
Le principal impact pour le développeur de l’utilisation des bases de données NoSQL est le changement profond du modèle de données. Ce n’est pas pour rien qu’elles sont qualifiées de « NoSQL », c’est-à-dire « dont le modèle de données n’est pas relationnel ». Les raisons de ce changement de modèle n’est pas dans le cadre de cet article.
Ce qui nous intéresse ici, c’est que nous devons revoir la façon de modéliser les données lors de la conception d’une nouvelle application.
Factures et commandes dans Cassandra
Aujourd’hui, je vous propose de voir le cas concret de la modélisation des factures ou des commandes dans Cassandra.
Ce premier exemple n’est pas choisi au hasard : c’est un cas concret très fréquent dans les applications de gestion. Il correspond à un cas d’école pour expliquer les jointures du SQL, mais aussi les documents de MongoDB. Nous verrons que contrairement à ce qu’on pourrait penser a priori, il se modélise très bien dans Cassandra à condition de bien comprendre le modèle CQL3.
Modèle conceptuel
Avant de partir dans la modélisation spécifique à Cassandra, prenons un instant pour construire un modèle conceptuel et dessinons-le sous la forme d’un diagramme UML.
Nous allons prendre le cas d’une facture, la commande étant identique à ceci prêt qu’il y a écrit « commande » au lieu de « facture » sur l’entête. Une facture est un document composé principalement de deux parties :
- Une entête (invoice) qui contient toutes les informations générales : - un identifiant de la facture ;
- la date de la facture ;
- les informations sur le client ; - nom,
- adresse
- la date de paiement ;
- le montant total de la facture ;
- …
- Une liste de lignes de facturation (invoice item) qui détaille l’ensemble des objets et des prestations facturées. Chaque ligne contient des informations comme : - un identifiant de la ligne ;
- la description de l’objet ou la prestation facturée ;
- la quantité facturée ;
- le prix unitaire ;
- éventuellement le total de la ligne ;
- …
Une ligne de facturation n’existe que dans le cadre d’une facture donnée. Il s’agit dont d’une relation de composition.
La facture est généralement liée à l’entité du client (client) facturé. Les lignes sont, elles, liées au produit vendu. Cependant, une facture n’étant pas modifiable, toutes les données modifiables de ces entités sont copiées pour garantir la validité des données.
Nous obtenons le diagramme suivant.

Le modèle de données de Cassandra
Avant de nous lancer dans la modélisation de notre facture dans Cassandra, il est important de bien comprendre le modèle de la base. J’imagine, Ô lecteur, que tu sais que Cassandra est une base de données de type famille de colonnes. Pourtant, avec l’arrivé de CQL3, le modèle logique de la base a complètement changé. Et l’ancien modèle de Map<SortedMap> inspiré de Google Big Table est sur le point de disparaitre.
Actuellement, Cassandra est une base de données que je qualifierais de tabulaire partitionnée. Les données sont organisées en tables, dont les colonnes et leurs types sont définis par un schéma. Chaque ligne est identifiée par une clé primaire. Les lignes peuvent être regroupées dans une partition. Une partition est identifiée par une clé de partition qui est un préfixe de la clé primaire de la table. Cassandra garantit que toutes les lignes d’une partition sont stockées ensemble. De plus, elles sont classées par l’ordre lexicographique des colonnes de la clé primaire qui ne font pas partie de la clé de partition. Ces colonnes importantes sont appelées « clustering columns ». Grâce à cela, il est possible de demander toutes les lignes d’une partition à la fois ou de demander une tranche de lignes en ne précisant les valeurs que d’un préfixe de la clé primaire ou une inégalité sur la dernière clustering column.
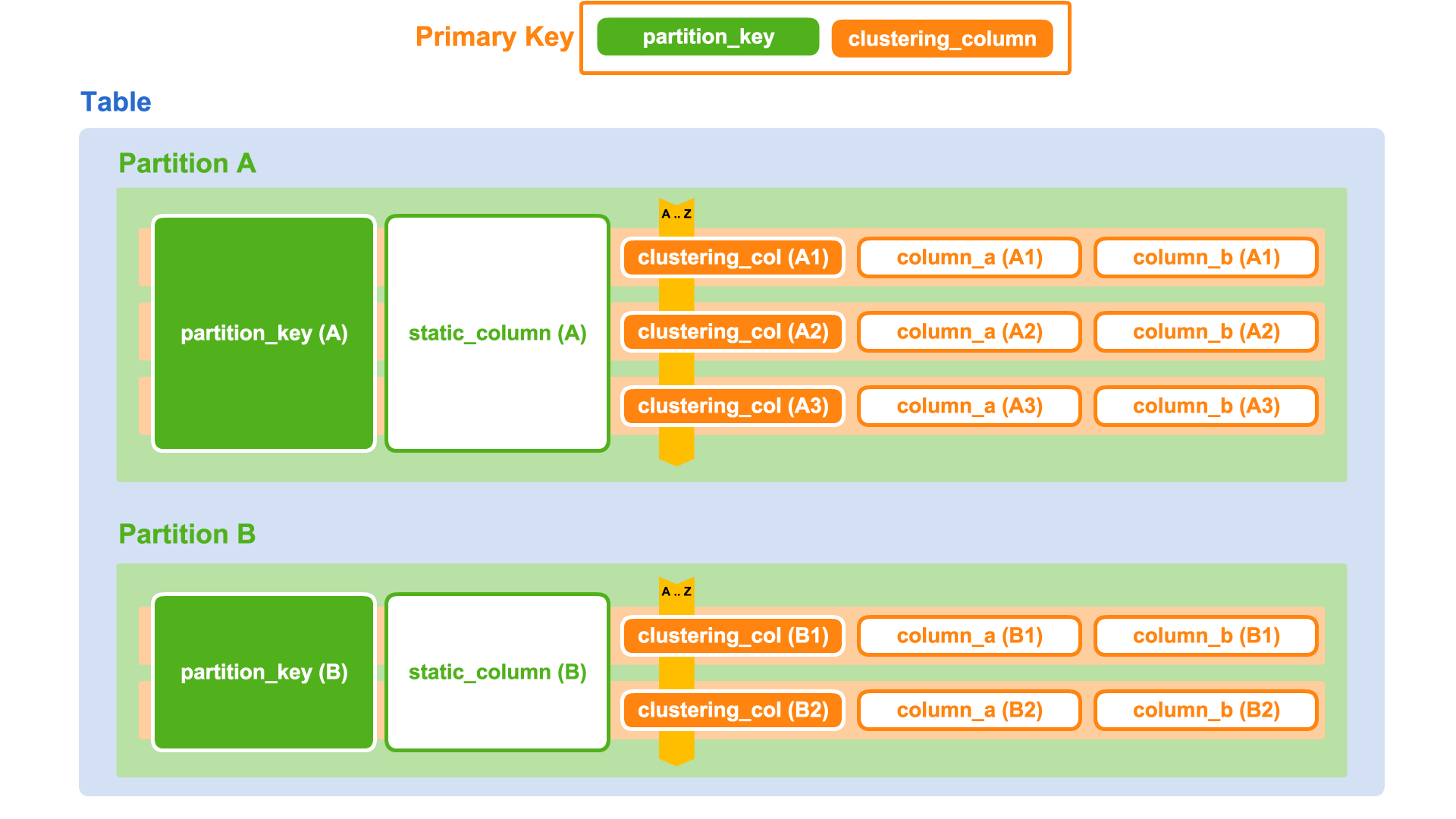
Une partition peut posséder des colonnes qui lui sont propres. Qualifiées de statiques, elles ne sont stockées qu’une fois par partition et possèdent la même valeur pour toutes les lignes de cette dernière. Le mot-clé static utilisé dans la définition a été pris du mot-clé en Java qui permet de partager une valeur entre toutes les instances d’une même classe.
Modèle logique
Après ce petit détour théorique, voyons comment modéliser notre facture dans Cassandra.
En général, lorsqu’on modélise une base Cassandra, on recense toutes les requêtes en lecture qu’on veut pouvoir exprimer et on construit les tables qui répondent à ce besoin. Les requêtes auxquelles nous voudrons répondre ici sont :
- Lister les factures d’un client du plus récent au plus ancien. Seul un résumé de la facture devra être affiché.
- Charger le détail d’une facture à partir de l’identifiant de facture trouvé grâce à la première requête.
À partir de ces requêtes, nous allons construire un diagramme de Chebotko. Ce dernier permet de réfléchir à la modélisation des tables Cassandra. Il doit son nom au premier auteur de la formation à la modélisation de Cassandra qui n’a pas trouvé mieux pour se faire connaitre que de donner son nom à ces diagrammes.
Lister les factures du client
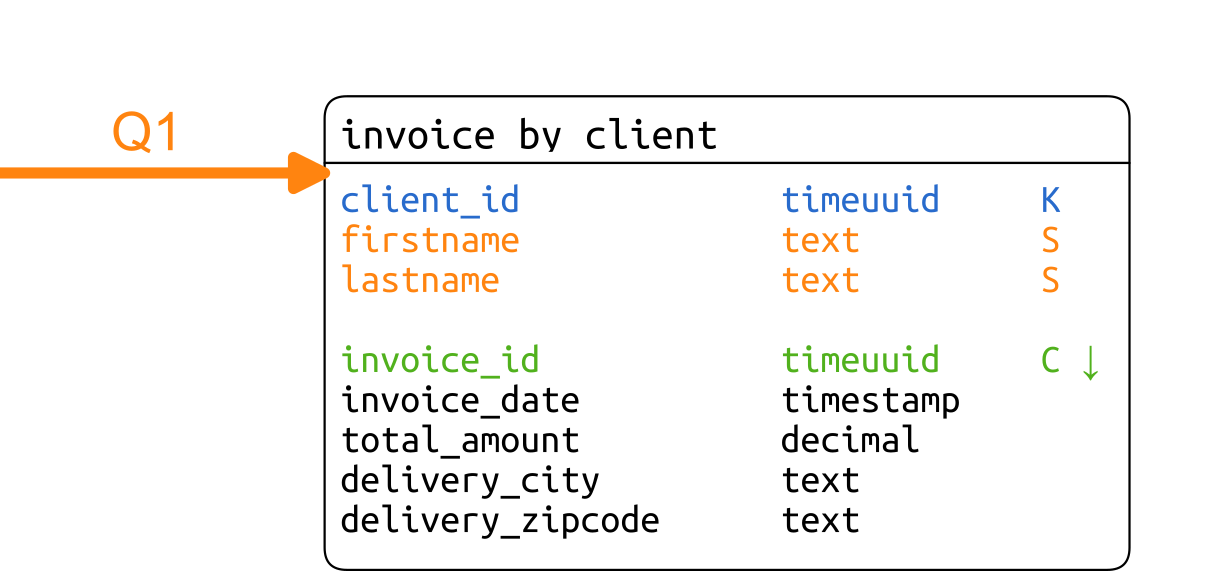
Pour répondre à la première requête, nous allons lister un résumé de la facture de chaque client. Notre clé de recherche est l’identifiant du client, elle prendra naturellement la place de clé de partition. Les informations spécifiques au client, mais indépendantes de la facture comme son nom et son prénom, seront copiées dans des colonnes statiques pour éviter une jointure trop coûteuse lorsqu’on travaille avec Cassandra. Chaque résumé de facture sera enregistré dans une ligne.
Les dernières factures étant les plus intéressantes, nous classerons les factures dans l’ordre descendant.
A cette étape, nous obtenons le schéma suivant :
La liste des factures du client obtenue, elle sera présentée à l’utilisateur d’une manière ou d’une autre. Celui-ci sera à même de choisir un élément dans la liste et d’en demander le détail.
Charger le détail d’une facture
Pour stocker le détail d’une facture, nous allons nous appuyer sur la relation de composition entre les entités Invoice et InvoiceItem. Celle-ci se traduit naturellement dans le modèle Cassandra par l’imbrication des lignes dans une partition. La partition et les colonnes statiques représentent l’entité contenante, Invoice dans notre cas, et les lignes l’entité contenue, ici InvoiceItem.
Les données utiles décrivant le produit et le client sont copiés dans les lignes et partitions.
Lors de cette modélisation, nous mettons en forme deux mécanismes importants : la duplication et l’imbrication. La duplication est mise en œuvre quand les données du client ou du produit sont copiées dans la table invoice. L’imbrication est mise en œuvre lorsque les lignes de factures sont incluses dans la partition qui représente la facture.
Il est important de distinguer la duplication technique du nom du client qui est une forme de dénormalisation motivée par les performances applicative et la copie fonctionnelle de l’adresse qui fait partie du modèle conceptuel et répond à un besoin métier.
La table invoice ainsi produite ressemble fortement à la table invoice_by_client. Elles diffèrent cependant dans l’interprétation d’un même élément. La table invoice représente deux entités imbriquées. Elle est la source de vérité des données qui y sont conservées à l’exception des champs copiés depuis Client et* Produit*. La table invoice_by_client représente une relation 1-* : seul les identifiants y sont significatifs, les autres données ne sont que des copies de dénormalisation.
À la fin, on obtient le diagramme suivant :

Modèle physique
Le modèle logique obtenu, il est d’usage de le transformer en modèle physique.
Cela consiste en général à dégrader le modèle logique pour qu’il puisse fonctionner avec les vrais contraintes opérationnelles. Dans le cadre de Cassandra, il convient de vérifier que la taille d’une partition ne devienne jamais trop grosse. Il est souhaitable de limiter une partition à 100 000 valeurs et 100 Mo pour éviter qu’une partition trop lourde ne plombe les performances.
Ici, le nombre de partitions de la facture ne risque pas de déborder. Il nous faut vérifier qu’il n’existe pas de super client qui dispose d’un nombre de factures gigantesque. Nous supposerons ici que ce n’est pas le cas. Nous verrons dans un prochain article comment adapter le modèle pour éviter les partitions de très grande taille.
Il ne nous reste plus qu’à produire nos scripts CQL de création de tables.
create keyspace invoice WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1 }; use invoice; create table invoice ( invoice_id timeuuid, firstname text static, lastname text static, invoice_date timestamp static, payment_date timestamp static, total_amount decimal static, delivery_address text static, delivery_city text static, delivery_zipcode text static, item_id timeuuid, item_label text, item_price decimal, item_qty int, item_total decimal, primary key (invoice_id, item_id) ); create table invoice_by_client ( client_id timeuuid, firstname text static, lastname text static, invoice_id timeuuid, invoice_date timestamp, total_amount decimal, delivery_city text, delivery_zipcode text, primary key (client_id, invoice_id) ) with clustering order by (invoice_id desc);
Et maintenant, il ne reste plus qu’à développer notre superbe application…
Cet article est le pilote d’une série d’articles sur la modélisation Cassandra. Beaucoup de séries s’arrêtent au pilote lorsqu’elles ne trouvent pas leur public. Donc si vous l’avez aimé et que vous souhaitez d’autres épisodes, faites le plus de bruit possible.
Vous souhaitez tout savoir du Big Data (architectures, solutions, freins et opportunités…) ? Découvrez notre livre blanc Big Data !
