
Dans les précédents posts, nous avons utilisé Apache Spark avec un exécuteur unique. Spark étant un framework de calcul distribué, nous allons maintenant monter un cluster en mode standalone.
Topologie
Un cluster Spark se compose d’un master et d’un ou plusieurs workers. Le cluster doit être démarré et rester actif pour pouvoir exécuter des applications.
Le master a pour seul responsabilité la gestion du cluster et il n’exécute donc pas de code MapReduce. Les workers, en revanche, sont les exécuteurs. Ce sont eux qui apportent des ressources au cluster, à savoir de la mémoire et des cœurs de traitement.
Pour exécuter un traitement sur un cluster Spark, il faut soumettre une application dont le traitement sera piloté par un driver. Deux modes d’exécution sont possibles :
- mode client : le driver est créé sur la machine qui soumet l’application
- mode cluster : le driver est créé à l’intérieur du cluster.
Communication au sein du cluster
Les workers établissent une communication bidirectionnelle avec le master : le worker se connecte au master pour ouvrir un canal dans un sens, puis le master se connecte au worker pour ouvrir un canal dans le sens inverse. Il est donc nécessaire que les différents nœuds du cluster puissent se joindre correctement (résolution DNS…).
La communication entre les nœuds s’effectue avec le framework Akka. C’est utile à savoir pour identifier les lignes de logs traitant des échanges entre les nœuds.
Les nœuds du cluster (master comme workers) exposent par ailleurs une interface Web permettant de surveiller l’état du cluster ainsi que l’avancement des traitements. Chaque nœud ouvre donc deux ports :
- un port pour la communication interne : port 7077 par défaut pour le master, port aléatoire pour les workers
- un port pour l’interface Web : port 8080 par défaut pour le master, port 8081 par défaut pour les workers.
Création du cluster
Pour commencer, téléchargez une distribution binaire de Spark depuis la page de download. Préférez la version “Pre-built for Hadoop 2.4” de la dernière release (1.1.0 à ce jour). Décompressez l’archive dans le répertoire de votre choix, au même endroit si vous déployez sur plusieurs machines.
Démarrage du master
Le master peut être démarré via le script sbin/start-master.sh. Les options disponibles sont :
-i IP,--ip IP: adresse IP sur laquelle se binder-p PORT,--port PORT: port utilisé pour la communication interne--webui-port PORT: port pour l’interface Web.
Nous pouvons lancer le script sans options :
$ sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /Users/aseigneurin/logiciels/spark-1.1.0-bin-hadoop2.4/sbin/../logs/spark-aseigneurin-org.apache.spark.deploy.master.Master-1-MacBook-Pro-de-Alexis.local.out
Le programme se lance en daemon et il rend donc la main. Les logs sont écrits dans des fichiers tournants. On peut y voir que l’interface Web est disponible sur le port 8080. On peut également lire l’URL du cluster (spark://MacBook-Pro-de-Alexis.local:7077) que l’on devra indiquer pour démarrer les workers.
$ tail -f logs/spark-aseigneurin-org.apache.spark.deploy.master.Master-1-MacBook-Pro-de-Alexis.local.out
...
14/11/12 14:29:09 INFO Remoting: Starting remoting
14/11/12 14:29:09 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkMaster@MacBook-Pro-de-Alexis.local:7077]
14/11/12 14:29:09 INFO Utils: Successfully started service 'sparkMaster' on port 7077.
14/11/12 14:29:09 INFO Master: Starting Spark master at spark://MacBook-Pro-de-Alexis.local:7077
14/11/12 14:29:09 INFO Utils: Successfully started service 'MasterUI' on port 8080.
14/11/12 14:29:09 INFO MasterWebUI: Started MasterWebUI at http://10.10.200.112:8080
14/11/12 14:29:09 INFO Master: I have been elected leader! New state: ALIVE
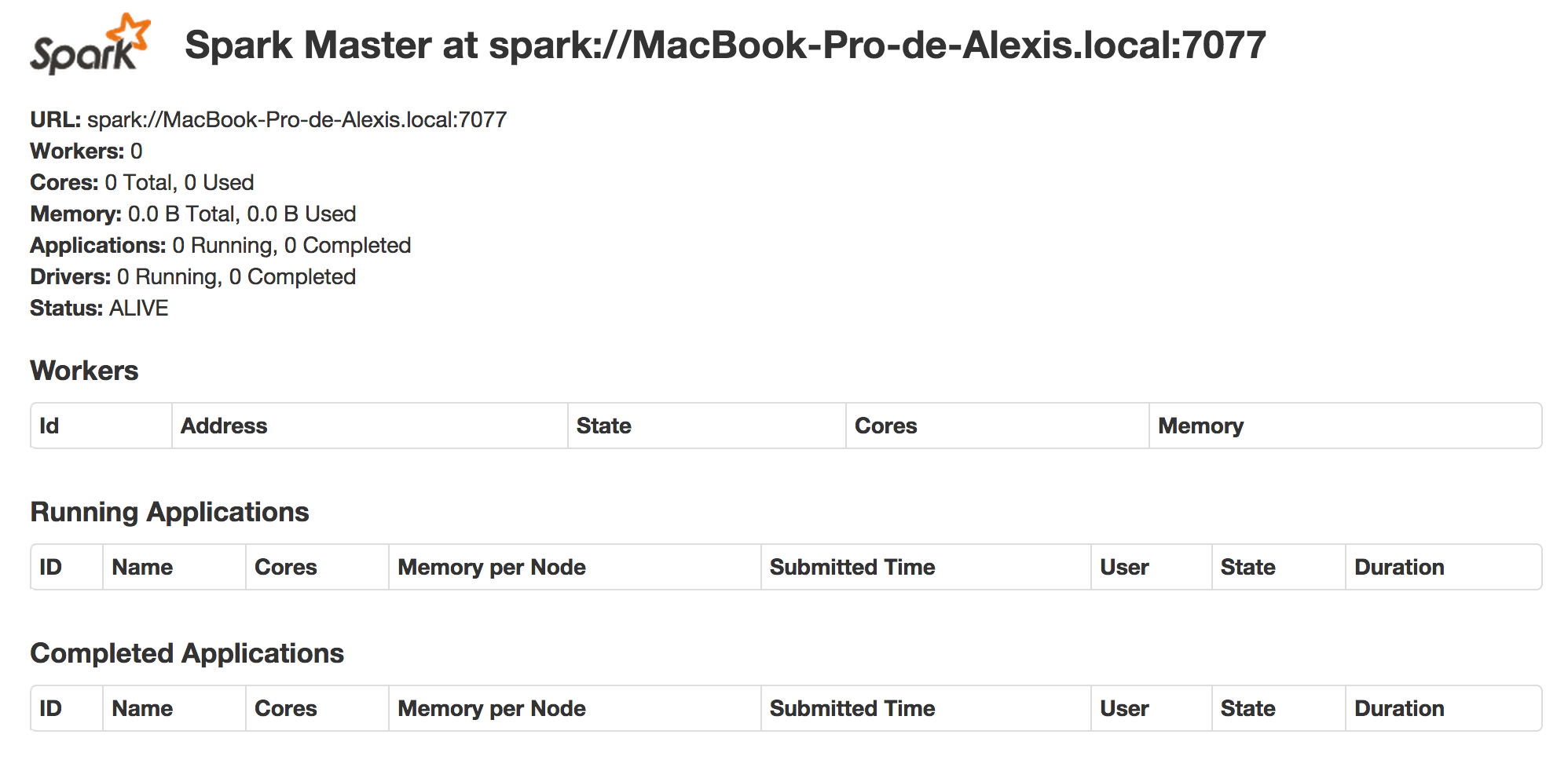
Nous pouvons alors afficher l’interface Web du cluster :
Démarrage des workers
Nous allons ensuite démarrer 3 workers via la commande bin/spark-class org.apache.spark.deploy.worker.Worker. Celle-ci attend en argument l’URL du cluster ainsi que d’éventuelles options. Les options possibles sont les mêmes que celles disponibles sur le master, auxquelles s’ajoutent :
-c CORES,--cores CORES: nombre de cœurs alloués-m MEM,--memory MEM: quantité de mémoire allouée
Notez qu’un worker utilise par défaut toute la mémoire de la machine moins 1 Go laissé à l’OS. Dans notre cas, nous allons démarrer plusieurs workers sur le même nœud physique. Nous allons donc limiter la mémoire allouée au process à 4 Go via l’option --memory 4G, et restreindre à l’utilisation de 2 cœurs via l’option --cores 2.
Ici, le programme ne rend pas la main et on voit le log s’afficher directement sur la console. On peut voir que le port de communication interne est choisi au hasard (ici, 64570), que l’interface Web est accessible sur le port 8081, et que la communication a été établi avec le master.
$ bin/spark-class org.apache.spark.deploy.worker.Worker spark://MacBook-Pro-de-Alexis.local:7077 --cores 2 --memory 4G
...
14/11/12 14:29:14 INFO Remoting: Starting remoting
14/11/12 14:29:14 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkWorker@10.10.200.112:64570]
14/11/12 14:29:14 INFO Utils: Successfully started service 'sparkWorker' on port 64570.
14/11/12 14:29:14 INFO Worker: Starting Spark worker 10.10.200.112:64570 with 2 cores, 4.0 GB RAM
14/11/12 14:29:14 INFO Worker: Spark home: /Users/aseigneurin/logiciels/spark-1.1.0-bin-hadoop2.4
14/11/12 14:29:14 INFO Utils: Successfully started service 'WorkerUI' on port 8081.
14/11/12 14:29:14 INFO WorkerWebUI: Started WorkerWebUI at http://10.10.200.112:8081
14/11/12 14:29:14 INFO Worker: Connecting to master spark://MacBook-Pro-de-Alexis.local:7077...
14/11/12 14:29:15 INFO Worker: Successfully registered with master spark://MacBook-Pro-de-Alexis.local:7077
Notez qu’une ligne supplémentaire apparait dans le log du master, confirmant ainsi la connexion entre le master et le worker :
14/11/12 14:29:15 INFO Master: Registering worker 10.10.200.112:64570 with 2 cores, 4.0 GB RAM
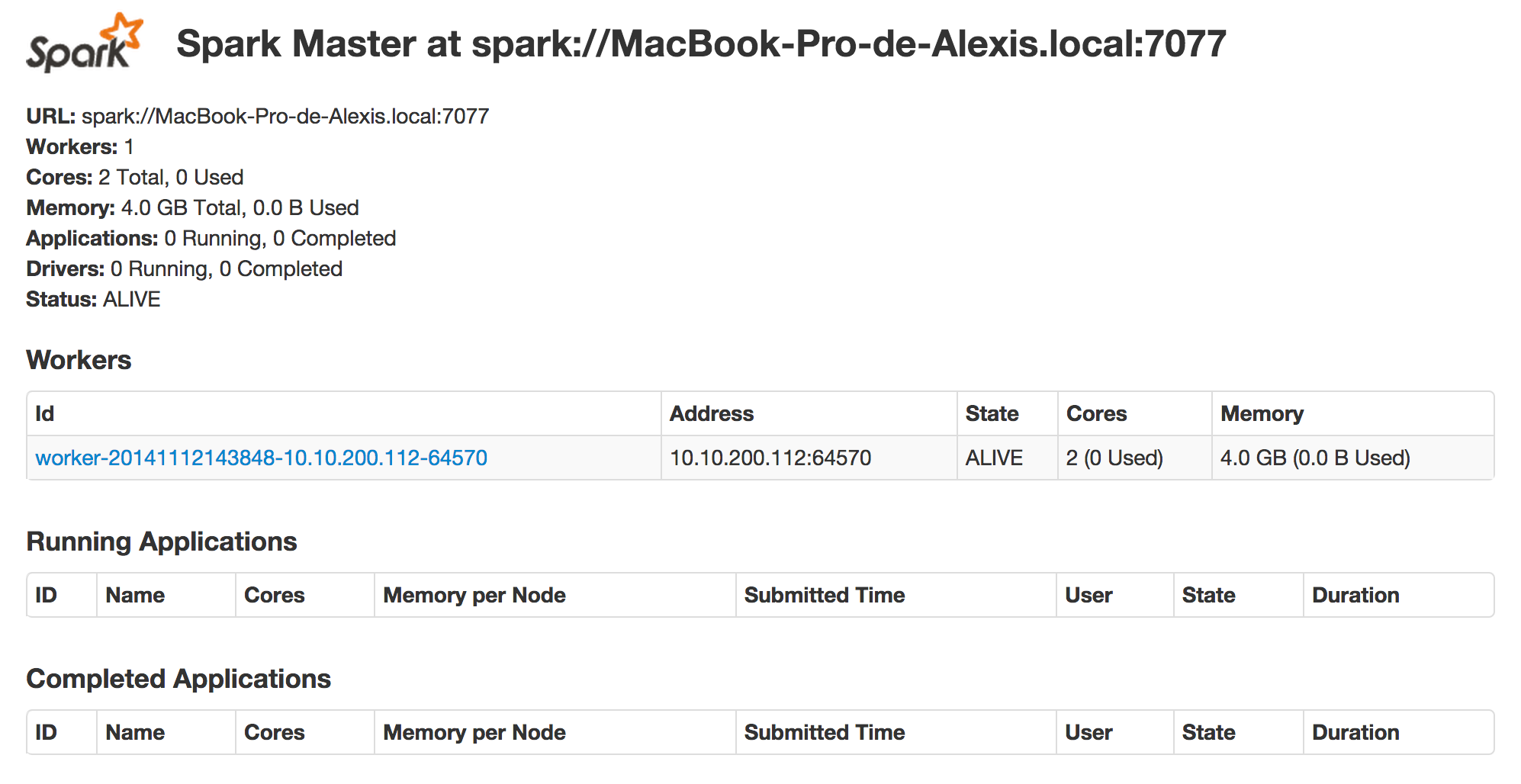
On peut voir apparaître le worker dans l’interface Web :
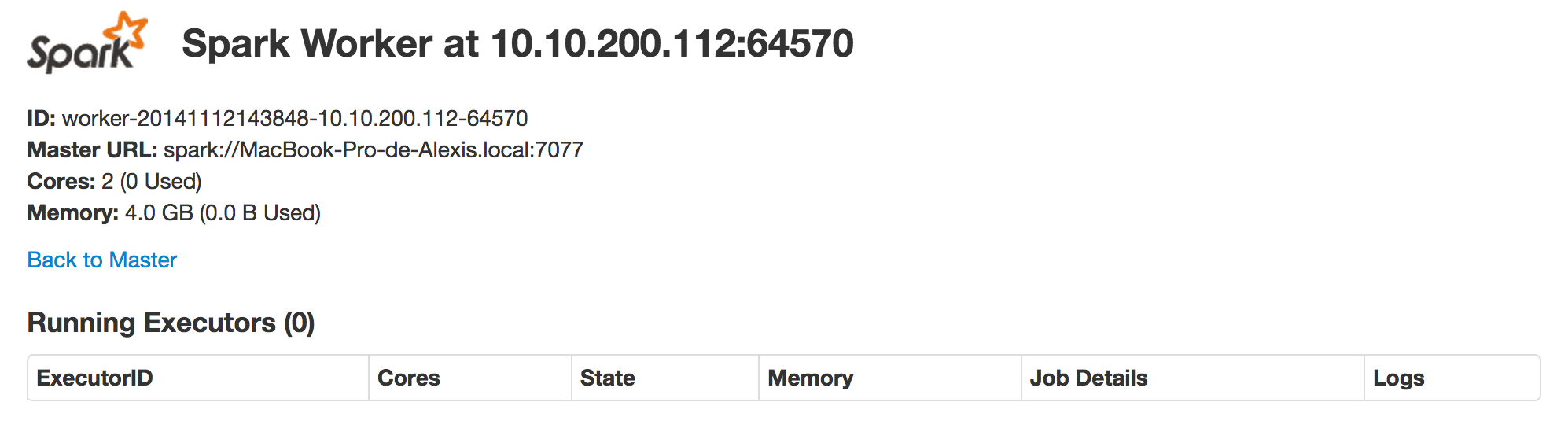
Via cette interface, il est possible de voir le statut du worker :
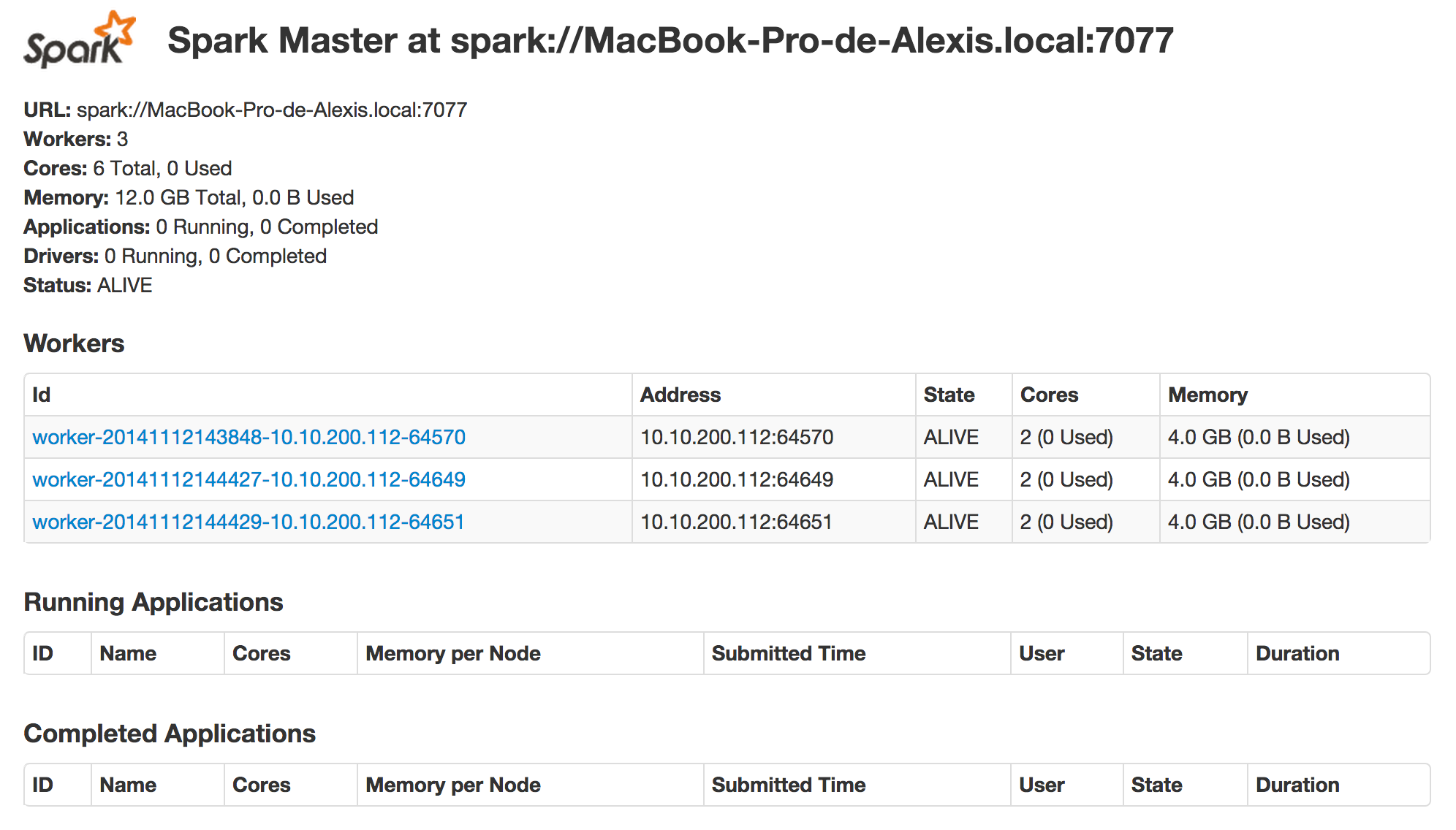
Nous démarrons donc deux workers supplémentaires. Le port 8081 étant déjà utilisé par le premier worker, ces nouveaux workers exposent alors leur interface Web sur les ports 8082 et 8083.
Dans l’interface Web du master, on peut voir que le nombre de cœurs et la mémoire des workers se cumulent, totalisant ainsi 6 cœurs et 12 Go de mémoire :
Lancement d’une application sur le cluster
Préparation et lancement
Pour être exécutée sur un cluster, une application Spark doit être packagée dans un JAR et disposer d’une classe avec une méthodemain.
Deux précautions doivent être prises :
- le contexte Spark doit être initialisé sans la déclaration
setMaster(...) - les chemins de fichiers doivent être accessibles par tous les workers : nous utilisons ici des chemins absolus.
Nous utilisons un exemple du post précédent :
public class WikipediaMapReduceByKey {
public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setAppName("wikipedia-mapreduce-by-key");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.textFile("/Users/aseigneurin/dev/spark-sandbox/data/wikipedia-pagecounts/pagecounts-20141101-*")
.map(line -> line.split(" "))
.mapToPair(s -> new Tuple2<String, Long>(s[0], Long.parseLong(s[2])))
.reduceByKey((x, y) -> x + y)
.sortByKey()
.foreach(t -> System.out.println(t._1 + " -> " + t._2));
}
}
Nous pouvons packager l’application avec Maven :
$ mvn package
[INFO] ------------------------------------------------------------------------
[INFO] Building spark-sandbox 0.0.1-SNAPSHOT
[INFO] ------------------------------------------------------------------------
...
[INFO] --- maven-jar-plugin:2.4:jar (default-jar) @ spark-sandbox ---
[INFO] Building jar: /Users/aseigneurin/dev/spark-sandbox/target/spark-sandbox-0.0.1-SNAPSHOT.jar
...
L’application peut alors être soumise via la commande bin/spark-submit à laquelle il faut indiquer des options :
- l’URL du master (
--master) - la classe
main(--class) - le mode
clientoucluster(--deploy-mode) - le JAR.
En mode cluster, le driver est soumis au cluster et le programme rend la main :
$ bin/spark-submit --master spark://MacBook-Pro-de-Alexis.local:7077 --class com.seigneurin.spark.WikipediaMapReduceByKey --deploy-mode cluster .../target/spark-sandbox-0.0.1-SNAPSHOT.jar
...
14/11/12 15:22:56 INFO Utils: Successfully started service 'driverClient' on port 65450.
Sending launch command to spark://MacBook-Pro-de-Alexis.local:7077
Driver successfully submitted as driver-20141112152257-0000
... waiting before polling master for driver state
... polling master for driver state
State of driver-20141112152257-0000 is RUNNING
Driver running on 10.10.200.112:64649 (worker-20141112144427-10.10.200.112-64649)
Suivi de l’exécution
L’application apparait alors dans la section Running Applications ainsi que dans la section Running Drivers.
On peut remarquer que le driver utilise 512 Mo de mémoire et que l’application utilise 512 Mo par nœud. Par ailleurs, les 2 cœurs de chaque worker sont utilisés.

En cliquant sur le nom de l’application, on peut obtenir son statut d’exécution.
On remarque que, sur l’un des workers, seul un cœur est alloué à l’application : l’autre cœur est alloué au driver.

En cliquant sur le worker numéro 2, on peut effectivement vérifier l’allocation des ressources entre l’application et le driver :
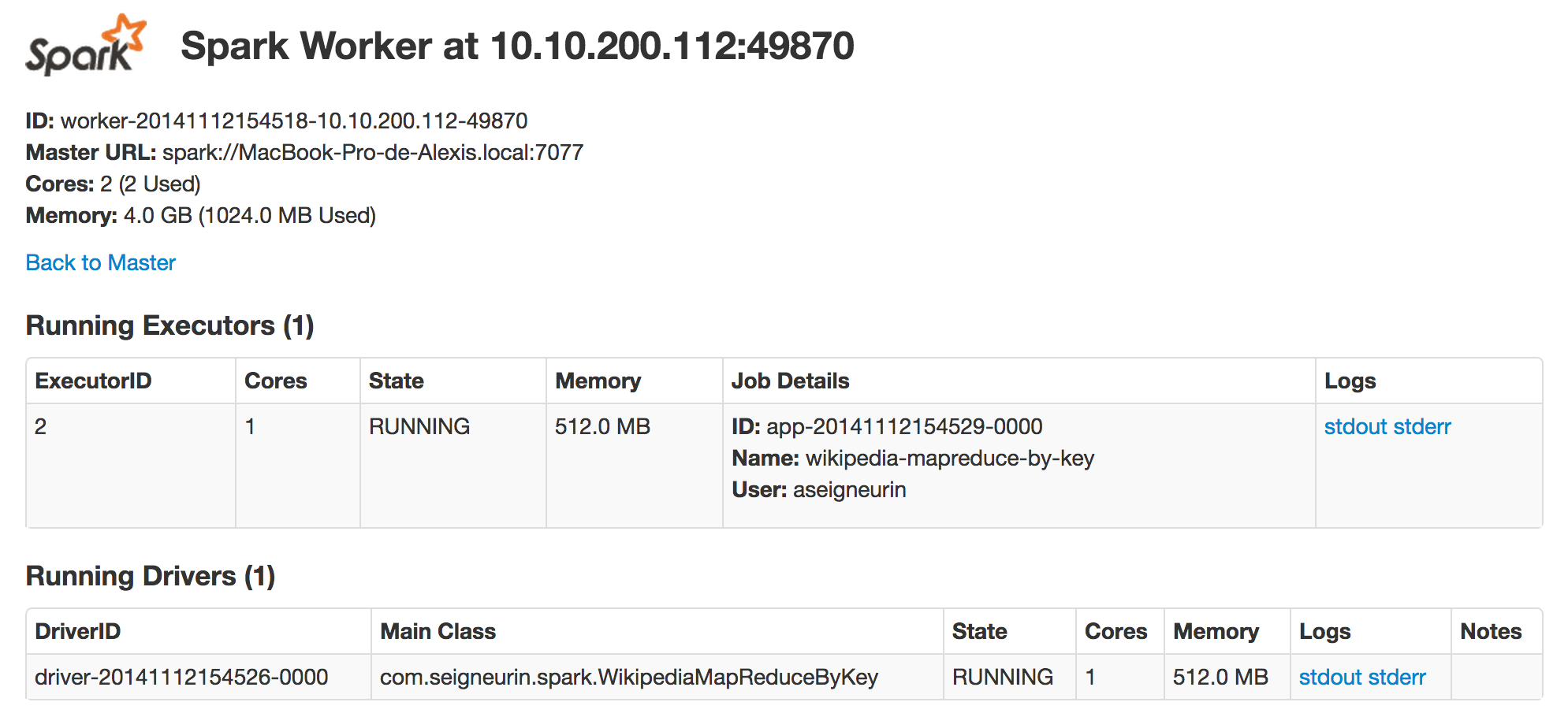
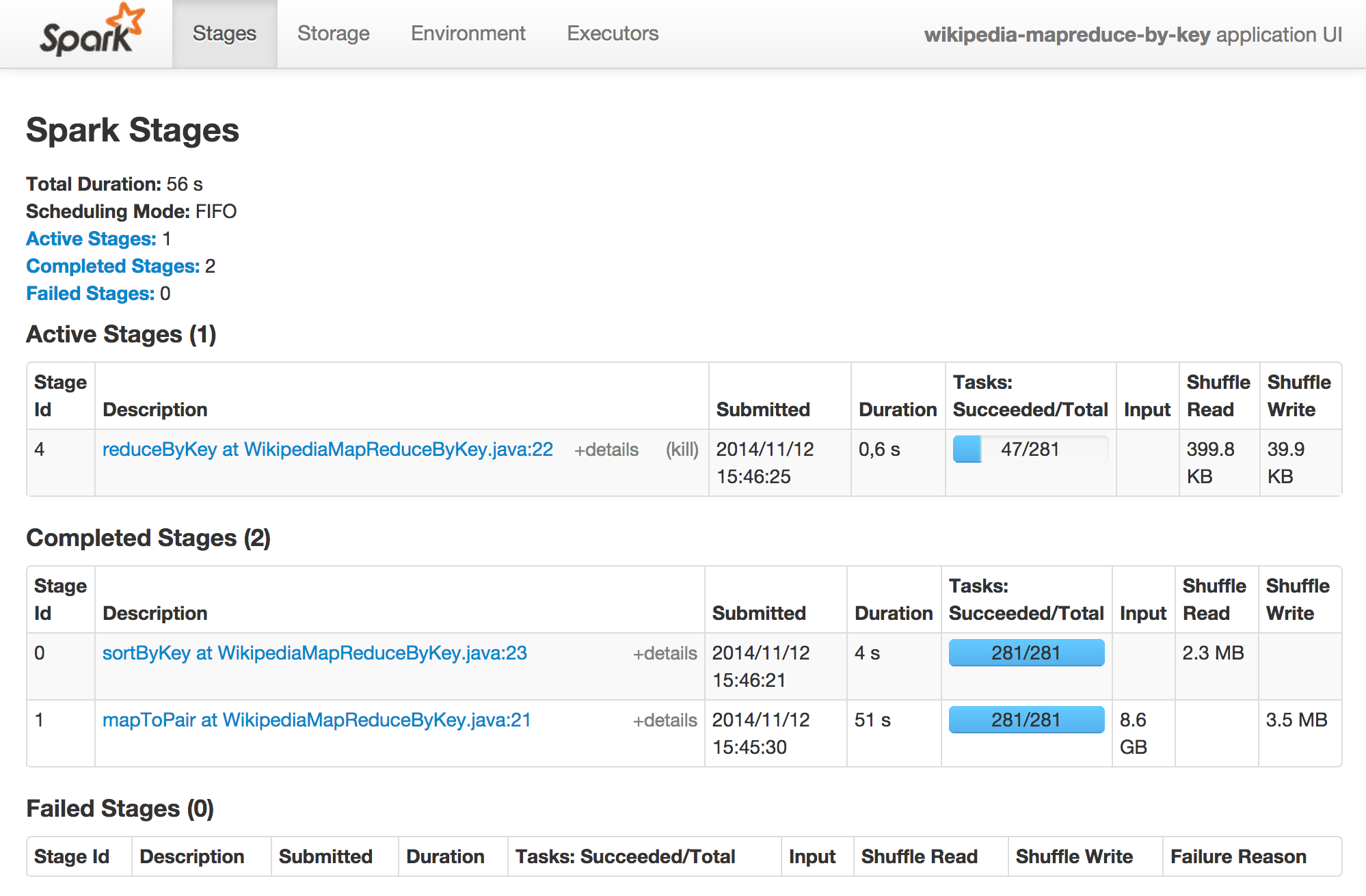
En revenant sur la page principale, si on clique sur l’ID de l’application (app-20141112154529-0000), on peut visualiser l’avancement des différentes tâches de notre application :
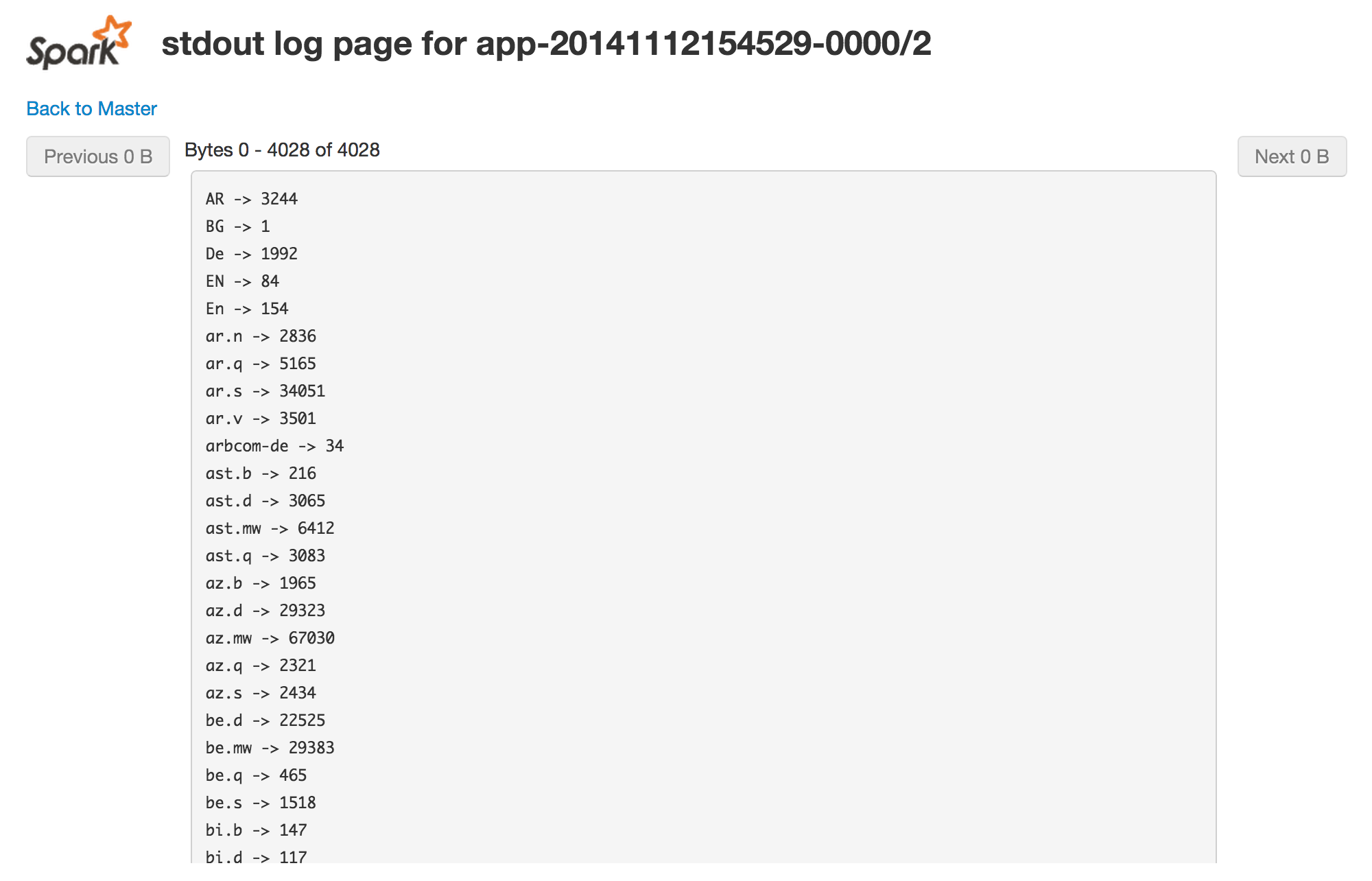
Enfin, via la page d’un worker, on peut accéder aux logs d’exécution (stdout et stderr).
Dans notre cas, le résultat ayant été écrit sur la console, celui-ci est fragmenté sur les consoles des 3 exécuteurs.
Analyse
Données en entrée
Notre programme utilise des données provenant du file system local. Ce n’est évidemment pas adapté pour un cluster distribué sur plusieurs machines.
Idéalement, les données devraient être distribuées sur le cluster. Lorsque chaque nœud stocke localement une partie des données, Spark peut exploiter le principe de colocalisation des données et des traitements : la donnée est traitée à l’endroit où elle se trouve, sans transfert réseau.
Un exemple de file system permettant cela est HDFS. HDFS répartit les données sur les nœuds du cluster, éventuellement en répliquant celles-ci. Ainsi, si les workers Spark sont également des data nodes HDFS, la donnée peut être traitée localement.
Données en sortie
Nous avons écrit le résultat de notre calcul sur la console. Ce résultat est fragmenté et difficilement accessible.
Une solution adaptée pourrait être d’écrire dans HDFS. On pourrait également utiliser un driver tels ceux fournis pour Cassandra ou Elasticsearch.
Allocation mémoire
Une application utilise par défaut 512 Mo de mémoire par nœud. Dans notre cas, l’application a effectivement utilisé 512 Mo sur chacun des 3 workers.
Il est possible de régler cette valeur lors de la création de la configuration fournie au contexte Spark :
new SparkConf()
.set("spark.executor.memory", "2G")
...
L’application ne sera déployée que sur les workers disposant de suffisamment de mémoire libre. Sur notre cluster de 3 workers disposant chacun de 2 Go, un nœud exécutera le driver (512 Mo). Seuls deux nœuds seront alors utilisables.
Attention à ne pas utiliser une valeur trop élevée : si aucun nœud ne répond à la contrainte, l’application ne pourra pas s’exécuter.
14/11/12 18:38:07 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient memory
Résilience
En cluster, le risque de défaillance est sensiblement augmenté. Un nœud peut être “perdu” en raison d’une défaillance d’un disque, d’une panne de réseau…
Spark répond à ce problème en relançant sur d’autres nœuds les traitements déjà effectués sur le nœud perdu.
En pratique, lorsqu’on tue volontairement un worker, on peut voir dans le log du driver que le nœud en question est déconnecté et que les tâches sont soumises à d’autres workers :
14/11/12 18:45:19 INFO TaskSetManager: Starting task 81.0 in stage 1.0 (TID 81, 10.10.200.112, PROCESS_LOCAL, 1313 bytes)
14/11/12 18:45:19 INFO TaskSetManager: Finished task 75.0 in stage 1.0 (TID 75) in 1061 ms on 10.10.200.112 (76/281)
14/11/12 18:45:19 INFO ConnectionManager: Removing ReceivingConnection to ConnectionManagerId(10.10.200.112,52569)
14/11/12 18:45:19 INFO ConnectionManager: Key not valid ? sun.nio.ch.SelectionKeyImpl@16575981
14/11/12 18:45:19 INFO ConnectionManager: Removing SendingConnection to ConnectionManagerId(10.10.200.112,52569)
14/11/12 18:45:19 INFO ConnectionManager: Removing SendingConnection to ConnectionManagerId(10.10.200.112,52569)
14/11/12 18:45:19 INFO SparkDeploySchedulerBackend: Executor 1 disconnected, so removing it
14/11/12 18:45:19 INFO ConnectionManager: key already cancelled ? sun.nio.ch.SelectionKeyImpl@16575981
java.nio.channels.CancelledKeyException
at org.apache.spark.network.ConnectionManager.run(ConnectionManager.scala:310)
at org.apache.spark.network.ConnectionManager$$anon$4.run(ConnectionManager.scala:139)
14/11/12 18:45:19 ERROR TaskSchedulerImpl: Lost executor 1 on 10.10.200.112: remote Akka client disassociated
14/11/12 18:45:19 INFO TaskSetManager: Re-queueing tasks for 1 from TaskSet 1.0
14/11/12 18:45:19 INFO DAGScheduler: Resubmitted ShuffleMapTask(1, 32), so marking it as still running
14/11/12 18:45:19 INFO DAGScheduler: Resubmitted ShuffleMapTask(1, 53), so marking it as still running
14/11/12 18:45:19 INFO DAGScheduler: Resubmitted ShuffleMapTask(1, 26), so marking it as still running
...
Dans l’interface Web, des items sont marqués comme “failed” :
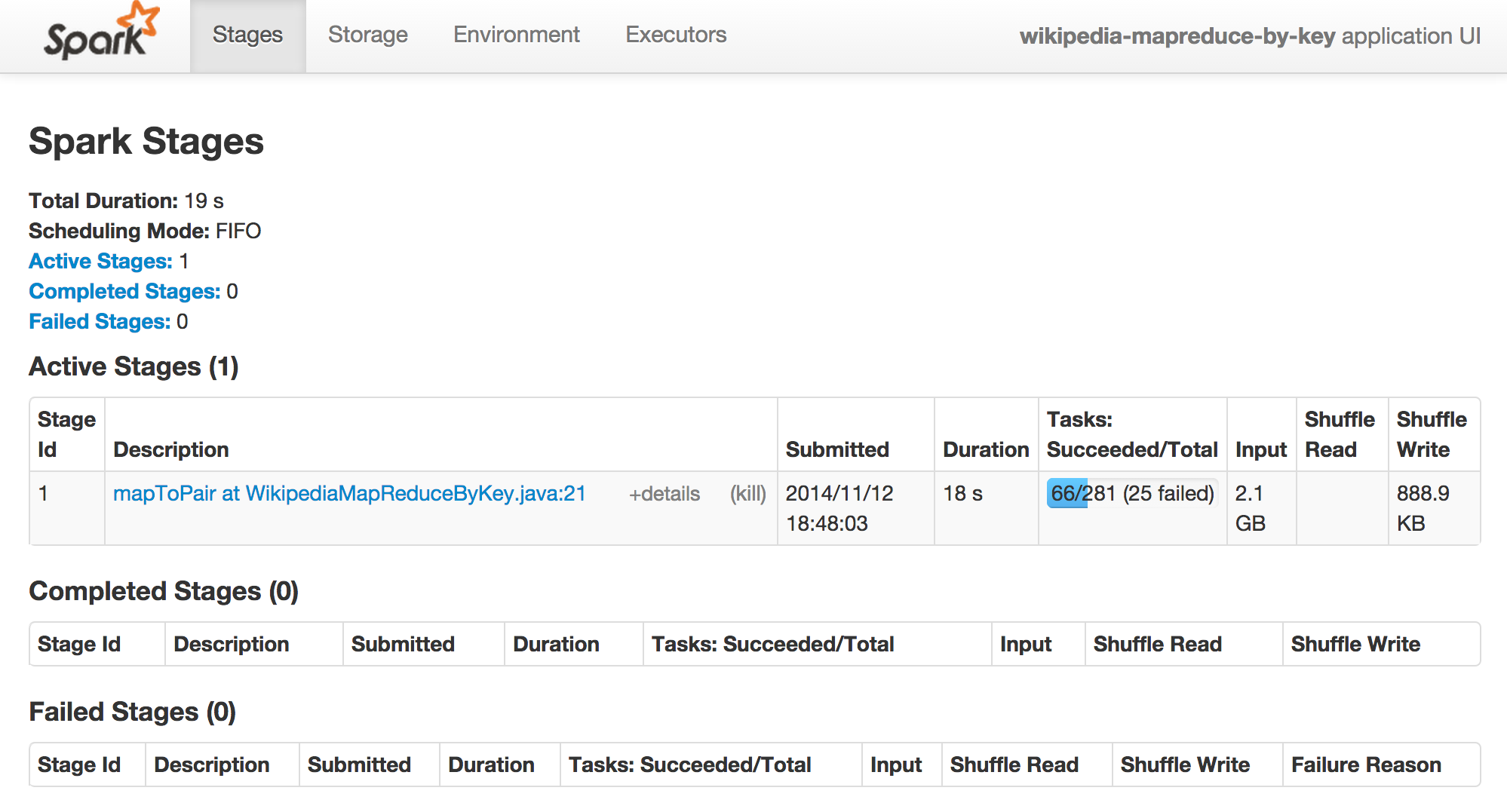
Le traitement se poursuit toutefois et se termine sans nécessiter d’intervention. La défaillance d’un worker est donc, au final, sans incidence sur le résultat outre un temps d’exécution allongé du fait du retraitement.
Le master, en revanche, joue un rôle unique dans le cluster. Il est donc un Single Point Of Failure qu’il est possible de résoudre avec ZooKeeper.
Conclusion
La création d’un cluster Spark permet d’exploiter la puissance de traitement de plusieurs machines. Sa mise en place est relativement simple. Il faudra simplement prendre garde à rendre le master résilient en utilisant ZooKeeper.
Par ailleurs, l’exécution d’une application ne requiert pas de modification du code de traitement. La contrainte principale est de s’assurer que les données sont lues et écrites depuis/vers des systèmes eux aussi distribués.
Nous verrons dans un prochain post les interconnexions possibles avec HDFS, Cassandra et Elasticsearch.
