Les avantages d’une centralisation des logs d’un système informatique complexe sont reconnus depuis longtemps par les hébergeurs. La mise en oeuvre d’une collecte centralisée basée sur syslog (via rsyslog ou syslog-ng) est donc maintenant un classique dans le cadre de l’exploitation de ces systèmes complexes.
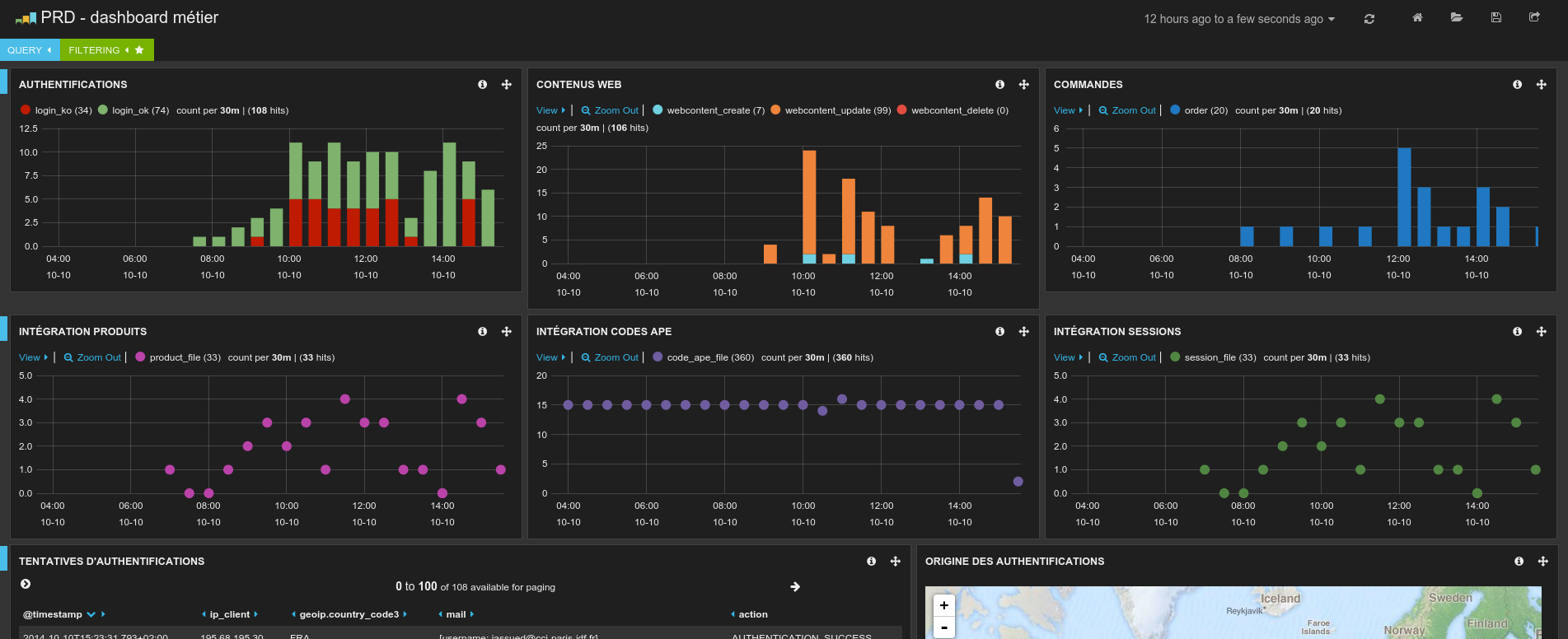
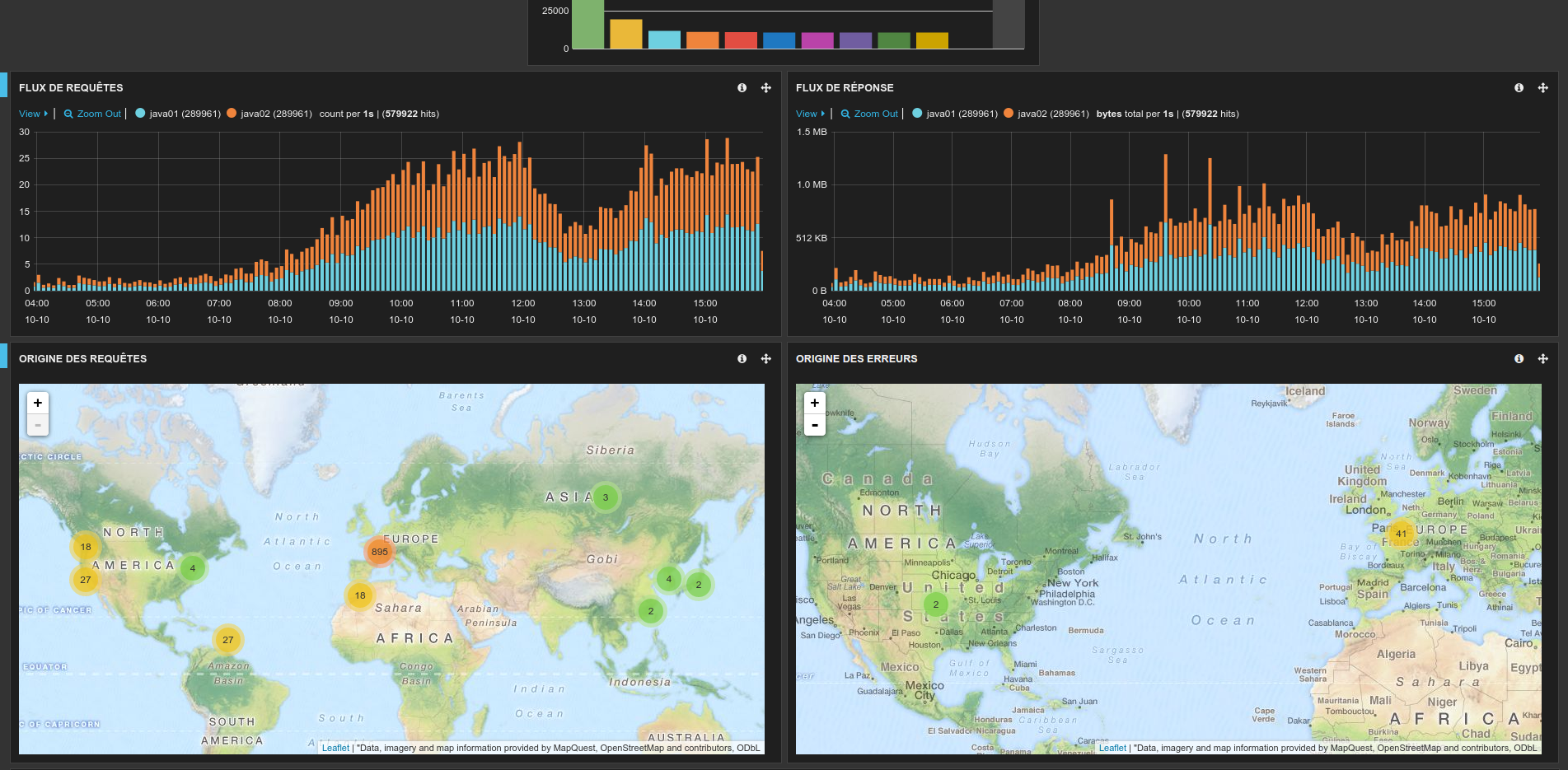
Néanmoins l’exploitation des masses d’informations contenues dans ces fichiers reste très limitée et fastidieuse tant qu’on a à faire à des fichiers texte sous forme brute. C’est là que des outils tels que Kibana (couplé à ElasticSearch) ou Splunk permettent d’aller vraiment plus loin en offrant des interfaces de recherche efficaces ainsi que la possibilité de produire des tableaux de bord permettant de suivre l’activité d’un système. Ce type d’outils destinés aussi bien aux administrateurs systèmes qu’aux développeurs ou aux experts métiers a pris un essor important ces dernières années avec le développement du mouvement DevOps, et nous souhaitions naturellement pouvoir proposer un tel service, pour un coût minimal, à l’ensemble des clients dont nous exploitons les systèmes.
Notre choix en terme de solution s’est porté sans surprise sur la stack ELK (ElasticSearch, LogStash, Kibana), mais autant son déploiement unitaire dans un cadre mono-projet est plutôt bien documenté, autant son déploiement en tant que service mutualisé posait plusieurs difficultés :
- transparence vis-à-vis des systèmes que nous hébergeons : ce service ne doit pas impacter les performances des systèmes en place ni nécessiter de modification de configuration et encore moins de code
- multi-tenancy : la condition sine qua non pour offrir ce service à faible coût est d’exploiter des instances mutualisées des différents composants de la stack ELK
- sécurisation : ces outils ayant vocation à être accessibles à des utilisateurs appartenant à des sociétés ou organismes différents, le cloisonnement des données et des permissions associées est donc une problématique essentielle
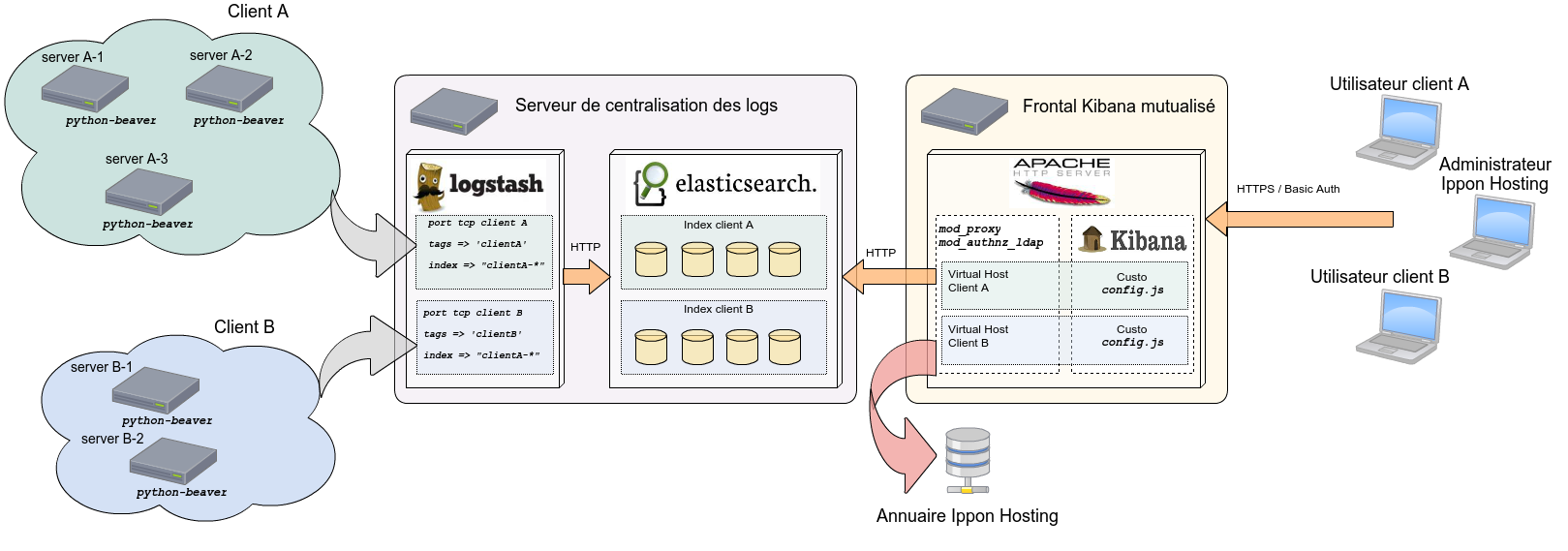
Avant de voir en détail comment nous avons traité ces trois problématiques, voici un schéma d’ensemble de l’architecture déployée.
Transparence
Lors de nos premiers tests de déploiement, le composant qui nous a posé le plus de difficultés était Logstash, pour deux raisons :
- comme l’on pouvait s’y attendre étant donné le socle technique (JRuby…) la consommation mémoire et CPU du processus Logstash fait qu’il n’est pas envisageable de le déployer sur chaque serveur dont on souhaite collecter les logs
- l’envoi des logs vers une instance centralisée de Logstash peut se faire via le protocole syslog (ou autre, comme un SockerAppender log4j), mais faire en sorte que chaque service produisant des logs utilise ce mécanisme risquait de devenir intrusif pour les services en question (il n’est pas forcément possible pour un hébergeur de modifier la librairie de log ou même la configuration de log d’un applicatif fourni tel quel par son client)
La solution à ce problème a été pour nous d’utiliser un composant complémentaire pour acheminer l’ensemble des logs jusqu’à une instance centralisée de Logstash, à savoir Beaver. Il s’agit d’un processus léger en Python qui consomme moins de 20 Mo de RAM sur chaque instance où il est déployé. Son rôle se limite à scanner les différents fichiers produits localement sur chaque serveur, à découper les logs ligne à ligne, à les horodater et enfin à les transmettre au serveur Logstash de centralisation. De cette manière, nous n’avons pas eu à modifier quoi que ce soit dans les services dont nous souhaitions collecter les logs et nous avons pu limiter au maximum l’utilisation des ressources matérielles sur chaque serveur.
Le déploiement d’un service Beaver ne pose aucune difficulté et sa configuration est très simple. En voici un extrait à titre d’exemple :
[beaver] logstash_version: 1 tcp_host: 123.123.123.123 tcp_port: 8083 format: json [/var/log/auth.log] type: auth tags: beaver
Multi-tenancy
La seconde difficulté que nous avons eu à traiter vient du fait que nous ne souhaitions pas avoir autant de processus Logstash et ElasticSearch que de clients. En effet, si on envisage un déploiement à grande échelle, le coût en ressources et en maintenance humaine devient vite insupportable. Il a donc fallu trouver une stratégie permettant de partager une seule instance tout en garantissant le cloisonnement des données.
Le point central concerne bien entendu le stockage des logs. ElasticSearch permet de cloisonner les données en utilisant des index distincts et permet également de créer de nouveaux index à la volée. Nous avons donc fait le choix de définir pour chaque client un préfixe utilisé pour nommer tous les index destinés à ce client.
En amont, nous avons également pu mutualiser l’instance Logstash en charge du parsing des logs en définissant un port d’écoute par client, les différentes instances Beaver de chaque client étant configurées pour communiquer vers ce port. Restait donc à implémenter au niveau Logstash l’association entre un port d’écoute et un ensemble d’index ElasticSearch. La notion de tag nous a permis de le faire simplement.
Extrait de configuration Logstash :
tcp { host => '123.123.123.123' port => '8083' codec => 'json' tags => 'clientA' } ... output { if 'clientA' in [tags] { elasticsearch { host => "234.234.234.234" protocol => http index => "clientA-%{+YYYY.MM.dd}" } } ... }
En aval, il nous a suffi de customiser le fichier config.js de Kibana pour chaque client de manière à le faire pointer vers l’index dédié aux dashboards de ce client :
kibana_index: "clientA-dashboards"
Sécurisation
La dernière problématique à traiter a été la sécurisation de cette infrastructure mutualisée. En effet, les stratégies décrites ci-dessus permettent de cloisonner les données au niveau du stockage, reste cependant à mettre en place une gestion fine d’autorisations pour associer des profils utilisateurs aux différents silos de données.
L’interface web exposée aux clients est Kibana, mais il ne s’agit que d’un ensemble de ressources statiques (HTML, JS, CSS) et l’accès aux données utiles se fait directement depuis le navigateur client vers ElasticSearch. C’est donc bien l’accès au composant ElasticSearch qu’il convient de sécuriser. Vous le savez probablement déjà mais ElasticSearch ne fournit nativement aucun mécanisme de ce type. Nous avons donc mis en place un reverse-proxy Apache afin de porter toute la couche sécurité. Nous avons retenu une stratégie de filtrage en white-list en ciblant précisément les requêtes ElasticSearch utilisées par Kibana
Dans notre implémentation, Apache est donc en charge :
- du chiffrement SSL
- de l’authentification des clients par rapport à notre annuaire LDAP (par virtual host)
- de la réécriture des URL permettant de servir le fichier
config.jsde Kibana customisé pour chaque client - du filtrage des requêtes à destination d’ElasticSearch - l’accès à ElasticSearch n’est autorisé que sur des URL commençant par le préfixe du client (ainsi que
/_nodes) - seul le verbe GET est autorisé sur
/_nodes - seuls les verbes GET et POST (et PUT et DELETE pour les administrateurs) sont autorisés pour les URL sur
/clientA
Conclusion
Une fois cette infrastructure mise en place, nous avons pu intégrer les logs d’un nouveau client en moins de 3 heures. L’objectif initial a donc été atteint. De fait, l’essentiel de l’effort pour déployer ce service pour un nouveau client consiste à identifier les données métiers utiles et à concevoir les dashboards métier qui les exploitent. Et c’est bien là que se trouve la valeur ajoutée de cette solution.
Merci à Alexis Seigneurin et Jimmy Goffaux pour leur aide précieuse dans la mise en place de cette solution !