
Article #4 – Hystrix, son dashboard et la stack ELK
Notre registre de services (Eureka) est en place, ainsi que notre point d’entrée (Zuul) avec le chargement dynamique de filtres depuis Cassandra. Il reste un dernier point à aborder, assez important pour y consacrer une partie de ce REX : que faire lorsqu’un service ne fonctionne plus ? Comment le savoir ? Comment le prévenir ?
Rappel : Cet article s’inscrit dans une série d’articles formant un retour d’expérience sur la création d’une architecture orientée microservices.
- Article #1 – Contexte et définition de l’application
- Article #2 – Eureka, registre de services au coeur de l’architecture
- Article #3 – Zuul, gatekeeper et filter loader depuis Cassandra
- Article #4 – Hystrix, son dashboard et la stack ELK
- Article #5 – Quelques éléments de conclusion
La solution Hystrix
“Fail fast, rapid recovery”
Les services sont amenés à arrêter de fonctionner à plusieurs reprises, du fait de leur répartition, ou encore du nombre trop important de requêtes. C’est un phénomène qualifiable de “récurrent” dans le domaine des microservices, ce qui a forcé les développeurs à créer un outil qui permettrait d’empêcher le blocage d’un service, d’adapter son comportement quand cela arrive, voire essayer de prévenir la faille.
Since services can fail at any time, it’s important to be able to detect the failures quickly and, if possible, automatically restore service.
Martin Fowler, dans son article au sujet des microservices (mentionné dans le premier article de notre série), nous parle de “détection des failles” et de “restauration des services”. Si le service doit s’arrêter, il faut qu’il s’arrête assez vite pour que l’on puisse y remédier tout aussi rapidement.
Les différentes fonctionnalités d’Hystrix
Conscient de cette problématique, les ingénieurs de Netflix (et oui, encore eux !) ont décidé de partager leur solution de “fault tolerance” avec la communauté, en créant Hystrix, logiciel open source faisant partie de la stack Netflix OSS. Ce logiciel permet de faire s’arrêter rapidement un service qui ne peut plus fonctionner. Hystrix implémente aussi un système de “circuit breaker” qui permet de rompre le lien entre la requête et le service destiné à fonctionner, pour éviter des problèmes d’overload. En ouvrant le circuit, Hystrix va signaler à Eureka que le service ne peut plus fonctionner correctement, afin de rediriger les requêtes sur d’autres instances de ce service. Ce signalement se fait indirectement, car le service en question, étant en circuit ouvert, n’enverra plus de heartbeat à Eureka, qui va donc, purement et simplement, le retirer de son registre.
Hystrix propose aussi une solution de “fallback” afin de minimiser l’impact aux yeux de l’utilisateur. Ce fallback est représenté sous la forme d’une méthode qui sera déclenchée si le service ne répond pas, quelle qu’en soit la raison. Afin de pouvoir y prétendre, il faut créer une classe qui représentera la fonctionnalité du service en question, et qui devra hériter de la classe abstraite HystrixCommand.
Et afin d’améliorer l’expérience Hystrix, Netflix a aussi dévoilé un dashboard utilisé en combinaison avec Hystrix afin d’avoir des informations sur l’état de santé des commandes Hystrix en temps réel. Le dashboard est une application à part entière qu’il s’agira de lancer préalablement aux services. Récupérer le dépôt Git et lancer l’application suffisent pour pouvoir utiliser le dashboard.
Avant de créer ces classes et de pouvoir monitorer votre application, il faut annoter vos services avec @EnableHystrix et @EnableHystrixDashboard
<dependency>
<groupid>org.springframework.cloud</groupid>
<artifactid>spring-cloud-starter-hystrix-dashboard</artifactid>
</dependency>
<dependency>
<groupid>com.netflix.hystrix</groupid>
<artifactid>hystrix-javanica</artifactid>
<version>1.4.0-RC6</version>
</dependency>
<dependency>
<groupid>com.netflix.hystrix</groupid>
<artifactid>hystrix-core</artifactid>
<version>1.4.0</version>
</dependency>
Dépendances
@SpringBootApplication
@EnableEurekaClient
@EnableHystrix
@EnableHystrixDashboard
public class ProductApplication {
public static void main(String[] args) {
SpringApplication.run(ProductApplication.class, args);
}
}
ProductApplication.java
Maintenant que notre service est proprement annoté, voici comment créer vos classes représentant vos commandes Hystrix, dans les grandes lignes :
public class GetDetailsCommand extends HystrixCommand<DetailsDTO> {
@Autowired
private RestTemplate rt;
@Autowired
private DiscoveryClient dc;
public GetDetailsCommand() {
super(HystrixCommand.Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("product"))
.andCommandKey(HystrixCommandKey.Factory.asKey(getDetails)));
}
@Override
protected DetailsDTO run() throws Exception {
String url = dc.getNextServerFromEureka("details-service", false).getHomePageUrl();
...
return rt.getForObject(url, DetailsDTO.class);
}
@Override
protected DetailsDTO getFallback() {
System.out.println("getDetails fallback.");
return null;
}
}
GetDetailsCommand.java
Cette méthode fallback permet d’imaginer bon nombre de solutions pour gérer ce cas de figure, comme par exemple retourner un résultat de requête précédent issu d’un cache, ou rediriger vers un autre service, etc. La structure étant assez implicite, les solutions sont multiples, c’est pourquoi aucun exemple n’est vraiment donné ici.
Le dashboard Hystrix
Maintenant que les commandes sont en place, vous pouvez lancer une instance d’Hystrix dashboard. En vous connectant à cette application, vous tomberez sur cette page d’accueil :
 Il vous suffit désormais de renseigner l’URL de votre service utilisant les
Il vous suffit désormais de renseigner l’URL de votre service utilisant les HystrixCommand mentionnées plus haut, en rajoutant /hystrix.stream à la fin. En cliquant sur Monitor Stream, vous tomberez sur une page similaire à celle-ci :

Vous voici devant votre dashboard représentant l’activité de vos commandes, donc de vos services, en temps réel. Retrouvez les explications concernant les différents indicateurs sur la page wiki du dashboard Hystrix.
Logging avec la pile Elasticsearch-Logstash-Kibana
Maintenant que tout est en place, et du fait de cette architecture fortement scalable, les services vont s’y multiplier à grande vitesse, et plusieurs instances d’un même service vont se créer. Cela va devenir très vite assez complexe comme environnement et il sera difficile de pouvoir suivre l’activité d’un service en particulier si jamais il venait à devenir défectueux. Rassembler les logs peut aussi permettre, dans une certaine mesure, de prévenir les dysfonctionnements et de repérer assez rapidement quel service ne fonctionne pas bien.
Depuis la console et les fichiers de logs …
Spring Boot génère déjà un certain nombre de logs qui peuvent s’avérer pratiques, depuis le lancement des multiples beans et de Tomcat jusqu’à certains logs liés aux requêtes entrantes, par exemple. Nous avons donc choisi de réutiliser ceux-là et d’y rajouter quelques informations :
- Le PID de l’instance du service en question
- Un UUID qui permettrait de suivre la requête depuis son entrée dans l’application, jusqu’à l’écran de l’utilisateur
Ces informations sont donc intégrées dans les logs que nous avons choisi de stocker dans la machine où sont exécutés les services (machine locale ou VM) afin de les propager plus tard.
Pour pouvoir rajouter ces informations, nous avons utilisé Logback afin de pouvoir rajouter manuellement des éléments aux logs déjà existants. Nous récupérons donc le PID du service instancié pour l’intégrer aux logs.
Un UUID a été rajouté en utilisant Zuul via un filtre. Ce dernier va rajouter dans un header custom X-RequestID une valeur UUID random, et il sera possible de la récupérer dans chacun des services et de l’écrire dans les logs console et fichiers. Cette valeur permettra de suivre le parcours d’une requête dans les nombreux services qu’elle a traversé et détecter des problèmes, ou simplement vérifier que cela fonctionne bien.
Il faut savoir aussi que Kibana permet notamment de récupérer le hostname de la machine depuis laquelle les logs ont été récupérés, ce qui peut aussi servir pour retrouver un service en particulier.
… en passant par Logstash …
Après avoir stocké les logs dans des fichiers locaux à une machine, il faut pouvoir les envoyer vers une instance Elasticsearch. Ce dernier est un moteur de recherche libre et open source (comme ses camarades Logstash et Kibana) basé sur Lucene, librairie de la fondation Apache. Elasticsearch rajoute une interface de type API Web (permettant par exemple l’indexation à partir de requêtes HTTP) à Lucene et assure les mécanismes d’indexation et de recherche de données.
input {
file {
type => "java"
path => "/home/ubuntu/logs/*.log"
codec => multiline {
pattern => "^%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{TIME}.*"
negate => "true"
what => "previous"
}
}
}
...
output {
...
elasticsearch {
host => "10.0.40.13"
}
}
logstash.conf
Logstash, par opposition à Elasticsearch, est lancé dans la même VM que celle contenant certains services. Ainsi, Logstash récupère les logs écrits localement par les services et Spring Boot, et les distribue à l’instance distante d’Elasticsearch. Une problématique pourrait se poser à grande échelle : Logstash a cet inconvénient d’être assez lourd comme processus, et placer une instance dans chaque VM, parmi des services potentiellement assez gourmands en ressources, peut rapidement devenir gênant. Mais c’est une autre histoire…
… vers le visualiseur de données Kibana
Maintenant que les logs sont stockés dans Elasticsearch, il est possible de les visionner, d’en faire des graphiques ou d’afficher certains logs plutôt que d’autres, en utilisant Kibana. Il s’agit là d’un outil très important car il permet de mettre de l’ordre dans la multitude de données qui peuvent être utilisées.
Pour lancer une instance de Kibana, il suffit de télécharger le zip et de rajouter l’URL d’Elasticsearch dans le fichier config/kibana.yml. En se dirigeant ensuite sur l’interface graphique de Kibana (à l’adresse http://yourhost.com:5601), vous pouvez créer des graphiques en fonction de plusieurs données, notamment timestamp ou encore les différents hostname des machines. Voici à quoi ressemble un graphique dans Kibana :
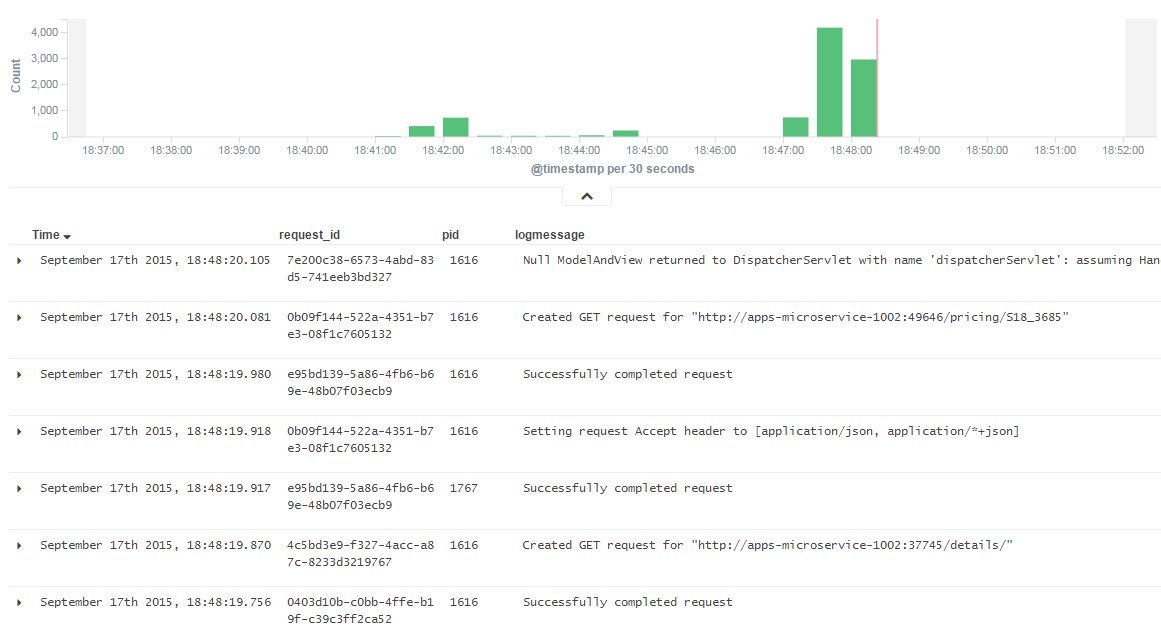
La combinaison de ces 3 outils, ainsi que les logs Spring Boot et l’utilisation de Logback, les logs sont ainsi stockés et consultables par le biais d’une interface graphique.
