
Nous avons vu dans un premier article comment modéliser une facture. Dans ce contexte, nous pouvions rechercher les factures associées à un client. Il arrive cependant qu’on souhaite rechercher les données via d’autres critères, voire selon une combinaison de critères possibles. C’est la fameuse recherche multicritère classique dans les applications traditionnelles. Si elle a tendance à disparaitre pour des recherches simplifiées, elle possède ses avantages et est parfois demandée avec insistance par le client. Nous allons voir maintenant comment résoudre le problème.
Avertissement

Les modélisations présentées dans cet article ont été réalisées par des professionnels.
N’essayez en aucun cas de les reproduire vous-même !
La recherche multicritère est un antipattern de Cassandra, sa mise en œuvre doit être réalisée avec la plus grande attention.
Modèle conceptuel
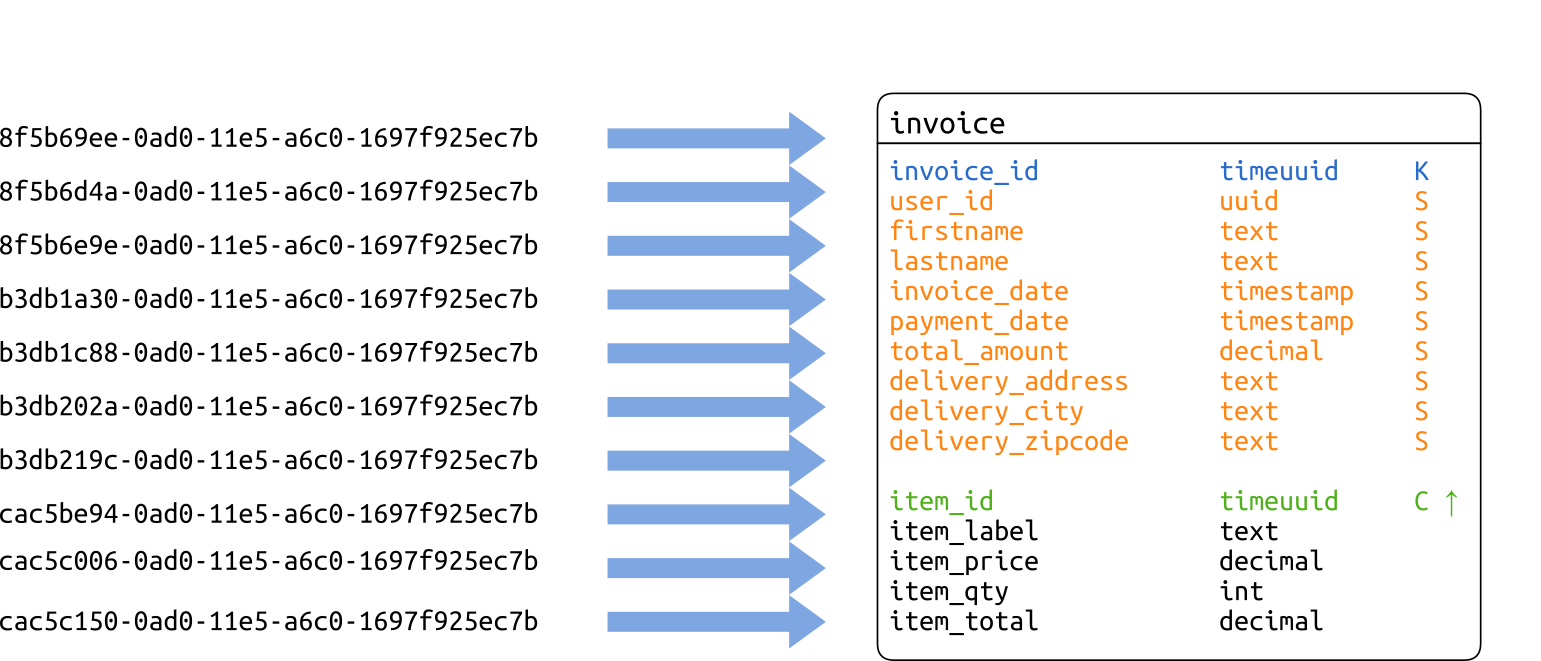
Pour cet article, nous reprendrons le modèle de la gestion de facture que nous modifierons un peu. Maintenant, notre application de facturation est fournie en mode SaaS hébergée par nos soins via la meilleure solution cloud du marché qui nous permet d’avoir une immense base de données qui contient toutes les données de tous nos utilisateurs.
Nous introduisons donc la notion d’utilisateur de l’application. Toutes les données sont maintenant cloisonnées par utilisateur. Notre modèle conceptuel est donc le suivant :
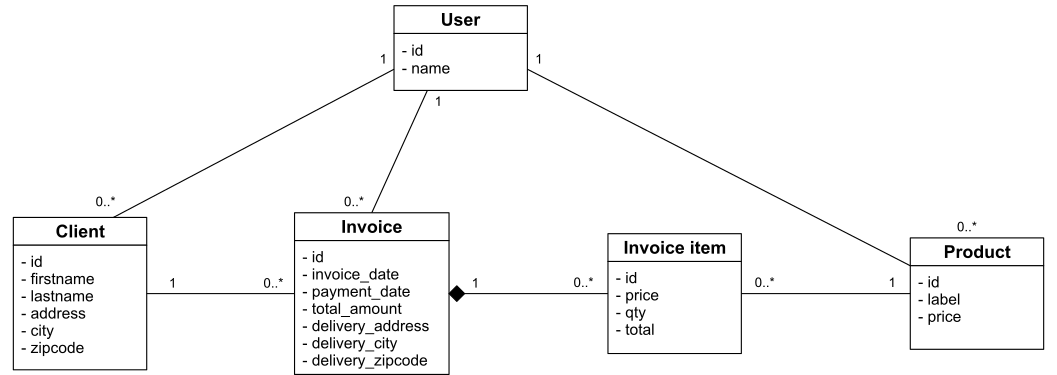
L’ajout de l’entité utilisateur parait anecdotique, mais c’est un prérequis indispensable au bon fonctionnement de la recherche multicritère.
Modèle logique
Comme nous l’avons fait lors de la modélisation des factures, nous créons une seule table qui imbrique l’entité InvoiceItem dans une partition représentant une entité Invoice. Conformément à la modélisation classique d’une relation de composition 1-n.
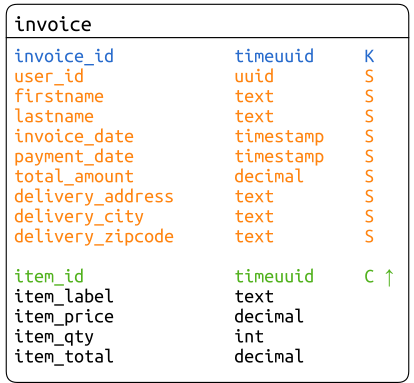
Recherche multicritère
Nous voulons pouvoir effectuer une recherche multicritère avec les caractéristiques suivantes.
Deux critères sont obligatoires:
- l’utilisateur, est un critère implicite qui n’a pas à être saisi, puisque chacun ne peut chercher que dans ses données ;
- la date de facturation, sous la forme d’une plage de dates, début et fin.
S’ajoutent ensuite des critères facultatifs :
- le nom du client ;
- le prénom du client ;
- la ville de livraison ;
- le code postal de livraison.
La recherche est paginée. Les factures sont présentées dans l’ordre antéchronologique.
Pour un tel cas d’usage, la solution la plus évidente est de coupler un moteur de recherche avec notre base. Nous pourrions ainsi déployer un cluster Elasticsearch ou Solr et y indexer nos factures à la création. Cette solution est la meilleure en terme de fonctionnalités, mais reste complexe. Nous devons créer et maintenir un deuxième cluster et nous assurer que les données qu’il contient sont cohérentes avec celles de Cassandra. Et ce n’est pas aussi simple qu’on peut le croire, surtout avec un base gigantesque telle que le produit notre application SaaS.
Ici, nos besoins étant limités à des recherches simples et exactes, nous ne souhaitons pas ajouter cette complexité.
Les experts qui me liront diront que, comme nous avons une base installée importante, nous avons pris du support auprès de DataStax et que dans la distribution DataStax Entreprise (DSE), il y a une version de Solr prête à l’emploi et totalement intégrée. Nous pouvons ainsi bénéficier des avantages d’un moteur de recherche documentaire en ne gérant qu’un cluster, la cohérence entre les tables et l’index étant, de plus, garantie par DSE.
Tout ceci est parfaitement vrai, mais ne pourrait nous suffire. En effet, si vous avez bien remarqué les critères de recherche, nous ne cherchons que sur des colonnes statiques or l’intégration de Solr ne les gère pas à ce jour. De plus, nous cherchons des partitions (des factures) alors que ladite recherche Solr nous retourne des lignes. L’intégration Solr ne nous est donc d’aucune aide pour l’instant.
On pourrait penser aux index secondaires. Mais d’une part, on ne peut en utiliser qu’un à la fois et, d’autre part les index secondaires de Cassandra sont tellement particuliers qu’il vaut mieux les fuir.
Table d’index
Le mieux est de se rapprocher du fonctionnement des index inversés. Pour cela nous allons créer une table d’index pour chaque critère secondaire. Une table d’index ne contient pas d’autres données que sa clé primaire. La clé de partition contient l’identifiant de l’utilisateur, la date de facturation (sans les heures), le critère secondaire. La clé primaire se termine par l’identifiant de la facture comme unique clustering column classée dans l’ordre décroissant pour que les factures les plus récentes soient présentées en premier.
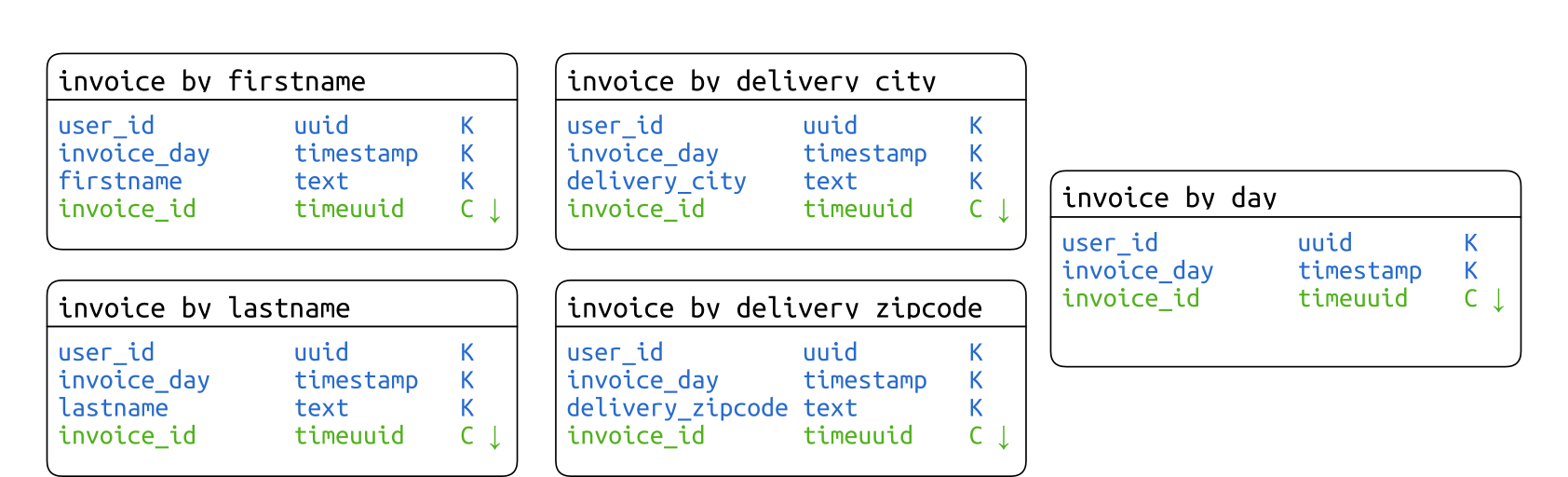
Notez que jusqu’à la version 2.1 de Cassandra, il faut gérer soit même le contenu de la table, écrivant dans l’index en même temps. Cette gestion est facilitée parce qu’une facture n’est en principe jamais modifiée, tout changement donnant lieu à l’édition d’une nouvelle facture qui annule la précédente.
À partir de la version 3.0, nous bénéficions des vues matérialisées. Il suffit de la créer avec la commande suivante pour que Cassandra prenne en charge la dénormalisation des données.
-- A partir de Cassandra 3.0 CREATE MATERIALIZED VIEW invoice_by_firstname AS SELECT invoice_id FROM invoice WHERE firstname IS NOT NULL PRIMARY KEY ((user_id, invoice_day, firstname), invoice_id) WITH CLUSTERING ORDER BY (invoice_id DESC)
Chercher dans les index
La recherche proprement dite s’effectuera simplement :
Pour une journée donnée et pour chaque critère de recherche renseigné, on effectue une recherche sur l’index correspondant au critère. Toutes les recherches sont envoyées en parallèle grâce à l’API asynchrone du driver Cassandra. Comme les résultats sont classés dans l’ordre décroissant, l’intersection des résultats est effectuée simplement en parcourant les resultSets en parallèle en ne conservant que les valeurs présentes dans tous. On s’arrête dès qu’on a assez de résultats pour remplir la page ou qu’un des resultSets est vide.
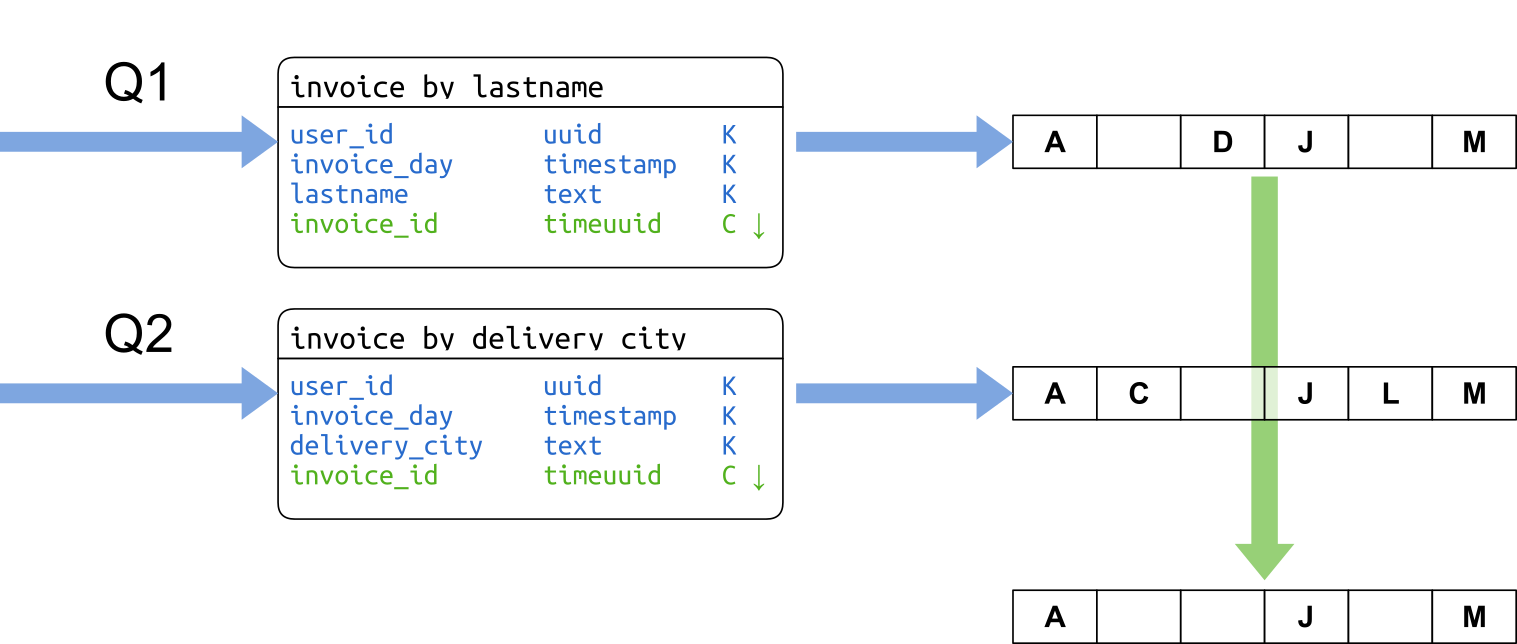
Recherche en parallèle sur deux index et intersection des résultats en mémoire.
Si la première journée ne suffit pas à remplir une page de résultat, on recommence la journée précédente jusqu’à atteindre le début de la plage demandé.
La combinaison de la pagination des résultats, de la lecture paresseuse des resultSets et du classement cohérent des identifiants, permet à la fois d’économiser la mémoire de travail et de ne transférer vers le client que les données nécessaires. La mémoire nécessaire pour traiter une requête est bornée par la mémoire nécessaire pour stocker une page de résultat et les tampons des resultSets.
Une fois qu’on a obtenu une page d’identifiants, il suffit de charger toutes les factures à partir de leur identifiant. Dans ce cas, il est préférable de lancer toutes les requêtes – une par identifiant – en parallèle et de regrouper les résultats. Comme cela, on répartit les requêtes sur tous les nœuds du cluster. L’erreur serait de lancer une seule requête avec une clause where ... in (..., ...) qui charge un seul nœud coordinateur.
Chargement en parallèle des factures de la page de résultat.
private int loadInvoices(List
Cette méthode charge les factures d’une journée dans la liste de résultats passée en argument dans la limite de limit documents.
Le deuxième argument, uuidIt, est l’itérateur qui correspond à l’intersection des lectures d’index qui est ici consommé de façon paresseuse.
Complexité
Tout comme nous avons limité l’empreinte mémoire utilisée, il est important de vérifier que le nombre de requêtes est maitrisé. Un nombre de requêtes trop important risquerait de surcharger le cluster et ralentir les performances de façon générale.
Ici, nous effectuons au maximum une requête d’index pour chaque journée dans la plage de dates et pour chaque critère secondaire renseigné. Chacune de ces requêtes est de complexité partition by query qui correspond à la complexité minimale pour une requête Cassandra. À ceci s’ajoute une requête par élément trouvé dans la limite du nombre d’éléments dans la page.
Ainsi, si nous avons une requête avec 3 critères, une plage de 7 jours et une page de 100, le nombre de requêtes est inférieur ou égal à 121 (3 × 7 + 100).
Il suffit de borner la largeur possible de l’intervalle des dates et la taille des pages pour borner le nombre de requêtes et assurer que la complexité de la recherche est de type partitions by query. C’est moins rapide qu’une requête unitaire, mais ça reste scalable. Sur le terrain, on obtient de très bonnes performances avec 5000 utilisateurs simultanés et 99% des temps de réponse sous la centaine de millisecondes avec un seul serveur frontal et un cluster de 5 nœuds Cassandra.
Autrement dit, si Cassandra n’est pas faite pour la recherche multicritère, il est possible, dans certains cas, de lever cette limitation et de la faire fonctionner correctement.
Pour aller plus loin
Le sujet sera exposé au Cassandra Summit http://cassandrasummit-datastax.com/ du 22 au 24 septembre 2015. En plus de la modélisation, vous y découvrirez l’implantation complète de la solution qui représente un bel exemple d’utilisation du driver Cassandra avec Java 8.
Ceux qui ne pourront se déplacer à Santa Clara pourront venir chez Ippon pour un IppEvent qui reprend l’exposé le 10 septembre ou faire intervenir l’auteur chez vous lors d’un Brown Bag Lunch.
Vous souhaitez tout savoir du Big Data (architectures, solutions, freins et opportunités…) ? Découvrez notre livre blanc Big Data !
