scripts de déploiement pour l’ensemble des environnements hors dev.
2. Gestion de la configuration
Un autre fait intéressant sur notre projet est que la plate-forme opérationnelle est très complexe et changeante. Chaque instance d’un même service et d’une même version peut avoir besoin d’utiliser des fichiers de configuration différents.
Cette contrainte, ainsi que la gestion du “multi-langue”, nous empêchent d’utiliser les mécanismes “classiques” de gestion de la configuration de Spring Boot ou encore Spring Cloud Config.
Tous les fichiers de configuration de tous nos services sont savamment organisés dans le même dépôt Git. Nous avons principalement un premier niveau d’arborescence correspondant à la plate-forme (dev, recette, etc.) et à l’intérieur de ces répertoires, les fichiers de configuration sont nommés en fonction du service concerné ainsi que des paramètres permettant de les spécifier. Au démarrage, chaque service chargera le fichier de configuration /{base_directory}/{platform}/application-{service_name}–{params}.xml
3. Déploiement avec Ansible
Du fait d’une architecture microservices, ces derniers peuvent être déployés sur un ou plusieurs ou même sur tous les serveurs. Le déploiement manuel d’une nouvelle version de service peut très vite être compliquée et chronophage. De plus, notre périmètre étant exclusivement Java, au sein d’un écosystème .NET, nous ne pouvions pas utiliser l’outil de déploiement massif déjà en place chez notre client.
Nous avons choisi d’utiliser “Ansible” qui nous paraissait être le plus efficace, et le moins intrusif dans le sens où il ne fait qu’exécuter des commandes ssh sur les serveurs.
Ansible fonctionne avec des scripts appelés “playbooks” qui permettent de décrire une liste d’opérations à effectuer sur une machine. Il embarque une panoplie de plugins permettant de simplifier l’écriture des scripts, par exemple, le plugin “apt” gère l’installation des packages Linux.
Pour la liste des serveurs auquel Ansible peut avoir accès, il est possible de définir des groupes de “hosts” dans un fichier. Il sera alors possible d’exécuter un playbook sur un serveur ou tous les serveurs du groupe. Il est également capable de paralléliser les actions sur plusieurs serveurs. C’est le playbook qui permet de configurer le pourcentage, ou le nombre de serveurs à traiter en même temps. Par exemple, si vous ne souhaitez pas avoir d’interruption de service, il sera préférable de redémarrer vos microservices 1 par 1, plutôt que de tout relancer d’un coup.
Ansible n’a besoin de rien d’autre qu’un accès ssh sur les serveurs pour fonctionner. Il est donc nécessaire de copier les clés publiques de tous les utilisateurs potentiels d’Ansible sur les serveurs.
4. Monitoring
Plus une architecture devient complexe, plus il devient essentiel de la surveiller. Il est nécessaire de savoir ce qu’il s’y passe et d’être averti en cas d’anomalie.
N’oublions pas que notre périmètre gravite autour de Solr. La priorité pour nous est de monitorer le moteur de recherche avant même de monitorer nos microservices. Par défaut, Solr n’expose pas d’API permettant de connaître sa santé. Il est cependant possible d’utiliser les MBeans JMX, ou encore de surveiller le Zookeeper pour en extraire les informations concernant les noeuds connectés.
1. Microservice de monitoring
Plutôt que de créer une dépendance forte entre la plate-forme de monitoring et la version de Solr, nous avons préféré mettre en place un service pour servir d’intermédiaire. Ce service devrait nous permettre d’encapsuler les appels JMX tout en exposant des endpoints REST, ou encore intégrer un peu d’intelligence pour le contenu des réponses (définition de seuils permettant de déterminer un niveau de santé plus “fin” par exemple). Ce service est destiné à être déployé sur tous les serveurs où existe un Solr. Pour simplifier le monitoring, c’est l’un des seuls services qui démarre sur un port statique et qui ne s’enregistre pas sur Zookeeper, donc non éligible à la découverte de services. Il est maintenant possible d’interroger chacun des noeuds au travers de son service de monitoring (en HTTP GET) afin de récupérer la consommation en temps réel du processeur, de la mémoire, le nombre de requêtes servies, les temps de réponse, etc..
Les sondes Zabbix sont branchées sur ce service, permettant de déclencher des alertes en cas de problème détecté.
2. Monitoring avec la stack Elastic
Lorsque nous avons décidé de mettre en place une stack de monitoring, nous avons étudié rapidement différentes solutions. Les outils proposés par Elastic sont très vite apparus comme une évidence, tant par leur facilité de mise en oeuvre que par l’offre toujours grandissante de fonctionnalités (sans parler de la communauté..).
Elasticsearch
Aujourd’hui, tous ceux qui ont eu à travailler de près ou de loin sur un moteur de recherche ont forcément entendu parler d’Elasticsearch. Nous n’approfondirons donc pas les détails de l’outil, dont nous devons souligner l’excellente documentation.
Sur la première version de notre plate-forme de monitoring, nous n’avions qu’un seul serveur Elasticsearch. Ceci bien entendu pouvait poser des problèmes en termes de sécurisation de la donnée et du volume de données sur lequel il était capable de rechercher. Mais à ce moment là, le client n’était pas encore convaincu du ROI, donc difficile de négocier du budget supplémentaire. Il n’a pourtant pas fallu longtemps pour convaincre de l’intérêt d’une plateforme de monitoring en quasi temps réel.
Nous faisons tourner aujourd’hui 5 noeuds Elasticsearch en version 2.x avec chacun 32Go de RAM et pour un total de presque 2To de stockage.
Comme toujours, avec 2To de stockage, nous pensions être tranquilles pour un moment. Mais évidemment, plus il y a de la place, plus on l’utilise. Nous sommes donc progressivement passés d’un volume de ~2 millions de documents par jour à 30 millions.
N’ayant pas un stockage infini, nous avons du réfléchir à un mécanisme de rotation des données de monitoring. Nous avons donc conservé le principe de base d’utilisation d’indexes quotidiens puis nous avons mis en place Elastic-curator. Elastic-curator est l’outil d’Elastic qui permet l’automatisation de la fermeture ou de la suppression des indexes Elasticsearch.
Logstash
Pour Logstash, et les outils de “shipping” en général, il existe plusieurs écoles. Ceux qui choisissent de mettre tous leurs oeufs dans le même panier en ne démarrant qu’une instance de Logstash pour récupérer l’intégralité des métriques, et ceux qui préfèrent diviser pour mieux régner en séparant les Logstash en fonction des types de métriques à récupérer… Nous faisons partie de la deuxième école, mais il y a une raison à ça. En effet, plus vous récupérez des métriques différentes, plus vous allez complexifier la configuration de Logstash, et donc plus vous avez de risque de mal gérer les erreurs ce qui signifie un arrêt du service. Ce serait dommage que le monitoring devienne aveugle parce que la nullité d’un objet n’a pas été testée… Dans notre contexte, si un Logstash tombe, seuls les KPIs de son périmètre ne sont plus récupérés alors que les autres continuent.
Bien évidement, il ne faut pas tomber dans l’excès en créant autant d’instance de Logstash qu’il y a de KPI différents à récupérer, bon courage pour le maintenir…
Sur notre projet, nous utilisons Logstash de manière “active”, en appelant les endpoints REST des agents de monitoring par exemple, mais aussi de manière “passive”, en écoutant par exemple sur un port UDP.
Kibana
Kibana est l’outil de visualisation des données de la stack Elastic. Par rapport aux autres outils du marché, Kibana se distingue par son interface intuitive de découverte et de parcours des données dans les indexes d’Elasticsearch. Il permet la création de graphiques “time-series” nous permettant de surveiller en temps réel notre plate-forme.
Aujourd’hui, nous avons environ 250 visualisations réparties en une trentaine de dashboards. Certains dashboards ont réellement vocation à être surveillés en permanence, alors que d’autres nous apportent plutôt des moyens d’analyse sur ce qui a pu se passer en cas d’anomalie.
Nous avons installé deux écrans TV dans notre open space sur lequel nous visualisons les dashboards les plus importants nous indiquant l’état de santé de notre système.
Vers une certaine scalabilité
Un arrêt inopiné d’une instance Logstash peut être problématique, et pourtant, ça peut arriver. Tout le temps où le service est arrêté, les métriques ne sont pas récupérées. D’expérience, nous savons que Logstash crashe essentiellement durant sa phase de “filter”, c’est à dire de transformation des messages à envoyer à Elasticsearch. Le meilleur moyen d’éviter la perte d’information est de séparer la partie “récupération” de la partie “transformation” des métriques. Pour cela, il est tout à fait possible de mettre en place un “broker” de type Kafka, Redis (qui n’est pas vraiment un broker) ou encore RabbitMq (Logstash intègre nativement des plugins pour les 3). Un Logstash pourrait alors se charger de la récupération et du stockage de la métrique “brute” dans le broker, et un autre lirait les messages dans le broker pour les transformer et les envoyer à Elasticsearch. Dans le cas où ce dernier viendrait à s’arrêter, les messages s’empileraient dans le broker jusqu’à ce qu’il soit relancé, ainsi aucune métrique ne serait perdue.
L’autre avantage du broker est qu’une même file de KPIs peut très bien être lue par plusieurs consommateurs tout en garantissant que le message ne sera lu qu’une seule fois. Il sera alors possible de lancer plusieurs instances de Logstash qui iront dépiler le même “topic” en prenant les messages les uns après les autres. Si l’un s’arrête, aucun souci, les autres continuent.
5. Vers le déploiement en continu
1. “Containerisation” de nos microservices avec Docker
Depuis le début du projet, les besoins n’ont eu cesse d’évoluer. Et avec eux, le nombre de nos microservices. Malgré l’outillage déjà mis en place, il nous est nécessaire de pouvoir gérer efficacement une plate-forme de plus en plus dynamique. A terme, nous souhaitons ne pas avoir à gérer où ni comment sont déployés nos microservices. Docker paraît être la première étape dans une gestion dynamique de notre plate-forme.
Le principe de Docker est relativement simple. Il permet de cloisonner sous forme d’un container tout un environnement d’exécution. Une fois l’image Docker créée, elle est vouée à être déployée sur les différents environnements, sans connaître de changement. Docker introduit la notion d’immuabilité mais qui n’est pas limitée au livrable, mais à tout son contexte d’exécution.
Il y a quelques notions à maîtriser avant d’utiliser Docker correctement. On utilise le terme d’”image” Docker pour symboliser le livrable immuable contenant un microservice par exemple. En revanche, on appelle “containers” les instances d’une image.
Tout comme un jar peut être construit et versionné, il est possible de rajouter, dans Jenkins, une étape de construction automatique d’une image Docker embarquant la version fraîchement construite du microservice. Nous avons choisi de générer autant d’image Docker que nous avons de versions d’un microservice.
Bien que la mise en place de containers paraisse simple, elle implique souvent des modifications qui peuvent être structurantes.
Rappelons que dans notre cas, les microservices démarrent sur un port dynamique et s’enregistrent dans Zookeeper.
Par défaut, Docker ajoute une couche d’abstraction au réseau, en permettant de gérer du binding de ports entre le serveur hôte et le container soit de manière statique (port 80 de l’hôte vers port 8080 du container) soit de manière dynamique. Pour le binding dynamique, Docker alloue un port disponible de l’hôte parmi une plage de ports définie pour chaque port exposé par un container. A l’heure actuelle, il n’est donc pas possible de gérer du binding statique (impossible de connaître à l’avance le port du container à binder) ni même dynamique. En effet, si notre service, à l’intérieur d’un container, démarre sur le port 12345, et que le container s’appelle “service_name”, le service va indiquer dans Zookeeper qu’il est disponible sur le serveur “service_name:12345”. Avec le binding dynamique, Docker pourrait avoir créer un pont entre le port 54321 de l’hôte vers le port 12345 du container. De même, le nom d’un container ne représente en rien un nom de machine ou de lien DNS. Si on veut que le service puisse être accessible depuis l’extérieur, nous avons besoin d’enregistrer dans Zookeeper l’adresse “host_name:54321”. Notre microservice ne sachant pas qu’il se situe sur un réseau virtuel, le mécanisme d’enregistrement doit donc être déporté au niveau de Docker, au niveau du serveur hôte.
Pour cela, il existe un outil open source disponible sur GitHub, permettant d’enregistrer les changements d’état des containers tournant sur serveur dans Zookeeper ou d’autres comme Consul, ou Etcd par exemple (https://github.com/gliderlabs/registrator).
Avant de mettre en place une telle mécanique, et de déporter toute la logique d’enregistrement et de découverte, nous allons passer par une étape intermédiaire. Docker permet, même si c’est très fortement déconseillé en production, de ne pas virtualiser le réseau des containers. Il suffit d’utiliser le paramètre de démarrage –net=host pour que le container utilise directement le réseau de l’hôte. Ainsi, nous pourrions conserver la gestion des ports dynamique au niveau du microservice dans un premier temps.
2. Provisionning et déploiement auto avec Mesos
Quel est le véritable intérêt d’exécuter nos microservices dans des containers ? Maîtriser le contexte d’exécution quelle que soit la plate-forme en proposant une image immuable de l’environnement de développement jusqu’à la production ? En fait, ce n’est pas vraiment notre objectif principal. Pour nous, le principal intérêt réside dans l’écosystème qui existe aujourd’hui autour de Docker. Notre premier objectif est de ne plus à avoir à déployer manuellement nos microservices. Bien qu’Ansible nous ait permis de gagner un temps précieux, nous souhaitons, à terme, que la plate-forme soit capable de gérer elle même.
Il existe une multitude d’outils dits de “provisionning” pour Docker. Les plus importants sont Mesos (Mesosphere), Kubernetes (Google), ou encore Rancher (Rancher Labs).
Sur notre projet, c’est Mesos qui a été imposé par les équipes d’exploitation, choix fait par rapport à leurs compétences déjà existantes sur cette application et pas sur les autres. Microsoft étant un utilisateur de Mesos, ceci a également pesé dans la décision.
Mesos permet de gérer un ensemble de machines comme si elles ne faisaient qu’un “tout”, qu’un seul et même serveur, en mutualisant l’intégralité des ressources disponibles. Un agent Mesos Slave doit être installé sur tous les serveurs, configurés pour communiquer avec un Mesos Master. Cet agent va permettre de préciser au Master, le CPU ou la Ram encore disponible de chaque serveur possédant l’agent.Une fois le cluster Mesos installé et configuré, il est possible d’ajouter l’application Marathon, qui permet de gérer graphiquement, à l’aide d’une interface web, la liste des applications déployées sur Mesos.
C’est dans cette application que nous devrons configurer la liste des microservices à exécuter, le nombre d’instance de chaque, ainsi que leurs paramètres spécifiques.
C’est Mesos qui devient alors garant de l’état de notre plate-forme. Si une instance d’un service s’arrête, Mesos est capable de la relancer immédiatement. De même si un serveur hôte s’arrête, Mesos prendra en charge le démarrage des containers “perdus” sur les autres hôtes en fonction de leur taux d’occupation et des ressources encore disponibles.
L’avantage d’une gestion dynamique de la plate-forme est non seulement l’assurance qu’un service reste opérationnel, mais également qu’il est capable de garder des performances équivalentes malgré la fluctuation de son utilisation. Dans les projets e-commerce, il est fréquent de constater des hausses d’activité à certaines heures de la journée, et lors de journées spéciales telles que les soldes. Les outils comme Mesos sont parfaitement capables de répondre à ces besoins ponctuels en démarrant automatiquement des nouveaux containers si un seuil défini est atteint, c’est ce que nous appelons l’”auto-scaling”.
Avec la mise en place de cet outil, nous affichons clairement la volonté de ne pas avoir besoin de savoir où sont démarrés nos services, mais uniquement de savoir qu’ils existent, qu’ils sont bien démarrés, et que le nombre d’instances en fonctionnement d’un microservice reste cohérent et maîtrisé.
3. Sécurisation des déploiements
Quelle que soit l’architecture d’une application (microservices ou monolithique) ou bien le type d’infrastructure (serveurs physiques ou bien cloud) nous nous apercevons que beaucoup d’erreurs, pouvant entraîner un arrêt de service en production, sont liées à une “erreur humaine”, une opération manuelle.
La mouvance du “continuous delivery” se base sur le principe que moins il y a d’intervention manuelle, plus vite le déploiement pourra être fait tout en minimisant le risque d’erreur. Des outils tels que Spinnaker, rendu open source par Netflix, permettant l’automatisation de tout le pipeline de déploiement, commencent à émerger. Nous pourrions citer également Jenkins, qui offre dans sa version 2 cette gestion de pipelines de déploiement. Attention, nous parlons bien ici de “pipeline” et non de “workflow”, il paraît que nous n’avons plus le droit de le dire…
Ici le terme “pipeline” permet d’identifier la liste de toutes les étapes par lesquelles un microservice doit passer avant d’arriver en production.
Spinnaker permet de configurer cette liste d’étapes, depuis la création du livrable par Jenkins, jusqu’à la mise en service sur la plate-forme de production. Historiquement, Spinnaker a été pensé pour du déploiement sur le cloud, mais rien ne l’empêche de s’interfacer avec un cluster Mesos hébergé sur site. Les étapes peuvent s’enchaîner de manière automatique, ou attendre une validation manuelle à l’aide d’un clic sur l’interface web. Par exemple, une fois le livrable déployé sur un environnement de développement, les tests d’intégration peuvent se lancer automatiquement, et au contraire, il sera préférable d’attendre une validation fonctionnelle des utilisateurs avant de demander à Spinnaker de continuer le déploiement vers la recette.De plus, le déploiement d’une nouvelle version d’un service peut être opérée de différentes manières. Spinnaker propose, entre autres, le mode “Blue/Green testing” ou le mode “Canary testing”.
Le Blue/Green consiste à démarrer la nouvelle version d’un microservice de façon à ce que les deux versions puissent cohabiter. Il suffira ensuite d’action un interrupteur pour diriger le trafic de la version actuelle (la version “blue”) vers la nouvelle (la version “green”). Si jamais la nouvelle version ne répond pas aux attentes, il sera toujours possible d’actionner l’interrupteur dans l’autre sens afin de se retrouver en version “blue”, toujours sans interruption de service.
Le Canary testing propose quant à lui de ne remplacer qu’une petite partie des microservices par la nouvelle version (environ 10%). Pas trop, pour ne pas risquer de pénaliser les utilisateurs, mais suffisamment pour être capable de mesurer l’impact de la migration. Une fois le comportement de la nouvelle version étudié et validé comme étant celui attendu, d’autres microservices peuvent être remplacés progressivement (ou massivement) jusqu’à avoir complètement migré.
Dans tous les cas, Spinnaker gère le rollback si une opération ne s’est pas déroulée comme prévu.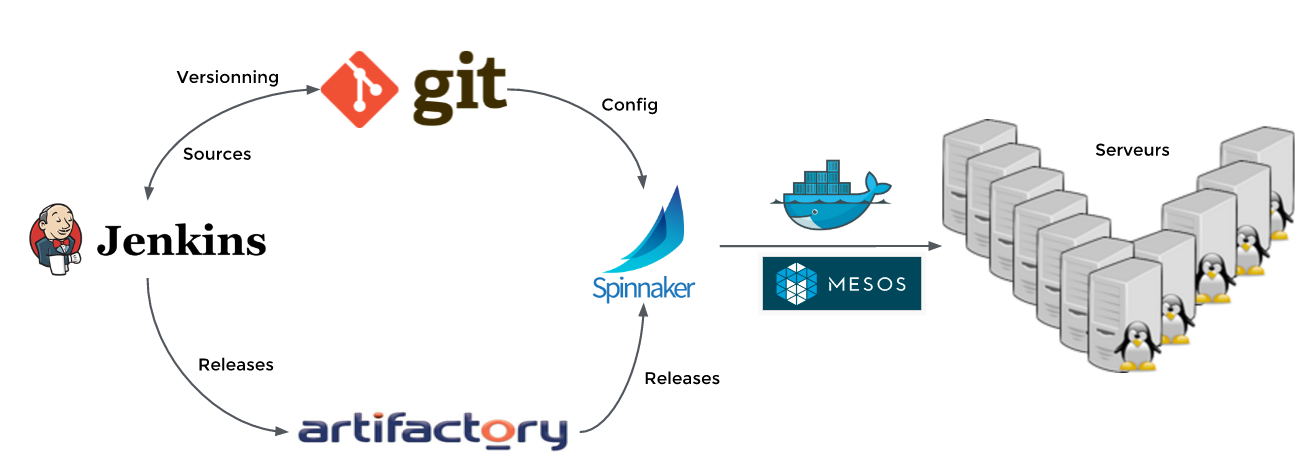
Dans notre environnement cible, une fois le code validé, et mis à disposition dans Git, Jenkins et Spinnaker seront capables de le compiler, le tester, et le déployer sur notre plate-forme de développement. jusqu’ici, pas grand chose de nouveau. Par contre, une fois le microservice versionné, et mis à disposition dans Artifactory, Spinnaker n’aura qu’à attendre notre validation avant de faire avancer cette nouvelle version au travers de nos différents environnements jusqu’à la production, sans aucune opération manuelle (excepté la validation), en minimisant donc les risques d’erreur.
